Abstract
We propose DeepSeek-V2, a powerful Mixture of Experts (MoE) language model characterized by economical training and efficient inference. It has a total of 236 billion parameters, with 21 billion parameters activated per token, and supports 128K tokens of context length. DeepSeek-V2 adopts innovative architectures such as Multi-head Latent Attention (MLA) and DeepSeekMoE. MLA ensures efficient inference by significantly compressing the key-value (KV) cache into latent vectors, while DeepSeekMoE trains strong models at economical costs through sparse computations. Compared to DeepSeek 67B, DeepSeek-V2 shows significantly stronger performance while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing maximum generation throughput by up to 5.76 times. We pre-trained DeepSeek-V2 on a high-quality multi-source corpus consisting of 8.1 trillion tokens and further performed supervised fine-tuning (SFT) and reinforcement learning (RL) to fully unleash its potential. Evaluation results show that even with only 21 billion activated parameters, DeepSeek-V2 and its chat version achieve top performance among open-source models. Model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V2.
Introduction
In recent years, large language models (LLMs) have undergone rapid development, bringing us closer to the dawn of artificial general intelligence (AGI). Generally, as the number of parameters increases, the intelligence of LLMs tends to improve, enabling them to exhibit remarkable capabilities across various tasks. However, this improvement comes at the cost of greater training computational resources and potential reductions in inference throughput. These limitations pose significant challenges to the widespread adoption and utilization of LLMs. To address this issue, we introduce DeepSeek-V2, a powerful open-source Mixture of Experts (MoE) language model characterized by economical training and efficient inference through innovative Transformer architecture. It is equipped with a total of 236 billion parameters, with 21 billion parameters activated per token, and supports 128K tokens of context length.
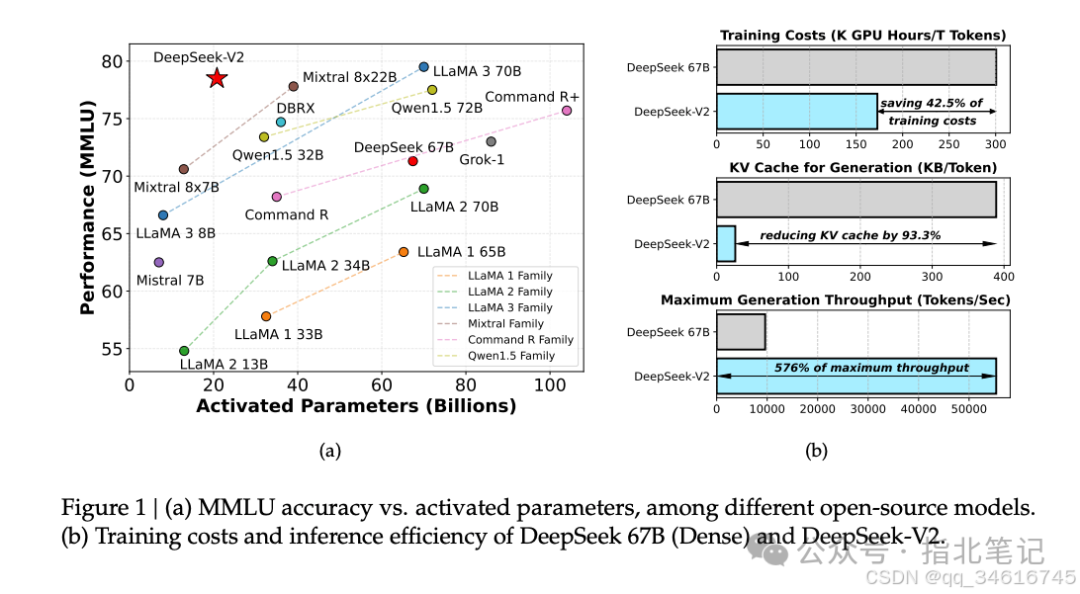
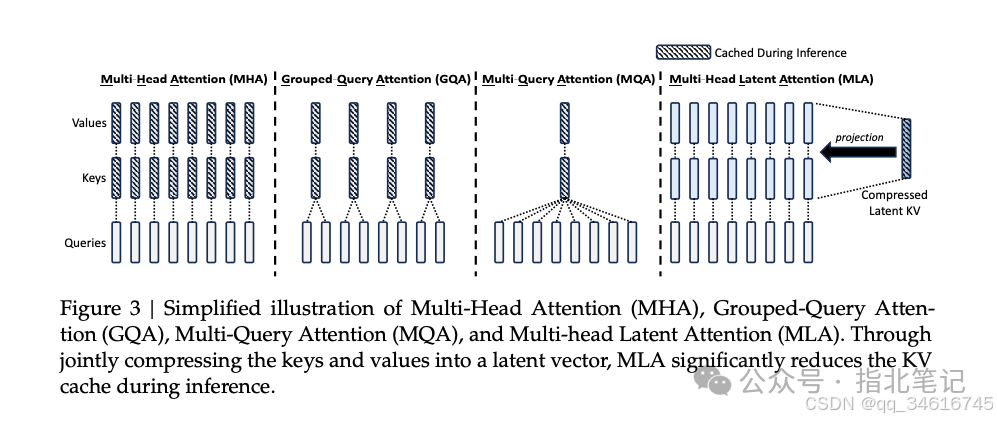
We optimized the attention module and feedforward network (FFN) in the Transformer framework using our proposed Multi-head Latent Attention (MLA) and DeepSeekMoE. (1) In the context of the attention mechanism, the Key-Value (KV) cache of Multi-Head Attention (MHA) poses a significant barrier to LLM inference efficiency. Various methods have been explored to address this issue, including Grouped-Query Attention (GQA) and Multi-Query Attention (MQA). However, these methods often compromise performance when attempting to reduce KV cache. To achieve the best of both worlds, we introduce MLA, an attention mechanism equipped with low-rank key-value joint compression. Empirical evidence shows that MLA outperforms MHA while significantly reducing KV cache during inference, thus improving inference efficiency. (2) For the feedforward network (FFN), we follow the DeepSeekMoE architecture, which employs fine-grained expert partitioning and shared expert isolation to enhance the potential for expert specialization. Compared to traditional MoE architectures like GShard, the DeepSeekMoE architecture demonstrates significant advantages, enabling us to train strong models at economical costs. When we use expert parallelism during training, we also design complementary mechanisms to control communication overhead and ensure load balancing. By combining these two techniques, DeepSeek-V2 achieves powerful performance (Figure 1(a)), economical training costs, and efficient inference throughput (Figure 1(b)).
We built a high-quality multi-source pre-training corpus consisting of 8.1 trillion tokens. Compared to the corpus used in DeepSeek 67B (our previous version), this corpus has a larger volume of data, especially Chinese data, and higher data quality. We first pre-trained DeepSeek-V2 on the complete pre-training corpus. Then, we collected 1.5 million conversations across various fields including mathematics, coding, writing, reasoning, and safety, performing supervised fine-tuning (SFT) on DeepSeek-V2 Chat. Finally, we followed DeepSeekMath, adopting Group Relative Policy Optimization (GRPO) to further align the model with human preferences and generate DeepSeek-V2 Chat (RL).
We evaluated DeepSeek-V2 on extensive benchmarks in both English and Chinese and compared it with representative open-source models. Evaluation results indicate that even with only 21 billion activated parameters, DeepSeek-V2 achieves top performance among open-source models, becoming the most powerful open-source MoE language model. Figure 1(a) highlights that DeepSeek-V2 achieves top performance on MMLU with only a small number of activated parameters. Furthermore, as shown in Figure 1(b), compared to DeepSeek 67B, DeepSeek-V2 saves 42.5% in training costs, reduces KV cache by 93.3%, and improves maximum generation throughput by up to 5.76 times. We also evaluated DeepSeek-V2 Chat (SFT) and DeepSeek-V2 Chat (RL) on open benchmarks. Notably, DeepSeek-V2 Chat (RL) achieved a length control win rate of 38.9 on AlpacaEval 2.0, a total score of 8.97 on MT-Bench, and a total score of 7.91 on AlignBench. English open conversation evaluations indicate that DeepSeek-V2 Chat (RL) exhibits top performance among open-source chat models. Additionally, evaluations on AlignBench show that in Chinese, DeepSeek-V2 Chat (RL) outperforms all open-source models, even surpassing most closed-source models.
To facilitate further research and development of MLA and DeepSeekMoE, we also released a smaller model equipped with MLA and DeepSeekMoE, DeepSeek-V2-Lite. It has a total of 15.7 billion parameters, with 2.4 billion parameters activated per token. Detailed descriptions of DeepSeek-V2-Lite can be found in Appendix B.
In the remainder of this paper, we first provide a detailed description of the DeepSeek-V2 model architecture (Section 2). Subsequently, we introduce our pre-training efforts, including training data construction, hyperparameter settings, infrastructure, long context extension, and evaluations of model performance and efficiency (Section 3). After that, we showcase our efforts in calibration, including supervised fine-tuning (SFT), reinforcement learning (RL), and finally summarize our conclusions, discussing the current limitations of DeepSeek-V2 and outlining our future work (Section 5).
Architecture
Overall, DeepSeek-V2 remains within the Transformer architecture (Vaswani et al., 2017), where each Transformer block consists of an attention module and a feedforward network (FFN). However, for the attention module and FFN, we have designed and adopted innovative architectures. For attention, we designed MLA, which eliminates the bottleneck of key-value caching during inference time by utilizing low-rank key-value joint compression, thus supporting efficient inference. For FFN, we adopted the DeepSeekMoE architecture, a high-performance MoE architecture that can train strong models at economical costs. Figure 2 illustrates the architecture of DeepSeek-V2, and we will detail MLA and DeepSeekMoE in this section. For other minor details (e.g., layer normalization and activation functions in FFN), unless specified, DeepSeek-V2 follows the settings of DeepSeek 67B.
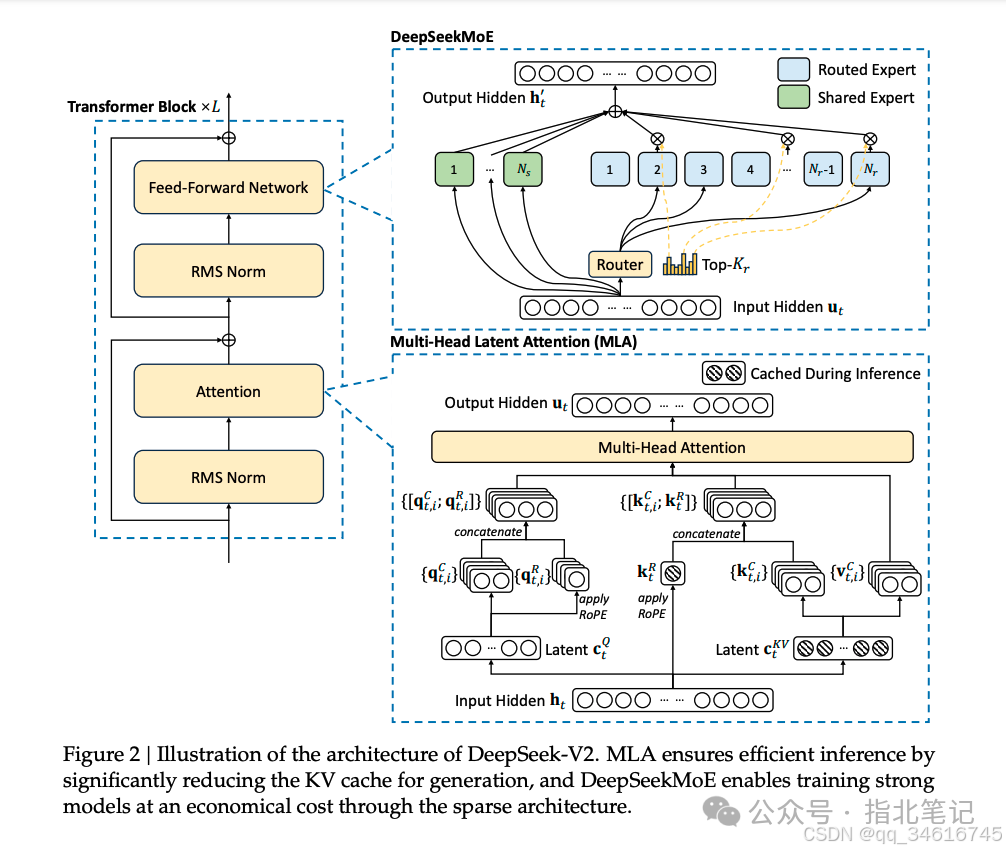
Multi-Head Latent Attention: Boosting Inference Efficiency
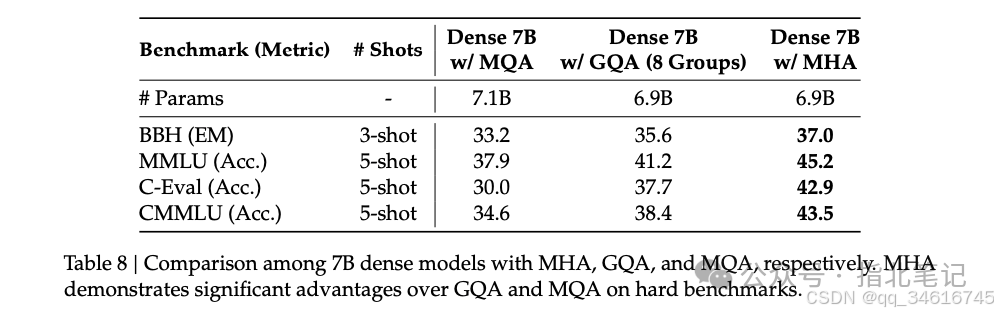
Traditional Transformer models typically use Multi-Head Attention (MHA), but during generation, its heavy Key-Value (KV) cache becomes a bottleneck limiting inference efficiency. To reduce KV cache, Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) have been proposed. They require smaller KV caches, but their performance does not match that of MHA (we provide an ablation study of MHA, GQA, and MQA in Appendix D.1).
For DeepSeek-V2, we designed an innovative attention mechanism called Multi-head Latent Attention (MLA). MLA employs low-rank key-value joint compression, outperforming MHA while requiring significantly less KV cache. We will outline its architecture below and provide a comparison between MLA and MHA in Appendix D.2.
Preliminaries: Standard Multi-Head Attention


Low-Rank Key-Value Joint Compression

Decoupled Rotary Position Embedding



Comparison of Key-Value Cache
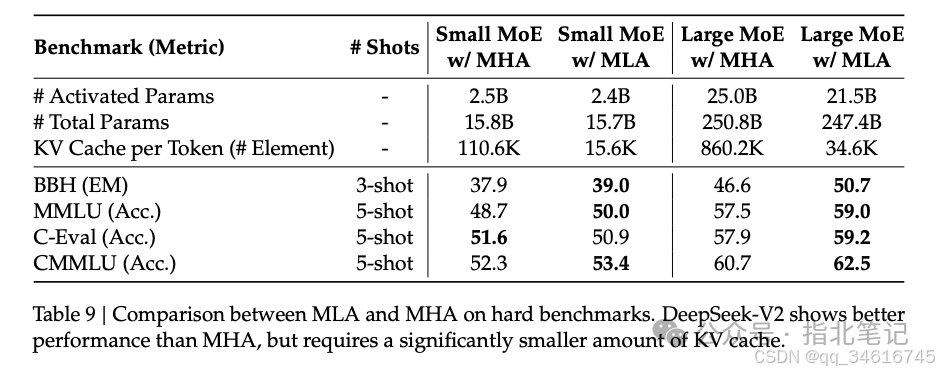
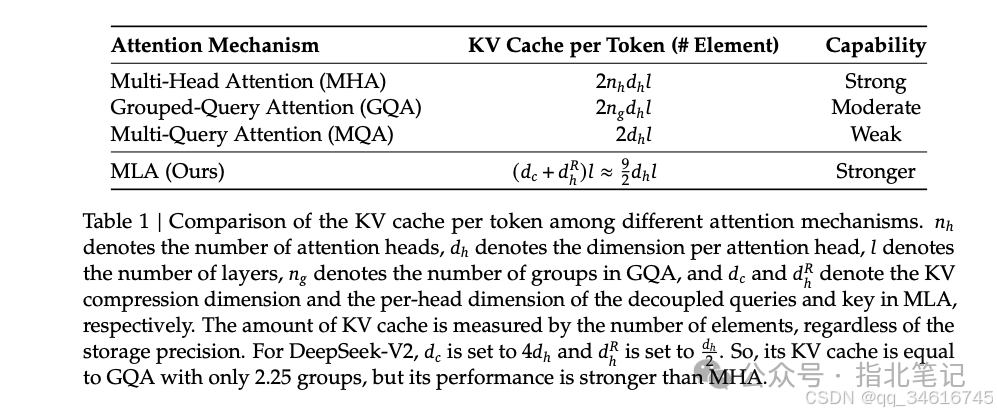
We present a comparison of the KV cache per token across different attention mechanisms in Table 1. MLA requires only a small amount of KV cache, comparable to GQA, with only 2.25 groups, yet achieves stronger performance than MHA.
DeepSeekMoE: Training Strong Models at Economical Costs
Basic Architecture
For FFN, we adopted the DeepSeekMoE architecture. DeepSeekMoE has two key ideas: partitioning experts into finer granularity to improve expert specialization and more accurate knowledge acquisition; isolating some shared experts to alleviate knowledge redundancy among routing experts. With the same number of activated and total expert parameters, DeepSeekMoE can outperform traditional MoE architectures like GShard significantly.

Device-Limited Routing
We designed a device-limited routing mechanism to constrain the communication costs associated with MoE. When employing expert parallelism, routing experts are distributed across multiple devices. For each token, its communication frequency associated with MoE is proportional to the number of devices covered by its target expert. Since the expert partitioning in DeepSeekMoE is fine-grained, the number of activated experts can be large, leading to higher communication costs if expert parallelization is adopted.
For DeepSeek-V2, in addition to simple top-K routing expert selection, we also ensure that the target experts for each token are distributed across at most 𝑀 devices. Specifically, for each token, we first select the 𝑀 devices of the experts with the highest affinity scores. Then, we perform top-K selection among the experts on these 𝑀 devices. In practice, we found that when 𝑀 is greater than or equal to 3, device-limited routing can achieve performance comparable to unrestricted top-K routing.
Auxiliary Loss for Load Balance
We considered load balancing in the automatic learning routing strategy. First, load imbalance increases the risk of routing collapse, preventing some experts from being adequately trained and utilized. Second, when using expert parallelism, unbalanced loads reduce computational efficiency. During the training of DeepSeek-V2, we designed three auxiliary losses for controlling expert-level load balance, device-level load balance, and communication balance.
Expert-Level Balance Loss. We use expert-level balance loss to mitigate the risk of routing collapse: 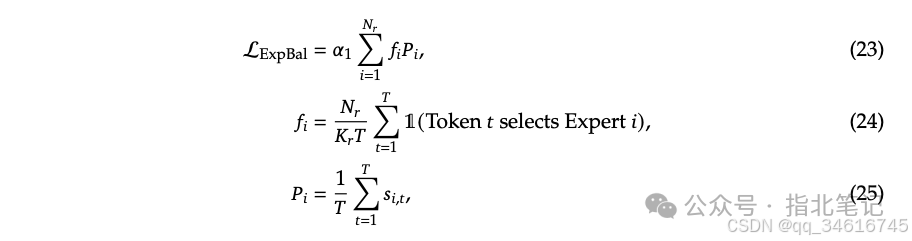 where 𝛼1 is a hyperparameter called the expert-level balance factor; is the metric function; 𝑇 represents the number of tokens in the sequence, and 𝐾𝑟 represents the number of activated routing experts.
where 𝛼1 is a hyperparameter called the expert-level balance factor; is the metric function; 𝑇 represents the number of tokens in the sequence, and 𝐾𝑟 represents the number of activated routing experts.
Device-Level Balance Loss. In addition to expert-level balance loss, we also designed a device-level balance loss to ensure balanced computation across different devices. During the training of DeepSeek-V2, we grouped all routing experts and deployed each group on a single device. The device-level balance loss is calculated as follows:
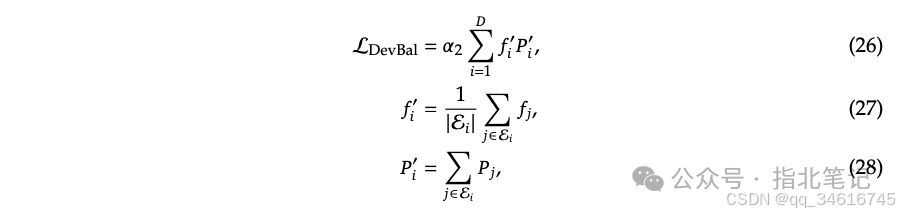
where 𝛼2 is a hyperparameter called the device-level balance factor.
Communication Balance Loss. Finally, we introduce a communication balance loss to ensure balanced communication across devices. While the device-limited routing mechanism ensures that the sending communication of each device is bounded, if one device receives more tokens than others, the actual communication efficiency can still be affected. To alleviate this issue, we designed the following communication balance loss:
 where 𝛼3 is a hyperparameter called the communication balance factor. The device-limited routing mechanism works by ensuring that each device transmits at most hidden states. Meanwhile, using communication balance loss encourages each device to receive approximately hidden states from other devices. The communication balance loss ensures balanced exchange of information between devices, enhancing communication efficiency.
where 𝛼3 is a hyperparameter called the communication balance factor. The device-limited routing mechanism works by ensuring that each device transmits at most hidden states. Meanwhile, using communication balance loss encourages each device to receive approximately hidden states from other devices. The communication balance loss ensures balanced exchange of information between devices, enhancing communication efficiency.
Token-Dropping Strategy
Although balance losses aim to encourage balanced loads, it is important to acknowledge that they cannot guarantee strict load balance. To further reduce computational waste caused by unbalanced loads, we introduced a device-level token dropping strategy during training. This method first calculates the average computational budget for each device, meaning that the capacity factor for each device equals 1.0. Then, inspired by Riquelme et al. (2021), we drop tokens with the lowest affinity scores on each device until the computational budget is reached. Additionally, we ensure that tokens belonging to approximately 10% of the training sequences are never dropped. This way, we can flexibly decide whether to drop tokens during inference based on efficiency requirements while ensuring consistency between training and inference.
Pre-Training
Experimental Setups
Data Construction
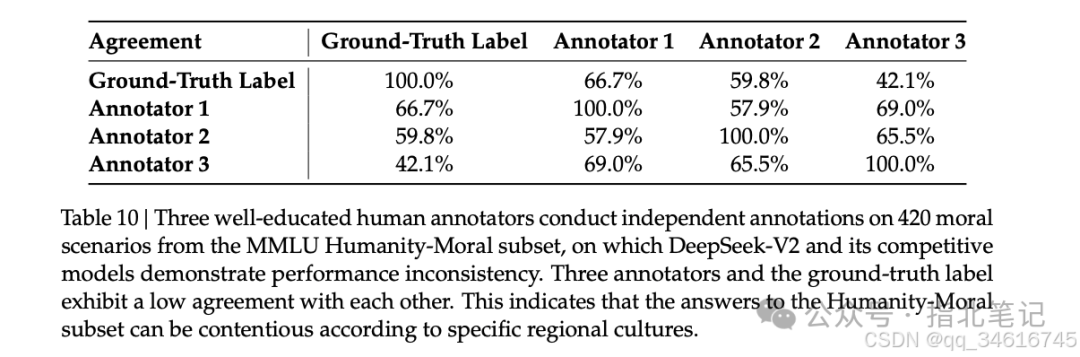
While maintaining the same data processing stages as DeepSeek 67B (DeepSeek-AI, 2024), we expanded the data volume and improved data quality. To enlarge our pre-training corpus, we explored the potential of internet data and optimized our cleaning process, restoring a substantial amount of data that was wrongly deleted. Furthermore, we incorporated more Chinese data, aiming to better utilize the corpus available on the Chinese internet. In addition to data volume, we also focused on data quality. We enriched the pre-training corpus with high-quality data from various sources while improving our quality-based filtering algorithms. The improved algorithm ensures that a large amount of useless data is removed while retaining most valuable data. Moreover, we filtered out controversial content from the pre-training corpus to mitigate data bias from specific cultural regions. A detailed discussion of the impact of this filtering strategy can be found in Appendix E.
We employed the same tokenizer as DeepSeek 67B, which is based on a byte-level byte pair encoding (BBPE) algorithm, with a vocabulary size of 100K. Our tokenized pre-training corpus contains 8.1 trillion tokens, with approximately 12% more Chinese tokens than English tokens.
Hyper-Parameters
Model Hyper-Parameters. We set the number of Transformer layers to 60, and the hidden dimensions to 5120. All learnable parameters are randomly initialized with a standard deviation of 0.006. In MLA, we set the number of attention heads to 128, with each head’s dimension set to 128. The KV compression dimension is set to 512, and the query compression dimension 𝑑’𝑐 is set to 1536. For decoupled queries and keys, we set the dimension of each head to 64. Following Dai et al. (2024), we replaced all FFNs except for the first layer with MoE layers. Each MoE layer consists of 2 shared experts and 160 routing experts, with each expert having an intermediate hidden dimension of 1536. Among the routing experts, each token activates 6 experts. Additionally, low-rank compression and fine-grained expert partitioning affect the output scale of a layer. Therefore, in practice, we use an additional RMS Norm layer after compressing the latent vector, and multiply an extra scaling factor at the width bottleneck (i.e., the compressed latent vector and the intermediate hidden states of the routing experts) to ensure stable training. In this configuration, DeepSeek-V2 has a total of 236 billion parameters, with 21 billion parameters activated per token.
Training Hyper-Parameters. We use the AdamW optimizer, with hyperparameters set to 𝛽1 = 0.9, 𝛽2 = 0.95, weight_decay = 0.1. The learning rate is scheduled using a warmup-and-step-decay strategy (DeepSeek-AI, 2024). Initially, in the first 2K steps, the learning rate increases linearly from 0 to a maximum value. Subsequently, after training approximately 60% of the tokens, the learning rate is multiplied by 0.316, and after training approximately 90% of the tokens, the learning rate is multiplied again by 0.316. The maximum learning rate is set to 2.4 × 10−4, and the gradient clipping norm is set to 1.0. We also utilize a batch size scheduling strategy, where the batch size gradually increases from 2304 to 9216 during the training of the first 225 billion tokens, and then remains at 9216 for the remaining training. We set the maximum sequence length to 4K, and trained DeepSeek-V2 on 8.1 trillion tokens. We employed pipeline parallelism to deploy different layers of the model across different devices, with routing experts uniformly deployed across 8 devices (𝐷= 8). For device-limited routing, each token is sent to at most 3 devices (𝑀= 3). For balance losses, we set 𝛼1 to 0.003, 𝛼2 to 0.05, and 𝛼3 to 0.02. We employed the token-dropping strategy during training but dropped no tokens for evaluation.
60 layers = 1(FFN) + 59(MoE), 1 + 59 x (1 + 8) = 532 cards, 532/8=(532+7)/8 = 67 H800.
Infrastructures
DeepSeek-V2 is trained based on the HAI-LLM framework (High-flyer, 2023), an efficient lightweight training framework developed in-house by our engineers. It employs 16-way zero-bubble pipeline parallelism (Qi et al., 2023), 8-way expert parallelism (Lepikhin et al., 2021), and ZeRO-1 data parallelism (Rajbhandari et al., 2020). Considering the relatively few activated parameters in DeepSeek-V2 and to save activation memory, some operators are recomputed, allowing training without the need for tensor parallelism, thus reducing communication overhead. Additionally, to further improve training efficiency, we overlap the computation of shared experts with all-to-all communication for expert parallelism. We also customized faster CUDA kernels for communication, routing algorithms, and fused linear computations across different experts. Furthermore, MLA is optimized based on an improved version of FlashAttention-2 (Dao, 2023).
We conducted all experiments on a cluster equipped with NVIDIA H800 GPUs. Each node in the H800 cluster contains 8 GPUs, and nodes are interconnected via NVLink and NVSwitch. Inter-node communication is facilitated by InfiniBand.
Long Context Extension
After the initial pre-training of DeepSeek-V2, we extended the default context window length from 4K to 128K using YaRN (Peng et al., 2023). YaRN is specifically applied to decouple shared keys, as it is responsible for carrying RoPE (Su et al., 2024). For YaRN, we set the scale 𝑠 to 40, set to 1, set to 32, and set the target maximum context length to 160K. With these settings, we expect the model to respond well to a context length of 128K. Unlike the initial YaRN, due to our different attention mechanism, we adjusted the length scaling factor to tune the computation of attention entropy. The calculation formula is aimed at minimizing perplexity.
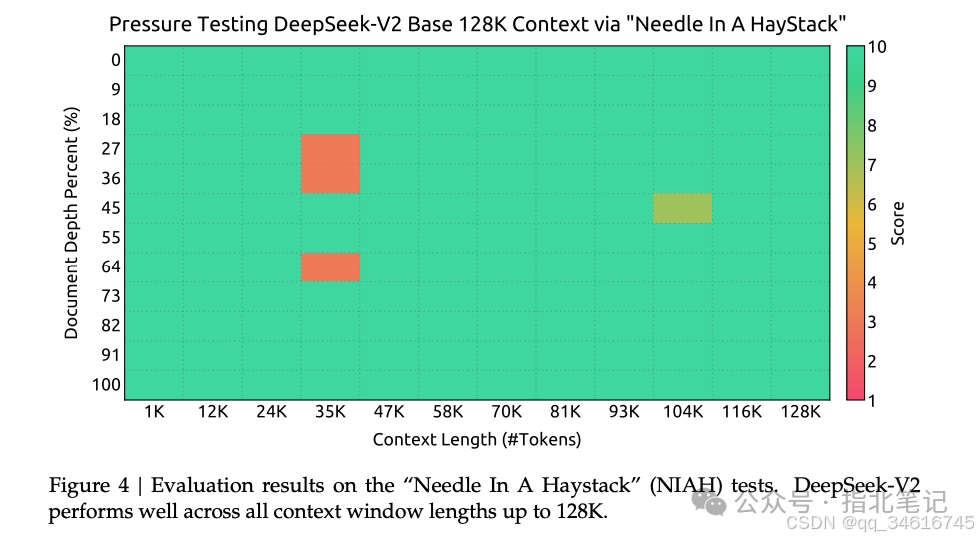
We further trained the model for 1000 steps, with a sequence length of 32K, and a batch size of 576 sequences. Although training was conducted only at a sequence length of 32K, the model still exhibits robustness at a context length of 128K. As shown in Figure 4, the results of the “needle in a haystack” (NIAH) test indicate that DeepSeek-V2 performs well across all context window lengths up to 128K.
YaRN is specifically applied to decouple shared keys. YaRN training only requires 1000 steps, with a sequence length of 3.2W, and a batch size of 576.
Evaluations
DeepSeek-V2 was pre-trained on a bilingual corpus, so we evaluated it on a series of benchmarks in English and Chinese. Our evaluations are based on our internal evaluation framework integrated into our HAI-LLM framework. The included benchmark categories are listed below, with the underlined benchmarks being Chinese benchmarks:
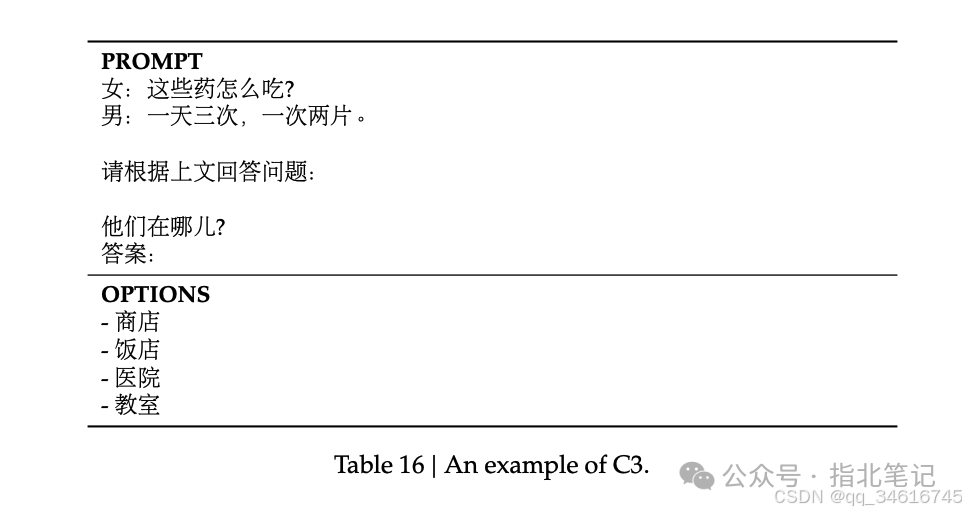
 Following the previous work of DeepSeek-AI (DeepSeek-AI, 2024), we adopted a perplexity-based evaluation method for datasets such as HellaSwag, PIQA, WinoGrande, RACE-Middle, RACE-High, MMLU, ARC-Easy, ARC-Challenge, CHID, C-Eval, CMMLU, C3, and CCPM, and a generation-based evaluation method for datasets such as TriviaQA, NaturalQuestions, DROP, MATH, GSM8K, HumanEval, MBPP, CRUXEval, BBH, ageval, CLUEWSC, CMRC, and CMath. Additionally, we performed language-modeling-based evaluations on Pile-test, using bits per byte (BPB) as a metric to ensure fair comparisons between models with different tokenizers.
Following the previous work of DeepSeek-AI (DeepSeek-AI, 2024), we adopted a perplexity-based evaluation method for datasets such as HellaSwag, PIQA, WinoGrande, RACE-Middle, RACE-High, MMLU, ARC-Easy, ARC-Challenge, CHID, C-Eval, CMMLU, C3, and CCPM, and a generation-based evaluation method for datasets such as TriviaQA, NaturalQuestions, DROP, MATH, GSM8K, HumanEval, MBPP, CRUXEval, BBH, ageval, CLUEWSC, CMRC, and CMath. Additionally, we performed language-modeling-based evaluations on Pile-test, using bits per byte (BPB) as a metric to ensure fair comparisons between models with different tokenizers.
To intuitively summarize these benchmarks, we also provide the evaluation format for each benchmark in Appendix G.











Evaluation Results
In Table 2, we compare DeepSeek-V2 with several representative open-source models, including DeepSeek 67B (DeepSeek-AI, 2024) (our previous version), Qwen1.5 72B (Bai et al., 2023), LLaMA3 70B (AI@Meta, 2024), and Mixtral 8x22B (Mistral, 2024). We evaluated all these models using our internal evaluation framework and ensured they share the same evaluation settings. Overall, with only 21 billion activated parameters, DeepSeek-V2 significantly outperforms DeepSeek 67B across almost all benchmarks and achieves top performance among open-source models.
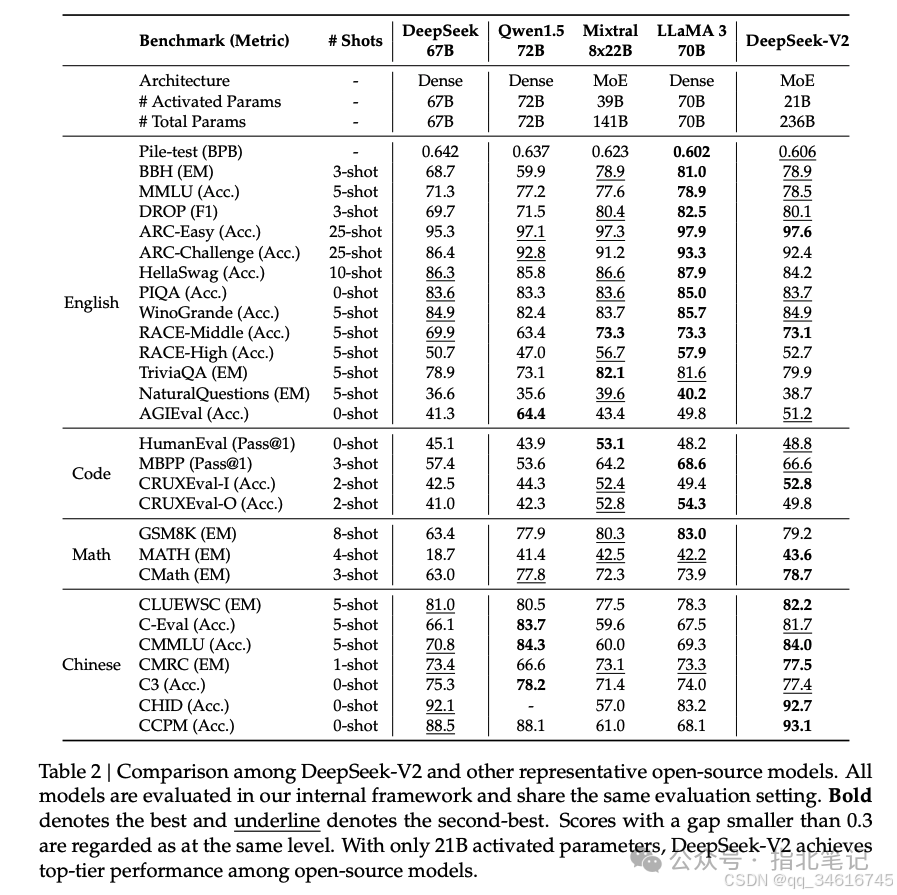
Additionally, we conducted detailed comparisons of DeepSeek-V2 with open-source versions one by one. (1) Compared to Qwen1.5 72B (another model supporting both Chinese and English), DeepSeek-V2 demonstrates overwhelming advantages in most English, coding, and mathematics tests. In Chinese benchmark tests, Qwen1.5 72B performs better on multi-topic selection tasks, while DeepSeek-V2 performs comparably or even better in other tests. Note that for the CHID benchmark, the tokenizer of Qwen1.5 72B encounters errors in our evaluation framework, so we left the CHID score of Qwen1.5 72B blank. (2) Compared to Mixtral 8x22B, except for TriviaQA, NaturalQuestions, and HellaSwag closely related to English common knowledge, DeepSeek-V2’s English performance is comparable to or better than Mixtral 8x22B. Notably, DeepSeek-V2 outperforms Mixtral 8x22B on MMLU. In coding and mathematics benchmark tests, DeepSeek-V2’s performance is comparable to Mixtral 8x22B. Since Mixtral 8x22B has not been specifically trained on Chinese data, its Chinese capabilities lag far behind those of DeepSeek-V2. (3) Compared to LLaMA3 70B, DeepSeek-V2 was trained on less than a quarter of the English tokens. Therefore, we acknowledge that DeepSeek-V2 still has some gaps in basic English capabilities compared to LLaMA3 70B. However, even with fewer training tokens and activated parameters, DeepSeek-V2 still demonstrates comparable coding and mathematical capabilities to LLaMA3 70B. Furthermore, as a bilingual model, DeepSeek-V2 significantly outperforms LLaMA3 70B in Chinese benchmark tests.
Lastly, it is worth mentioning that some previous studies (Hu et al., 2024) included SFT data during the pre-training phase, while DeepSeek-V2 has never been exposed to SFT data during pre-training.
Training and Inference Efficiency
Training Costs. Since DeepSeek-V2 activates fewer parameters per token and requires fewer FLOPs compared to DeepSeek 67B, training DeepSeek-V2 is theoretically more economical than training DeepSeek 67B. Although training MoE models incurs additional communication overhead, with our operator and communication optimizations, DeepSeek-V2 can achieve relatively high model FLOPs utilization (MFU). In our actual training on the H800 cluster, for every trillion tokens trained, DeepSeek 67B requires 300.6K GPU hours, while DeepSeek-V2 only requires 172.8K GPU hours, which means that sparse DeepSeek-V2 can save 42.5% of training costs compared to dense DeepSeek 67B.
Inference Efficiency. To effectively deploy DeepSeek-V2 services, we first convert its parameters to FP8 precision. Additionally, we performed KV cache quantization to further compress DeepSeek-V2, averaging each element in its KV cache down to 6 bits. Thanks to MLA and these optimizations, the deployed DeepSeek-V2 requires less KV cache than DeepSeek 67B, allowing it to serve larger batch sizes. We evaluated the generation throughput of DeepSeek-V2 based on the prompt and generation length distribution of the deployed DeepSeek 67B service. On a single node with 8 H800 GPUs, DeepSeek-V2’s generation throughput exceeds 50K tokens per second, which is 5.76 times the maximum generation throughput of DeepSeek 67B. Furthermore, DeepSeek-V2’s prompt input throughput exceeds 100K tokens per second.
Alignment
Supervised Fine-Tuning
Building on our previous research (DeepSeek-AI, 2024), we managed a instruction tuning dataset that includes 1.5 million instances, where 1.2 million instances are for helpfulness, and 300 thousand instances are for safety. Compared to the initial version, we improved data quality to mitigate hallucination responses and enhance writing quality. We fine-tuned DeepSeek-V2 for 2 epochs, with a learning rate set to 5 × 10−6.
SFT used 1.5 million data, fine-tuned for 2 epochs, learning rate .
For the evaluation of DeepSeek-V2 Chat (SFT), we primarily included generation-based benchmarks alongside several representative multiple-choice tasks (MMLU and ARC). We also evaluated DeepSeek-V2 Chat (SFT) using instruction-following evaluation (IFEval) (Zhou et al., 2023), employing instant-level loose accuracy as the metric. Furthermore, we used LiveCodeBench (Jain et al., 2024) questions from September 1, 2023, to April 1, 2024, to evaluate the chat model. In addition to standard benchmarks, we further evaluated our model on open conversation benchmarks, including MT-Bench (Zheng et al., 2023), AlpacaEval 2.0 (Dubois et al., 2024), and AlignBench (Liu et al., 2023). For comparison, we also evaluated Qwen1.5 72B Chat, LLaMA-3-70B Instruct, and Mistral-8x22B Instruct in our evaluation framework and settings. For DeepSeek 67B Chat, we directly referenced our previously published evaluation results.
Reinforcement Learning
To further unleash the potential of DeepSeek-V2 and align it with human preferences, we performed reinforcement learning (RL) to adjust its preferences.
Reinforcement Learning Algorithm. To save training costs for reinforcement learning, we adopted Group Relative Policy Optimization (GRPO), which forgoes the critic model usually of the same size as the policy model, instead estimating the baseline from group scores. Specifically, **for each question 𝑞, GRPO samples a group of outputs from the old policy, and then optimizes the policy model by maximizing the following objective**: 
where {o_1, o_2, …, o_G}= Policy(q), r_i = Critic(q, o_i). The clipping in the first term ensures that the scores of the new and old policies are bounded within a range, i.e., the value of the first term (min) is bounded. The second term ensures that the change is not too drastic, i.e., the distance from to is small, used for stabilizing training convergence; when equals , the second term is zero.
Training Strategy. In our preliminary experiments, we found that reinforcement learning training on inference data (such as coding and mathematics prompts) exhibits unique characteristics distinct from general data training. For example, our model’s mathematical and coding capabilities can continuously improve over longer training steps. Therefore, we adopted a two-stage reinforcement learning training strategy, first performing inference alignment, and then executing human preference alignment. In the first inference alignment stage, we trained the reward model on code and mathematics reasoning tasks and optimized the policy model using feedback:

Two-stage RL training. The first stage trains RM for math and code. RL can train for more epochs, improving performance.
In the second stage of human preference matching, we adopted a multi-reward framework that obtains rewards from a helpful reward model, a safety reward model, and a rule-based reward model for the final reward of the response
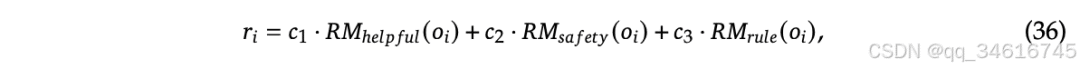 where 𝑐1𝑐2𝑐3 are the corresponding coefficients.
where 𝑐1𝑐2𝑐3 are the corresponding coefficients.
The second stage trains helpful, safety, and rule-based three RMs for alignment of general data. The number of training epochs may not be many.
To obtain reliable reward models that play a key role in reinforcement learning training, we carefully collected preference data and carefully conducted quality filtering and proportion adjustments. We obtained code preference data based on compiler feedback and mathematical preference data based on ground truth labels. For reward model training, we initialized the reward model with DeepSeek-V2 Chat (SFT) and trained it using point-wise or pair-wise loss. In our experiments, we observed that reinforcement learning training can fully tap into and activate our model’s potential, enabling it to select the correct and satisfactory answers from possible responses.
Data quality, quality, quality. RL corresponds to preference selection, or discriminative training, or metric learning, etc.
Optimizations for Training Efficiency. Performing RL training on very large models imposes high demands on the training framework. It requires careful engineering optimizations to manage GPU memory and RAM pressure while maintaining fast training speeds. To achieve this goal, we implemented the following engineering optimizations. (1) First, we proposed a hybrid engine that employs different parallel strategies for training and inference to achieve higher GPU utilization. (2) Second, we utilized large-batch vLLM (Kwon et al., 2023) as our inference backend to accelerate inference speeds. (3) Third, we carefully designed a scheduling strategy to unload the model to the CPU and load the model back to the GPU, achieving near-optimal balance between training speed and memory consumption.
Evaluation Results
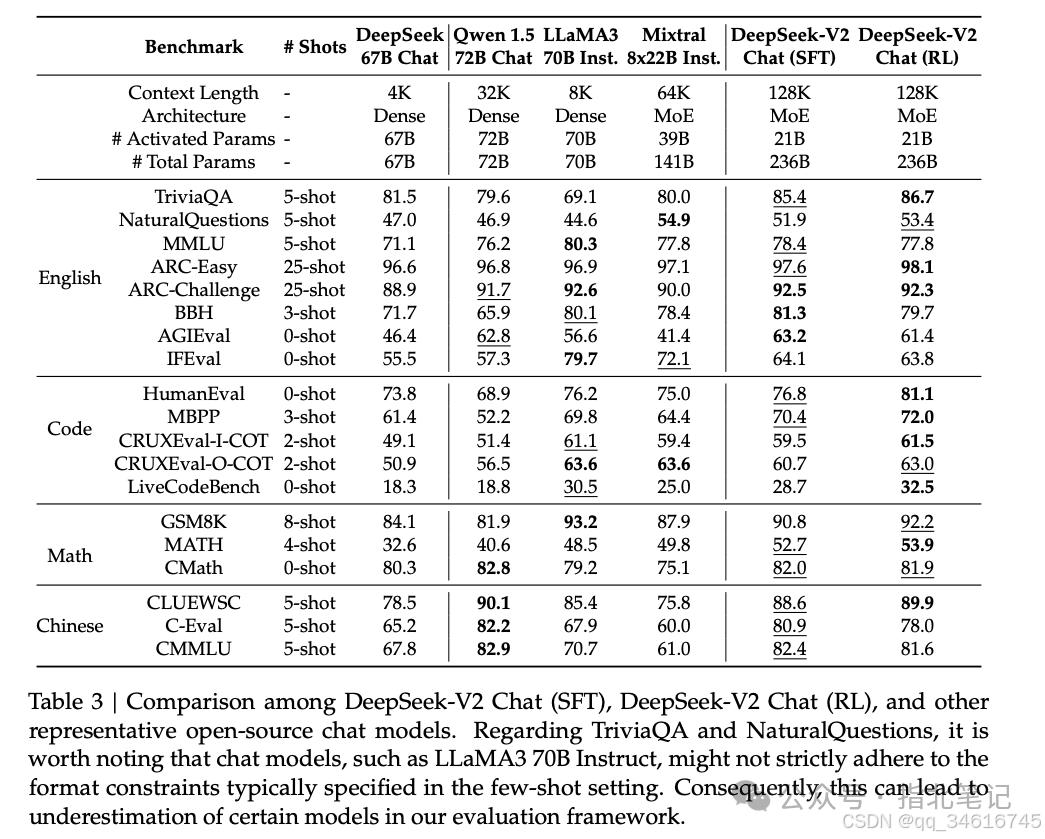
Evaluations on Standard Benchmarks. First, we evaluated DeepSeek-V2 Chat (SFT) and DeepSeek-V2 Chat (RL) on standard benchmarks. Notably, compared to the base version, DeepSeek-V2 Chat (SFT) exhibited substantial improvements in GSM8K, MATH, and HumanEval evaluations. This progress can be attributed to our SFT data, which contains a considerable amount of math and code-related content. Furthermore, DeepSeek-V2 Chat (RL) further improved performance on math and code benchmarks. We present more code and math computations in Appendix F.
As for comparisons with other models, we first compared DeepSeek-V2 Chat (SFT) with Qwen1.5 72B Chat, finding that DeepSeek-V2 Chat (SFT) outperformed Qwen1.5 72B Chat in almost all English, math, and code benchmarks. In Chinese benchmark tests, DeepSeek-V2 Chat (SFT) scored slightly lower than Qwen1.5 72B Chat on multi-topic multiple-choice tasks, consistent with the performance observed for their base versions. Compared to the state-of-the-art open-source MoE model (Mixtral 8x22B instruction), DeepSeek-V2 Chat (SFT) demonstrated better performance on most benchmarks, except for NaturalQuestions and IFEval. Additionally, compared to the state-of-the-art open-source model LLaMA3 70B Chat, DeepSeek-V2 Chat (SFT) exhibited similar performance in code and math-related benchmark tests. LLaMA3 70B Chat performed better on MMLU and IFEval, while DeepSeek-V2 Chat (SFT) excelled in Chinese tasks. Ultimately, compared to DeepSeek-V2 Chat (SFT), DeepSeek-V2 Chat (RL) further improved performance in math and coding tasks. These comparisons highlight the advantages of DeepSeek-V2 Chat across different domains and languages relative to other language models.
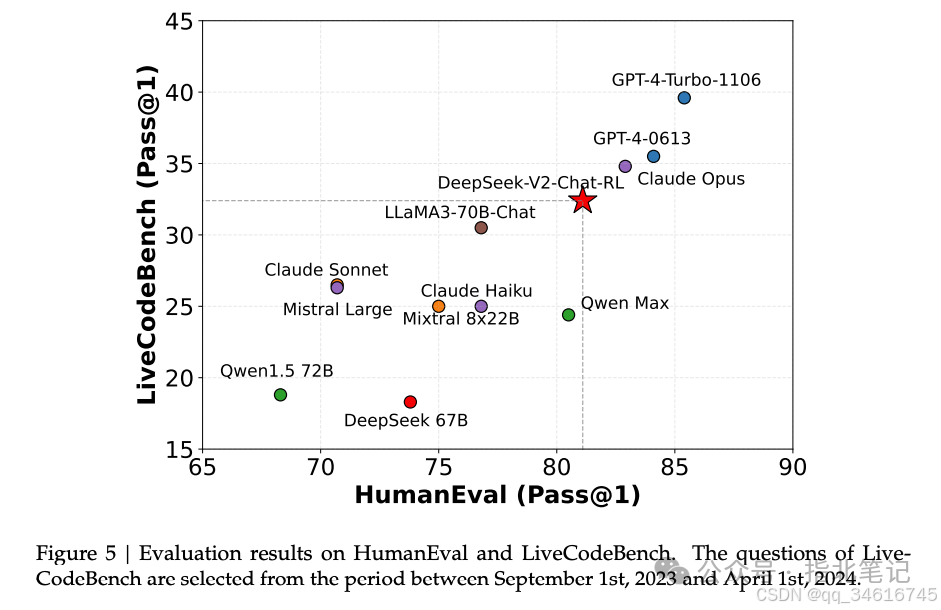
Evaluations on Open-Ended Generation. We continue to conduct additional evaluations of our model on open-ended conversation benchmarks. For English open-ended conversation generation, we used MT-Bench and AlpacaEval 2.0 as benchmarks. The evaluation results shown in Table 4 indicate that DeepSeek-V2 Chat (RL) has a significant performance advantage over DeepSeek-V2 Chat (SFT). This result demonstrates the effectiveness of our reinforcement learning training in achieving improvements in consistency. Compared to other open-source models, DeepSeek-V2 Chat (RL) outperformed both Mistral 8x22B instruction and Qwen1.5 72B Chat in both benchmark tests. In comparison to LLaMA3 70B instruction, DeepSeek-V2 Chat (RL) demonstrated competitive performance on MT-Bench and significantly outperformed LLaMA3 70B on AlpacaEval 2.0. These results highlight the strong performance of DeepSeek-V2 Chat (RL) in generating high-quality and contextually relevant responses, especially in instruction-based dialogue tasks.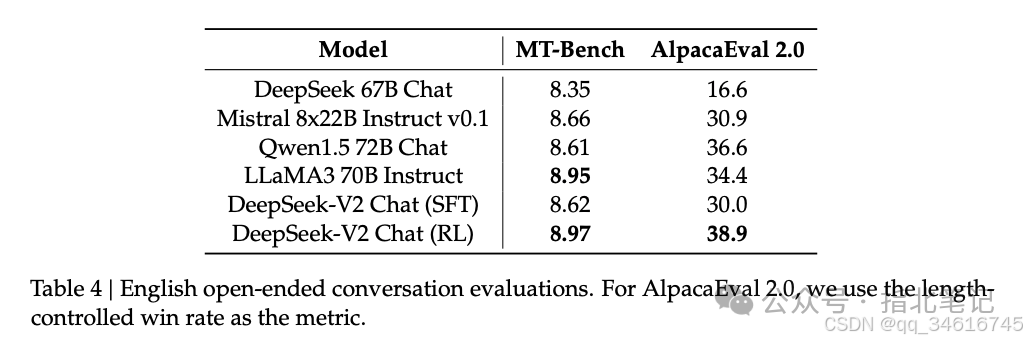
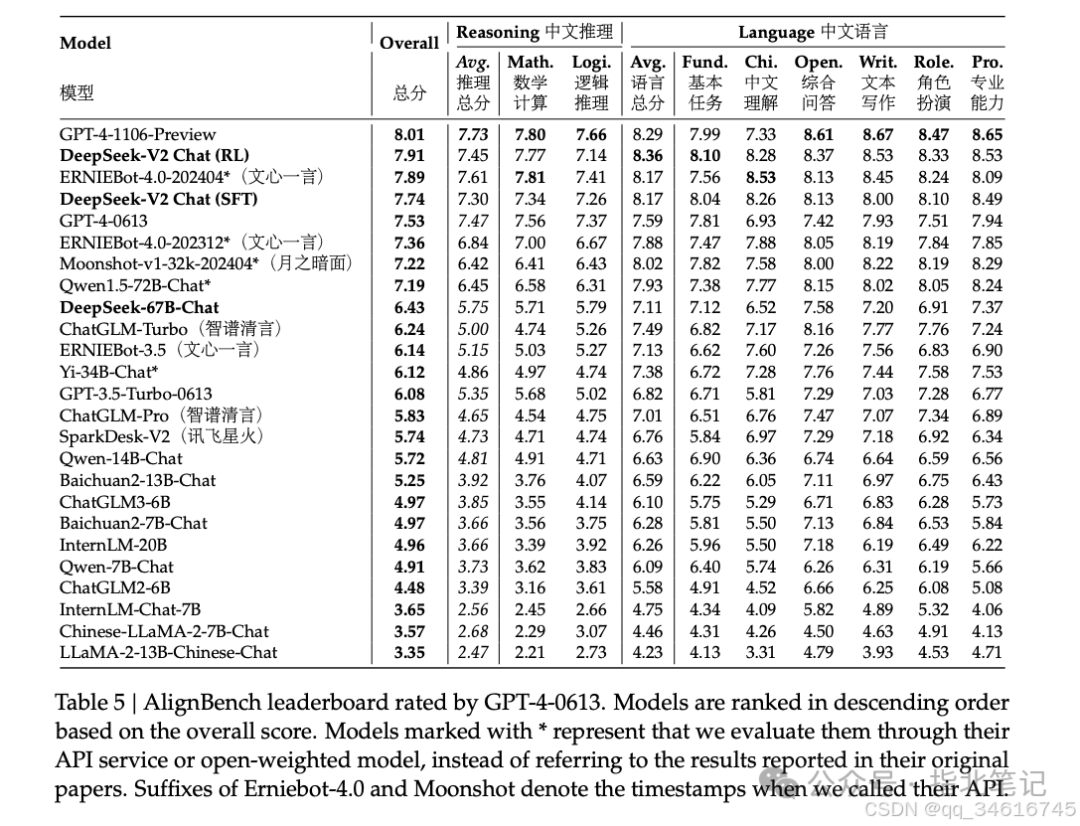
Furthermore, we also evaluated the open-ended generation capability of DeepSeek-V2 Chat (RL) based on AlignBench. As shown in Table 5, DeepSeek-V2 Chat (RL) exhibits slight advantages over DeepSeek-V2 Chat (SFT). Notably, DeepSeek-V2 Chat (SFT) significantly surpasses all open-source Chinese models. In terms of Chinese reasoning and language capabilities, it clearly outperforms the second-best open-source model Qwen1.5 72B Chat. Additionally, both DeepSeek-V2 Chat (SFT) and DeepSeek-V2 Chat (RL) outperform GPT-4-0613 and ERNIEBot 4.0, solidifying our model’s position among the top LLMs supporting Chinese. Specifically, DeepSeek-V2 Chat (RL) demonstrates outstanding performance in Chinese language understanding, surpassing all models including GPT-4-Turbo-1106-Preview. On the other hand, the reasoning capabilities of DeepSeek-V2 Chat (RL) still lag behind those of large models like Erniebot-4.0 and gpt-4.
Discussion
Amount of SFT Data. The necessity surrounding a large SFT corpus has been a topic of heated debate. Previous works (Young et al., 2024; Zhou et al., 2024) argue that fewer than 10K SFT data instances are sufficient to yield satisfactory results. However, in our experiments, we observed a significant drop in performance on the IFEval benchmark when using fewer than 10K instances. One possible explanation is that language models require a certain amount of data to develop specific skills. While the required amount of data may decrease as the model size increases, it cannot be completely eliminated. Our observations emphasize that providing sufficient data is crucial for equipping LLMs with the necessary capabilities. Furthermore, the quality of SFT data is also critical, especially for tasks involving writing or open-ended questions.
Different models require different amounts of data, generally larger models require less, but it cannot be completely eliminated. Different capabilities or skills require different amounts of data, generally needing a certain amount to work, but the specifics need to be explored. Data quality is critical, especially for tasks involving collaboration or open-ended questions.
Alignment Tax of Reinforcement Learning. During the human preference alignment process, we observed significant performance enhancements on open-ended generation benchmarks, in terms of ratings from AI and human evaluators. However, we also noticed a phenomenon of “alignment tax,” where the alignment process negatively impacts performance on certain standard benchmarks (e.g., BBH). To mitigate the alignment tax, during the RL stage, we made significant efforts in data processing and improved training strategies, ultimately achieving a tolerable trade-off between performance on standard benchmarks and open-ended benchmarks. Exploring how to align the model with human preferences without affecting its overall performance is a valuable direction for future research.
Online Reinforcement Learning. In our preference alignment experiments, we found that online methods significantly outperform offline methods. Thus, we invested considerable effort in implementing an online RL framework to calibrate DeepSeek-V2. The conclusions regarding online and offline preference alignment may differ in various contexts, and we will reserve more in-depth comparisons and analyses for future work.
Conclusion, Limitation, and Future Work
In this paper, we introduced DeepSeek-V2, a large MoE language model that supports a context length of 128K. In addition to powerful performance, it also features economical training and efficient inference, thanks to its innovative architectures, including MLA and DeepSeekMoE. In practice, compared to DeepSeek 67B, DeepSeek-V2 shows significant performance enhancements while saving 42.5% in training costs, reducing KV cache by 93.3%, and increasing maximum generation throughput by up to 5.76 times. Evaluation results further indicate that with only 21 billion activated parameters, DeepSeek-V2 achieves top performance among open-source models, becoming the strongest open-source MoE model.
DeepSeek-V2 and its chat version exhibit recognized limitations common in other LLMs, including a lack of continuous knowledge updates post pre-training, the potential to generate non-factual information (such as unverified suggestions), and opportunities for hallucination. Additionally, due to our data primarily consisting of Chinese and English content, our model’s proficiency in other languages may be limited. Caution should be exercised in scenarios beyond Chinese and English.
DeepSeek will continue to invest in open-source large models with a long-term vision, aiming to gradually approach the goal of artificial general intelligence.
• In our ongoing explorations, we are committed to designing methods that can further scale MoE models while maintaining economical training and inference costs. Our next goal is to achieve performance comparable to GPT-4 in the upcoming release.
• Our calibration team is continuously working to enhance our models, aiming to develop a model that is not only useful but also honest and safe for global users. Our ultimate goal is to align our model’s values with human values while minimizing the need for human supervision. By prioritizing ethical considerations and responsible development, we are committed to creating a positive and beneficial impact on society.
• Currently, DeepSeek-V2 is designed specifically to support text modalities. In our forward-looking agenda, we intend to enable our model to support multiple modalities, enhancing its versatility and practicality across a wider range of scenarios.
References
-
https://arxiv.org/pdf/2405.04434