Click the above“Beginner’s Guide to Vision”, select “Add to Favorites” or “Pin”
Important content delivered promptly
In this article, researchers from the Department of Mechanical Engineering at the University of California, Riverside, demonstrate the feasibility of a hybrid computer vision system through the application of optical vortices. This research provides new insights into the role of photonics in constructing general cerebellar hybrid neural networks and developing real-time hardware for big data analysis.
From medical diagnosis to autonomous driving and face recognition, image analysis is ubiquitous in modern technology. Computer vision has been revolutionized by deep learning convolutional neural networks. However, convolutional neural networks (CNNs) classify images by learning from pre-trained data, which often retains or develops certain biases. Furthermore, the data is vulnerable to adversarial attacks (manifesting as subtle and nearly imperceptible image distortions), leading to erroneous decisions. These shortcomings limit the utility of convolutional neural networks.One way to enhance the efficiency and reliability of image processing algorithms is to combine conventional computer vision with optical preprocessors. This hybrid system can operate with minimal electronic hardware. Since optical functions can be completed in the preprocessing stage without dissipating energy, using a hybrid computer vision system can save significant time and energy. This new approach overcomes the disadvantages of deep learning and fully leverages the advantages of optics and electronics.In August of this year, in a paper published in Optica, Assistant Professor Luat Vuong and PhD student Baurzhan Muminov from the Department of Mechanical Engineering at the University of California, Riverside, demonstrated the feasibility of a hybrid computer vision system by applying optical vortices (twisted light waves with dark central points). Optical vortices can be metaphorically likened to fluid dynamic vortices created when light propagates around edges and corners.

Paper link: https://www.osapublishing.org/optica/fulltext.cfm?uri=optica-7-9-1079&id=437484The research shows that optical preprocessing can reduce the power consumption of image computation, while digital signal recognition correlations in electronic devices provide optimized and rapid calculations of reliable decision thresholds. With hybrid computer vision, optical devices have the advantage of speed and low-power computation, reducing time costs by two orders of magnitude compared to CNNs. Through image compression, it is possible to significantly reduce the complexity of electronic backend hardware from both storage and computational perspectives.Luat Vuong stated: “The vortex encoder in this study demonstrates that optical preprocessing can eliminate the need for CNNs, is more robust than CNNs, and can generalize solutions to inverse problems. For example, when a hybrid neural network learns the shapes of handwritten digits, it can reconstruct previously unseen Arabic or Japanese characters.”The paper also indicates that reducing images to fewer high-intensity pixels enables image processing under extremely low light conditions. This research provides new insights into the role of photonics in constructing general cerebellar hybrid neural networks and developing real-time hardware for big data analysis.Summary of Paper ContentDeep learning convolutional neural networks typically involve multi-layer, forward-backward propagation machine learning algorithms with high computational costs. Therefore, in this paper, the researchers present an alternative to convolutional neural networks that reconstructs the original image from its optical preprocessing and Fourier encoding patterns. This approach requires significantly less computation and has higher noise robustness, making it suitable for imaging under high speeds and low light conditions.Specifically, the study introduces vortex phase transformations with micro-lens arrays, combined with shallow dense “cerebellar” neural networks. The single-shot coding aperture method utilizes coherent diffraction of Fourier transform spiral phase gradients, compact characterization, and edge enhancement. Using vortex encoding, the cerebellum can be trained to perform deconvolution operations on images, achieving speeds 5 to 20 times faster than using random coding schemes, while gaining greater advantages in the presence of noise.Once trained, the cerebellum can reconstruct objects from intensity-only data, solving the inverse mapping problem without performing iterations on each image or relying on deep learning schemes. Through vortex Fourier encoding, the researchers reconstructed MNIST Fashion objects illuminated with low light flux (5nJ/cm²) at several thousand frames per second on a 15W CPU. Ultimately, the researchers demonstrated that using vortex encoders for Fourier optical preprocessing is two orders of magnitude faster than convolutional neural networks while achieving similar accuracy rates.The knowledge of vortices can be extended to understand arbitrary waveforms. When accompanied by vortices, optical image data propagates in a way that highlights and mixes different parts of the optical image. The researchers noted that vortex image preprocessing using shallow “cerebellar” neural networks (requiring only a few layers of algorithms) can serve as a substitute for CNNs.Vuong also stated: “The unique advantages of optical vortices lie in their mathematical and edge enhancement capabilities. In this paper, we demonstrate that optical vortex encoders can rapidly reconstruct original images from their optical preprocessing patterns in a manner akin to a cerebellar neural network, generating target intensity data.”Methods
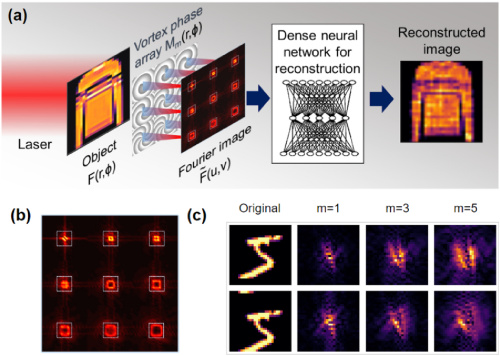
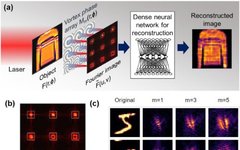
Figure 1 describes the imaging scheme of the study, where multiple images of the object F(r,Φ) are collected in the Fourier domain: the light through each micro-lens is modulated by different vortex and lens mask patterns M_m(r,Φ); the camera detects the scaled modulus square image of the Fresnel propagation and vortex-Fourier-transformed intensity pattern.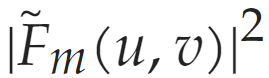 .Here, m is the vortex topological charge, r and Φ are real domain cylindrical coordinates, while u and v are Cartesian coordinates in the Fourier plane. The vortex Fourier intensity pattern F^~ is concentrated in a relatively small area, but as m increases, it typically presents an increasingly wider donut shape (Figure 1(b)). The vortex phase in the object’s “real domain” spatially encodes and disrupts the translational invariance of the Fourier transform intensity pattern, as shown in Figure 1(c).Moreover, the study considers some small image datasets as object inputs and compares different representations in F(r,Φ). For each positive real-valued dataset image X, the mapping of phase variation is shown in the following formula:
.Here, m is the vortex topological charge, r and Φ are real domain cylindrical coordinates, while u and v are Cartesian coordinates in the Fourier plane. The vortex Fourier intensity pattern F^~ is concentrated in a relatively small area, but as m increases, it typically presents an increasingly wider donut shape (Figure 1(b)). The vortex phase in the object’s “real domain” spatially encodes and disrupts the translational invariance of the Fourier transform intensity pattern, as shown in Figure 1(c).Moreover, the study considers some small image datasets as object inputs and compares different representations in F(r,Φ). For each positive real-valued dataset image X, the mapping of phase variation is shown in the following formula:
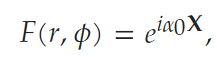
where α_0 is the dynamic range of the object phase shift. This mapping is convenient since the signal power does not change with the selected X. The researchers also consider X as opaque objects when it occludes or absorbs the signal, i.e.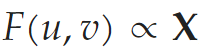 , which produces similar trends.Ultimately, the study has three main innovations: (1) edge enhancement of spectral features using vortex lenses; (2) rapid inverse reconstruction of images without similar learned datasets; (3) noise resilience depending on layer activations.Interested readers can read the original paper for more research content.Reference link: https://news.ucr.edu/articles/2020/12/11/optical-pre-processing-makes-computer-vision-more-robust-and-energy-efficient
, which produces similar trends.Ultimately, the study has three main innovations: (1) edge enhancement of spectral features using vortex lenses; (2) rapid inverse reconstruction of images without similar learned datasets; (3) noise resilience depending on layer activations.Interested readers can read the original paper for more research content.Reference link: https://news.ucr.edu/articles/2020/12/11/optical-pre-processing-makes-computer-vision-more-robust-and-energy-efficient
Good News!
Beginner’s Guide to Vision Knowledge Community
Is now open to the public👇👇👇
Download 1: Chinese Version Tutorial for OpenCV-Contrib Extension Modules
Reply "Chinese Tutorial for Extension Modules" in the backend of the "Beginner's Guide to Vision" public account to download the first Chinese version of the OpenCV extension module tutorial, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: 52 Lectures on Practical Python Vision Projects
Reply "Python Vision Practical Projects" in the backend of the "Beginner's Guide to Vision" public account to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: 20 Lectures on Practical OpenCV Projects
Reply "20 Lectures on Practical OpenCV Projects" in the backend of the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV for advanced learning of OpenCV.
Discussion Group
Welcome to join the reader group of the public account to exchange with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GANs, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format, otherwise, the invitation will not be accepted. After successfully adding, you will be invited to join the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise you will be removed from the group. Thank you for your understanding~