

Click the image to sign up for the Guangzhou & Zhuhai Innovation Conference
For the past six months, I have been working on developing a programming language called Pinecone. I can’t say it is fully mature yet, but it already has enough features (for a programming language) in use, such as:
-
Variables
-
Functions
-
User-defined structs
If you are interested, you can check out the Pinecone landing page or its GitHub repo.
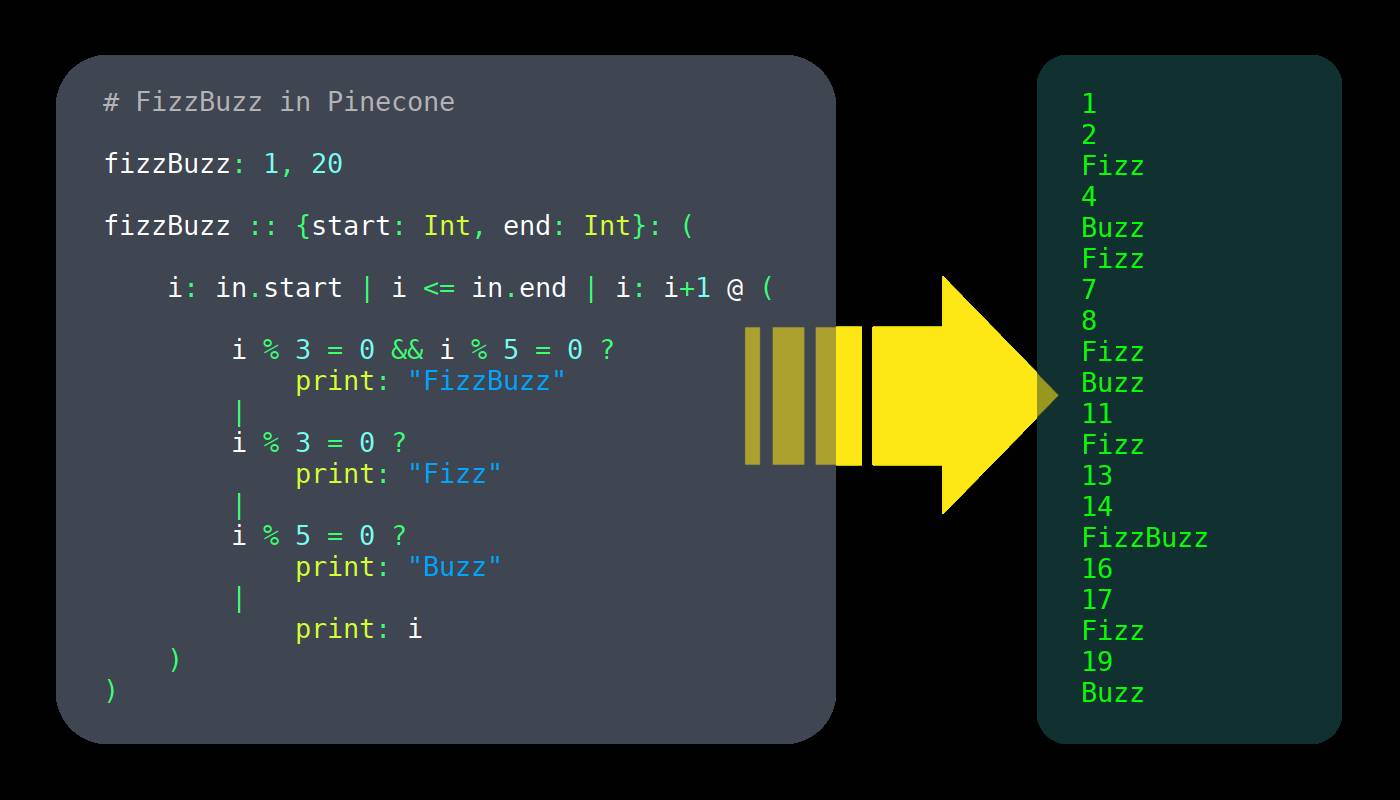
I am not an expert. When I started this project, I had no direction in what I was doing, but I didn’t give up. My level of language creation was 0; I had only read a little online material and didn’t follow the advice given.
However, I still created a complete new language. And it works. So I must have done something right. In this article, I will delve into the process of how Pinecone (and other programming languages) transforms source code into a new language. I will also talk about some trade-offs I have made and why I made those decisions.
This is definitely not a complete tutorial on making a programming language, but if you are curious about language development, this is a good start.

Getting Started

“I don’t even know where to start,” is usually the response I get when I tell other developers that I am writing a language. If your reaction is the same, I will now guide you through some decisions and steps I have tried to help you get started on a new language.
Compiled vs Interpreted
There are mainly two types of languages: compiled and interpreted:
A compiler calculates the operations a program will perform, converts it into “machine code” (a format that the computer can run very quickly), and saves it for later execution.
An interpreter executes the source code line by line, figuring out what it does.
Technically, any language can be compiled or interpreted, but one or the other usually makes more sense for a specific language. Generally, interpreted languages tend to be more flexible, while compiled languages often have better performance. But this is just a warm-up before tackling complex problems.
I place a high value on performance, and I’ve seen a lack of high-performance and simplicity in programming languages, so I decided to compile Pinecone.
This is an important decision that needs to be made early on, as many language design decisions are influenced by it (for example, static typing is a significant advantage for compiled languages but not so important for interpreted languages).
Although Pinecone is designed as a compiled language, it also has a unique, fully functional interpreter. The reasons for this will be explained later.
Choosing a Language
I know this sounds a bit like metadata, but a programming language is itself a program, so you need to write it in a language. I chose C++ because of its performance and extensive feature set. Additionally, I actually enjoy working with C++.
If you are writing an interpreted language, it makes a lot of sense to write it in a compiled language (like C, C++, or Swift) because the performance loss in your interpreted language and its corresponding interpreter will be more complex.
If you plan to compile, slower languages (like Python or JavaScript) are more acceptable. Compile times can be terrible, but in my view, the runtime difference is not that significant.
High-Level Design
A programming language is typically constructed as a kind of pipeline. This means it usually has several stages. Each stage formats the data in a specific way and has the ability to convert data from one stage to the next.
The first stage is a string containing the entire input source file. The final stage is something that can be executed. As we gradually complete the Pinecone pipeline, everything will become clearer.

Lexing


The first step for most programming languages is lexing or tokenization. “Lex” is short for lexical analysis, which is a great term for breaking a large amount of text into multiple tokens. The term “tokenizer” is more meaningful, but “lexical analysis” sounds fun, so I often use it.
Tokens
A token is a unit of the language. A token can be a variable or function name (also called an identifier), or it can be an operator or a number.
Task of the Lexer
The lexer takes a file containing source code as an input string and outputs a list of tokens.
The stages after the pipeline (the compilation process) will no longer refer to these string source codes, so the lexer must produce all the information needed for the subsequent stages. The reason for this relatively strict format design is that the lexer can do some work at this stage, such as removing comments or detecting identifiers or numbers. If you place these logical rules in the lexer, then you won’t have to consider these rules when constructing other parts of the language, and you can conveniently modify these syntax rules in one place.
Flex
The first thing I did when I started developing this language was write a simple lexer. Soon after, I began learning about tools that could simplify and correct the lexer.
This little tool is Flex, a program that generates lexers. You provide it with a file formatted in a specific way to describe the language’s syntax. It generates a program code in C language syntax.
My Decision
I chose to temporarily keep the lexer I initially wrote. In the end, I didn’t see a clear advantage of Flex, at least not enough to justify adding dependencies and completing a complex build.
My lexer is only a few hundred lines of code with almost no issues. Iterating on my lexer also provided more flexibility. For example, adding operators to the language without editing multiple files.

Parsing


The second stage of the pipeline process is the parser. The parser takes the list of identifiers and parses it into a tree structure. The tree used to store this data is called an Abstract Syntax Tree (AST). In the final Pinecone AST, no identifier type information will be included; it will just be a simple structured identifier.
Role of the Parser
The parser adds structure to the ordered list of tokens produced by the lexer. To prevent ambiguity, the parser must consider parentheses and operator precedence. Parsing simple operators is not too difficult, but as more language constructs are added, parsing becomes very complex.
Bison
Again, there is a decision involving a third-party library. The main parsing library is Bison. Bison works similarly to Flex. You write files in a custom format that stores syntax information, and then Bison uses that file to generate a C program that will perform the parsing. But I did not choose to use Bison.
Why Custom is Better
Using my own code in the lexer was a fairly obvious decision. The lexer is such a small program that it felt silly not to write it myself, like not writing my own “left-pad”.
The parser is another matter. My Pinecone parser is currently 750 lines long, and I have written three because the first two were garbage.
There are many reasons for the decisions I made; although it hasn’t been smooth, most of them were correct. The main points are as follows:
-
Minimize context switching in the workflow: The context switching between C++ and Pinecone is not enough without throwing Bison’s syntax in.
-
Keep the build simple: Every time the syntax changes, Bison must be run before the build. This can be automated, but it becomes painful when switching between build systems.
-
I enjoy building cool things: I didn’t create Pinecone because I thought it would be easy, so why would I decide on a central role? A custom parser may not be trivial, but it is entirely feasible.
At first, I wasn’t entirely sure if this was feasible, but I have to say something about Walter Bright (the developer of early versions of C++ and the creator of the D language):
One thing that is more controversial is that I will not waste time on lexer or parser generators and other so-called “compiler-compilers” as they are a waste of time. Writing a lexer and parser is a small part of writing a compiler. Using a generator will take as much time as writing one by hand, and it will combine you with the generator (which is very important when porting the compiler to a new platform). Generators also sometimes produce bad error messages and unfortunate sounds.
Action Tree
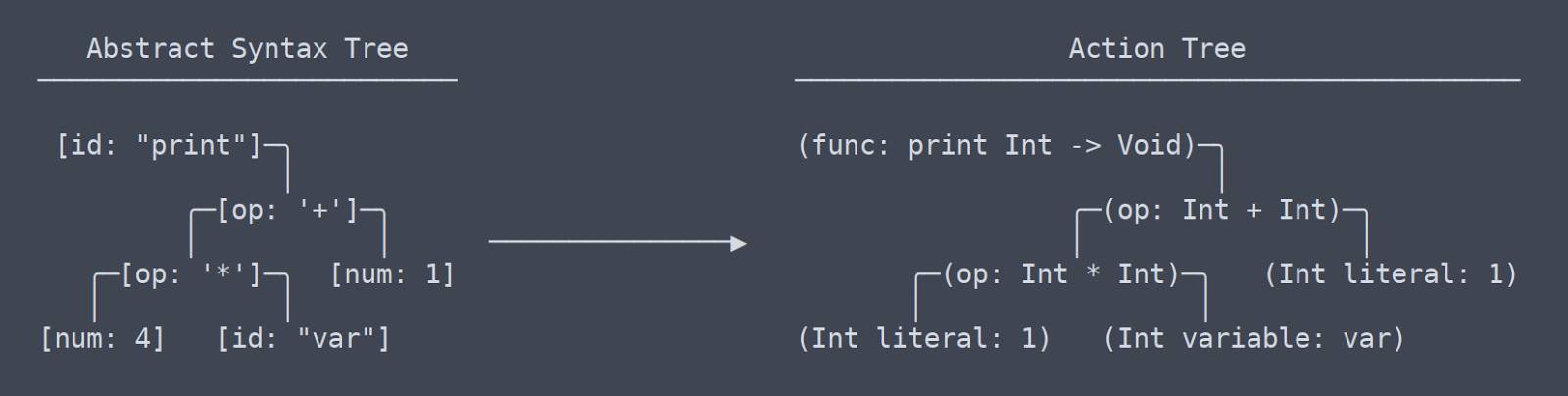
We are now out of the realm of common terminology or jargon, at least terms I don’t recognize. From my understanding, what I call an ‘Action Tree’ is most similar to LLVM’s IR (Intermediate Representation).
I spent a considerable amount of time figuring out the subtle but very important distinction between the Action Tree and the AST, which we should treat differently (this led to a rewrite of the parser).
Action Tree vs AST
Simply put, an Action Tree is an AST with context. The context is information about the type of a function’s return or that two variables used in different places are actually the same variable. Because it needs to figure out and remember all this context, the code that generates the Action Tree requires a lot of namespace lookup tables and other things.
Running the Action Tree
Once we have the Action Tree, running the code becomes easy. Each action node has an execute function that takes some input, regardless of how the action should behave (including potentially calling sub-actions), and returns the output of the action. This is the interpreter of the actions.

Choice of Compilation

Wait, isn’t Pinecone supposed to be compiled first? Yes, but compiling is much more complex than interpreting, and there are several solutions:
Develop a New Compiler
Sounds like a good idea; I love creating things and have long wanted to explore the field of compilation.
However, writing a compiler is not as simple as translating every element of the language into machine code because there are many different architectures and operating systems, making it impractical for an individual to write a cross-platform compiler.
Even the Swift team with Rust and Clang does not want to start from scratch; their approach is…
LLVM
LLVM is a compilation toolkit; essentially, it is a library that can compile your programming language into executable files, which seems like a perfect choice, so I immediately used it. Unfortunately, I did not realize how deep the waters were at that time.
LLVM is an exceptionally large library, almost impossible to use, even if it is not as difficult as assembly language. Even though they have good documentation, I feel that I need to gain more experience before fully implementing Pinecone with LLVM.
Transpilation
I wanted to quickly compile Pinecone, so I turned to a feasible method: transpilation.
I wrote a Pinecone to C++ transpiler and added the ability to use GCC to automatically compile the output source code. This currently works for almost all Pinecone programs (but there are exceptions). It is not a particularly portable or scalable solution, but it is a usable temporary solution.
The Future
Assuming I continue to develop Pinecone, it will eventually receive LLVM compilation support. I doubt that no matter how much work I do, the transpiler will ever work completely stably; the benefits of LLVM are numerous. The question is when I will have time to do some sample projects in LLVM and master it.
In the meantime, the interpreter is excellent for trivial programs, and the C++ transpilation works for most cases that require more performance.

Conclusion

I hope the programming language I have created is clear and straightforward for you. If you want to create one yourself, I highly recommend it. There are many implementation details to figure out, and this outline should help you.
Here are my starting suggestions (remember, I really don’t know what I’m doing, so just as an example):
-
When in doubt, choose interpreted. Interpreted languages are generally easier to design, build, and learn. If you are sure you want to create a compiled language, I won’t stop you from trying, but I would advise caution.
-
When it comes to lexers and parsers, choose whatever you want. There are many valid arguments for both writing your own and using existing ones. Ultimately, if you give your design and implement everything reasonably, it doesn’t matter.
-
Learn some tricks from the pipeline in the conclusion of this article. I had a lot of trial and error when designing the pipeline. I tried eliminating the AST, turning the AST into an Action Tree, and other bad ideas. This pipeline works, so there’s no need to change it unless you have a really good idea.
-
If you don’t have the time or motivation to implement a complex general-purpose language, try implementing an esoteric language like Brainfuck. These interpreters can be as short as a few hundred lines.
I apologize for some poor decisions I made during the implementation of Pinecone, but I have rewritten most of the code affected by such mistakes.
Now, Pinecone is good enough, especially in its functionality, and open to improvements. Writing Pinecone has been a very rewarding and enjoyable experience for me, and it is just the beginning.
 For more insights, please check the “Read Me” section in the public account menu -> “Insight Sharing”.
For more insights, please check the “Read Me” section in the public account menu -> “Insight Sharing”.
