DeepSeek has introduced a new MoE model, DeepSeek-V2, with a total parameter count of 236 billion and 21 billion active parameters. Although it is still a bit short of GPT-4 levels, it can be considered the strongest open-source MoE model available. Staying true to its open-source spirit, the accompanying technical report is also packed with valuable insights, so today we will focus on a technical interpretation.
Understanding Huanfang
Although this is a technical interpretation, I particularly want to talk about Huanfang, the parent company of DeepSeek.
First Encounter
The first time I heard about DeepSeek was during my exploration of scaling laws, a concept proposed by OpenAI in 2020. In 2022, DeepMind’s Chinchilla initiated best practices, guiding the development of large models. I believe DeepSeek is one of the most serious followers among domestic companies. After reading the paper on DeepSeek’s LLM model, I felt that this is a rare company with a strong technical pursuit.
Out of curiosity, I searched for information about the company online. Established in 2023, it is an independent company spun off from Huanfang Quantitative, focusing on foundational research in artificial intelligence. At first glance, it seems unbelievable that a quantitative firm would venture into large models, making it hard to see the connection behind this move. Large models are derived from NLP technologies, while quantitative analysis and NLP are two completely unrelated fields. However, as I learned more about Huanfang’s history, particularly the background of its founder, Wu Wenfeng, I suddenly found clarity and even admiration. Wu Wenfeng studied artificial intelligence at Zhejiang University in 2008 and, after graduation, started a venture in the quantitative field without any prior experience, driven by the idea that AI could change the world. After six years of development, Huanfang became a leading enterprise in the quantitative field. I do not fully understand the concept of quantitative analysis, but can you think of a cooler entrepreneurial story, especially for those who believe in the transformative power of technology?
What is even more commendable is that Huanfang has consistently invested in AI. Inspired by OpenAI in 2020, they began quietly accumulating computing power, a rare foresight in the domestic tech community at the time. A decade of honing a skill, remaining true to their original intentions, and always believing in progress—this may be the reason for Huanfang’s success. Therefore, when they later established DeepSeek as an independent company to invest in generative AI, it was a natural progression, as the company’s DNA is filled with a pursuit of technology and AI.
Reflections
The era of large models leading artificial intelligence is built on three cornerstones: computing power, data, and talent. The first two are merely hard conditions, while the true decisive factor lies in talent, which is the core driving force behind advancing AGI. What characteristics should this talent possess? If we focus on people, we can identify many skills and qualities, but does having enough talent guarantee a lead in the large model race? Strategic planning and talent management may be even more important, depending on the leader’s will or the company’s DNA, which more bluntly means assessing the leader’s determination and resolve.
The development of large models in China has gone through last year’s hundred-model battle, with hundreds of billions in funding. Currently, the first tier is nearing GPT-4 levels. 2024 is anticipated to be the dawn of AI applications, with major companies and startups actively seeking application scenarios or integrating them with their business. This may be a necessary step, but one can sense the investors’ impatience. No one knows what the real killer applications will look like in the future. At such times, the spirit of patiently continuing foundational innovation becomes precious and may be the fastest way to approach AGI.
This is one aspect I admire about Huanfang. Like the name of their large model, DeepSeek, which means deep exploration, their motivation for this endeavor is simply to satisfy curiosity, and they happen to have enough resources to invest.
DeepSeek MoE Model
It should be around December 2023, after Mixtral sparked a wave of MoE enthusiasm, that DeepSeek released their MoE paper and model. Initially, I thought this was a follow-up piece, but after in-depth study, I found it filled with valuable insights, undoubtedly the result of long-term technical accumulation.
DeepSeek-V2’s MoE technology is largely consistent with the paper released last December, with two key points: fine-grained experts and shared experts. I will skip the details and try to analyze the motivations behind these approaches.
Fine-Grained Experts
When I first saw the DeepSeek MoE paper, I was surprised by their remarkably good experimental results, which far exceed normal MoE gains given the same number of active and total parameters. This is primarily due to the fine-grained expert technology, which the paper states allows each expert to focus on specific domain knowledge, leading to a more flexible expert combination.

In fact, as shown in the mixtral image, a closer look reveals that each expert focuses on tokens that are not limited to a specific domain but resemble roles at a grammatical level. In a normal Dense network, all knowledge is stored in the hidden layer space of the FFN, with different types of knowledge residing in different dimensional activation combinations. In MoE, similar knowledge at the grammatical level is placed in a separate space, allowing for better differentiation.
Moreover, from the perspective of scaling laws, the formula for MoE scaling law is as follows:
To explain the variables used: represents the number of experts, and represents the parameter count of the corresponding base model.
Substituting N=21B, E=8 (DeepSeek-V2 configuration, not considering fine-grained), observing the derivatives of loss concerning N and E reveals that the derivative for N is -0.074, while for E it is -0.025. The benefit of increasing N is evidently greater, but increasing N also raises training and inference costs, while the fine-grained method effectively increases E while keeping N and total parameter count unchanged.
Shared Expert
When MoE first appeared, it was believed that topk > 1 was necessary for better routing learning. Since multiple experts are always activated, the idea behind shared experts is to make some experts fixed activations to learn some general knowledge. This approach has two additional benefits: first, efficient computation, and second, upcycling.
During training, MoE models spend a significant amount of time on communication, as experts are distributed across different devices, leading to memory consumption from the large total parameter count. One solution is to perform subsequent computations while the communication core is active, thus hiding some communication time. The computation of shared experts is independent of MoE communication, allowing it to use communication hiding for more efficient computation than ordinary MoE structures.
In implementation, shared experts often merge multiple shared expert parameters into a larger MLP computation. During upcycling, the parameters of the Dense network are used to initialize MoE. Given that the MLP layers of fine-grained experts are generally small, each expert can only use part of the MLP parameters. The ideal partitioning method is to split different types of information from Dense into different experts to meet their own needs. However, finding such methods is difficult. The existence of shared experts allows Dense parameters to be loaded without partitioning, thus retaining the original capabilities of Dense to a greater extent. The reason for upcycling instead of training from scratch is simple: MoE training is too slow.
Device-Limited Routing
Considering the dependence of MoE models on communication capabilities during training, the pressure is placed on the hardware and framework layers. DeepSeek V2 proposes the use of Device-Limited Routing to reduce overall communication pressure, but I have not fully understood the implementation details, and I have raised an issue with the official team, hoping to clarify this point in the future.
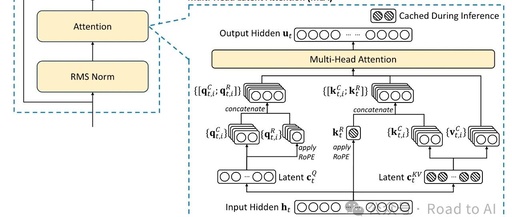
MLA: Multi-Head Latent Attention
The schematic diagram from the paper is as follows:
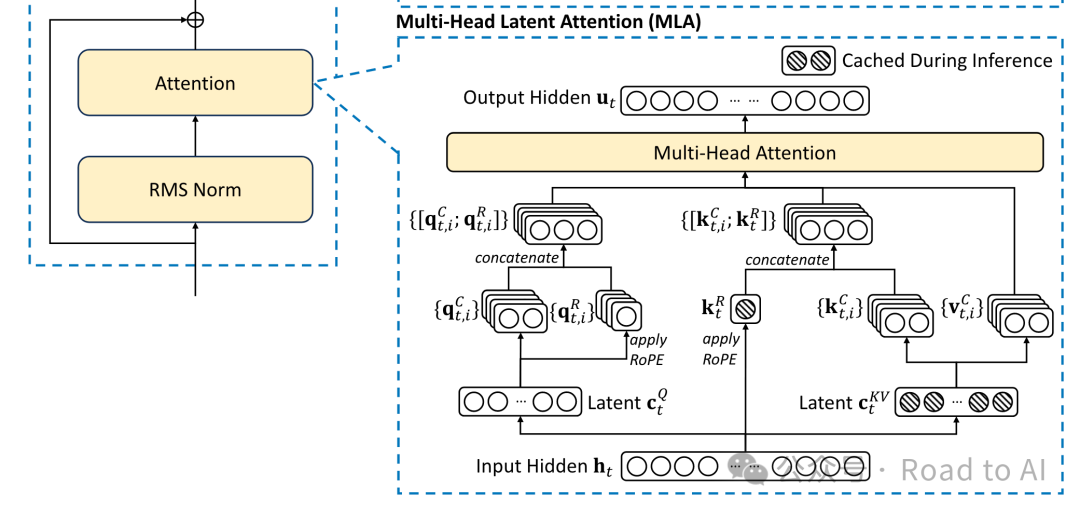
The overall understanding is that MLA is an enhanced version of MQA, capable of achieving the same inference speed while delivering better performance. Here’s a brief introduction to how it works:
-
In MHA, KV is mapped to the same dimension as Q, so a large amount of KV needs to be retained during inference. MLA maps KV to a smaller dimension and then maps it back to the same dimension as Q. Since QK and OV belong to a hidden matrix during the attention computation, the upward mapping matrix can be absorbed into it, ensuring that during inference, only a smaller dimension of KV values needs to be retained. -
Since RoPE applies different matrix transformations to the QK vectors of tokens at different positions, this disrupts the matrix fusion operation in MLA. DeepSeek-V2’s approach is to perform RoPE separately on a smaller dimension of QK. This means that MLA retains some of the MHA calculations; whether performing RoPE in a smaller dimension impacts the results still needs further validation.
Conclusion
This concludes the interpretation of DeepSeek-V2, which is indeed a technical report filled with valuable insights. It is clear that DeepSeek is innovatively addressing problems. Innovating within non-research institutions is challenging due to the need to integrate scenarios, which limits the technologies that can be applied and increases the number of factors to consider. Innovation often arises spontaneously, not through deliberate arrangements or teaching, and it also requires a relaxed environment to boldly engage in aimless experimentation. Innovation is high-risk, expensive, and inefficient, but I am pleased to see a company that maintains such a hardcore technical style.