
Click on the "Xiaobai Learns Vision" above, choose to add "Starred" or "Pinned"
Heavyweight content delivered at the first time
Introduction
MoD is a new method for Convolutional Neural Networks (CNNs) that improves computational efficiency by selectively processing channels. Unlike traditional static pruning methods, MoD adopts a dynamic computation approach, adjusting computational resources based on the complexity of the input.
Reprinted from丨3D Machine Vision Workshop
0. Paper Information
Title: CNN Mixture-of-Depths
Authors: Rinor Cakaj, Jens Mehnert, Bin Yang
Original Link: https://arxiv.org/abs/2409.17016
1. Abstract
We introduce a new method for Convolutional Neural Networks (CNNs) called Mixture-of-Depths (MoD), which improves the computational efficiency of CNNs by selectively processing channels based on their relevance to the current prediction. This method optimizes computational resources by dynamically selecting key channels from feature maps for focused processing within convolutional blocks (Conv blocks), while skipping less relevant channels. Unlike conditional computation methods that require dynamic computation graphs, CNN MoD uses static computation graphs with fixed tensor sizes, enhancing hardware efficiency. It accelerates training and inference processes without the need for custom CUDA kernels, unique loss functions, or fine-tuning. CNN MoD either matches the performance of traditional CNNs with reduced inference time, GMACs, and parameters or exceeds their performance while maintaining similar inference time, GMACs, and parameters. For example, on ImageNet, the performance of ResNet86-MoD exceeds that of standard ResNet50 by 0.45%, with acceleration of 6% and 5% on CPU and GPU, respectively. Additionally, ResNet75-MoD achieves the same performance as ResNet50 while accelerating 25% on CPU and 15% on GPU.
2. Introduction
In recent years, Convolutional Neural Networks (CNNs) have made significant progress in various computer vision applications such as image recognition, object detection, and image segmentation. Despite their excellent performance, CNNs typically require substantial computational power and extensive memory usage, posing significant challenges when deploying advanced models on resource-limited devices.
To address these challenges, pruning techniques have been widely applied to reduce the model size and computational demands of CNNs by removing redundant weights or filters based on established criteria. However, these methods uniformly process all inputs and cannot adjust to the varying complexities of different inputs, which may lead to performance degradation.
Another approach is dynamic computation or conditional computation, which adjusts computational resources based on the complexity of the input to improve efficiency. However, because these methods rely on dynamic computation graphs, which are often incompatible with systems optimized for static computation workflows, integrating them into hardware can be challenging. For example, Wu et al. reported that processing time increases when layers are conditionally executed through a separate policy network. Although computational demands are theoretically reduced, actual gains on hardware such as GPUs or FPGAs are limited because non-uniform tasks interfere with the efficiency of standard convolution operations. Additionally, Ma et al. demonstrated that floating-point operations (FLOPS) are insufficient for estimating inference speed, as they often exclude element-wise operations such as activation functions, summation, and pooling.
To combine the performance advantages of dynamic computation with the operational efficiency of static computation graphs, we propose CNN’s Mixture-of-Depths (MoD) inspired by the Mixture-of-Depths method developed for Transformers. The fundamental principle of CNN MoD is that only a selected subset of channels within the feature map at a given layer of the network is crucial for effective convolution processing. By focusing on these key channels, CNN MoD enhances computational efficiency without compromising network performance.
Next, the channel selector identifies the most important k channels using a top-k selection mechanism based on computed importance scores. These channels are sent to the Conv-Block, designed to operate on reduced dimensions, thereby improving computational efficiency. To ensure that gradients from the processed output \hat{X} effectively optimize the channel selection process, the processed channels are scaled according to their respective importance scores. This allows gradients to flow back to the channel selector, learning the importance of channels throughout the training process.
The final step is the fusion operation, adding the processed channels to the top k channels of the original feature map. This fusion not only preserves the original dimensions of the feature map but also enhances feature representation by combining processed and unprocessed channels. Recommended Course:Fully Managed! Deployment Based on TensorRT + CUDA Acceleration.
The reduction in the number of processed channels within the Conv-Block is controlled by a hyperparameter, where k defines the number of channels to be processed. Here, C is the total number of input channels in the Conv-Block. For example, in a typical ResNet architecture, a bottleneck block that usually processes 1024 channels processes only 16 channels (k=16) when c=64. This selective processing significantly reduces the computational load by focusing on a smaller subset of channels. Additionally, the kernel size of the Conv-Block is also adjusted according to the reduction in the number of input channels.
Empirical evaluations indicate that the optimal integration of MoD within CNN architectures involves alternating it with standard Conv-Blocks. In architectures like ResNets or MobileNetV2, Conv-Blocks are organized into modules containing multiple Conv-Blocks of the same type (i.e., with the same number of output channels). Each module starts with a standard block followed by a MoD block. This alternating arrangement is based on the Mixture-of-Depths principle of Transformers. It does not imply adding extra MoD blocks to the existing sequence but rather replacing every second Conv-Block in the original architecture with a MoD block, ensuring the overall depth of the architecture remains unchanged.
3. Performance Demonstration
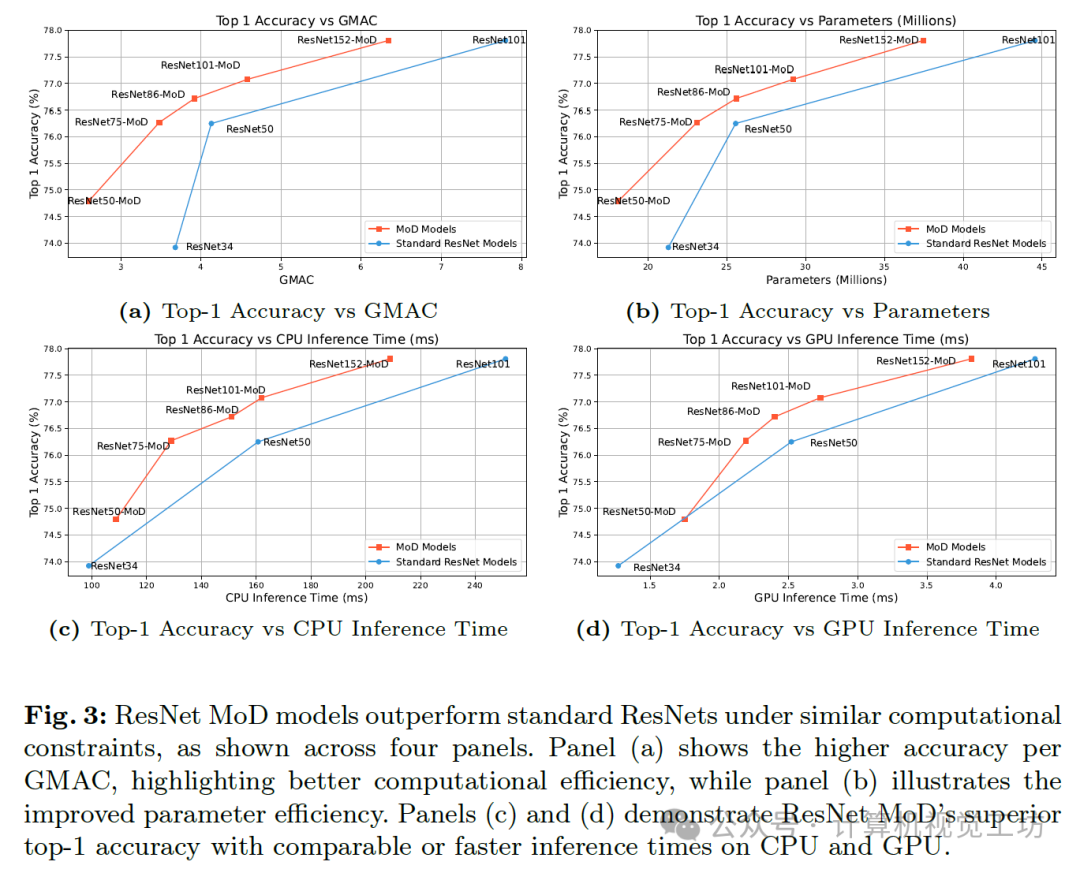
As shown in the four panels of the figure, the performance of the ResNet MoD model outperforms standard ResNet under similar computational constraints. Panel (a) demonstrates higher accuracy per GMAC (Giga Multiply-Accumulate Operations per second), highlighting better computational efficiency, while panel (b) illustrates improved parameter efficiency. Panels (c) and (d) show that ResNet MoD achieves comparable or faster inference times on both CPU and GPU while attaining higher top-1 accuracy.
4. Main Contributions
CNN MoD achieves performance comparable to traditional CNNs but with shorter inference times, fewer GMACs, and parameters, or exceeds them while maintaining similar inference times, GMACs, and parameters. On the ImageNet dataset, our ResNet75-MoD matches the accuracy of standard ResNet50 while providing a 15% speed boost on GPU and a 25% speed boost on CPU. Similar results can be achieved in semantic segmentation and object detection tasks.
5. Methodology
As shown in Figure 1, the MoD mechanism enhances CNN feature map processing by dynamically selecting the most important channels within the Conv-Block for focused computation.
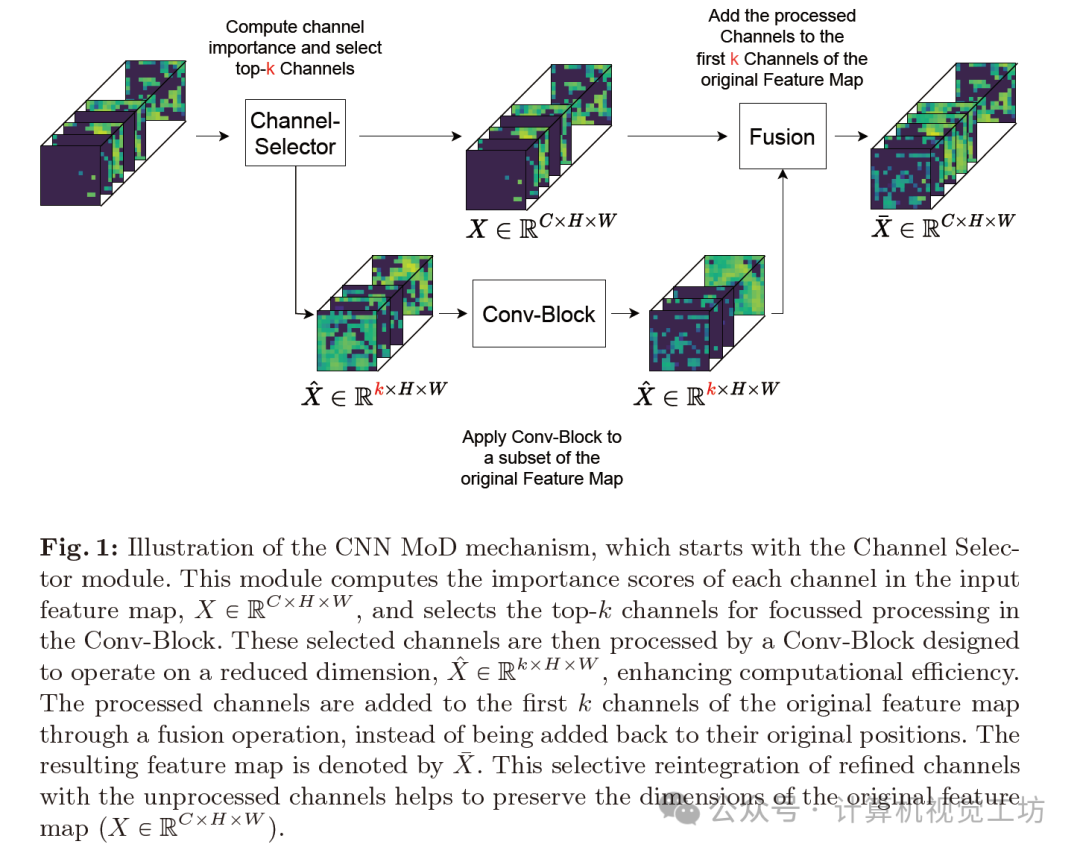
MoD begins with a channel selector, as shown in Figure 2, designed similarly to a Squeeze-and-Remember block. It evaluates the input feature map X and processes it through a two-layer fully connected neural network with a bottleneck design. A Sigmoid activation function generates scores indicating the importance of each channel.

6. Experimental Results
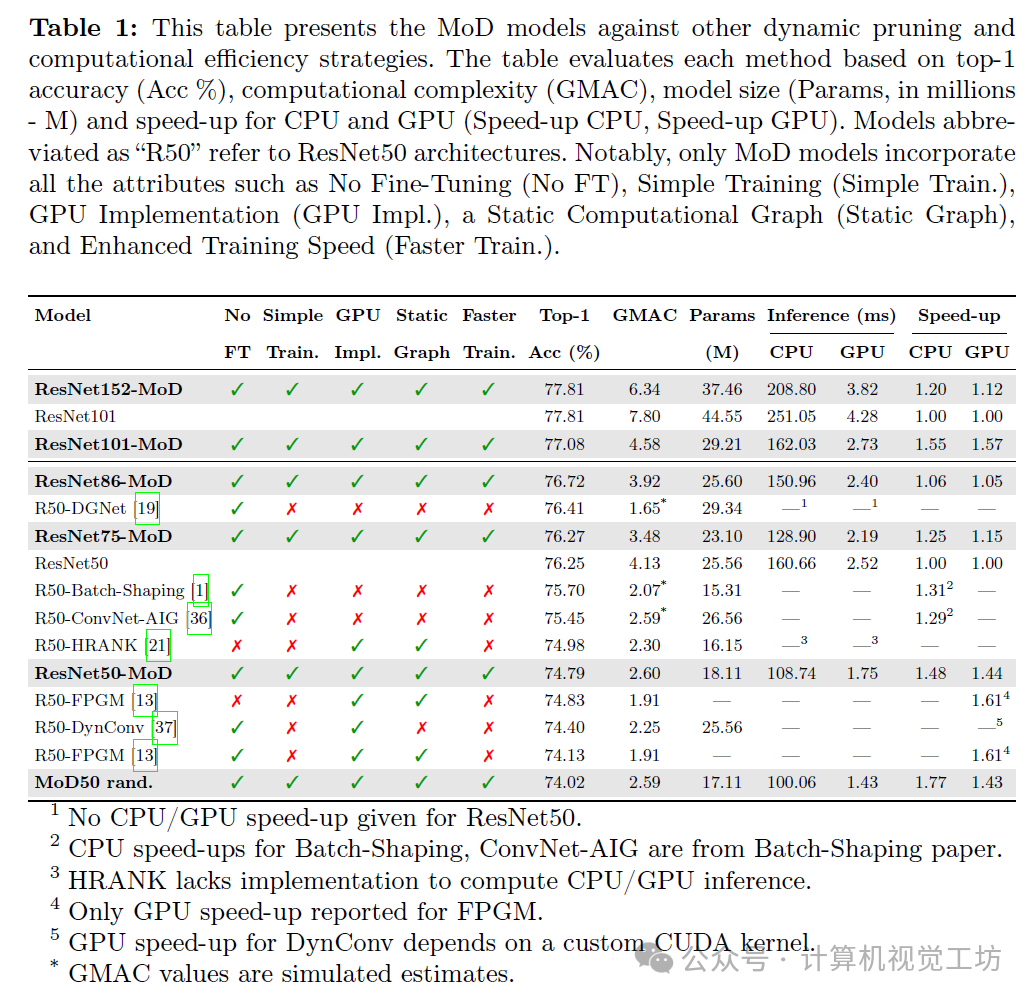
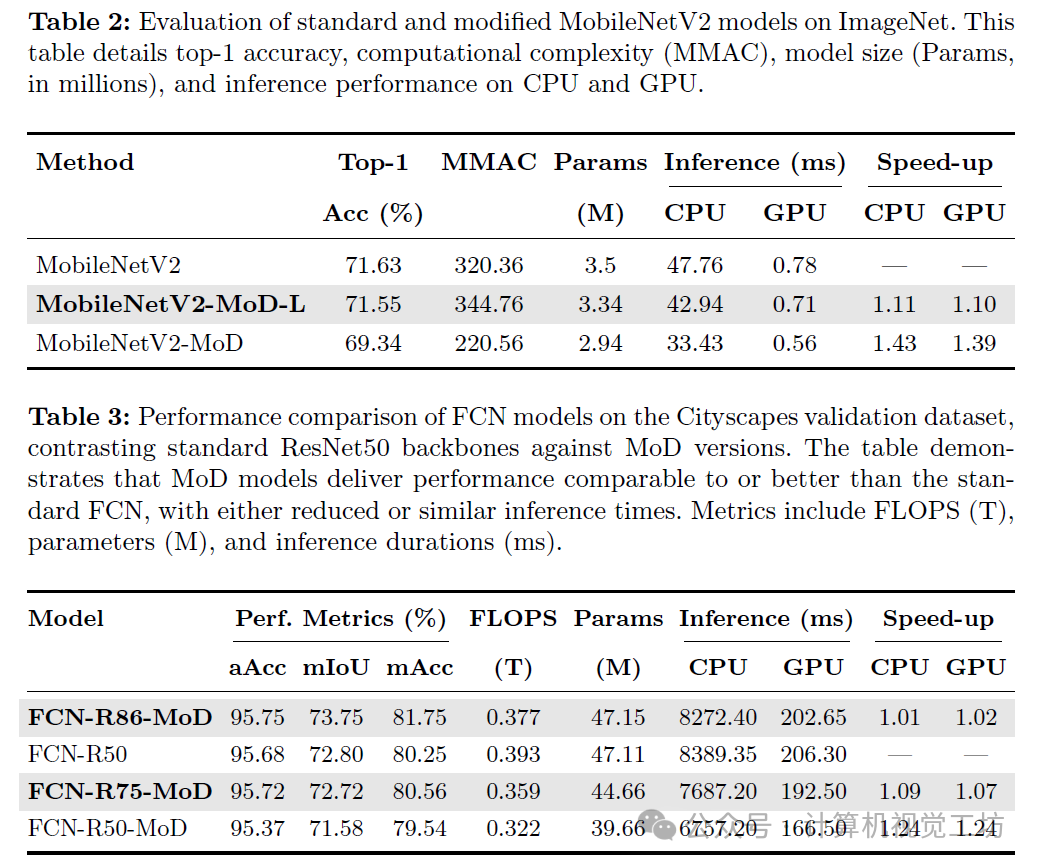
7. Conclusion & Future Work
In this study, we proposed the CNN MoD method, inspired by the Mixture-of-Depths method developed for Transformers. This technique combines the advantages of static pruning and dynamic computation within the same framework. It optimizes computational resources by dynamically selecting key channels in the feature map for targeted processing while skipping less relevant channels.
It maintains a static computation graph, optimizing training and inference speeds without the need for custom CUDA kernels, additional loss functions, or fine-tuning. These features distinguish MoD from other dynamic computation methods, greatly simplifying the training and inference processes. CNN MoD achieves performance comparable to traditional CNNs in image recognition, semantic segmentation, and object detection, while reducing inference time, GMACs, and parameter counts, or exceeding traditional CNNs while maintaining similar inference time, GMACs, and parameter counts. For example,
on ImageNet, ResNet86-MoD achieves speed boosts of 6% on CPU and 5% on GPU while outperforming standard ResNet50’s performance by 0.45%. Additionally, ResNet75-MoD achieves a 25% speed boost on CPU and a 15% speed boost on GPU while matching the performance of ResNet50.
While the current fusion operation has achieved significant efficiency improvements, especially in high-dimensional datasets like ImageNet and practical tasks such as Cityscapes and Pascal VOC, further optimization of the slicing operation may yield greater improvements. Future work will explore methods to optimize this component, potentially through custom CUDA kernels. Additionally, further research into the optimal number of processed channels within layers holds promise for optimizing performance.
Interested readers can refer to the original paper for more experimental results and article details~
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of the "Xiaobai Learns Vision" public account to download the first Chinese version of OpenCV extension module tutorial on the internet, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the backend of the "Xiaobai Learns Vision" public account to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, helping to quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the backend of the "Xiaobai Learns Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will be gradually subdivided in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format, otherwise, you will not be approved. After successfully adding, you will be invited to relevant WeChat groups based on research direction. Please do not send advertisements in the group, otherwise, you will be removed. Thank you for your understanding~