



Click the blue text above to follow us

1. Introduction
By combining the capabilities of semantic search with the excellence of LLMs like GPT, we will demonstrate how to build an advanced document Q&A system utilizing cutting-edge AI technology.
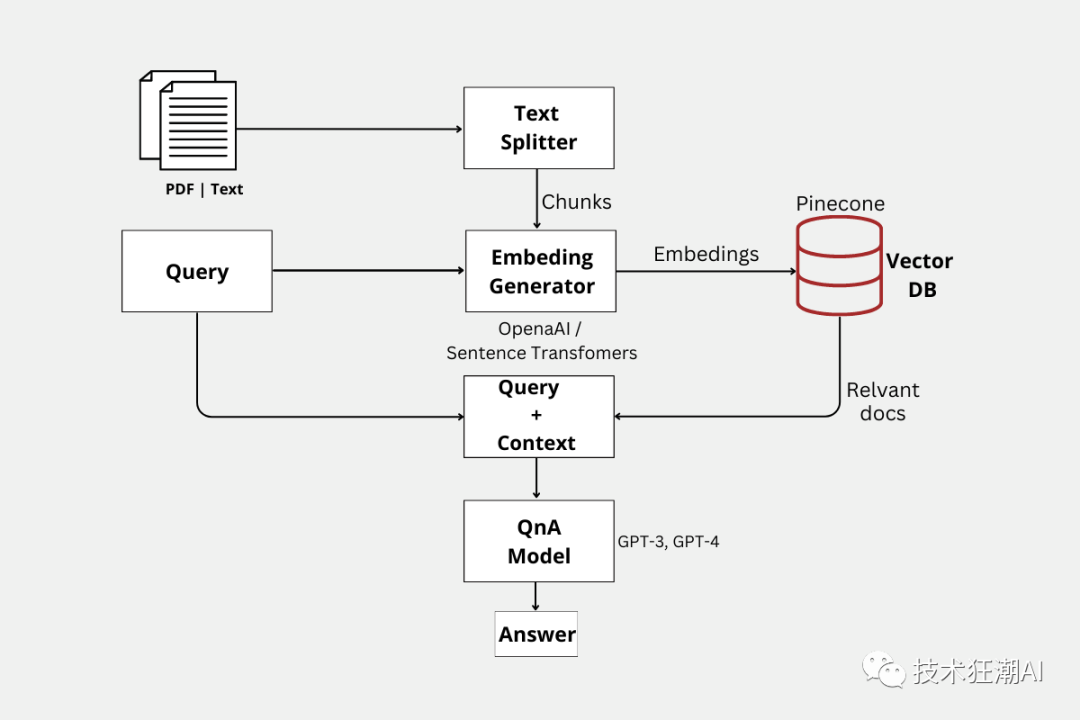

2. Why Semantic Search + GPT Q&A is Better than Fine-tuning GPT?
Before we dive into the implementation, let’s understand the advantages of using semantic search + GPT Q&A compared to fine-tuning GPT:
2.1. Broader Knowledge Coverage:

Semantic search + GPT Q&A mainly involves two core steps: first, finding relevant paragraphs from a large number of documents, and then generating answers based on those paragraphs. This method can provide more accurate and up-to-date information, utilizing the latest information from various sources. In contrast, fine-tuning GPT relies on the knowledge encoded in the model during training, which may become outdated or incomplete over time.
2.2. Context-specific Answers:

Semantic search + GPT Q&A can generate more contextually precise answers by basing answers on specific paragraphs from relevant documents. However, fine-tuned GPT models may generate answers based on general knowledge embedded in the model, which may not be accurate or relevant to the context of the question.
2.3. Adaptability:

The semantic search component can easily be updated with new information sources or adjusted to different domains, making it more adaptable to specific use cases or industries. In contrast, fine-tuning GPT requires retraining the model, which can be time-consuming and computationally expensive.
2.4. Better Handling of Ambiguous Queries:

Semantic search can eliminate query ambiguity by identifying the most relevant paragraphs related to the question. This can lead to more accurate and relevant answers compared to fine-tuned GPT models that lack appropriate context.

3. LangChain Modules

4. Setting Up the Environment
-
Install Required Packages:
!pip install --upgrade langchain openai -q
!pip install unstructured -q
!pip install unstructured[local-inference] -q
!pip install detectron2@git+https://github.com/facebookresearch/[email protected]#egg=detectron2 -q
!apt-get install poppler-utils-
Import Necessary Libraries:
import os
import openai
import pinecone
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
5. Loading Documents
ImportError: cannot import name 'is_directory' from 'PIL._util' (/usr/local/lib/python3.10/dist-packages/PIL/_util.py)Check the version of pillow, reinstall version 6.2.2, and restart the Colab Runtime environment after installation.!pip show pillow
!pip uninstall pillow
!pip install --upgrade pillow==6.2.2 directory = '/content/data'
def load_docs(directory):
loader = DirectoryLoader(directory)
documents = loader.load()
return documents
documents = load_docs(directory)
len(documents)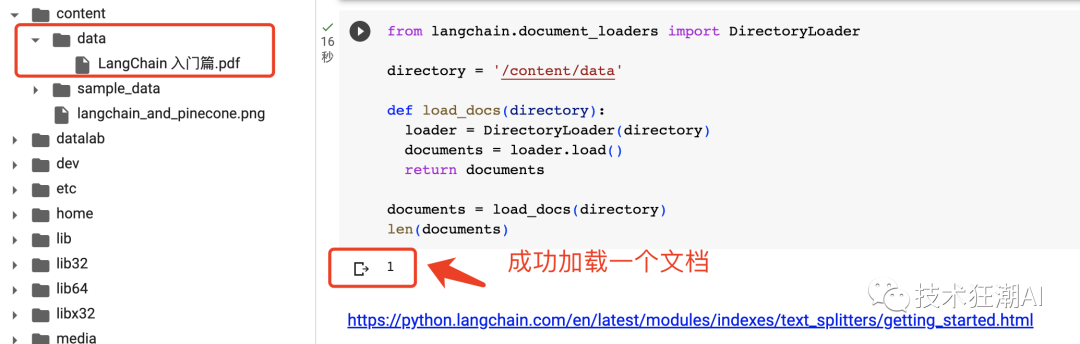

6. Splitting Documents
def split_docs(documents, chunk_size=1000, chunk_overlap=20):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
docs = text_splitter.split_documents(documents)
return docs
docs = split_docs(documents)
print(len(docs))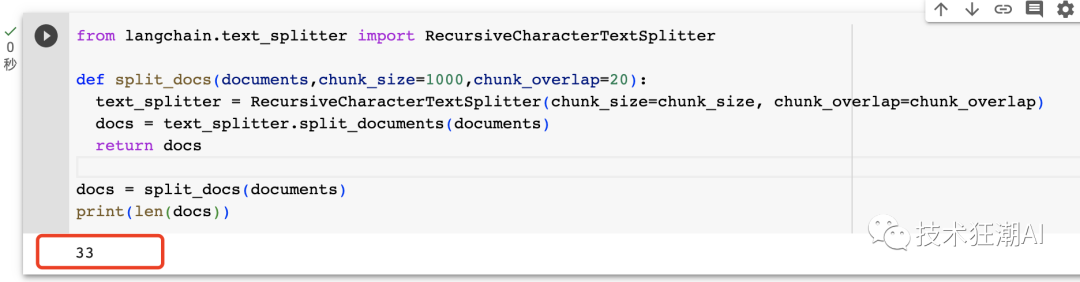

7. Using OpenAI to Embed Documents
!pip install tiktoken -qNow, we can use LangChain's OpenAIEmbeddings class to embed the documents.import openai
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
query_result = embeddings.embed_query("memory")
len(query_result)
8. Using Pinecone for Vector Search
!pip install pinecone-client -qpinecone.init(
api_key="pinecone api key",
environment="env"
)
index_name = "langchain-demo"
index = Pinecone.from_documents(docs, embeddings, index_name=index_name)
9. Finding Similar Documents
def get_similiar_docs(query, k=2, score=False):
if score:
similar_docs = index.similarity_search_with_score(query, k=k)
else:
similar_docs = index.similarity_search(query, k=k)
return similar_docs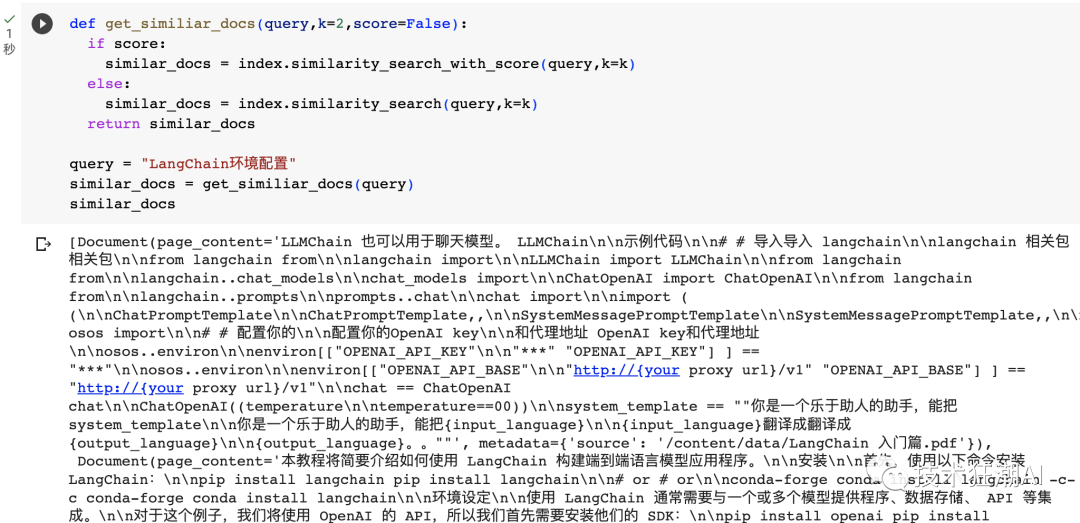

10. Using LangChain and OpenAI LLM for Q&A
# model_name = "text-davinci-003"
# model_name = "gpt-3.5-turbo"
model_name = "gpt-4"
llm = OpenAI(model_name=model_name)
chain = load_qa_chain(llm, chain_type="stuff")
def get_answer(query):
similar_docs = get_similiar_docs(query)
answer = chain.run(input_documents=similar_docs, question=query)
return answer
11. Example Queries and Answers
query = "How to install LangChain?"
answer = get_answer(query)
print(answer)
query = "Managing LLM prompts?"
answer = get_answer(query)
print(answer)
12. Conclusion
If you are interested in this article and want to learn more about practical skills in the AI field, you can follow the ‘Tech Wave AI’ public account. Here you can see the latest and hottest articles and practical tutorials in the AIGC field.