
Author | hyk_1996
1. Difference in Effects of nn.Module.cuda() and Tensor.cuda()
Both the cuda() function can achieve memory migration from CPU to GPU for models and data, but their effects differ.
model = model.cuda()
model.cuda()
The above two lines achieve the same effect, which is memory migration for the model itself.
Unlike nn.Module, calling tensor.cuda() only returns a copy of this tensor object in GPU memory and does not change the tensor itself. Therefore, it must be reassigned, i.e., tensor=tensor.cuda().
model = create_a_model()
tensor = torch.zeros([2,3,10,10])
model.cuda()
tensor.cuda()
model(tensor) # Will raise an error
tensor = tensor.cuda()
model(tensor) # Runs normally
2. Different Calculation of Cumulative Loss in PyTorch 0.4
Taking the widely used pattern total_loss += loss.data[0] as an example. Before Python 0.4.0, loss was a Variable encapsulating a (1,) tensor, but in Python 0.4.0, loss is now a zero-dimensional scalar. Indexing a scalar is meaningless (it seems to raise an invalid index to scalar variable error). Using loss.item() can extract a Python number from the scalar. So it should be changed to:
total_loss += loss.item()
If the loss is not converted to a Python number during accumulation, there may be an increase in program memory usage. This is because the right side of the above expression was originally a Python float, but now it is a zero-dimensional tensor. Therefore, the total loss accumulates tensors and their gradient history, which can create a large autograd graph, consuming memory and computational resources.
3. Writing Device-Independent Code in PyTorch 0.4
# torch.device object used throughout this script
device = torch.device("cuda" if use_cuda else "cpu")
model = MyRNN().to(device)
# train
total_loss= 0
for input, target in train_loader:
input, target = input.to(device), target.to(device)
hidden = input.new_zeros(*h_shape) # has the same device & dtype as `input`
... # get loss and optimize
total_loss += loss.item()
# test
with torch.no_grad(): # operations inside don't track history
for input, target in test_loader:
...
4. Usage of torch.Tensor.detach()
The official description of detach() is as follows:
Returns a new Tensor, detached from the current graph.
The result will never require gradient.
Assuming there are models A and B, we need to use the output of A as the input to B, but during training, we only train model B. This can be done as follows:
input_B = output_A.detach()
This can break the gradient propagation between the two computation graphs, achieving the desired functionality.
5. ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm)
This error occurs when running training code in a docker on the server with a batch size set too large, and shared memory is insufficient (because docker limits shm). The solution is to set the num_workers of the Dataloader to 0.
6. Setting Parameters for Loss Functions in PyTorch
Taking CrossEntropyLoss as an example:
CrossEntropyLoss(self, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='elementwise_mean')
-
If reduce = False, then the size_average parameter is invalid, directly returning a vector form of loss, i.e., the loss corresponding to each element in the batch.
-
If reduce = True, then the loss returned is a scalar:
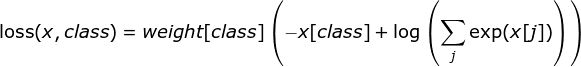
-
ignore_index: Select target values to ignore, making them not contribute to the input gradient. If size_average = True, then only the mean of the loss for non-ignored targets is calculated.
-
reduction: The optional parameters are: ‘none’ | ‘elementwise_mean’ | ‘sum’, as the name suggests, no explanation.
7. Reproducibility Issues in PyTorch
https://blog.csdn.net/hyk_1996/article/details/84307108
8. Multi-GPU Processing Mechanism
When using multiple GPUs, it should be remembered that PyTorch’s processing logic is:
1) Initialize the model on each GPU.
2) During forward propagation, distribute the batch across the GPUs for computation.
3) The obtained output is summarized on the main GPU, calculating the loss and backpropagating to update the weights on the main GPU.
4) Copy the model from the main GPU to other GPUs.
9. num_batches_tracked Parameter
Today, an error occurred when reading the model parameters:
KeyError: ‘unexpected key “module.bn1.num_batches_tracked” in state_dict’
After investigation, it was found that in PyTorch versions 0.4.1 and later, the BatchNorm layer added the num_batches_tracked parameter to count the number of batches processed during training. The source code is as follows (PyTorch 0.4.1):
if self.training and self.track_running_stats:
self.num_batches_tracked += 1
if self.momentum is None: # use cumulative moving average
exponential_average_factor = 1.0 / self.num_batches_tracked.item()
else: # use exponential moving average
exponential_average_factor = self.momentum
It can be seen that this parameter is related to the normalization calculation during training.
Therefore, we know that the error is caused by the inconsistency in the PyTorch versions used for training and testing (the differences around version 0.4.1). The specific solution is: if the model parameter (Orderdict format, easy to modify) is missing the num_batches_tracked variable, add it; if it is extra, remove it. A lazy approach is to set the strict parameter of load_state_dict to False, as shown below:
load_state_dict(torch.load(weight_path), strict=False)
It was also seen that some people directly modified the source code of PyTorch 0.4.1 to remove the num_batches_tracked parameter, which is highly discouraged.
10. NaN Loss During Training
Recently, a situation occurred where the loss became NaN during model training, which turned out to be a big pitfall. Just recording it for now.
Three possible reasons for gradients to become NaN:
1. Gradient Explosion. This means that the gradient values exceed the range and become NaN. Usually, reducing the learning rate, adding a BN layer, or performing gradient clipping can help solve this.
2. Loss Function or Network Design.For example, division by zero may occur, or some boundary conditions may lead to the function being non-differentiable, such as log(0) or sqrt(0).
3. Dirty Data.It can be helpful to check the input data beforehand to see if there are any NaN values.
To supplement the method for checking NaN data:
Note! Values like NaN or inf cannot be checked using == or is! For safety, use math.isnan() or numpy.isnan() uniformly.
import numpy as np
# Check if the input data has NaN
if np.any(np.isnan(input.cpu().numpy())):
print('Input data has NaN!')
# Check if the loss is NaN
if np.isnan(loss.item()):
print('Loss value is NaN!')
11. ValueError: Expected more than 1 value per channel when training
This error occurs when there is only one sample in the batch, and calling batch_norm will raise the following error:
raise ValueError('Expected more than 1 value per channel when training, got input size {}'.format(size))
There is no particularly good solution; before training, check if num_of_samples % batch_size leaves exactly one sample.
12. Hidden Bugs Caused by the weight_decay Item of the Optimizer
We all know that weight_decay refers to weight decay, which adds an L2 penalty term to the original loss, causing the model to tend to choose smaller weight parameters, thereby achieving regularization. However, I often overlook this item, leading to unexpected problems.
This time, the pitfall was as follows: when training a ResNet50, the upper layer part layer4 was temporarily unused, so there would be no gradient backpropagation. Therefore, I confidently passed all parameters of ResNet50 to the Optimizer for updates, thinking that layer4 should maintain its original weights. However, in reality, even though layer4 did not have gradient backpropagation, the effect of weight_decay still existed, causing the layer4 weights to decrease and approach zero. Later, when I needed to use layer4, I found the output was abnormal (close to zero), and only then did I notice this problem.
Although such situations may not be easy to encounter, it is still important to be cautious: weights that do not need to be updated should not be passed to the Optimizer to avoid unnecessary troubles.
The Programmer Da Bai account is a knowledge-sharing account created with my classmates from Harbin Institute of Technology and West Lake University, full of valuable content. I recommend everyone to follow it! Learning
