Original link: https://blog.llamaindex.ai/multimodal-rag-pipeline-with-llamaindex-and-neo4j-a2c542eb0206
Code link: https://github.com/tomasonjo/blogs/blob/master/llm/neo4j_llama_multimodal.ipynb

Image by DALL·E
The rapid development of artificial intelligence and large language models (LLMs) is astonishing. Just a year ago, no one was using large language models to enhance work efficiency. But now, many people find it hard to imagine working without the assistance of large language models or at least delegating some smaller tasks to them. As research deepens and interest grows, large language models are becoming increasingly powerful and intelligent. Moreover, their understanding abilities have begun to encompass different forms of information expression (modalities). For example, with the emergence of GPT-4-Vision and other follow-up large language models, they now seem to handle and understand images quite well. Here is an example of ChatGPT generating image content based on a description.
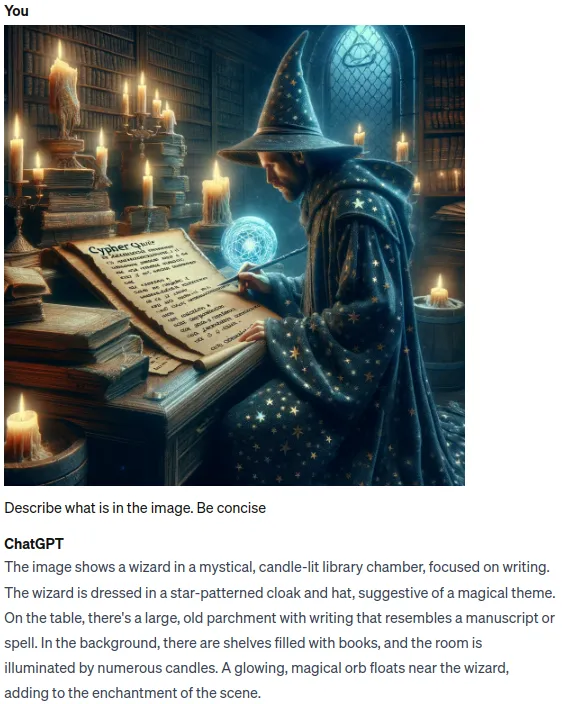
Using ChatGPT to describe images.
As we can see, ChatGPT performs excellently in understanding and describing images. We can leverage its ability to interpret images in RAG (retrieval-augmented generation) applications, no longer relying solely on text to generate accurate and up-to-date answers, but rather combining information from both text and images to create responses that are more precise than ever before. Implementing a multimodal RAG process using LlamaIndex is very straightforward. Inspired by their multimodal cookbook example, I plan to explore whether it is possible to utilize Neo4j as a database to implement a multimodal RAG application.
To implement a multimodal RAG process with LlamaIndex, you only need to create two vector repositories: one for storing image information and another for storing text information. Then, by querying these two repositories, you can retrieve the relevant information needed to generate the final answer.
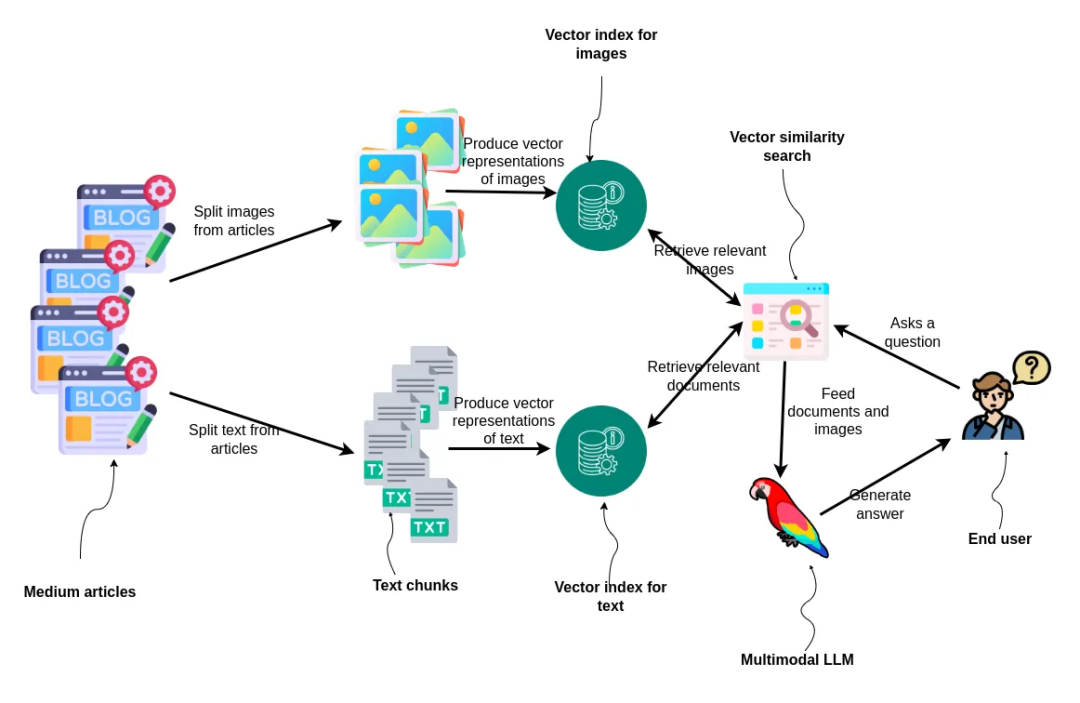
Workflow diagram for the blog post. Image by author.
First, the article is split into image and text parts. Then, these parts are transformed into vector form and indexed separately. For the text part, we use the ada-002 text embedding model, while for images, we use the dual encoder model CLIP, which can handle both text and images in the same embedding space. When a user poses a question, the system conducts two vector-based similarity searches: one for relevant images and another for relevant documents. The results found will be sent to a multimodal large language model, which will generate answers for the user, showcasing a comprehensive approach to information retrieval and answer generation through processing and utilizing mixed media.
Data Preprocessing
I will use the articles I published on Medium in 2022 and 2023 as the data foundation for the RAG application. These articles contain rich information regarding the Neo4j graph data science library and how to integrate Neo4j with large language model frameworks. When downloading articles from Medium, the format is HTML. Therefore, we need some programming operations to extract the text and images from the articles separately.
def process_html_file(file_path):
with open(file_path, "r", encoding="utf-8") as file:
soup = BeautifulSoup(file, "html.parser")
# Find the required section
content_section = soup.find("section", {"data-field": "body", "class": "e-content"})
if not content_section:
return "Section not found."
sections = []
current_section = {"header": "", "content": "", "source": file_path.split("/")[-1]}
images = []
header_found = False
for element in content_section.find_all(recursive=True):
if element.name in ["h1", "h2", "h3", "h4"]:
if header_found and (current_section["content"].strip()):
sections.append(current_section)
current_section = {
"header": element.get_text(),
"content": "",
"source": file_path.split("/")[-1],
}
header_found = True
elif header_found:
if element.name == "pre":
current_section["content"] += f"```{element.get_text().strip()}```\n"
elif element.name == "img":
img_src = element.get("src")
img_caption = element.find_next("figcaption")
caption_text = img_caption.get_text().strip() if img_caption else ""
images.append(ImageDocument(image_url=img_src))
elif element.name in ["p", "span", "a"]:
current_section["content"] += element.get_text().strip() + "\n"
if current_section["content"].strip():
sections.append(current_section)
return images, sections
I won’t go into detail about the parsing code, but we will split the text based on headers h1-h4 and extract image links. Then, we simply run all articles through this function to extract all relevant information.
all_documents = []
all_images = []
# Directory to search in (current working directory)
directory = os.getcwd()
# Walking through the directory
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith(".html"):
# Update the file path to be relative to the current directory
images, documents = process_html_file(os.path.join(root, file))
all_documents.extend(documents)
all_images.extend(images)
text_docs = [Document(text=el.pop("content"), metadata=el) for el in all_documents]
print(f"Text document count: {len(text_docs)}") # Text document count: 252
print(f"Image document count: {len(all_images)}") # Image document count: 328
We ended up with 252 text blocks and 328 images. It is somewhat surprising that I created so many photos, but I know that some of them are just images of tabular results. We could use visual models to filter out irrelevant photos, but I skipped that step here.
Creating Data Vector Index
As mentioned earlier, we need to create two vector stores, one for images and another for text. The dimension of the CLIP embedding model is 512, while the dimension of ada-002 is 1536.
text_store = Neo4jVectorStore(
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name="text_collection",
node_label="Chunk",
embedding_dimension=1536
)
image_store = Neo4jVectorStore(
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name="image_collection",
node_label="Image",
embedding_dimension=512
)
storage_context = StorageContext.from_defaults(vector_store=text_store)
Now that the vector stores are initialized, we use MultiModalVectorStoreIndex to index the information we have from the two modalities.
# Takes 10 min without GPU / 1 min with GPU on Google collab
index = MultiModalVectorStoreIndex.from_documents(
text_docs + all_images, storage_context=storage_context, image_vector_store=image_store
)
Under the hood, the MultiModalVectorStoreIndex uses text and image embedding models to compute embeddings and store the results in Neo4j. For images, only the URL is stored, not the actual base64 or other image representations.
Multimodal RAG Process
This code is directly copied from LlamaIndex’s multimodal cookbook. We first define a multimodal large language model and a prompt template, and then combine everything as a query engine.
openai_mm_llm = OpenAIMultiModal(
model="gpt-4-vision-preview", max_new_tokens=1500
)
qa_tmpl_str = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query.\n"
"Query: {query_str}\n"
"Answer: "
)
qa_tmpl = PromptTemplate(qa_tmpl_str)
query_engine = index.as_query_engine(
multi_modal_llm=openai_mm_llm, text_qa_template=qa_tmpl
)
Now we can continue to test how it performs.
query_str = "How do vector RAG applications work?"
response = query_engine.query(query_str)
print(response)
Output

Generated response by an LLM.
We can also visualize the retrieved images and use them to help provide relevant information for the final answer.
Image input to LLM.
The large language model received two identical images as input, indicating that I reused some charts. However, I was surprised by the CLIP embeddings as they managed to retrieve the most relevant images from a multitude of pictures. In a setting closer to a production environment, you might want to clean up and deduplicate images, but that is beyond the scope of this article.
Conclusion
The development of large language models has exceeded our historical experiences and is crossing multiple modalities. I firmly believe that by the end of next year, large language models will soon be able to understand videos, thus capturing non-verbal cues when conversing with you. On the other hand, we can pass images as input to the RAG process, thereby enhancing the diversity of information delivered to the large language model, making answers more accurate and high-quality. Implementing a multimodal RAG process with LlamaIndex and Neo4j is that simple.
Related Links
[1] https://github.com/run-llama/llama_index/blob/main/docs/examples/multi_modal/gpt4v_multi_modal_retrieval.ipynb [2] https://github.com/openai/CLIP [3] https://github.com/tomasonjo/blog-datasets/blob/main/articles.zip