
“ Large language models (LLMs) have become a key force driving industry transformation, especially crucial in RAG systems. This article focuses on five open-source tools that can efficiently import diverse data sources into LLMs, enhancing development efficiency while improving system performance.”

In the RAG workflow, how to efficiently and accurately import diverse data sources into LLMs is a critical challenge that directly affects system performance and reliability. Developers and researchers need reliable tools to seamlessly handle various data sources and optimize LLM performance. In this article, we will explore five outstanding open-source tools that can simplify the data scraping process and stand out due to their excellent practicality and significant impact.
1. OneFileLLM
OneFileLLM (GitHub repository: <span>jimmc414/onefilellm</span>) is a command-line utility designed to aggregate and preprocess data from different sources into a single text file, facilitating seamless data acquisition for LLMs. It can automatically identify the type of data source, whether it is a local file, GitHub repository, academic paper, YouTube subtitle, or web document link, and process accordingly. The aggregated data is automatically copied to the clipboard for immediate use.
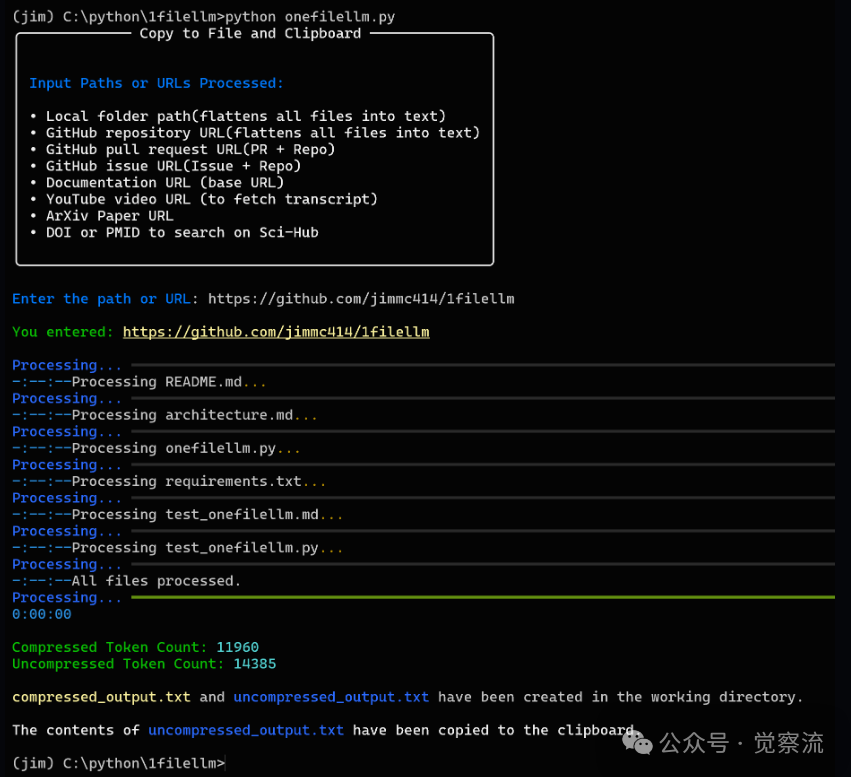
Key Features
-
• Automatic Source Detection: No manual intervention is required; it can automatically identify and process different data sources. -
• Multi-format Support: Compatible with various formats such as local files, GitHub repositories, pull requests, issue feedback, ArXiv papers, YouTube subtitles, and web links. -
• Clipboard Integration: Directly copies the aggregated text to the clipboard, effectively optimizing the workflow.
Use Cases
OneFileLLM is particularly useful for developers and researchers who need to integrate multi-source information into a unified format for LLM training or prompt generation. Its ability to handle various data types makes it an extremely flexible tool within the LLM ecosystem.
2. Firecrawl
Firecrawl (GitHub repository: <span>mendableai/firecrawl</span>) is a web data scraping tool that can extract content from websites and convert it into clear Markdown format, making it easier for LLMs to process. It can traverse all accessible subpages, even if the website does not provide a sitemap, and can handle dynamically rendered content through JavaScript. Firecrawl is not only open-source but also integrates with various tools and workflows.
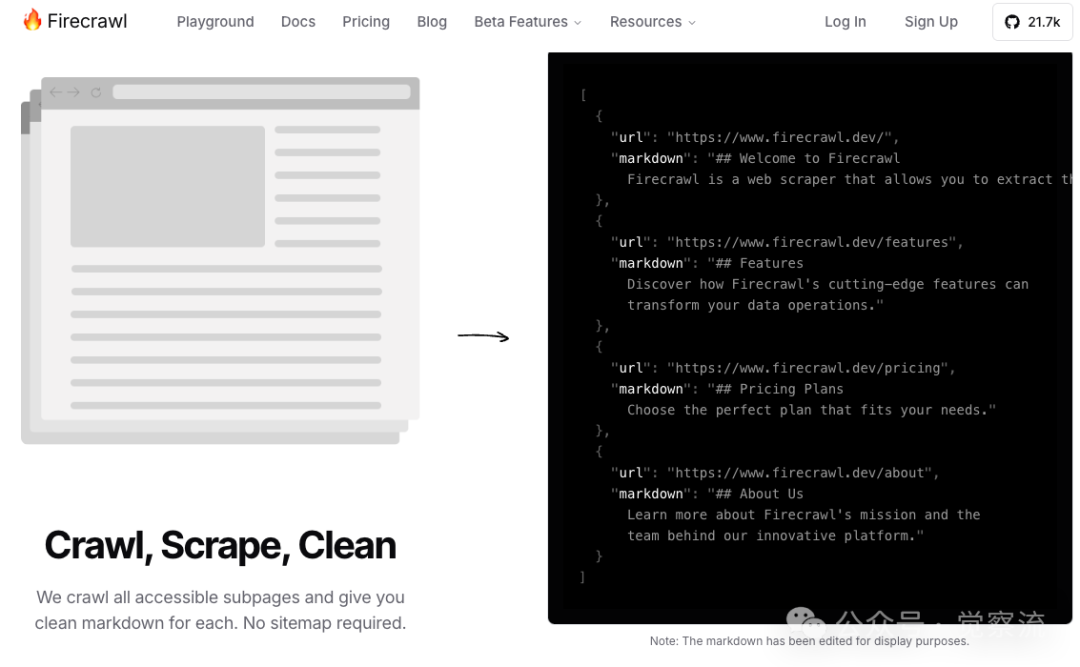
Key Features
-
• Comprehensive Scraping: Can access all subpages of a website, ensuring comprehensive data extraction. -
• Dynamic Content Handling: Capable of processing content rendered by JavaScript, capturing data that traditional scraping tools might miss. -
• Markdown Output: Generates clean, well-formatted Markdown text, making it very suitable for LLM-related applications.
Use Cases
Firecrawl is ideal for developers who need to import complete website data into LLMs, especially when facing complex and dynamic web pages. Its ability to handle JavaScript-rich websites significantly expands its application scope.
3. Ingest
Ingest (GitHub repository: <span>sammcj/ingest</span>) can parse directories of plain text files (e.g., source code) into a single Markdown file suitable for LLM slot inference. It traverses the directory structure, generating a tree view, and can include or exclude specific files based on glob patterns. Additionally, Ingest can directly pass prompts to LLMs for processing.

Key Features
-
• Directory Traversal: Can browse freely within the directory structure to aggregate data. -
• File Filtering: Can specify files to include or exclude based on specific patterns. -
• LLM Integration: Can interact directly with LLMs for immediate processing of acquired data.
Use Cases
Ingest is an ideal choice for developers looking to preprocess large-scale codebases or document repositories for LLMs. It can effectively structure data and convert it to Markdown format, significantly enhancing compatibility with various LLMs.
4. Jina AI Reader
Jina AI (GitHub repository: <span>jina-ai/reader</span>)’s Reader tool can convert any URL into a format suitable for LLM processing by simply adding https://r.jina.ai/ before the URL. This tool can clean and structure web content to meet LLM usage requirements. Additionally, it has a search function that can return the top five web results in a clear format.
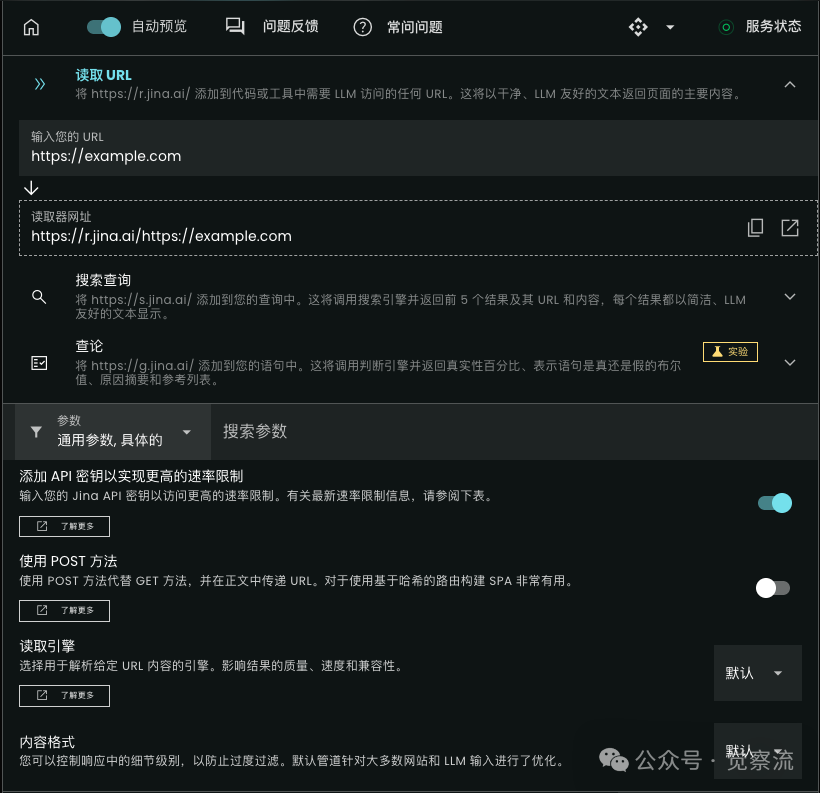
Key Features
-
• URL Conversion: Can convert web pages into clean, structured text for LLM processing. -
• Web Search Integration: Features a search endpoint that presents top search results in a format suitable for LLMs. -
• Adaptive Crawling: Can recursively crawl websites to accurately extract the most relevant pages.
Use Cases
Jina AI Reader is very beneficial for applications that need to import real-time web data into LLMs, such as chatbots or information retrieval systems. Its simple URL conversion method greatly simplifies the entire integration process.
5. Git Ingest
Git Ingest (GitHub repository: <span>cyclotruc/gitingest</span>) can convert Git repositories into a text format friendly to LLM prompts. Users only need to replace “hub” with “ingest” in any GitHub URL to obtain a text summary of the codebase. Additionally, this feature is also provided to users through a Chrome extension.
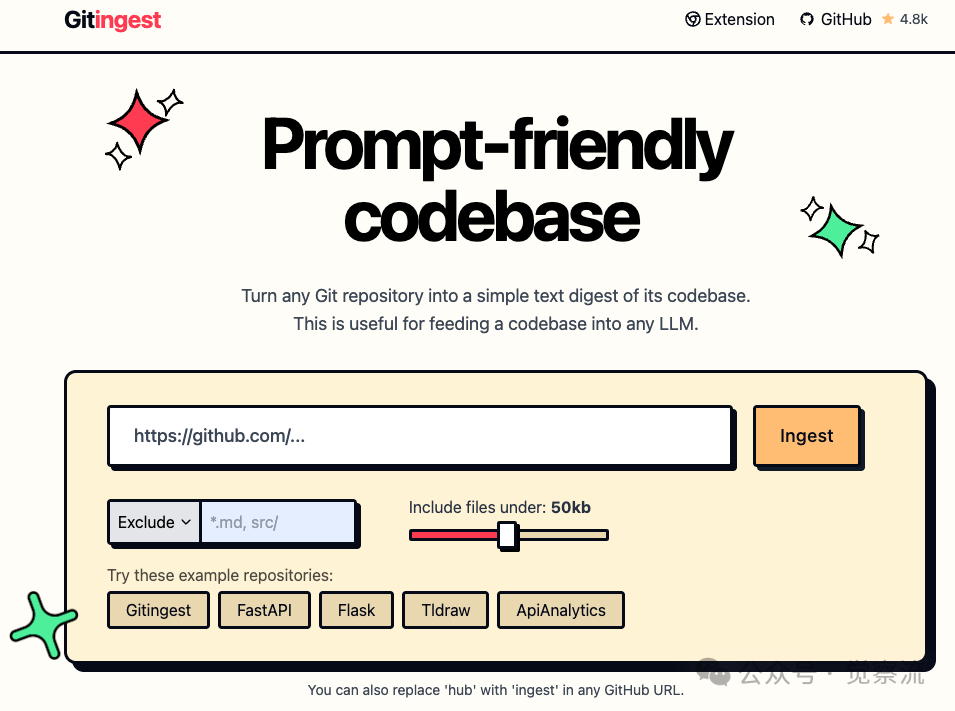
Key Features
-
• Simple URL Modification: Converts GitHub URLs into text summaries by adjusting the URL structure. -
• Browser Integration: Equipped with a Chrome extension for user convenience. -
• File Size Filtering: Can filter out files below a specified size, optimizing output results.
Use Cases
Git Ingest is well-suited for developers and researchers who need to analyze and manage codebases using LLMs. Its simple and intuitive URL modification method, along with seamless browser integration, effectively optimizes the data acquisition process for codebase information.
Conclusion
Efficient data acquisition is key to building high-performance RAG systems, and these tools ensure that LLMs obtain the structured and highly relevant data they need. Have you used any of the five tools mentioned above? We welcome your feedback.
This Week in Review – 202503
◆ Xinference + Roo-Cline: Private AI Coding Enhancement Solution, local security, improving R&D efficiency!
◆ phi-4 the strongest 14B? Custom inference challenges to solve? Xinference helps with just a click!
◆ Revealing A3: Comprehensive autonomous evaluation platform for Android Agent [Paper]
◆ Unlocking LLM System 2 Inference: The secrets of meta-cognitive chains (Meta-CoT) thinking
◆ Upgrading AI Evaluation Standards: ToolHop dataset, redefining the measurement scale for multi-hop reasoning ability of language models! [Paper]
◆ MiniMax-Text-01 Release: How Lightning Attention breaks the limitations of traditional Transformers?
◆ Top Ten LLM Benchmark Evaluations: Assisting AI teams in selection and R&D
◆ Coding’s single loop BGM
Welcome to like、 to read、 to follow. Follow us for more exciting content
I am 407🐝, an internet practitioner passionate about AI. Here, I share my observations, thoughts, and insights. I hope to inspire those who also love AI, technology, and life through my process of self-exploration.
Looking forward to our unexpected encounters. Click below to follow