
Click the “CVer” above to select “Star” or “Pin”.
Heavyweight content delivered at the first time.
Author: Bi Ji Ji
https://zhuanlan.zhihu.com/p/59271905
This article is authorized, and no secondary reproduction is allowed without permission.
1. The Differences Between nn.Module.cuda() and Tensor.cuda()
Both the cuda() function can achieve memory migration from CPU to GPU for models and data, but their effects are different.
For nn.Module:
model = model.cuda()
model.cuda()The above two lines can achieve the same effect, which is to perform memory migration on the model itself.
For Tensor:
Unlike nn.Module, calling tensor.cuda() only returns a copy of this tensor object in GPU memory, and does not change itself. Therefore, it must be reassigned, i.e., tensor=tensor.cuda().
Example:
model = create_a_model()
tensor = torch.zeros([2,3,10,10])
model.cuda()
tensor.cuda()
model(tensor) # Will raise an error
tensor = tensor.cuda()
model(tensor) # Runs normally2. Differences in Calculating Accumulated Loss in PyTorch 0.4
Taking the widely used pattern total_loss += loss.data[0] as an example. Before Python 0.4.0, loss was a Variable encapsulating a (1,) tensor, but in Python 0.4.0, loss is now a zero-dimensional scalar. Indexing a scalar is meaningless (it seems to raise an invalid index to scalar variable error). Using loss.item() can extract the Python number from the scalar. So change to:
total_loss += loss.item()If the loss is not converted to a Python number when accumulating losses, it may lead to increased program memory usage. This is because the right side of the above expression was originally a Python float, but it is now a zero-dimensional tensor. Therefore, the total loss accumulates tensors and their gradient history, which may generate a large autograd graph, consuming memory and computational resources.
4. Usage of torch.Tensor.detach()
The official description of detach() is as follows:
Returns a new Tensor, detached from the current graph. The result will never require gradient.
Assuming there are models A and B, and we need to use the output of A as input to B, but during training, we only train model B. This can be done as follows:
input_B = output_A.detach()This can break the gradient propagation between the two computation graphs, achieving the desired functionality.
5. ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm)
This error occurs when running training code in docker on the server, with the batch size set too large, and there is insufficient shared memory (because docker limits shm). The solution is to set the num_workers of Dataloader to 0.
6. Parameter Settings for Loss Functions in PyTorch
Taking CrossEntropyLoss as an example:
CrossEntropyLoss(self, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='elementwise_mean')-
If reduce = False, then the size_average parameter is invalid, and it directly returns the loss in vector form, i.e., the loss corresponding to each element in the batch.
-
If reduce = True, then the loss returns a scalar:
-
If size_average = True, it returns loss.mean().
-
If size_average = False, it returns loss.sum().
-
weight: Input a 1D weight vector to weight the loss of each category, as shown in the following formula:
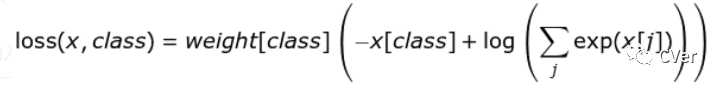
-
ignore_index: Select the target values to ignore, so that they do not contribute to the input gradient. If size_average = True, then only the mean of the loss for the non-ignored targets is calculated.
-
reduction: Optional parameters are:‘none’ | ‘elementwise_mean’ | ‘sum’, as the parameters literally mean, no further explanation.
7. Techniques That May Improve Model Accuracy in Metric Learning
From the comments of a Zhihu expert:
-
Background: When using BFE-net for reidentification, the backbone selected is resnet50, but without warm-up, the accuracy did not meet expectations. The dialogue and solutions from experts:

Find the author’s git commit record:
if ep < 50:
lr = 1e-4*(ep//5+1)
elif ep < 200:
lr = 1e-3
elif ep < 300:
lr = 1e-4Conclusion: In February, two lines of code were added, simply using a lower learning rate for warm-up in the first 50 epochs, and then gradually returning to the normal lr.
8. Using nn.DataParallel When Data Is Not on the Same GPU
-
Background: PyTorch multi-GPU training mainly uses data parallelism:
model = nn.DataParallel(model)-
Problem: However, during a concurrent training experiment based on optical flow detection, it was found that data was not in the same CUDA. During code review, printing each node tensor revealed that the data in CUDA was not distributed across the same GPU.
-
Solution: The final solution was to execute .cuda() uniformly on the data after it was output, bringing the data into the same CUDA stream resolved the issue.
9. Potential Pitfalls When Loading PyTorch Models:
If nn.DataParallel is used for multi-card training, be sure to add .module when loading the model, as shown in the code below:
def get_model(self):
if self.nGPU == 1:
return self.model
else:
return self.model.module10. Issues with Reading .h5 Data in PyTorch:
Thanks to the comment from @Tio for sharing:
-
Background: We know that the Torch framework requires input data to conform to its own specifications, and in image recognition, the .t7 file type is used, while there is also .h5 format, which is similar to .t7 and can be used by the torch framework, but there is an official bug when reading it.
-
Problem: DataLoader, when num_worker > 0, there is a bug When reading .h5 data format, if dataloader > 0, memory will be filled, causing an error.
-
Solution:
# Test data
f = h5py.File('test.h5')
for i in range(256):
f['%s/data' % i] = np.random.uniform(0, 1, (1024, 1024))
f['%s/target' % i] = np.random.choice(1000)Solution:
# Error occurs
dataloader = torch.utils.data.DataLoader(
H5Dataset('test.h5'),
batch_size=32,
num_workers=8,
shuffle=True
)
# Solution, change num_workers to 0
dataloader = torch.utils.data.DataLoader(
H5Dataset('test.h5'),
batch_size=32,
num_workers=0,
shuffle=True
)CVer Academic Exchange Group
Scan to add the CVer assistant to apply to join the CVer-Object Detection Group, Image Segmentation, Object Tracking, Face Detection & Recognition, OCR, Super Resolution, SLAM, Medical Imaging, Re-ID, and GAN groups. Be sure to note: Research direction + Location + School/Company + Nickname (e.g., Object Detection + Shanghai + Shanghai Jiao Tong University + Kaka)

▲ Long press to join the group
Such a solid summary sharing, please give me a “looking”. Looking!
 !
!