

Author: PCA-EVAL Team
Affiliation: Peking University & Tencent
Abstract: Researchers from Peking University and Tencent have proposed the PCA-EVAL multi-modal embodied decision-making intelligence evaluation set. By comparing end-to-end decision-making methods based on multi-modal models with tool invocation methods based on LLMs, it has been observed that GPT-4 Vision demonstrates outstanding end-to-end decision-making capabilities from multi-modal perception to action, opening a new chapter in the field of embodied intelligence and visual language models.
Arxiv: https://arxiv.org/abs/2310.02071
Project Homepage: https://pca-eval.github.io/
GitHub: https://github.com/pkunlp-icler/PCA-EVAL
Introduction
In recent research, the term “embodied intelligence” often appears alongside “agent.” The goals of both pursuits share many similarities: they aim to develop an agent capable of perceiving the environment, possessing rich knowledge and cognitive reasoning abilities, and interacting with the environment through actions. These abilities can be collectively referred to as PCA (Perception, Cognition, Action). The current wave of research in embodied intelligence is closely linked to the popularity of large language models (LLMs) such as GPT-4. It has been found that these powerful language models exhibit astonishing capabilities in understanding text data, accumulating knowledge across various domains, and invoking various tools and APIs to complete tasks. Consequently, many researchers test and enhance agent capabilities in textual environments, such as ALFWorld’s text-based simulated rooms, text RPG games like Agent Town, and API evaluation frameworks like APIBench and RestGPT.
However, training an agent solely in textual environments is insufficient for creating one that can operate in the real world. The agent must possess the ability to perceive the physical properties of the real world, with visual perception being particularly critical. This is precisely what existing language models lack. So, how can we supplement the deficiencies of language models in visual and other multi-modal information? Many studies have chosen the “modal transformation” approach, which involves converting multi-modal information into text through other models or APIs, and then passing it to the language model for processing, allowing it to “see” the multi-modal world indirectly.
In this scenario, LLMs resemble a visually impaired sage who relies on others’ descriptions of the world to make decisions. The advantage of this method is that it can directly utilize powerful language models, and as the models are further enhanced, their effectiveness will continue to improve. However, this also brings significant drawbacks: during the conversion of multi-modal information into text, a large amount of information is lost.
For an intuitive example, suppose we show the agent a street view photo and ask it to determine what a driver should do next. If we provide the LLM with an object detection API and inform it that there are 14 cars in the image, GPT-4 might conclude that the road is congested and suggest slowing down. However, the reality may be that most of those 14 cars are in the opposite lane, and the driver should continue driving. This exposes a problem: the information obtained through the object detection API may lose spatial correlation, preventing the model from comprehensively perceiving the overall road conditions, leading to incorrect judgments. This is a typical example of information loss caused by modal transformation.

While modal transformation indeed accompanies information loss, why not directly utilize visual language models for end-to-end decision-making? In other words, can we input images and questions directly and let the model output the best action recommendation? Isn’t this a visual question answering (VQA) problem? But in reality, too young, too naive. Making behavioral decisions in embodied environments is far more complex than simple visual question answering or visual question answering using external knowledge (like VQA and OKVQA), primarily reflected in the following three aspects:
-
Deep Perception Capability: The model should possess the ability to analyze specific content in the image related to the question deeply, not just provide superficial descriptions of the image. For instance, in a traffic scenario, the model needs to accurately identify traffic signs; in a home environment, recognizing various household items is crucial.
-
Rich World Knowledge and Reasoning Ability: The model must not only have knowledge, such as traffic regulations and game rules, but also be able to effectively reason based on the perceived information.
-
Behavior Understanding and Selection: The model needs to clearly understand the meanings of various actions and be able to reason and select the most appropriate behavior based on the perceived information and existing knowledge.
Recently, discussions about “language models as world models” have become quite popular. In our view, only models equipped with the above three capabilities can truly approach the definition of a “world model,” rather than relying solely on textual knowledge. This means that the model we pursue should: 1) possess cross-domain visual perception capabilities; 2) have deep world knowledge and reasoning abilities; 3) effectively combine the above two capabilities to support decision-making.
Problems and Methods
In current research efforts, our biggest challenge is the lack of an appropriate evaluation framework for efficiently assessing LLM-based agents’ decision-making capabilities in multi-modal embodied environments. We have particularly focused on three areas closely related to embodied intelligence research: 1) autonomous driving; 2) household robot application scenarios; 3) open-world gaming contexts.
To this end, we have constructed and annotated datasets based on real-world traffic situations, household robot scenarios (ALFRED), and open-world game environments (Minecraft). Currently, each area has collected 100 samples and continues to grow. The following figure showcases some examples from each domain.
-
Traffic Domain

-
Household Robot Domain

-
Open World Game Domain

To accurately reflect the capabilities of an embodied intelligent agent and achieve trustworthy AI goals, we believe that evaluating such agents should encompass the three core dimensions of perception, cognition, and decision-making. Each annotated instance is a six-tuple consisting of:
As demonstrated in the video at the beginning of the article, we compared two types of methods: one is an end-to-end decision-making method based on visual language models; the other is based on language models. In the latter, we proposed a method called HOLMES, which simulates the strategy of a detective solving cases, continuously invoking APIs to collect multi-modal information and converting it into text for analysis by the language model to ultimately provide an answer.
In the end-to-end approach, we compared current SOTA visual language models, such as instructblip, mmicl, and the latest GPT-4 Vision model. In the HOLMES method, we compared the performance of vicuna, chatgpt-3.5, and gpt4. To evaluate the outputs of these models, we employed manual evaluation in the paper, scoring them precisely across the aforementioned three dimensions. Additionally, we provided an automatic evaluation tool based on LLM-EVAL to assess performance in perception, cognition, and behavior.
Experimental Results
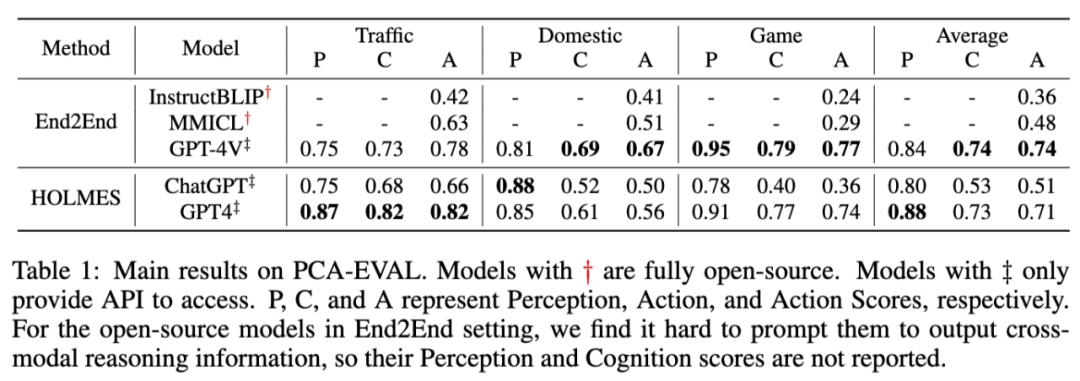
As shown in the table above, we observed significant performance differences between the current SOTA visual language models and OpenAI’s GPT-4 Vision model when it comes to end-to-end methods. This is reflected not only in the average action score difference of 26 points but also in a deeper layer: we found that current visual language models often fail to demonstrate a complete reasoning process in the decision-making tasks we set. In other words, these models cannot provide the reasoning behind their decisions and merely output an answer. This limitation persists even when we attempt various ways to optimize prompts. In contrast, GPT-4 Vision can cleverly combine image information with world knowledge, reasoning smoothly and arriving at final conclusions.
Impressively, GPT-4 Vision surpassed the HOLMES method based on GPT-4 in both cognition and action scores, demonstrating its enormous potential in the field of embodied intelligence. Nevertheless, in terms of perception, GPT-4 Vision’s performance still slightly lags behind GPT-4-HOLMES. We speculate this is primarily because the HOLMES method frequently invokes numerous expert-level APIs or directly extracts metadata from simulated environments. In certain specific scenarios, such as traffic sign recognition tasks, the information obtained through this method may be more accurate than GPT-4 Vision’s direct analysis of images.
Conclusion
Returning to the initial question: when stepping out of the realm of pure textual games into multi-modal environments, how does the agent perform? The answer is: GPT-4 Vision exhibits excellent end-to-end cross-modal reasoning and decision-making capabilities, while other open-source visual language models still have significant room for improvement. We sincerely invite everyone to evaluate our dataset and share the results.
For more details, please read our paper. We also welcome everyone to participate in discussions, star the project, or raise issues to share your valuable opinions. In the future, we plan to expand to larger datasets and more real interactive environments. If you are interested and willing to participate in the release of our future versions, please contact us!
GitHub: https://github.com/pkunlp-icler/PCA-EVAL
To join the technical discussion group, please add the AINLP assistant on WeChat (id: ainlp2)
Please note your specific direction + related technical points
About AINLP
AINLP is an interesting and AI-focused natural language processing community, specializing in sharing technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include LLM, pre-trained models, automated generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, job experience sharing, etc. Welcome to follow! To join the technical discussion group, please add the AINLP assistant on WeChat (id: ainlp2), noting your work/research direction + purpose of joining the group.
Having read this far, please share, like, or check one of the three options 🙏