

Author: Mariya Mansurova
Translation: Ouyang Jin
Proofreading: Zhao Ruxuan
This article is approximately 3500 words, recommended reading time is 10 minutes.
This article discusses the impact and insights of LLMs on the future work of analysts through two specific use cases that used the OpenAI API to build LLMs to solve simple tasks.

In the previous article, we discussed whether large language models (LLMs) can replace data analysts and focused on extraction for structured output. Now, let’s continue discussing more interesting use cases—tools and routing.
Use Case #2: Tools and Routing
It’s time to use tools and provide external functionalities for our models. The models in this approach are reasoning engines that can decide what tools to use and when to use them (known as routing).
LangChain has a concept of tools—agents that can serve as interfaces to interact with the world. Tools can be functions, LangChain chains, or even other agents.
We can easily convert tools into OpenAI functions using format_tool_to_openai_function and continue passing the function (functions) parameters to the LLM.
Defining Custom Tools
Let’s teach the LLM analyst to calculate the difference between two metrics. We know that LLMs may make mistakes in math, so we want the model to use a calculator instead of calculating by itself.
To define a tool, we need to create a function and use the @tool decorator.
from langchain.agents import tool
@tool
def percentage_difference(metric1: float, metric2: float) -> float:
"""Calculates the percentage difference between metrics"""
return (metric2 - metric1)/metric1*100Now, the function has name (name) and description (description) parameters that will be passed to the LLM.
print(percentage_difference.name) # percentage_difference.name
print(percentage_difference.args) # {'metric1': {'title': 'Metric1', 'type': 'number'},
# 'metric2': {'title': 'Metric2', 'type': 'number'}}
print(percentage_difference.description) # 'percentage_difference(metric1: float, metric2: float) -> float - Calculates the percentage difference between metrics'These parameters will be used to create the OpenAI function specification. Let’s convert our tool into an OpenAI function.
from langchain.tools.render import format_tool_to_openai_function
print(format_tool_to_openai_function(percentage_difference))We get the following JSON as a result. It outlines the structure but lacks field descriptions.
{'name': 'percentage_difference', 'description': 'percentage_difference(metric1: float, metric2: float) -> float - Calculates the percentage difference between metrics', 'parameters': {'title': 'percentage_differenceSchemaSchema', 'type': 'object', 'properties': {'metric1': {'title': 'Metric1', 'type': 'number'}, 'metric2': {'title': 'Metric2', 'type': 'number'}}, 'required': ['metric1', 'metric2']}}We can use Pydantic to specify the schema for the parameters.
class Metrics(BaseModel):
metric1: float = Field(description="Base metric value to calculate the difference")
metric2: float = Field(description="New metric value that we compare with the baseline")
@tool(args_schema=Metrics)
def percentage_difference(metric1: float, metric2: float) -> float:
"""Calculates the percentage difference between metrics"""
return (metric2 - metric1)/metric1*100Now, if we convert the new version to the OpenAI function specification, it will include parameter descriptions. This is much better because we can share all necessary context with the model.
{'name': 'percentage_difference', 'description': 'percentage_difference(metric1: float, metric2: float) -> float - Calculates the percentage difference between metrics', 'parameters': {'title': 'Metrics', 'type': 'object', 'properties': {'metric1': {'title': 'Metric1', 'description': 'Base metric value to calculate the difference', 'type': 'number'}, 'metric2': {'title': 'Metric2', 'description': 'New metric value that we compare with the baseline', 'type': 'number'}}, 'required': ['metric1', 'metric2']}}Thus, we have defined tools that the LLM can use. Let’s try it in practice.
Using Tools in Practice
Let’s define a chain and pass our tool to that function. Then we can test it based on user requests.
model = ChatOpenAI(temperature=0.1, model='gpt-3.5-turbo-1106')
.bind(functions=[format_tool_to_openai_function(percentage_difference)])
prompt = ChatPromptTemplate.from_messages([
("system", "You are a product analyst willing to help your product team. You are very strict to the point and accurate. You use only facts, not inventing information."),
("user", "{request}")
])
analyst_chain = prompt | model
analyst_chain.invoke({'request': "In April we had 100 users and in May only 95. What is the difference in percent?"})We received a function call with the correct parameters, so it is working.
AIMessage(content='', additional_kwargs={
'function_call': {
'name': 'percentage_difference',
'arguments': '{"metric1":100,"metric2":95}'
}
})To handle the output in a more convenient way, we can use OpenAIFunctionsAgentOutputParser. Let’s add it to our chain.
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
analyst_chain = prompt | model | OpenAIFunctionsAgentOutputParser()
result = analyst_chain.invoke({'request': "There were 100 users in April and 110 users in May. How did the number of users change?"})Now, we get output in a more structured way and can easily retrieve the tool’s parameters in the form of result.tool_input.
AgentActionMessageLog(
tool='percentage_difference',
tool_input={'metric1': 100, 'metric2': 110},
log="\nInvoking: `percentage_difference` with `{'metric1': 100, 'metric2': 110}`\n\n\n",
message_log=[AIMessage(content='', additional_kwargs={'function_call': {'name': 'percentage_difference', 'arguments': '{"metric1":100,"metric2":110}'}})])Thus, we can execute the function as required by the LLM as follows.
observation = percentage_difference(result.tool_input)
print(observation) # 10If we want to get the final answer from the model, we need to return the result of the function execution. To do this, we need to define a message list to pass the model observations.
from langchain.prompts import MessagesPlaceholder
model = ChatOpenAI(temperature=0.1, model='gpt-3.5-turbo-1106')
.bind(functions=[format_tool_to_openai_function(percentage_difference)])
prompt = ChatPromptTemplate.from_messages([
("system", "You are a product analyst willing to help your product team. You are very strict to the point and accurate. You use only facts, not inventing information."),
("user", "{request}"),
MessagesPlaceholder(variable_name="observations")
])
analyst_chain = prompt | model | OpenAIFunctionsAgentOutputParser()
result1 = analyst_chain.invoke({
'request': "There were 100 users in April and 110 users in May. How did the number of users change?",
"observations": []
})
observation = percentage_difference(result1.tool_input)
print(observation) # 10Then, we need to add the observation to our observations variable. We can use format_to_openai_functions to format our results in the way the model expects.
from langchain.agents.format_scratchpad import format_to_openai_functions
format_to_openai_functions([(result1, observation), ])As a result, we get information that the LLM can understand.
[AIMessage(content='', additional_kwargs={'function_call': {'name': 'percentage_difference', 'arguments': '{"metric1":100,"metric2":110}'}}), FunctionMessage(content='10.0', name='percentage_difference')]Let’s call our chain again, passing the function execution result as an observation.
result2 = analyst_chain.invoke({
'request': "There were 100 users in April and 110 users in May. How did the number of users change?",
'observations': format_to_openai_functions([(result1, observation)])})Now, we got the final result from the model that sounds reasonable.
AgentFinish(
return_values={'output': 'The number of users increased by 10%.'},
log='The number of users increased by 10%.')
If we use the ordinary OpenAI Chat Completion API, we can add another message with role = tool. You can find detailed examples here.
If we enable debugging, we can see the exact prompt sent to the OpenAI API.
System: You are a product analyst willing to help your product team. You are very strict to the point and accurate. You use only facts, not inventing information.
Human: There were 100 users in April and 110 users in May. How did the number of users change?
AI: {'name': 'percentage_difference', 'arguments': '{"metric1":100,"metric2":110}'}
Function: 10.0To enable LangChain debugging, execute the following code and call your chain to see what happens behind the scenes.
import langchain
langchain.debug = TrueWe tried using one tool, but let’s expand our toolkit and see how the LLM handles it.
Routing: Using Multiple Tools
Let’s add more tools to the analyst’s toolkit:
-
Get monthly active users; -
Use Wikipedia.
First, we define a virtual function to calculate the audience filtered by month and city. We will again use Pydantic to specify the input parameters of the function.
import datetime
import random
class Filters(BaseModel):
month: str = Field(description="Month of customer's activity in the format %Y-%m-%d")
city: Optional[str] = Field(description="City of residence for customers (by default no filter)", enum = ["London", "Berlin", "Amsterdam", "Paris"])
@tool(args_schema=Filters)
def get_monthly_active_users(month: str, city: str = None) -> int:
"""Returns number of active customers for the specified month"""
dt = datetime.datetime.strptime(month, '%Y-%m-%d')
total = dt.year + 10*dt.month
if city is None:
return total
else:
return int(total*random.random())Then, we use the Wikipedia Python package to allow the model to query Wikipedia.
import wikipedia
class Wikipedia(BaseModel):
term: str = Field(description="Term to search for")
@tool(args_schema=Wikipedia)
def get_summary(term: str) -> str:
"""Returns basic knowledge about the given term provided by Wikipedia"""
return wikipedia.summary(term)Define a dictionary with all the functions that our model now knows. This dictionary will help us with routing later.
toolkit = {
'percentage_difference': percentage_difference,
'get_monthly_active_users': get_monthly_active_users,
'get_summary': get_summary
}
analyst_functions = [format_tool_to_openai_function(f) for f in toolkit.values()]I made some changes to the previous setup:
-
I adjusted the system prompt to force the LLM to consult Wikipedia when it needs some basic knowledge. -
I changed the model to GPT-4 because it is better suited for tasks that require reasoning.
from langchain.prompts import MessagesPlaceholder
model = ChatOpenAI(temperature=0.1, model='gpt-4-1106-preview')
.bind(functions=analyst_functions)
prompt = ChatPromptTemplate.from_messages([
("system", "You are a product analyst willing to help your product team. You are very strict to the point and accurate.
You use only information provided in the initial request.
If you need to determine some information i.e. what is the name of the capital, you can use Wikipedia."),
("user", "{request}"),
MessagesPlaceholder(variable_name="observations")
])
analyst_chain = prompt | model | OpenAIFunctionsAgentOutputParser()We can use all the functions to call our chain. Let’s start with a very simple query.
result1 = analyst_chain.invoke({
'request': "How many users were in April 2023 from Berlin?",
'observations': []
})
print(result1)We got a result function call with input parameters for get_monthly_active_users – {‘month’: ‘2023–04–01’, ‘city’: ‘Berlin’}, which looks correct. The model was able to find the right tool and solve the task.
Let’s try to make the task a bit more complex:
result1 = analyst_chain.invoke({
'request': "How did the number of users from the capital of Germany change between April and May 2023?",
'observations': []
})Pause for a moment and think about how we want the model to reason. Clearly, the model does not have enough information to answer immediately, so it needs to perform a series of function calls:
-
Call Wikipedia to get the capital of Germany; -
Call get_monthly_active_users function twice to get MAUs for April and May; -
Call percentage_difference to calculate the difference between metrics.
It looks quite complex. Let’s see if ChatGPT can solve this problem.
For the first call, the LLM returned a function call to Wikipedia with the following parameters – {‘term’: ‘capital of Germany’}. So far, it is following our plan.
Let’s provide the observation result and see what the next steps are.
observation1 = toolkit[result1.tool](result1.tool_input)
print(observation1)
# The capital of Germany is the city state of Berlin. It is the seat of the President of Germany, whose official residence is Schloss Bellevue. The Bundesrat ("federal council") is the representation of the Federal States (Bundesländer) of Germany and has its seat at the former Prussian Herrenhaus (House of Lords). Though most of the ministries are seated in Berlin, some of them, as well as some minor departments, are seated in Bonn, the former capital of West Germany. Although Berlin is officially the capital of the Federal Republic of Germany, 8,000 out of the 18,000 total officials employed at the federal bureaucracy still work in Bonn, about 600 km (370 mi) away from Berlin.
# source: https://en.wikipedia.org/wiki/Capital_of_Germany
result2 = analyst_chain.invoke({
'request': "How did the number of users from the capital of Germany change between April and May 2023?",
'observations': format_to_openai_functions([(result1, observation1)])})The model wants to execute get_monthly_active_users with parameters {‘month’: ‘2023–04–01’, ‘city’: ‘Berlin’}. Let’s do that and return the information to the model again.
observation2 = toolkit[result2.tool](result2.tool_input)
print(observation2) # 168
result3 = analyst_chain.invoke({
'request': "How did the number of users from the capital of Germany change between April and May 2023?",
'observations': format_to_openai_functions([(result1, observation1), (result2, observation2)])})The model then requests to call get_monthly_active_users again with parameters {‘month’: ‘2023–05–01’, ‘city’: ‘Berlin’}. So far, it has done very well. Let’s follow its logic.
observation3 = toolkit[result3.tool](result3.tool_input)
print(observation3) # 1046
result4 = analyst_chain.invoke({
'request': "How did the number of users from the capital of Germany change between April and May 2023?",
'observations': format_to_openai_functions([(result1, observation1), (result2, observation2), (result3, observation3)])})The subsequent result is a function call to percentage_difference using parameters {‘metric1’: 168, ‘metric2’: 1046}. Let’s calculate the observation results and call our chain again. Hopefully, this will be the last step.
observation4 = toolkit[result4.tool](result4.tool_input)
print(observation4) # 523.27
result5 = analyst_chain.invoke({
'request': "How did the number of users from the capital of Germany change between April and May 2023?",
'observations': format_to_openai_functions([(result1, observation1), (result2, observation2), (result3, observation3), (result4, observation4)])})Finally, we got the following response from the model: The number of users from Berlin, the capital of Germany, increased by approximately 523.27% between April and May 2023.
The following diagram shows the complete scheme of the LLM calls for this question:
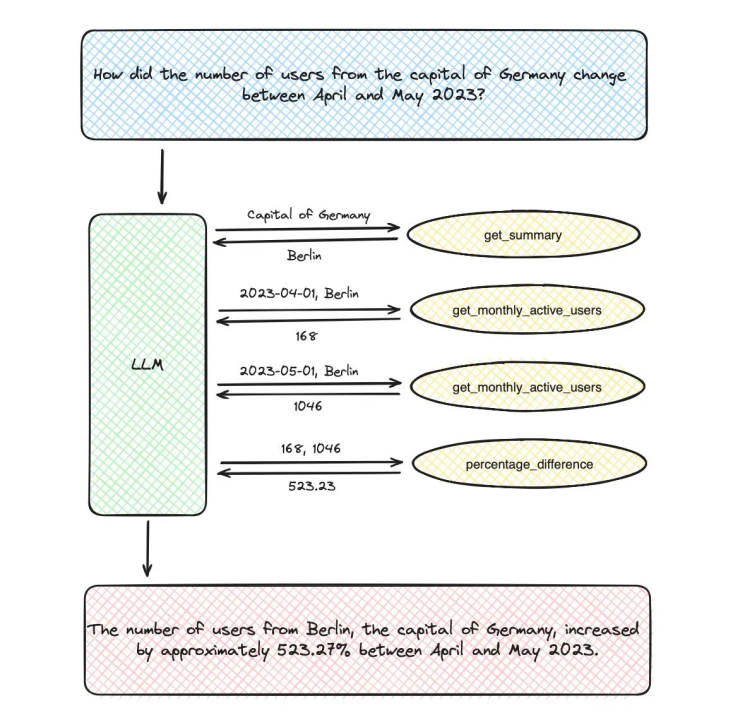
Image source: Author
In the example above, we manually triggered subsequent calls one by one, but it can be easily automated.
This is an amazing result, and we can see how the LLM reasons and utilizes multiple tools. It took 5 model steps to achieve the result, but it followed the logical path we initially outlined. However, if you plan to deploy LLMs in production, keep in mind that they may make mistakes and introduce evaluation and quality assurance processes.
You can find the complete code on GitHub.
Returning to the initial question, can LLMs replace data analysts? Our current prototype is quite basic, and it is far from the capabilities of a junior analyst, but this is just the beginning. Stay tuned! We will delve deeper into the different approaches of LLM agents.
References
This article was inspired by DeepLearning.AI’s “Functions, Tools and Agents with LangChain” course.
Translator Introduction

Translation Team Recruitment Information
Job Content: Requires a meticulous heart to translate selected foreign articles into fluent Chinese. If you are an international student in data science/statistics/computer-related fields, or working overseas in related jobs, or confident in your foreign language skills, feel free to join the translation team.
What you can get: Regular translation training to improve volunteers’ translation skills, enhance understanding of cutting-edge data science, and overseas friends can keep in touch with domestic technology application development. The THU Data Team’s background in industry, academia, and research brings good development opportunities for volunteers.
Other Benefits: Data scientists from well-known companies, students from prestigious universities such as Peking University and Tsinghua University, and overseas students will become your partners in the translation team.
Click “Read the original text” at the end to join the Data Team~
Reprint Notice
If you need to reprint, please indicate the author and source prominently at the beginning of the article (Reprinted from: Data Team ID: DatapiTHU), and place a prominent QR code of the Data Team at the end of the article. For articles with original identification, please send [Article Name – Pending Authorized Public Account Name and ID] to the contact email to apply for whitelist authorization and edit as required.
After publishing, please feedback the link to the contact email (see below). Unauthorized reprints and adaptations will be legally pursued.
