

Cover Image Source:CAM (Cambridge Alumni Magazine) Issue 85
Written by | Jin Chunqi
In recent years, deep learning methods have achieved tremendous success in learning complex data forms, leading to new modeling and data processing methods across many scientific disciplines. It can address numerous data-intensive tasks, including but not limited to 3D computer vision, sequence modeling, causal reasoning, generative modeling, and efficient probabilistic reasoning, which are crucial for further scientific discoveries.
What is Deep Learning?
Along with deep learning, the concepts we most often hear are artificial intelligence, machine learning, and neural networks.
Artificial Intelligence (AI) is a broad concept that involves simulating, extending, and enhancing human intelligence using machines. For example, the robots in the TV series “Westworld” can think like humans and possess self-awareness.
Machine Learning (ML) is a branch of artificial intelligence aimed at allowing machines to learn how to judge and output corresponding results automatically by providing them with raw “learning materials.” When the system performs correctly, it is rewarded to reinforce such behavior, and when it makes mistakes, it is punished to weaken that behavior. Models are trained using data, which are then used for predictions.
Neural Networks generally refer to networks composed of brain neurons, synapses, cells, etc., used to generate consciousness and help organisms think and act. Later, artificial intelligence was inspired by neural networks to develop Artificial Neural Networks (ANNs).
Deep Learning (DL) originates from the study of artificial neural networks, referring to multi-layer artificial neural networks and the methods to train them. A layer of the neural network takes a large matrix of numbers as input, applies a non-linear activation method to weight them, and produces another data set as output. This process mimics the workings of biological neural brains, where suitable quantities of matrices are linked together to form a neural network “brain” that performs precise and complex processing, similar to how humans recognize objects and label images.
Deep learning is a new research direction in the field of machine learning, introduced to bring it closer to its original goal—artificial intelligence.
Unlike traditional machine learning, deep learning requires more samples, resulting in fewer manual annotations and higher accuracy. The early notion of “deep” referred to neural networks with more than one layer, but with the rapid development of deep learning, its connotation has exceeded the traditional multi-layer neural networks and even the scope of machine learning, rapidly evolving towards artificial intelligence. It can learn the intrinsic patterns and expressive hierarchies of sample data, and the information obtained is highly beneficial for interpreting data such as text, images, and sounds. Its ultimate goal is to enable machines to possess analytical learning capabilities akin to humans, capable of recognizing data like text, images, and sounds.
Deep learning has achieved significant results in search technologies, data mining, machine learning, machine translation, natural language processing, multimedia learning, speech, recommendation and personalization technologies, and other related fields.

Image Source: quantdare
The basic idea of learning using deep neural networks is quite simple. Based on a database of input-output pairs, the correct output is linked to the input data through machine learning. Deep learning employs multi-layer neural networks, where input data is fed into the first layer, and its output serves as input for the next layer, and so on. Each layer consists of the product of input and weight matrix, along with a non-linear function. The number of repetitions of the learning process is determined by the number of layers.
Assuming we have a system S with n layers (S1,…,Sn), its input is I, and output is O, represented as: I =>S1=>S2=>…=>Sn => O. If the output O equals the input I, meaning that there is no information loss during the transformation of input I through this system, it indicates that there is no information loss at any layer Si, and at any layer Si, it is another representation of the original information (i.e., input I). For deep learning, we need to learn features automatically. Assuming there are some inputs I (such as images or text), and a system S (with n layers) is designed, we adjust the parameters in the system so that its output remains I. This allows us to automatically obtain a series of hierarchical features of the input I, namely S1,…,Sn. The idea of deep learning is to achieve a hierarchical representation of the input information through stacked multiple layers. When the output requirements change, a different type of deep learning method will also emerge.
Figure 1 shows the process of recognizing a Samoyed dog (bottom left) using its RGB (Red, Green, Blue) image as input, employing a typical convolutional neural network. The rectangular images correspond to the feature maps detected at each image position. Information is transmitted from bottom to top, where low-level features act as directional edge detectors. After calculating scores for each image class, the category of the input image can be determined.
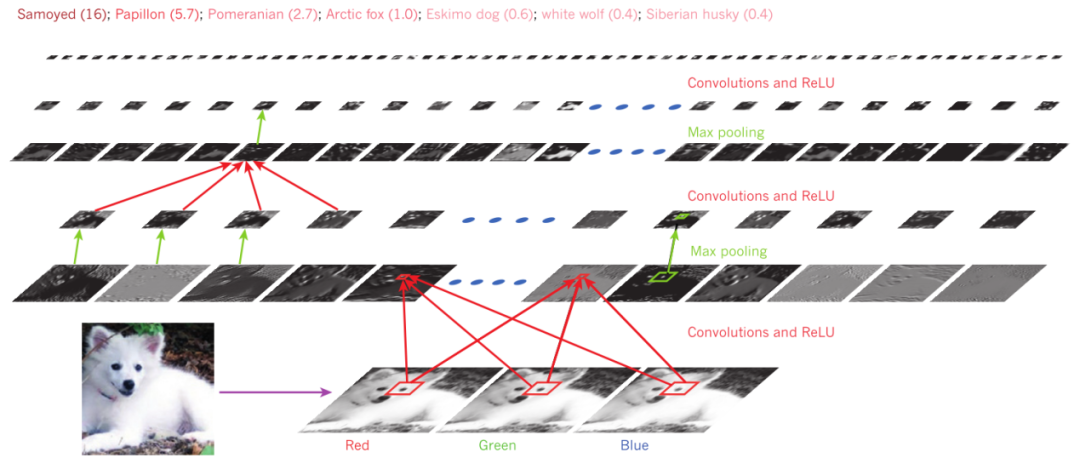
Figure 1: Recognizing a Samoyed Dog Using Convolutional Neural Networks
There are many factors that affect whether a deep learning system can successfully “learn,” and the key components mainly includethree. As noted by Professor Lenka Zdeborová of Paris-Saclay University in her commentary article titled “Understanding deep learning is also a job for physicists” published in Nature Physics, the three main elements of current deep learning systems are neural network architecture, algorithms, and structured data (as shown in Figure 2). Decoding these three elements means decoding the deep learning system.
The Three Elements of Deep Learning
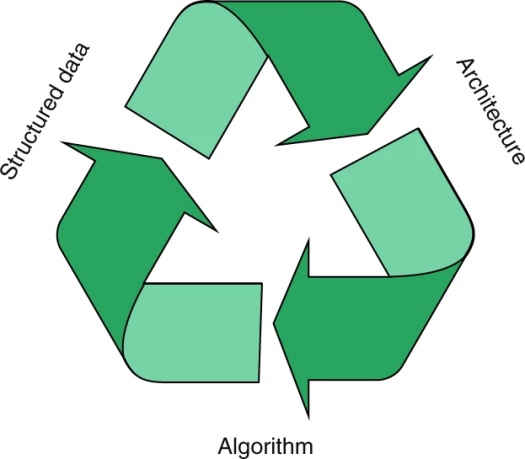
Figure 2: Interaction of Three Key Components
2.1
Neural Network Architecture
2.2
Algorithms
2.3
Structured Data
These three elements—architecture, algorithms, and structured data—are essentially interdependent, as the choice of network architecture is meant to represent the structure of the data in a way that the given algorithm can learn.
Scientists Should Embrace Deep Learning
Although deep learning has achieved tremendous success in research across various scientific disciplines, there are still some unresolved issues: For instance, when can deep neural networks, often described as black boxes, provide satisfactory answers, and when can they not? What is the best way to incorporate relevant domain knowledge, constraints, and symmetries when applying deep learning systems? How can we adapt existing learning tools to new problems, and how can we scientifically interpret the results obtained? How can we determine and quantify whether the training and testing data come from different sources, etc.
As a hot concept today, deep learning has gained wide recognition in both academia and industry. We have already seen its extensive applications and astonishing results across various fields, with many predictions about the scientific problems we can solve using deep learning in the near future. Some even question whether future learning systems will be able to directly collect suitable data and fully automatically infer natural laws from that data. As scientific researchers, we should embrace machine learning, utilize it as a new tool, actively study and understand why and how it truly works, and integrate it as a part of our research field, fully mobilizing our research spirit to explain it.
[4] https://ml4physicalsciences.github.io/