
Machine Heart released
How to better, faster, and cheaper achieve training and fine-tuning of AIGC models has become the biggest pain point for the commercialization and explosive application of AIGC.
Colossal-AI, based on its professional technical accumulation in democratizing large models,open-sourced a complete Stable Diffusion pre-training and personalization fine-tuning solution, accelerating pre-training time and reducing economic costs by 6.5 times, and lowering hardware costs for personalized fine-tuning by 7 times! Fine-tuning tasks can be quickly completed on personal computers with RTX 2070/3050, making AIGC models like Stable Diffusion easily accessible.
Open-source address:
https://github.com/hpcaitech/ColossalAI
The Booming AIGC Track and High Costs
AIGC (AI-Generated Content) is one of the hottest topics in the AI field today, especially with the emergence of cross-modal applications represented by Stable Diffusion, Midjourney, NovelAI, DALL-E, etc., AIGC has gained immense attention.

Due to the massive demand for AIGC, it is regarded as one of the important directions for the next wave of AI. The industry widely anticipates a new technological revolution and killer applications based on AIGC in various technical scenarios such as text, audio, image video, gaming, and the metaverse. The successful commercialization of AIGC in related scenarios presents a potential market worth trillions of dollars, making related startups like Stability AI and Jasper, which have raised over a hundred million dollars in just a year or two, the darlings of capital.
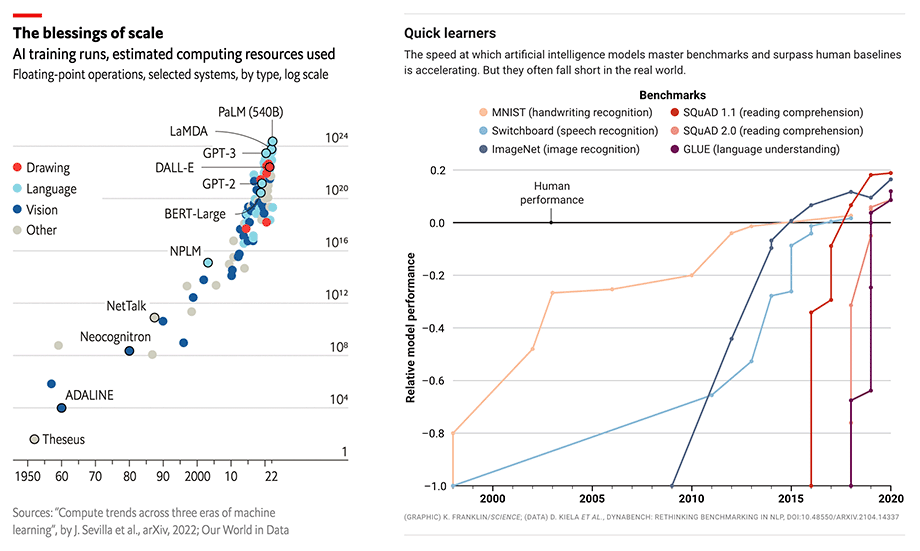
However, high hardware demands and training costs still severely hinder the rapid development of the AIGC industry. The excellent performance of AIGC applications is usually built on large models like GPT-3 or Stable Diffusion and fine-tuned for specific downstream tasks and applications. Taking the popular Stable Diffusion as an example, despite its founding team Stability AI being established recently, itmaintains a cluster of over 4000 NVIDIA A100 GPUs and has spent over 50 million dollars on operational costs, with a single training session for the Stable Diffusion v1 model requiring 150,000 A100 GPU hours.
Diffusion model
The idea of the Diffusion model was first proposed in the 2015 paper “Deep Unsupervised Learning using Nonequilibrium Thermodynamics”. The 2020 paper “Denoising Diffusion Probabilistic Models” (DDPM) pushed it to a new height, and subsequently, models based on diffusion such as DALL-E 2, Imagen, and Stable Diffusion achieved far superior results in generation tasks compared to traditional generative models like GANs, VAEs, and AR models.
The diffusion model consists of two processes: the forward diffusion process and the reverse generation process. The forward diffusion process gradually adds Gaussian noise to an image until it becomes random noise, while the reverse generation process is the denoising process, which uses multiple U-Nets to gradually denoise random noise until an image is generated. This is also part of the training of the diffusion model.
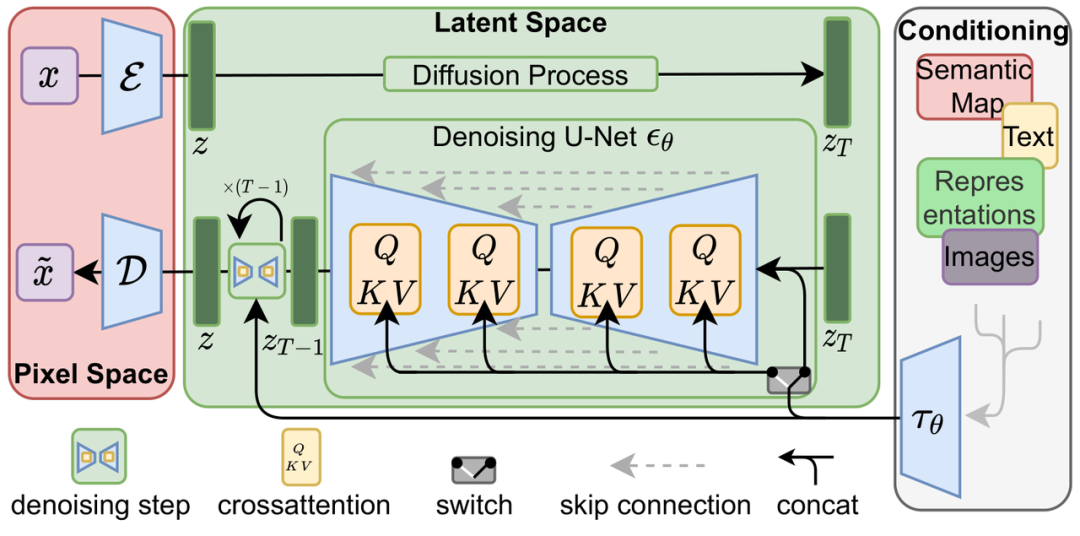
Compared to traditional end-to-end deep learning models, the training process of the diffusion model is undoubtedly more complex. Taking Stable Diffusion as an example, in addition to the diffusion model itself, there is also a Frozen CLIP Textcoder to input text prompts, and an Autoencoder to compress high-resolution images into latent space (Latent Space) and calculate loss at each time step. This presents greater challenges for memory consumption and computational speed in training schemes.
Lower Costs – Pre-training Acceleration and Resource-Limited Fine-tuning
Pre-training Optimization
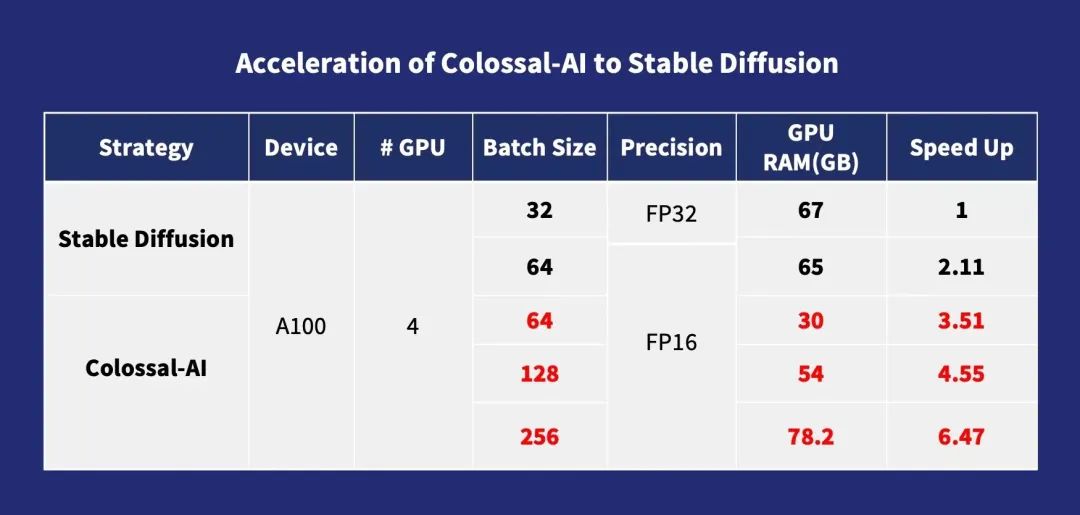
Personalized Fine-tuning Optimization
Since the pre-training of Stable Diffusion uses the LAION-5B dataset with a total of 585 billion image-text pairs, requiring 240TB of storage, combined with the model’s complexity, it is evident that the cost of complete pre-training is extremely high: the Stability team of Stable Diffusion has spent over 50 million dollars to deploy 4,000 A100 GPUs. For most AIGC players, a more practical choice is to use open-source pre-trained model weights for fine-tuning personalized downstream tasks.
However, the training parallelism methods used in other existing open-source fine-tuning solutions mainly utilize DDP, which leads to significant memory consumption during training,even fine-tuning requires at least the highest-end consumer graphics cards like RTX 3090 or 4090 to start.At the same time,many currently open-source training frameworks do not provide complete training configurations and scripts, requiring users to spend additional time on tedious completion and debugging.
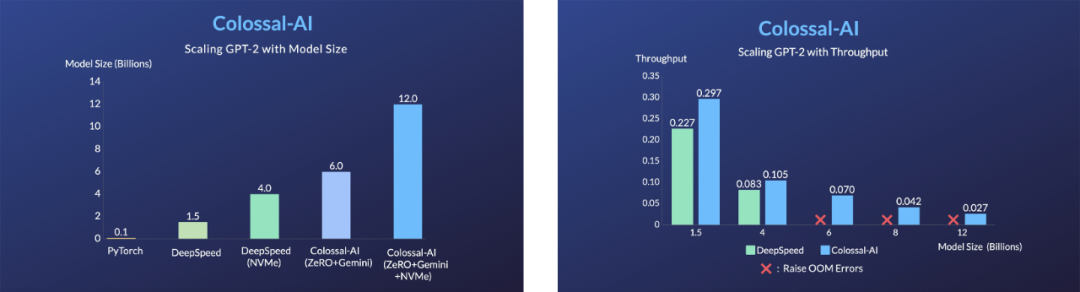
Unlike other solutions, Colossal-AI isthe first to open-source complete training configuration parameters and training scriptsallowing users to train the latest fine-tuned models for new downstream tasks at any time, using a more flexible and widely applicable approach. Moreover, due to the introduction of memory optimization technologies by Colossal-AI,fine-tuning tasks can be quickly completed on a single consumer-grade graphics card (like GeForce RTX 2070/3050 8GB), reducing hardware costs by approximately 7 times compared to RTX 3090 or 4090, greatly lowering the barriers and costs for using AIGC models like Stable Diffusion, allowing users to no longer be limited to existing weight inference and easily complete personalized customization services. For tasks that are not sensitive to speed, Colossal-AI NVMe can be further used to reduce memory consumption by utilizing low-cost disk space.
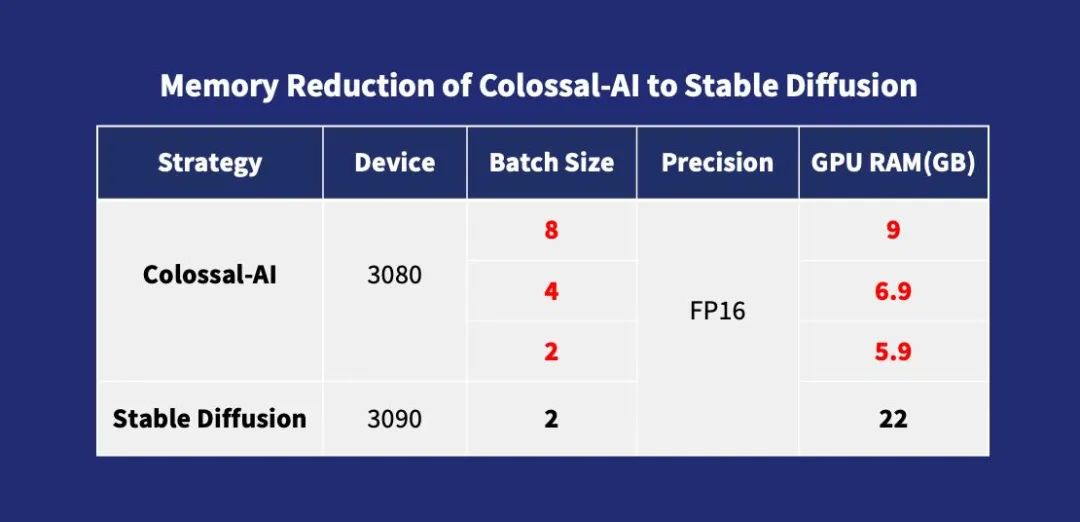
Memory Reduction of Colossal-AI to Stable Diffusion
Underlying Optimization Technologies
ZeRO + Gemini
Colossal-AI supports the use of the Zero Redundancy Optimizer (ZeRO) method to eliminate memory redundancy, which can greatly improve memory usage efficiency compared to classic data parallelism strategies, without sacrificing computational granularity and communication efficiency.
Colossal-AI introduces the Chunk mechanism, allowing us to further enhance ZeRO’s performance. A group of parameters that are sequentially operated on is stored in a Chunk (which is a contiguous memory space), with each Chunk being the same size. Organizing memory in chunks ensures efficient utilization of network bandwidth between PCI-e and GPU-GPU, reduces communication frequency, and avoids potential memory fragmentation.
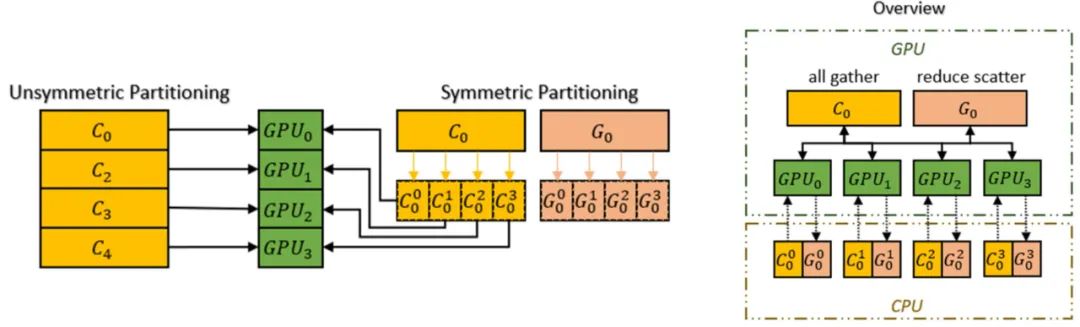
Additionally, Colossal-AI’s heterogeneous memory space manager Gemini supports offloading optimizer states from GPU to CPU to save GPU memory usage. It can simultaneously utilize GPU memory and CPU memory (composed of CPU DRAM or NVMe SSD memory) to break through the single GPU memory wall, further expanding the scale of trainable models.
Flash Attention
LDM (Latent Diffusion Models) introduces cross-attention layers into the model architecture to achieve multi-modal training, allowing the Diffusion model to flexibly support class-condition, text-to-image, and layout-to-image. However, compared to the original CNN layers of the Diffusion model, the cross-attention layer adds additional computational overhead, significantly increasing training costs.
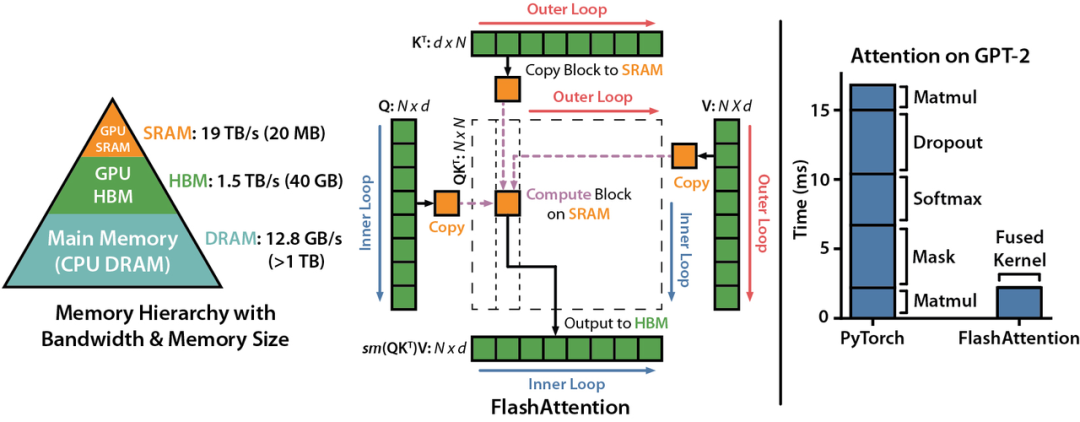
Colossal-AI successfully improves the speed of attention by 104% and reduces peak memory usage for end-to-end training by 23% by introducing the Flash attention mechanism. Flash attention is an accelerated version of attention for long sequences, using Flatten to reduce memory read/write times between high-bandwidth memory (HBM) of GPUs. Flash attention also designs an approximate attention algorithm for block-sparse attention that is faster than any existing approximate attention method.
Other Optimizations
Colossal-AI also integrates common optimization techniques such as FP16 and activation checkpointing. For instance, activation checkpointing works by trading computation for memory. It avoids storing all intermediate activations of the computational graph for backward computation, not saving intermediate activations at checkpoints but recomputing them during backpropagation, further reducing memory usage. FP16 reduces memory usage and improves computational efficiency by converting 32-bit floating-point operations to 16-bit without significantly affecting accuracy.
Quick Start
Unlike common PyTorch open-source projects, the currently popular stable diffusion is built on PyTorch Lightning. PyTorch Lightning provides a concise and efficient high-level interface for the popular deep learning framework PyTorch, offering a clean and easy-to-use high-level abstraction for AI researchers, making deep learning experiments easier to read and reproduce, and has garnered 20.5k stars on GitHub.
Invited by PyTorch Lightning, Colossal-AI has been integrated as the official large model solution of PyTorch Lightning.Thanks to the strong collaboration between the two, AI researchers can now train and use diffusion models more efficiently. For example, to train the stable diffusion model, only a small amount of code is needed to get started quickly.
from colossalai.nn.optimizer import HybridAdamfrom lightning.pytorch import trainer
class MyDiffuser(LightningModule): ...
def configure_sharded_model(self) -> None: # create your model here self.model = construct_diffuser_model(...) ...
def configure_optimizers(self): # use the specified optimizer optimizer = HybridAdam(self.model.parameters(), self.lr) ...
model = MyDiffuser()trainer = Trainer(accelerator="gpu", devices=1, precision=16, strategy="colossalai")trainer.fit(modelColossal-AI and PyTorch Lightning also provide good support and optimization for popular models and communities like OPT and HuggingFace.
Low-Cost Fine-tuning
Colossal-AI aims to meet users’ needs to train models that can generate their own styles with fewer resources in a short time, offering fine-tuning capabilities based on open-source Stable Diffusion model weights from HuggingFace. Users only need to modify the Dataloader to load their fine-tuning dataset and read the pre-trained weights, simply adjust the parameter configuration YAML file, and run the training script to fine-tune their personalized model on a personal computer.
model: target: ldm.models.diffusion.ddpm.LatentDiffusion params: your_sub_module_config: target: your.model.import.path params: from_pretrained: 'your_file_path/unet/diffusion_pytorch_model.bin' ...
lightning: trainer: strategy: target: pytorch_lightning.strategies.ColossalAIStrategy params: ...
python main.py --logdir /your_log_dir -t -b config/train_colossalai.yamlQuick Inference
Colossal-AI also supports the native Stable Diffusion inference pipeline. After completing training or fine-tuning, users can directly call the diffuser library and load their saved model parameters for inference without any other modifications, making it easier for new users to familiarize themselves with the inference process and allowing users accustomed to the original framework to get started quickly.
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained( "your_ColoDiffusion_checkpoint_path" ).to("cuda")
image = pipe('your prompt', num_inference_steps=50)["sample"][0]image.save('file path')
The generated work from the above inference process
One More Thing
The above-mentioned breakthroughs in training optimizations for Diffusion, represented by AIGC, are based on the general deep learning system Colossal-AI, which achieves efficient and rapid deployment of large AI model training and inference through efficient multi-dimensional automatic parallelism, heterogeneous memory management, large-scale optimization libraries, and adaptive task scheduling, reducing the application costs of large AI models. Since its open-source release, Colossal-AI has repeatedly ranked first on GitHub and Papers With Code hot lists, attracting attention both domestically and internationally alongside many star open-source projects with tens of thousands of stars! After rigorous review by international experts,Colossal-AI has been successfully selected as the official tutorial for top international AI and HPC conferences such as SC, AAAI, and PPoPP.
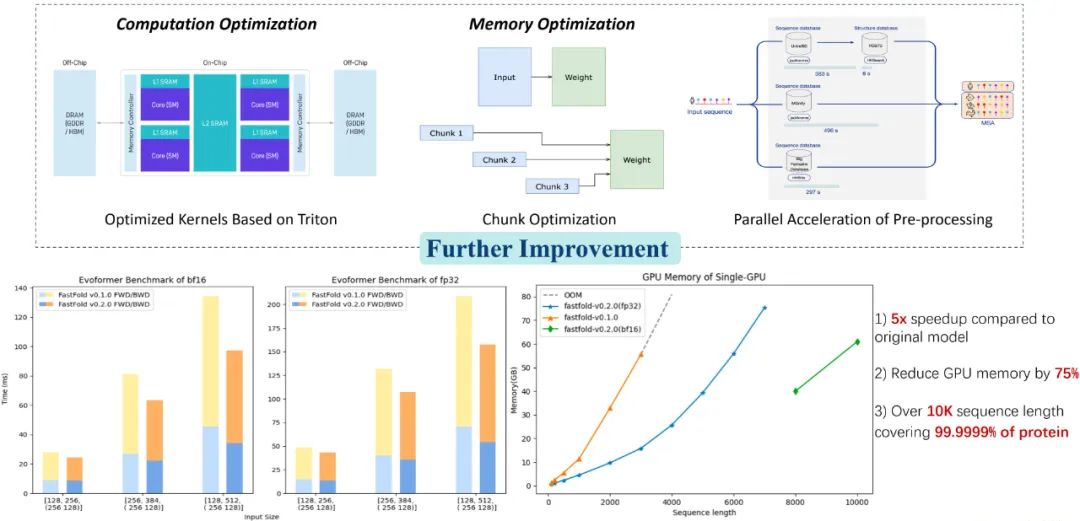
Colossal-AI Application: Better Protein Structure Prediction Solutions
Colossal-AI related solutions have been successfully applied in well-known manufacturers in industries such as autonomous driving, cloud computing, retail, pharmaceuticals, and semiconductors, receiving widespread acclaim. For example, for the biopharmaceutical industry, the protein structure prediction model AlphaFold, based on Colossal-AI’s optimization scheme FastFold, has successfully broken through the maximum amino acid sequence length that can be inferred on a single GPU to ten thousand, covering 99.9999% of proteins, and can decode 90% of proteins using only consumer-grade graphics cards on a laptop. It can further accelerate the entire process of training and inference in parallel, helping many new drug development companies shorten development processes and reduce research and development costs.
Open-source address:
https://github.com/hpcaitech/ColossalAI
Reference Links
https://github.com/CompVis/stable-diffusion
https://arxiv.org/abs/2205.14135
https://arxiv.org/abs/2112.10752
https://openai.com/blog/triton/
https://medium.com/@yangyou_berkeley/diffusion-pretraining-and-hardware-fine-tuning-can-be-almost-7x-cheaper-85e970fe207b
© THE END
For reprints, please contact this public account for authorization
Submissions or inquiries: [email protected]