
Click the blue text above to follow us!


1 Basic Design Framework of CNN
-
Convolution layer extracts spacial information; -
Pooling layer reduces the resolution of images or feature maps, decreasing computational load and obtaining semantic information; -
Fully-connected (FC) layer regresses targets.
In the infinite possibilities of network architecture, even using neural architecture search (NAS) to explore can seem challenging. In recent developments of CNN architectures, common CNN architectures can be divided into three parts:
-
Stem: The input image is processed with a small number of convolutions, adjusting the resolution. -
Body: The main part of the network, which can be divided into multiple stages, usually each stage performs a resolution-reducing operation, internally consisting of one or more repeated combinations of building blocks (such as residual bottlenecks). -
Head: Uses the features extracted from the stem and body to perform predictions for the target task.
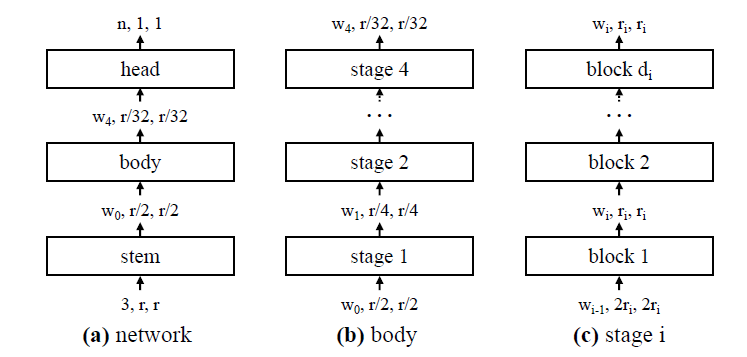
Not all CNNs follow this framework; it is merely a common framework.
Building blocks are also a commonly used term, referring to small network combinations that are repeatedly used, such as the residual block and residual bottleneck block in ResNet, or the depthwise convolution block and inverted bottleneck block in MobileNet.
In addition to the above, there are many other details that can be adjusted in designing convolutional neural networks: designs for shortcuts (like FPN), adjustments to receptive fields, etc. However, to avoid lengthy complexity, these will not be discussed in this article.
2 Scale An Existing Structure
-
Depth D (depth): Represents the number of stacked building blocks or convolution layers from input to output.
-
Width W (width): Represents the width of the feature map output from the building block or convolution layer (number of channels or filters).
-
Resolution R (resolution): Represents the length and width of the feature map tensor output from the building block or convolution layer.
Regarding depth, we believe that deeper networks can capture more complex features and bring better generalization ability. However, overly deep networks can still be difficult to train due to gradient vanishing, even with the use of skip connections and batch normalization.
In terms of width, generally, wider networks can capture more fine-grained information and are easier to train. However, wide and shallow networks struggle to capture complex features.
In terms of resolution, high resolution undoubtedly provides more detailed information; in most papers, this is essentially a good way to enhance performance. The evident downside is the computational load, and adjustments to the receptive fields are needed for localization issues.
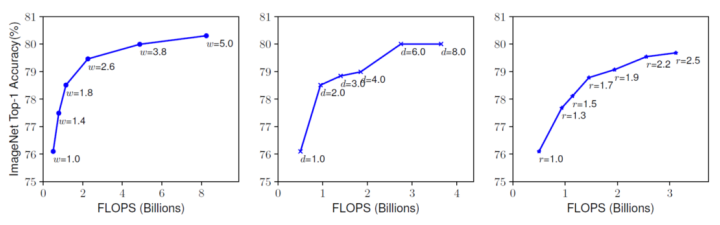
Based on the experiments of single enhancements, the authors of EfficientNet suggest that depth, width, and resolution should be considered together. However, under a certain computational resource setting, determining the adjustment ratio among these three is an open question.

-
Search Space: Defines the basic elements of the network that can be selected (such as convolution, batch normalization) and the adjustable contents (such as kernel size, filter number).
-
Search Strategy: Defines the method of searching, such as reinforcement learning, which is one of the common methods.
-
Performance Estimation: Defines how to evaluate the quality of an architecture, such as accuracy, computational load, etc.
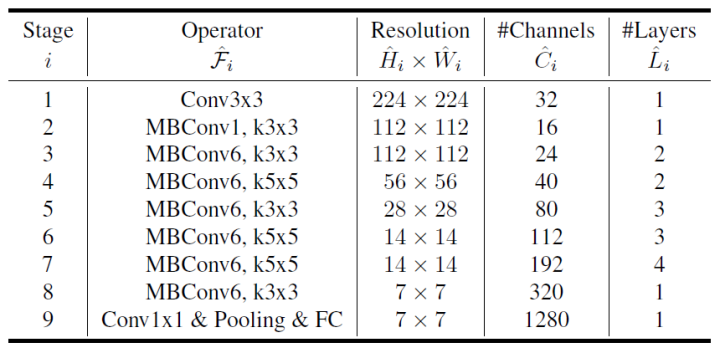
EfficientNet is arguably the strongest network architecture for mobile devices (using CPU computation) as of 2020. EfficientNet adopts the search space of MnasNet but changes the estimation of computational resources from latency to FLOPs, controlling the trade-off between accuracy and FLOPs using a hyperparameter w for a given network m and target computational load T, optimizing Accuracy(m)*[FLOPs(m)/T]^w.
Generally, the process of manually designing a network is as follows: start with a rough network concept, hypothesize an adjustable range (design space, termed search space in NAS), and conduct numerous experiments within this space to find directions that yield positive benefits. At this point, we continue experiments based on this direction, which is equivalent to converging to a smaller design space. This iterative process is like moving from A to B to C as shown in the diagram below.
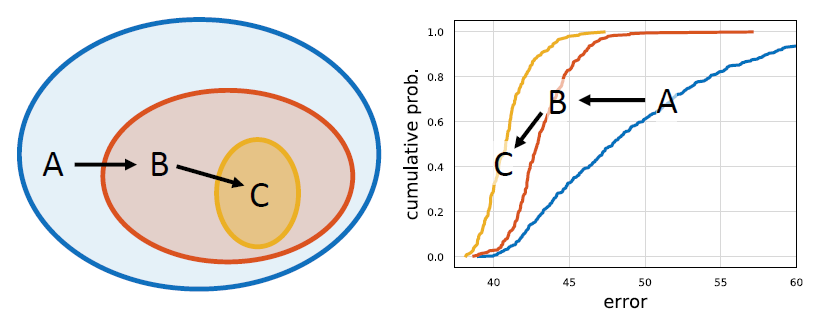
Some may feel that neural networks are black boxes, and many insights are forced explanations for publishing papers. However, without these insights, I would truly not know how to modify a network.
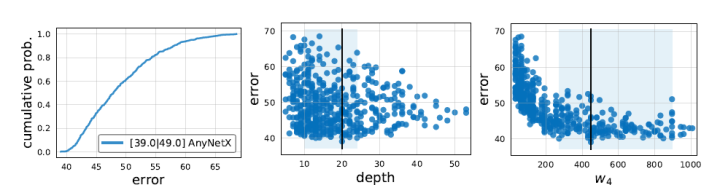
RegNet is a network discovered through analyzing EDF in the paper “Designing Network Design Spaces.” Below, I share the authors’ process of searching the RegNet design space, giving insight into the design process of a network architecture.
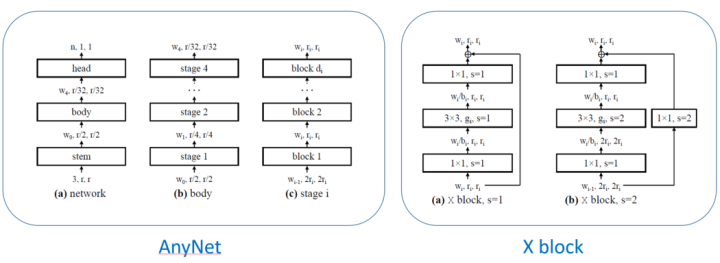
AnyNetX inherits much of the spirit of CNNs, serving as a template similar to ResNet, dividing the network into stem, body, and head, focusing the search process on the body. The body is divided into four stages, starting with an input resolution of 224×224, with each stage halving the resolution at the beginning. For controllable parameters, each stage has four degrees of freedom: block count (b), block width (w), bottleneck ratio (b), and width of group convolution (g), totaling 16 degrees of freedom.
-
The bottleneck ratio and the width of group convolution have nearly identical results when analyzed across stages, suggesting that sharing parameters across stages does not affect outcomes.
-
Width and block count (depth) significantly improve performance as stage increases, indicating this is a good design direction.
After simplification, the remaining design space for AnyNetX consists of six degrees of freedom, which is RegNetX. The six dimensions include: model depth d, bottleneck ratio b, number of group convolutions g, target slope for network width increase w_a, width increase interval multiplier w_m, and initial width w_0.
The width increase interval multiplier (width multiplier) and target slope for network width increase (width slope) may sound convoluted; I have translated them based on their meanings. Even looking at the original text can be confusing, but the practical meaning is as follows: the target slope is a fixed value defining how each block’s width should grow, while the interval multiplier is a convenient integer multiplier that can be manipulated to ensure each block’s width does not fluctuate too erratically or to keep repeated blocks within each stage at the same width.
By analyzing some popular network architectures, the paper further restricts the design space of RegNetX: bottleneck ratio b = 1, block depth 12 ≤ d ≤ 28, and the basic multiplier for width increase w_m ≥ 2. To further optimize model inference latency, RegNetX imposes additional restrictions on parameter count and activation number: assuming the number of FLOPs is f, restrict activation count #act ≤ 6.5 sqrt(f), and restrict parameter count #param ≤ 3.0 + 5.5*f.
I believe that many of the current settings in NAS (such as search space) still rely on human wisdom, which means NAS must first borrow from many handcrafted insights. On the other hand, humans also attempt to gain insights from architectures discovered by NAS. Thus, NAS and handcrafted design can currently be said to complement each other.
The advantage of NAS lies in finding the most advantageous architecture for a task, but this strong purpose also brings uncertainty in generalization (could it lead to overfitting architectures). This is why the EfficientNet paper not only demonstrates the power of its architecture on ImageNet but also spends additional time showcasing its transferability to other classification datasets. However, even if transferability to other datasets is feasible, transferring to other tasks may present another challenge.
In fact, EfficientNet has already demonstrated strong capabilities in other visual tasks, whether in object detection or semantic segmentation, although this evaluation is based on the premise of