

China boasts a brilliant civilization with thousands of years of history, leaving behind a vast amount of ancient texts. These precious materials are important material carriers for the inheritance of our national culture, embodying rich historical legacies and possessing multiple cultural and social values. Over time, the already rare existing ancient texts have become increasingly fragile. Therefore, it is imperative to promote the digitization of ancient texts vigorously. This not only preserves ancient texts but also promotes multidimensional development in areas such as text retrieval, dissemination, information mining, and knowledge discovery. Among these, Optical Character Recognition (OCR) is one of the core supporting technologies for the digitization of ancient texts. The theme of today’s report is OCR for complex and diverse ancient texts, and I will provide a brief overview from three aspects: data, methods, and applications, focusing on our team’s research work in ancient text OCR over the past two years.
1. Research Background
Relevant work on the digitization of ancient texts has been carried out in China for decades, with typical projects including the Dunhuang manuscripts, the Siku Quanshu, and the Tripitaka. The basic ancient text database of China has gradually included many digitized ancient texts, but these texts only account for a small part of the total ancient texts in the country. For example, from 2000 to 2018, the total number of materials in the basic ancient text database was about 20,000 volumes, but according to reports from the national ancient text census led by the National Library since 2016, there are over 7 million existing ancient texts. It is evident that a majority of ancient texts have yet to be digitized, which severely hinders research related to knowledge mining, information discovery, and knowledge graphs concerning ancient texts.
In discussions with experts in the field of ancient text applications, I found that their demand for digitization is quite high; even if the recognition accuracy is not high, it can significantly reduce their workload. For instance, if these experts are studying the evolution of an ancient script or a particular poetic form, we can quickly locate the relevant content they need from a large number of ancient texts through information retrieval techniques. Therefore, the digitization of ancient texts is a highly valuable and meaningful task.
However, the digitization of ancient texts is extremely challenging. Unlike modern literature, ancient texts have their own characteristics. As shown in Figure 1, ancient texts exhibit dense text, significant variations in fonts, and complex layouts, all of which pose substantial challenges to recognition. Figure 2 shows a test image from the ancient text dataset we constructed; some characters are written neatly and can be easily recognized by the human eye. However, our team’s tests found that current mainstream OCR engines from major companies fail to achieve good recognition accuracy, with the highest being around 80% and the lowest as low as about 10%. Such performance is far from comparable to the recognition accuracy of scene text or handwriting, indicating that there is still a lot of research work to be done in the field of ancient text OCR.

Figure 1 Example of Ancient Document Image

Figure 2 Test Image of Ancient Text
The digitization and intelligentization of ancient texts is one of the research areas highly valued at the national level. In April last year, the General Office of the CPC Central Committee and the General Office of the State Council issued the “Opinions on Promoting the Work of Ancient Texts in the New Era,” which clearly stated the need to protect, inherit, and develop the country’s precious cultural heritage, utilizing information technology and artificial intelligence to carry out research and practice in structuring ancient text content, systematizing knowledge, and intelligent utilization. Among these, OCR is the key first step in the digitization of ancient texts, text structuring, and intelligent utilization.
2. Chinese Ancient Text Dataset
Today, deep learning technology is rapidly developing and maturing. As long as we have high-quality annotated data, conventional ancient document recognition can achieve considerable accuracy. As Director Yu Tianxiu of the Dunhuang Academy stated in his first presentation, the recognition rate for Dunhuang manuscripts has reached about 97%.
However, recognizing ancient texts in complex scenarios remains quite challenging, one of the difficulties being the lack of data. To carry out related work, several Chinese ancient text datasets have been released. Our team has constructed a diverse ancient text dataset (MTH), which has been expanded to MTHv2. MTHv2 contains a total of 2,200 images, encompassing approximately 760,000 characters. In 2021, Professor Liu Chenglin’s team from the Institute of Automation at the Chinese Academy of Sciences released an ancient single-character dataset (CASIA-AHCDB). As far as I know, CASIA-AHCDB is currently the dataset with the most categories and the largest number of single-character samples. Notably, CASIA-AHCDB includes images of single characters in two styles, one of which additionally includes over ten different ancient Buddhist texts from various periods. Therefore, this dataset can be used to study tasks such as sample transfer, domain adaptation, zero-shot recognition, and open-set recognition. MTHv2 and CASIA-AHCDB are currently the two largest Chinese ancient text datasets.
In 2019, the International Conference on Document Analysis and Recognition (IC-DAR) held a competition on understanding Chinese genealogies, which included text line recognition, pixel-level layout analysis, and end-to-end text line detection and recognition tasks. The genealogy dataset used in the competition (HDRC-Chinese) contains over 10,000 images. Unfortunately, the training set is no longer available for download.
Additionally, our team launched a Chinese ancient text layout analysis dataset (SCUT-CAB) last year. Layout analysis is also a crucial aspect of ancient text OCR. If we can analyze the layout of ancient texts, it will undoubtedly benefit detection and recognition. This dataset is divided into a logical layout data subset and a physical layout data subset. In the logical layout dataset, we defined 27 different categories based on the typography of ancient texts, including layout type, author, title, header, footer, etc.
Recently, our team is in the process of creating a complex and diverse ancient document image dataset, which is expected to be released in the second half of this year. The preliminary scale of this dataset is 4,000 images, covering classic works from Confucianism, Taoism, Buddhism, and Traditional Chinese Medicine. Since this dataset contains some precious ancient texts that cannot be scanned and must be photographed open, the text in the ancient images may exhibit deformation. Therefore, processing this dataset is relatively more challenging, and how to achieve better recognition despite the deformation is a key focus of related research.
3. Intelligent Structured Recognition Solutions for Ancient Document Images
For the aforementioned complex and diverse scenarios of ancient text data, we utilize techniques from computer vision (CV) and OCR to establish a complete solution for intelligent analysis and reading order understanding of ancient texts. The entire solution process is shown in Figure 3, which is divided into data preprocessing, text line detection, end-to-end connection, text line recognition, and reading order prediction, with images as input and structured results as output. The techniques used in the solution come not only from our team’s published work but also from the research findings of other researchers in the OCR field. Today, I will focus on sharing the specific process of this solution.
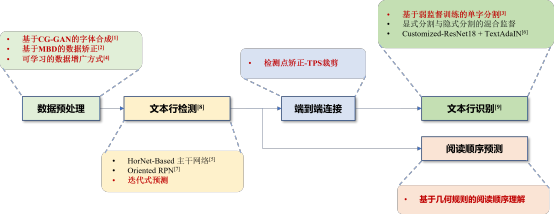
Figure 3 Flowchart of Intelligent Structured Recognition Solutions for Ancient Document Images
(1) Irregular Ancient Text Line Detection
First, I will introduce the irregular ancient text line detection in the solution. Initially, we attempted to use detectors designed for scene text to detect ancient document images, but such methods are not robust for dense text in images and do not perform as well as general detectors in the CV field. Therefore, to address the issues of dense text and irregular shapes and layouts in ancient document images, we designed a targeted model based on Cascade Mask R-CNN. First, we adopted a new backbone network, HorNet. Second, we changed the detected rectangular boxes to multi-directional rectangular boxes to accommodate text of any shape. Third, we designed an iterative prediction scheme. Additionally, we performed image correction preprocessing to assist subsequent detection. I will introduce these four points separately.
For the backbone network, we experimentally selected HorNet, which performs well on dense text, and incorporated traditional feature pyramid techniques (FPN). Considering the dense nature of ancient text lines and the presence of many rotations and distortions, we employed the Oriented-RPN regression method to predict multi-directional rectangular boxes. This type of box has excellent segmentation fitting capabilities for arbitrarily curved text. Moreover, to enhance detection accuracy, we designed an iterative prediction scheme. Through multiple iterations, we continuously refined the predicted results of the detection boxes. Without increasing any storage requirements, this scheme can further enhance detection performance.
For curved and distorted text in non-contact precious ancient texts, we need to perform appropriate image preprocessing to correct the curved text. First, we used the rule-based data synthesis method proposed in DocUNet to perform geometric deformation data synthesis, and then utilized the synthetic data to adjust our correction engine. The correction engine primarily employs the MBD module proposed in our team’s document correction model, Marior. MBD is also rule-based and does not require training with deep neural networks. In simple terms, we first detect reference points using traditional methods, and then perform thin plate spline (TPS) transformation based on the reference points to correct the images. The correction preprocessing significantly aids subsequent detection results.
After incorporating the above improvements into Cascade Mask R-CNN, the detection performance improved significantly. Subsequently, we made some engineering optimizations, such as large-scale input, multi-anchor box scales, and random cropping, further enhancing detection performance. Overall, commonly used scene text detection methods like DBNet++, PAN, and PSENet do not perform as well on ancient text detection compared to traditional methods like Mask R-CNN and Cascade Mask R-CNN. Our method builds upon traditional detection methods, achieving satisfactory detection results. Figure 4 shows the visualization of the detection results. Our method handles detection of images with conventional rotation or geometric deformation without significant issues. Even in slightly distorted cases, our method can adapt well with some post-processing. As long as the images are not excessively distorted, the proposed method remains relatively robust.

Figure 4 Visualization of Detection Results
(2) Ancient Text Recognition
Next, I will introduce the methods for text line recognition. In OCR recognition, traditional approaches are divided into two directions: one based on Connectionist Temporal Classification (CTC) and the other based on segmentation. Recently, a new direction based on Transformers has emerged. Transformer-based methods generally have higher training costs for dense text and require long sequences of characters to achieve good performance. Therefore, for recognizing dense ancient texts, we still choose the traditional approaches based on CTC and segmentation. We attempted to integrate these two approaches to complement each other and improve the final recognition performance. Figure 5 illustrates the fusion process.

Figure 5 Ancient Text Line Recognition Scheme
Segmentation-based methods require training samples with character box annotations. MTHv2 comes with such level of annotated data, but the sample size is limited, so we primarily utilize synthetic data to train the segmentation branch. For the segmentation branch, we adopted a mixed supervision training approach, using annotated training samples for strong supervision and unannotated training samples for weak supervision based on pseudo-labels.
To obtain a robust recognition engine, the existing ancient text training data is far from sufficient. For instance, the CASIA-AHCDB dataset has about 10,000 character categories, with each character requiring approximately 300 samples on average, meaning we need at least several million training samples to train a robust recognizer. To address this issue, we explored some data synthesis methods. We used our team’s font generation model CG-GAN as the synthesis engine for ancient single characters. CG-GAN can synthesize images of single characters in any category and with specified styles, effectively alleviating issues such as rare characters, variant forms, small samples, and zero samples in ancient texts. We synthesized over 20 million characters in total and spliced the synthesized single-character images into text lines to blend them with the background. Figure 6 shows examples of synthesized ancient text characters. As can be seen, whether it is different engraving styles from various eras or different fonts, the generated images are quite realistic. These synthetic data are used to train the recognition engine in the solution.

Figure 6 Effect of Synthesized Ancient Characters
The recognition engine is based on the methods mentioned earlier, which combine CTC and segmentation. According to Figure 5, we first use Convolutional Neural Networks (CNN) to extract features from the images, then employ a Transformer encoder to facilitate collaborative interaction among different features, and finally input them into the CTC and segmentation branches for joint optimization. CTC-based methods are prone to duplicate samples during recognition and may also produce insertion or deletion errors. Conversely, if the sliding window or positioning is accurate, segmentation-based methods generally do not exhibit the defects associated with CTC methods. However, if the segmentation is inaccurate, segmentation-based methods can easily produce recognition errors. Therefore, combining both approaches allows us to leverage their strengths and further enhance recognition performance. Our method’s performance on the publicly available handwritten dataset ICDAR2013-Offline is comparable to other optimal methods, and it also performs well on the ancient text dataset MTHv2.
Finally, we need to integrate detection and recognition. An end-to-end connection may not be the optimal solution, especially when aiming to improve recognition rates. Therefore, our scheme adopts a two-stage approach, first detecting the text and then recognizing it. The output of the text detection part is a mask of the text lines, so we need to crop the text line images based on the masks for recognition. Currently, the Mask-TPS cropping method is commonly used, which directly samples points on the mask boundaries and then performs TPS transformation. However, this method is particularly sensitive to the detection of the four corners; if there is a slight misalignment, the resulting text area is prone to errors. Thus, we proposed a detection point correction-TPS cropping method, which covers the mask with extended lines at both ends to sample more detection points before performing TPS transformation, addressing the shortcomings of the Mask-TPS cropping method. A detailed comparison is shown in Figure 7. Ultimately, our detection and recognition method can achieve around 91% accuracy on relatively challenging datasets, fully demonstrating the effectiveness of the aforementioned modules we proposed.
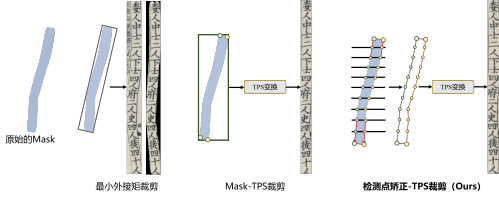
Figure 7 Three Methods for Cropping Text Lines Based on Masks
(3) Understanding the Reading Order of Ancient Texts
Even if the issues of text line detection and recognition for ancient texts are resolved, we still need to output paragraphs in the correct reading order. The layout of ancient texts is quite complex, with double columns, single columns, double-column interlinear annotations, headers, etc. Currently, the performance of ancient text layout analysis is not ideal, achieving only over 70% accuracy. When ancient text layout analysis is incorrect, the output recognition results will also be erroneous. Therefore, we propose to address this issue from the perspective of character and text line reading order. After detecting text lines from ancient document images, we need to determine the reading order between the text lines. Additionally, within each line, there are large characters, small characters, and interlinear annotations, so we also need to judge the reading order of these characters.
To tackle these issues, we first constructed a network for predicting character relationships using a graph neural network. Based on spatial L2 distance, we constructed subgraphs with each character as a pivot, while defining the node features and edge features of the graph. Then, we input the subgraphs into a relationship reasoning module, which consists of two layers of graph convolutional layers to encode the edge features and output classification results. Secondly, for predicting the reading order of text lines, we made some improvements based on LayoutReader and achieved good results. On the MTHv2 dataset, our proposed graph-based reasoning module achieved optimal performance in character relationship prediction tasks. In predicting the relationships between text lines, our text line relationship prediction network can directly obtain order detection results using only the geometric information of the text lines, without needing layout analysis results. Compared to heuristic rules, our proposed method performs best on both single-page and multi-page documents. Figure 8 illustrates the prediction of character relationships, with red arrows indicating the predicted connections between characters. It is evident that our proposed method can effectively handle scenarios of double-column interlinear annotations (Figure 8(a)) and various layout configurations (Figure 8(b)). For slightly curved text, conventional methods may misrecognize it, but our method can avoid this issue using the reading order relationships of characters. Figure 9 shows the corresponding numbering of text line orders and connection sequences, with a high accuracy rate. However, this method relies on Transformers and graph neural networks, so the inference speed may be relatively slow due to the combination of both.
Therefore, the reading order prediction method should also emphasize inference efficiency. The reading order of ancient documents follows a very fixed rule, which is from right to left and top to bottom. Utilizing such prior rules, we adopted a geometry-based reading order solution. The main idea is to input the image, obtain the rotation box, then distinguish between inter-line, inter-column, and intra-column, followed by aggregation between columns and segments, and finally output the reading order. Although the method is simple, it still yields satisfactory results.

(a) Ancient Document with Double-Column Interlinear Annotations

(b) Ancient Document with Various Layouts
Figure 8 Visualization of Character Relationship Prediction

Figure 9 Visualization of Text Line Order Numbering and Connection Sequences
4. Applications of Ancient Text OCR
Our complete solution participated in last year’s Guangdong-Hong Kong-Macao Greater Bay Area Artificial Intelligence Algorithm Competition in the ancient text image analysis and recognition track, which included three tasks: detection, recognition, and reading order output. There are two aspects of evaluation criteria: algorithm accuracy and algorithm cost efficiency. Algorithm accuracy includes text detection and recognition performance as well as reading order prediction performance, while algorithm cost efficiency includes scores for algorithm storage cost and inference speed. The final score is a weighted sum of each evaluation index. Since the competition considers inference speed, our team also made some engineering optimizations, such as using FP16 precision for acceleration and employing TensorRT as the backend for operator acceleration. Ultimately, our solution achieved the highest performance in text detection and recognition, but our reading order recognition performance, inference speed, and model parameter size were slightly inferior to Baidu’s. However, as detection and recognition weigh 80%, we fortuitously secured first place with a good score.
Additionally, our team developed a demo for the OCR of the Great Tibetan Tripitaka, with the corresponding URL being http://47.101.165.49/textv2/lineRec.html.
Currently, we are still using the old version of the solution, and we expect to deploy the latest solution in the second half of this year. We welcome everyone to test and experience it and provide valuable feedback.
5. Discussion and Outlook
Currently, there are still a large number of ancient documents that cannot be processed by current engines, and ancient text OCR still has many unresolved or inadequately addressed issues.
First, small sample, zero sample, and even open-set recognition of ancient texts. Researchers engaged in digital humanities, philology, and ancient text analysis need to recognize the most primitive characters, which may be extremely rare or even nonexistent, so these issues warrant further exploration. Second, the learning of recognition confidence for ancient text OCR. In practical applications, recognition errors are not a problem; the key is to know where the errors are and then manually correct them. However, the problem of confidence learning has not yet been adequately resolved. Third, ancient image enhancement and restoration. For instance, due to years of erosion, some characters in the Fangshan Stone Classics have fallen off. Can we use current technological means to restore the characters within? Fourth, in the era of large models, with the current boom in large models, can we construct a large model for ancient texts to help us better address issues such as character recognition, information extraction, and reading order understanding in ancient texts? In addition, we should strengthen interdisciplinary collaboration, with researchers in artificial intelligence working together with those in philology, digital humanities, and ancient text preservation to contribute to the digitization of ancient texts.
Source: “Communications of the Chinese Society of Image and Graphics” Volume 2, Issue 2, 2023 CCIG 2023 Speech Transcript


Welcome to scan the QR code to join the Chinese Society of Image and Graphics
(http://membership.csig.org.cn)


