
With the advent of ChatGPT, research on generative artificial intelligence has made groundbreaking progress in the field of multimodal information processing, including text, images, and videos, attracting widespread attention. This article reviews the research progress of generative artificial intelligence and discusses its future development trends. Specifically, it includes three parts: first, a review of the development history and research status of generative artificial intelligence from the perspective of natural language models, images, and multimodal models; second, an exploration of the application prospects of generative artificial intelligence in different fields, focusing mainly on four aspects: content communication, assisted design, content creation, and personalized customization; third, an analysis of the main challenges faced by generative artificial intelligence and its future development trends.
History And Current Status Of Generative Artificial Intelligence
Generative artificial intelligence (artificial intelligence generated content, AIGC) is fundamentally about using artificial intelligence technologies to generate and edit various types of content, including text, speech, music, images, and videos. In the current context of the accelerated integration of the digital and physical worlds, AIGC is reshaping the production and consumption patterns of digital content. In 2018, a portrait created by artificial intelligence (AI) sold for $432,000 at a Christie’s auction in New York, becoming the world’s first AI-generated artwork sold, sparking interest across various sectors.
The models of AIGC can be roughly divided into two categories. One category is natural language models, where both input and output are natural language descriptions. For example, the input is a piece of text, requesting a story or a dialogue system, and the output is also a piece of text that meets the requirements of the instruction or engages in dialogue with the input text. The other category is image and multimodal models, where input and output are cross-modal, such as text input producing video output, or image input producing text, etc. Furthermore, both input and output can be multimodal, for instance, inputting text plus images to output a sequence of videos and audio. The output here can be regenerated content or edited and modified versions of the input.
1

Natural Language Models
Since 2018, based on the Transformer architecture, large language models have gradually emerged, most notably Google’s Bidirectional Encoder Representations from Transformers (BERT) model and OpenAI’s Generative Pre-training (GPT) series models, including the GPT-1 model proposed by OpenAI in 2018, which has approximately 120 million parameters. Subsequently, Google introduced the BERT model in 2019, with about 340 million parameters, outperforming GPT-1 overall. Following this, OpenAI quickly introduced the GPT-2 model, which has a staggering 1.5 billion parameters and was trained on 40GB of text, achieving further performance improvements. Later, to achieve even better performance, OpenAI launched the GPT-3 model in 2020, which has 175 billion parameters, crushing the previous GPT-1, BERT, and GPT-2 models. However, due to a lack of effective guidance, the GPT-3 model often produces unsatisfactory results when generating text content.
To solve this problem, OpenAI proposed the InstructGPT model, which specifically guides the model to generate expected content results through reinforcement learning from human feedback (reinforcement learning from human feedback, RLHF). Based on the InstructGPT model, OpenAI launched ChatGPT in 2022, ushering in a wave of AIGC in the era of large models. Shortly after, OpenAI introduced GPT-4 in 2023, with a parameter count reaching 1.8 trillion, achieving astonishing overall performance. These models excel in text understanding, demonstrating exceptional capabilities in text classification, entity detection, and question answering. At the same time, other emerging large models, such as Sora, have brought new perspectives to the AIGC field. The Sora model, through its unique architecture and advanced multimodal processing capabilities, further expands the application range of natural language processing. In 2024, some new breakthrough research further advanced the development of the NLP field. For example, Ding et al. proposed a new efficient fine-tuning method that greatly reduces the resource requirements for large models and enhances the adaptability of large language models. Wu et al. conducted in-depth discussions on the application of continuous learning in NLP, proposing potential future development directions for natural language processing. The development history of NLP models is illustrated in Figure 1.

From the above development history, it can be seen that AIGC has officially entered the era of large language models (large language model, LLM) in terms of the development of natural language models. In addition to significant progress in natural language models, AIGC has also made many significant breakthroughs in the image and multimodal fields.
2

Image Generation Models And Multimodal Models
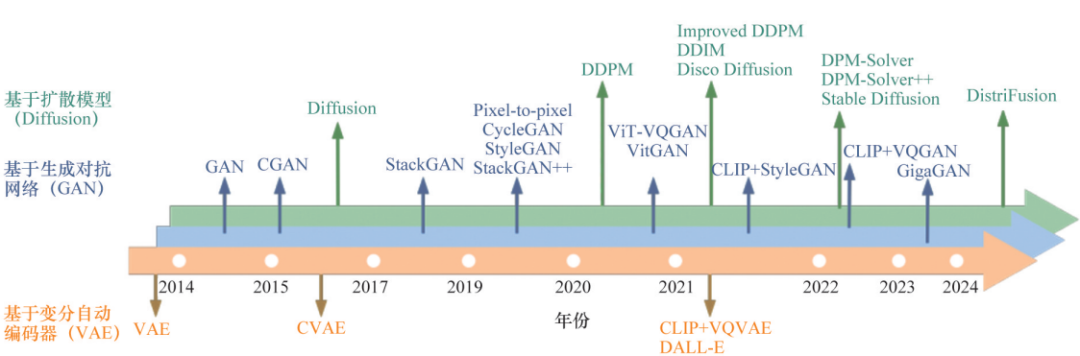
Thanks to the emergence of Transformer and diffusion models, AIGC has also made many significant breakthroughs in multimodal models. In January 2021, OpenAI released the text-to-image synthesis model DALL-E, whose remarkable generation effects were astonishing. In the same year, the contrastive language-image pre-training (CLIP) model was introduced. CLIP is a multimodal model that combines the visual language model ViT and Transformer. It trains by receiving a large amount of text and image data, integrating visual and language knowledge during the pre-training process, allowing it to train transferable visual models using text as a supervisory signal. Due to CLIP’s strong capabilities in image and text processing, many subsequent multimodal models have combined with the CLIP model to achieve excellent results. Subsequently, DALL-E2 and DALL-E3 were released in April 2022 and October 2023, respectively. DALL-E2 and DALL-E3 can generate ultra-high-quality new images with just a few lines of text, raising the realism of text-to-image generation and language comprehension to new heights. In addition to the DALL-E series, Stable Diffusion and Midjourney have also been launched, both of which have received widespread acclaim for their generation effects. Furthermore, based on diffusion models, AIGC has made significant progress in the field of video synthesis. Gen-2 and Pika can now generate coherent videos, but the quality and motion diversity of generated videos still need improvement. In the field of video generation, the most advanced model is I2VGen-XL, released in December 2023, which achieves high-definition video generation results with time and space consistency by optimizing the initial 600 denoising steps, with video resolutions reaching 1280×720. Figure 2 summarizes the development process of generative models based on VAE, GAN, and diffusion.
Processes And Application Prospects Of Generative Artificial Intelligence
Benefiting from the rapid growth of computational resources and data volume, AIGC algorithms have achieved remarkable achievements in text, image, and multimodal information processing, greatly promoting the application of AIGC across various industries. AIGC represents cutting-edge technology in the field of artificial intelligence, transforming the way people work, their creative processes, and daily lives at an unprecedented speed.
1

The Learning Process Of AI
The learning of AIGC involves technologies such as generative adversarial networks (GAN) and variational autoencoders (VAE) in deep neural networks. These models undergo a competitive learning process, where one generative model aims to create increasingly realistic data, while another discriminative model works to better distinguish between real and generated data. Their common goal is to improve the generative model’s generalization ability on unseen data. Additionally, the training of AIGC must consider not only the quantity of data but also the quality and diversity of the data, as well as the training strategies and regularization techniques of the model to prevent the model from prematurely falling into local optima and losing generalization performance.
2. The Learning Process Of Traditional AI
Traditional AI learning typically relies on large labeled datasets, utilizing supervised learning algorithms to iteratively reduce the error between model predictions and real-world scenarios. This learning method excels in specific tasks, such as image classification and speech recognition in single-modal data processing. In contrast, AIGC requires learning the underlying distribution from data and generating new data instances based on this learned distribution, which places higher demands on the model’s understanding and grasp of the inherent features of the data. This process resembles “learning to generate” rather than “learning to predict.”
3. Deep Learning And Transfer Learning
The learning methods of AIGC are also closely related to deep learning, which automatically learns high-level features from complex data through multi-layer neural network structures. When these deep learning models are combined with transfer learning strategies, knowledge learned in one domain can be applied to another domain, saving resources and improving efficiency when learning new tasks.
2

Differences Between AIGC And Traditional AI
1. Differences In Goals And Methods
The main purpose of AIGC is creation, not merely the replication or copying of existing information, but to create entirely new data instances based on an understanding of the data. This requires AIGC to learn the intrinsic distribution and structure of the data to generate new data that is highly similar to real data but not identical. In contrast, traditional AI, especially supervised learning-based models, focuses more on “prediction.” They learn from a large number of input-output instances to predict the output corresponding to a given input. The main objectives of these models are accuracy and reliability, rather than creativity.
2. Model Structures And Training Approaches
Commonly used generative adversarial networks (GAN) and variational autoencoders (VAE) in AIGC have unique characteristics in model structure. For example, GAN introduces adversarial training between the generator and discriminator, simulating a mini “game field”; while VAE uses probabilistic graphical models to optimize the latent space representation of data. Traditional AI models, such as regression models, decision trees, and support vector machines (SVM), typically have more direct structures, training by minimizing the difference between actual outputs and predicted outputs.
3. Data Processing Methods
AIGC can handle and generate a wider variety of data types, including but not limited to text, images, and audio. It not only focuses on specific tasks or labels when processing data but also attempts to understand the global properties and structures of the data. In contrast, traditional AI often requires explicit label information to conduct task-driven learning, optimizing for specific tasks or problems.
4. Application Scenarios
Due to its unique creative capabilities, AIGC shows broad application prospects in fields such as artistic creation, data augmentation, and virtual environment simulation, helping designers create novel design solutions, providing researchers with rich training data, or creating realistic virtual environments for the gaming and VR (virtual reality) industries. Traditional AI is more commonly applied in data analysis, predictive modeling, and automated control fields, such as risk assessment in finance, disease diagnosis in healthcare, and fault prediction in manufacturing.
Understanding the differences between AIGC and traditional AI not only helps people choose tools more reasonably to solve problems but also opens up new perspectives and imaginative spaces for the future development of AI.
3

Current Status Of AIGC Applications
1. Content Communication
The greatest application prospect of AIGC currently lies in its ability to engage in interactive communication with users, mainly divided into two aspects: chat-based communication and content consulting communication. Chat-based communication can primarily be used for emotional chatbots, helping individuals with autism, depression, and other mental health issues alleviate their conditions and assisting doctors in formulating corresponding treatment plans. In terms of content consulting communication, AIGC can build content consulting platforms across various industry fields, such as medical consulting, legal consulting, and everyday knowledge consulting. On one hand, compared to traditional search platforms, consulting platforms can better clarify users’ consulting needs through interactive communication, thereby providing more effective consulting results. On the other hand, constructed AIGC consulting platforms can help professionals in different fields improve efficiency. For example, in medical and legal consulting, users can obtain basic advice on the consulting platform based on their needs before seeking help from doctors or lawyers.
2. Assisted Design
AIGC has broad application prospects in assisted design. In the education sector, AIGC can provide course design materials for educators, automatically creating and updating course materials, allowing teachers to make further modifications based on the generated materials, significantly saving teachers’ time and effort. Additionally, AIGC can assist students in writing daily reports and can correct grammar, identify weak points, and provide content improvement suggestions, helping students learn from mistakes and gradually improve their writing skills. In the media industry, AIGC can assist journalists in timely writing news reports for urgent events and automatically generate news headlines, improving efficiency and response speed in journalism. Furthermore, AIGC can enable virtual host news broadcasting 24/7, alleviating the burden on journalists. In the film industry, AIGC can assist in script processing, transforming old scripts into polished new scripts, which can then be further modified by directors and screenwriters. Moreover, it can enhance the visual effects of films, such as changing the colorization and resolution of movie scenes. Beyond these industries, AIGC can assist workers in related design and research in fields such as computing, medicine, and painting. For example, in the computing industry, it can automatically generate high-quality code and conduct code testing and refactoring; in medicine, it can assist in drug development, protein structure prediction, and protein sequence design; in painting, AIGC can assist in the preservation and restoration of artworks, restoring damaged artworks to their original state.
3. Content Creation
AIGC has promising development prospects in content creation. In the music industry, AIGC can automate the entire process of music creation, with lyrics, melodies, and tunes all generated automatically. Additionally, during the music creation process, it can provide different styles of music for users to choose from. In the painting industry, AIGC can produce unique and complex artworks, generating color schemes, patterns, and texture information by analyzing images, creating artworks in various artistic forms, such as ink paintings, abstract paintings, Chinese landscape paintings, and watercolor paintings. In the advertising industry, AIGC can automatically generate advertising content, posters, and design logos. In the video industry, AIGC can generate creative short video content and also create scenes for movies. The advantage of AIGC content creation lies in its ability to automatically generate diverse results based on the same content, effectively meeting the needs of users across different industries.
4. Personalized Customization
AIGC has immense application potential in personalized customization. In the education sector, AIGC can provide personalized tutoring, such as generating unique foreign language teaching products for children to capture their attention, stimulate their enthusiasm, and provide a fun learning environment; it can help older students understand certain theories, concepts, and different language articles, facilitating more effective learning. In the gaming industry, AIGC allows users to customize game scenes and storylines according to their needs, enhancing the immersive gaming experience. Furthermore, users can host large events in games, such as concerts, art exhibitions, and graduation ceremonies, providing all participants with unique and extraordinary experiences. Beyond these applications, the greatest application prospect of AIGC in personalized customization is achieving digital immortality. Currently, using AIGC technology, it is already possible to alter a person’s voice, create 3D avatars, and facilitate content communication. Based on existing AIGC technology and its continuous updates, as long as a large amount of data is collected and organized regarding a person’s voice, image, and communication patterns, a digital immortality model of that person can be trained using this data. This model can simulate the person’s speaking voice and mannerisms, present their 3D appearance, and communicate with others in the person’s speaking style, thus achieving a preliminary form of digital immortality. Even after this person passes away, others can communicate with their digital immortality model.
Potential Risks Of Generative Artificial Intelligence
While comprehensively recognizing the application potential of generative artificial intelligence, it is also crucial to face the potential risks that accompany its development.
1

Disputes Over Intellectual Property
2

Threats To Data Privacy
3

Challenges Of Ethical Use
4

Continuation Of Technical Bias
5

Impact On Employment
AIGC, as a powerful tool, presents various potential risks that span social, legal, and ethical dimensions. Therefore, enhancing regulation of AIGC applications, establishing ethical use principles, and developing corresponding legal frameworks will be urgent tasks. Only in this way can we ensure that technological advancements bring greater benefits to humanity without compromising individual and societal interests.
Challenges And Development Trends Of Generative Artificial Intelligence
1

Main Challenges
1) High Research Barriers. Currently, high-performing AIGC algorithms are achieved in environments characterized by “three supers” (super-large-scale parameters, super-large-scale data, and super-large-scale computational resources), making the cost and barriers for AIGC algorithm research prohibitively high, deterring many researchers. This situation greatly limits the progress of AIGC algorithm research.
2) Uncontrollable Generated Content. Although AIGC has achieved high-quality generation results in multimodal content generation such as text, speech, images, and videos, the results of content generation are uncontrollable. This uncontrollability primarily manifests in the potential for AIGC algorithms to generate discriminatory, violent, or illegal content, which poses legal and social moral issues.
3) Unstable Generation Performance. Current AIGC algorithms occasionally produce particularly poor results in certain specific research areas (such as text generating images, text generating videos, speech generating images, etc.), making their applicability in these fields relatively average. Additionally, in some high-risk areas (such as healthcare, financial services, autonomous driving, etc.), where extremely low or zero error rates are required, AIGC can only play a supportive role in these applications.
2

Development Trends
1) Obtaining Labeled High-Quality Data. AIGC currently achieves excellent performance through a “brute force miracle” approach, but to achieve such “miracles,” research must be conducted in a “three supers” environment, which excludes most researchers. Compared to the “three supers” environment, acquiring labeled high-quality data can achieve excellent performance in a “three mediums” environment (medium-scale parameters, medium-scale data, and medium-scale computational resources). Therefore, future efforts need to focus on researching effective methods for obtaining labeled high-quality data to lower the barriers for AIGC research.
2) Detection And Evaluation Of Generated Content. The primary reason for the uncontrollable problem of generated content faced by AIGC is the lack of detection and evaluation during the generation process, leading to problematic content being output. Therefore, future research should focus on developing detection and evaluation algorithms for generated content to effectively prevent the output of problematic content.
3) Research Targeting Specific Domains. On one hand, AIGC’s performance in certain specific fields is unsatisfactory. On the other hand, most high-performing AIGC models are designed for multiple fields, resulting in significant room for improvement in their performance within specific domains. Therefore, future research needs to focus on targeted model research for specific domains, improving model performance while enhancing applicability.
Conclusion
Generative artificial intelligence undoubtedly stands out as a highlight in modern technological development; it is a double-edged sword, possessing the potential to change the rules of the game while also carrying risks and challenges that cannot be ignored. The future development of generative artificial intelligence needs to reasonably utilize its benefits while avoiding potential risks. It is essential not only to focus on the development of the technology itself but also to begin establishing corresponding regulatory measures, legal frameworks, and ethical guidelines.
In the future, academia, industry, and policymakers must collaborate, engaging in cross-domain cooperation and dialogue to continuously improve the understanding and application of generative artificial intelligence, collectively building an ecosystem that promotes technological innovation while ensuring social justice and the protection of individual rights, thus driving and achieving the healthy development of generative artificial intelligence technology, making it a positive force for the advancement of human society.
Authors Of This Article: Che Lu, Zhang Zhiqiang, Zhou Jinjia, Li Lei
Author Profiles: Che Lu, Southwest University of Science and Technology, School of Environmental and Resource Sciences, PhD student, research direction in artificial intelligence multi-source data fusion technology; Zhou Jinjia (corresponding author), Hosei University, associate professor, research direction in generative artificial intelligence.
This article was published in the 12th issue of “Science and Technology Guide” in 2024. Subscription is welcome for viewing.

The content is original from the “Science and Technology Guide” WeChat public account, and reprints are welcomeWhitelist reply to the background “Reprint”
Exciting Content Review