


DA/T 31-2017 Digitalization Standards for Paper Archives

The following terms and definitions apply to this document.
3.1 Character
An element in a set of elements used to organize, control, or represent data.
[GB 18030-2005, Definition 4.1]
3.2 Character Set
A collection of multiple characters.
Note: Common character sets include ASCII, GB2312, BIG5, GB18030, Unicode, etc.
3.3 Optical Character Recognition; OCR
The process of recognizing character shapes in image files, converting text, and outputting/presenting the text through information technology.
3.4 Digital Copy of Paper-Based Record
A digital image formed after the digitization process of paper archives, stored on carriers such as tapes, disks, and CDs, and can be recognized by electronic devices like computers.
3.5 OCR Outcome of Record
A document that records the text content of digital copies of paper archives obtained through OCR technology.
3.6 Recognition Accuracy
The ratio of correctly recognized characters through OCR technology.
Note: Recognition accuracy = (Number of correctly recognized characters / Total number of characters that should be recognized) × 100%
3.7 Recognition Speed
The number of characters recognized by OCR technology in a unit of time.




Table 1 Saving Rules for OCR Results
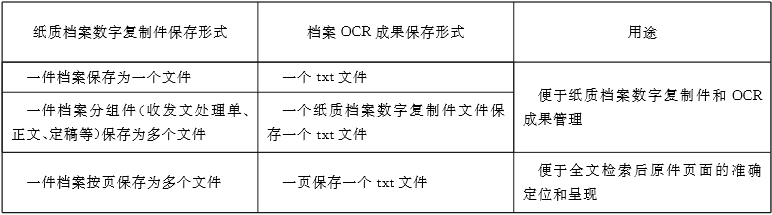


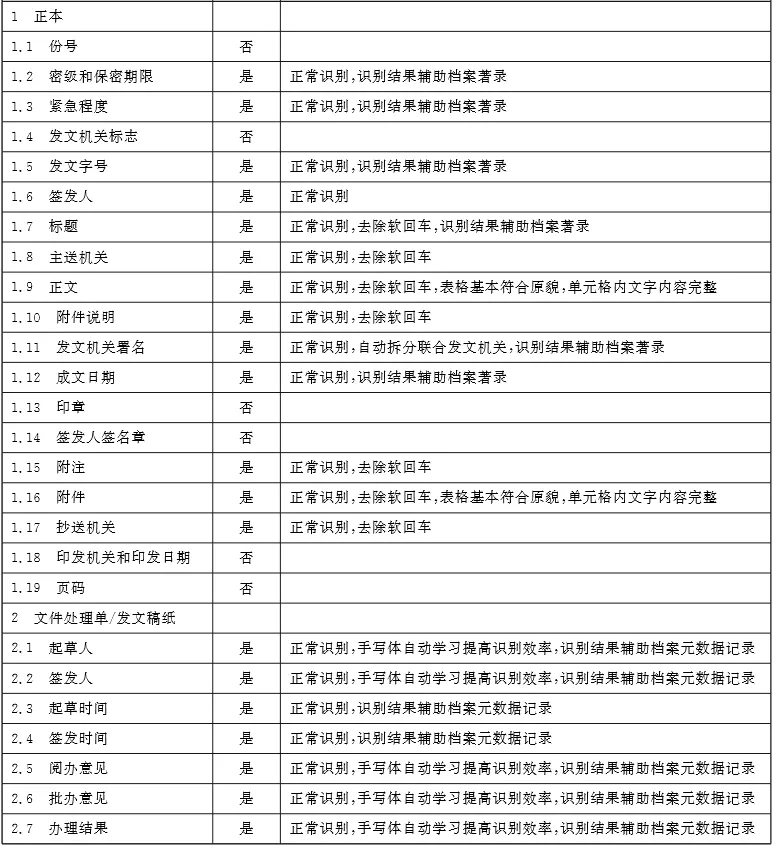
Table A.1 OCR Recognition Requirements for Document Elements
Source: Digital Archive Management
Editor: Xu Aoxue
Reviewer: Wang Xiaowei

