

This article is an excellent piece from the KX Forum, author ID: Flying Fish Oil
1
Introduction
2
Overall Framework

3
Function Embedding
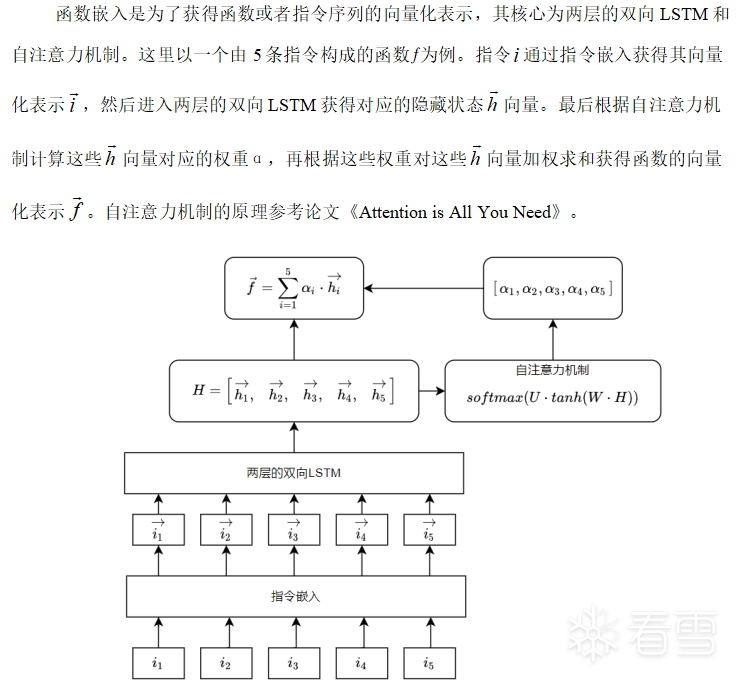
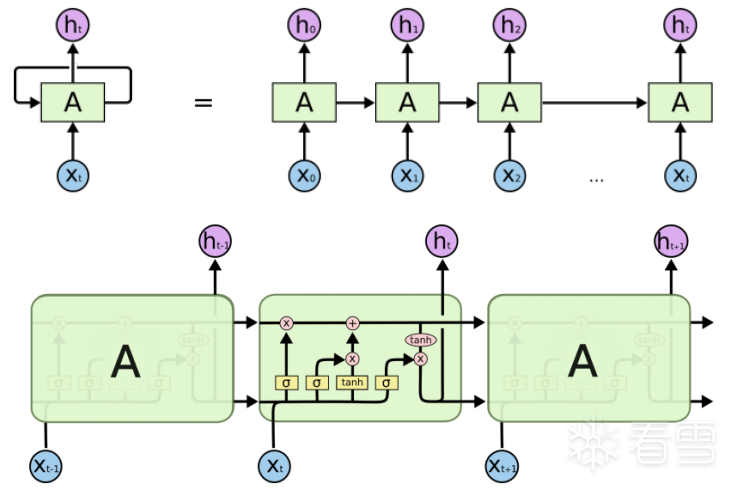
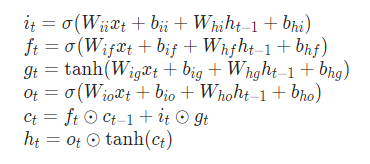 W and b are the parameters to be learned by LSTM; specific parameter details can be referenced in the official PyTorch documentation.
W and b are the parameters to be learned by LSTM; specific parameter details can be referenced in the official PyTorch documentation.4
Instruction Embedding
[0xXXXXXXXX] -> [mem][0xXXXXXXXX + index*scale + base] -> [disp + index*scale + base]0xXXXXXXXX -> imm5
Code Implementation
model = Word2Vec(tokensList, vector_size=wordDim, negative=15, window=5, min_count=1, workers=1, epochs=10, sg=1) model.save('insn2vec.model')class instruction2vec(nn.Module): def __init__(self, word2vec_model_path:str): super(instruction2vec, self).__init__() word2vec = Word2Vec.load(word2vec_model_path) self.embedding = nn.Embedding.from_pretrained(torch.from_numpy(word2vec.wv.vectors)) self.token_size = word2vec.wv.vector_size# Dimension size self.key_to_index = word2vec.wv.key_to_index.copy() # dict self.index_to_key = word2vec.wv.index_to_key.copy() # list del word2vec def keylist_to_tensor(self, keyList:list): indexList = [self.key_to_index[token] for token in keyList] return self.embedding(torch.LongTensor(indexList)) def InsnStr2Tensor(self, insnStr:str) -> torch.tensor: insnStr = RefineAsmCode(insnStr) tokenList = re.findall('\w+|[\+\-\*:\[\]\,]', insnStr) opcode_tensor = self.keylist_to_tensor(tokenList[0:1])[0] op_zero_tensor = torch.zeros(self.token_size) insn_tensor = None if(1 == len(tokenList)): # No operands insn_tensor = torch.cat((opcode_tensor, op_zero_tensor, op_zero_tensor), dim=0) else: op_token_list = tokenList[1:] if(op_token_list.count(',') == 0): # One operand op1_tensor = self.keylist_to_tensor(op_token_list) insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op_zero_tensor), dim=0)#tensor.mean求均值后变成一维 elif(op_token_list.count(',') == 1): # Two operands dot_index = op_token_list.index(',') op1_tensor = self.keylist_to_tensor(op_token_list[0:dot_index]) op2_tensor = self.keylist_to_tensor(op_token_list[dot_index+1:]) insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op2_tensor.mean(dim=0)), dim=0) elif(op_token_list.count(',') == 2): # Three operands dot1_index = op_token_list.index(',') dot2_index = op_token_list.index(',', dot1_index+1) op1_tensor = self.keylist_to_tensor(op_token_list[0:dot1_index]) op2_tensor = self.keylist_to_tensor(op_token_list[dot1_index+1:dot2_index]) op3_tensor = self.keylist_to_tensor(op_token_list[dot2_index+1:]) op2_tensor = (op2_tensor.mean(dim=0) + op3_tensor.mean(dim=0)) / 2 insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op2_tensor), dim=0) if(None == insn_tensor): print("error: None == insn_tensor") raise insn_size = insn_tensor.shape[0] if(self.token_size * 3 != insn_size): print("error: (token_size)%d != %d(insn_size)" % (self.token_size, insn_size)) raise return insn_tensor #[len(tokenList), token_size] def forward(self, insnStrList:list) -> torch.tensor: insnTensorList = [self.InsnStr2Tensor(insnStr) for insnStr in insnStrList] return torch.stack(insnTensorList) #[insn_count, token_size]class SiameseNet(nn.Module): def __init__(self, hidden_size=60, n_layers=2, bidirectional = False): super(SiameseNet, self).__init__() self.insn_embedding = instruction2vec("./insn2vec.model") input_size = self.insn_embedding.token_size * 3 # input_size is the dimension of the instruction, hidden_size is the dimension of the entire instruction sequence self.lstm = nn.LSTM(input_size, hidden_size, n_layers, batch_first=True, bidirectional = bidirectional) self.D = int(bidirectional)+1 self.w_omega = nn.Parameter(torch.Tensor(hidden_size * self.D, hidden_size * self.D)) self.b_omega = nn.Parameter(torch.Tensor(hidden_size * self.D)) self.u_omega = nn.Parameter(torch.Tensor(hidden_size * self.D, 1)) nn.init.uniform_(self.w_omega, -0.1, 0.1) nn.init.uniform_(self.u_omega, -0.1, 0.1) def attention_score(self, x): # x:[batch_size, seq_len, hidden_size*D] u = torch.tanh(torch.matmul(x, self.w_omega)) # u:[batch_size, seq_len, hidden_size*D] att = torch.matmul(u, self.u_omega) # att:[batch_size, seq_len, 1] att_score = F.softmax(att, dim=1)# Get the hidden weights for each step # att_score:[batch_size, seq_len, 1] scored_x = x*att_score # Similar to matrix multiplication return torch.sum(scored_x, dim=1)# Weighted summation def forward_once(self, input:list) -> torch.tensor: lengths = []# Record the length of each instruction sequence out = [] for insnStrList in input: insnVecTensor = self.insn_embedding(insnStrList)# Convert instructions to vectors out.append(insnVecTensor) lengths.append(len(insnStrList)) pad_out = pad_sequence(out, batch_first=True)# Pad zeros to make all handlers have the same seq_len pack_padded_out = pack_padded_sequence(pad_out, lengths, batch_first=True, enforce_sorted=False) packed_out,(hn,_) = self.lstm(pack_padded_out)# Input shape:[batch_size, seq_len, input_size] # hn:[D*num_layers,batch_size,hidden_size] # out:[batch_size, seq_len, hidden_size*D], at this point out has some zero padding out,lengths = pad_packed_sequence(packed_out, batch_first=True) out = self.attention_score(out) return out def forward(self, input1, input2): out1 = self.forward_once(input1)# out1:[batch_size,hidden_size] out2 = self.forward_once(input2) out = F.cosine_similarity(out1, out2, dim=1) return out6
Model Evaluation
ntdll_7600_x64.dllntoskrnl_7600_x64.exewin32kfull_17134_x64.sysntdll_7600_x32.dllntoskrnl_7600_x32.exewin32kfull_17134_x32.sys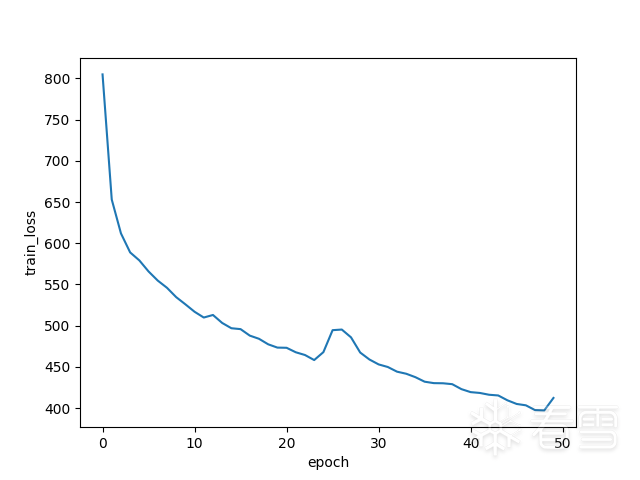
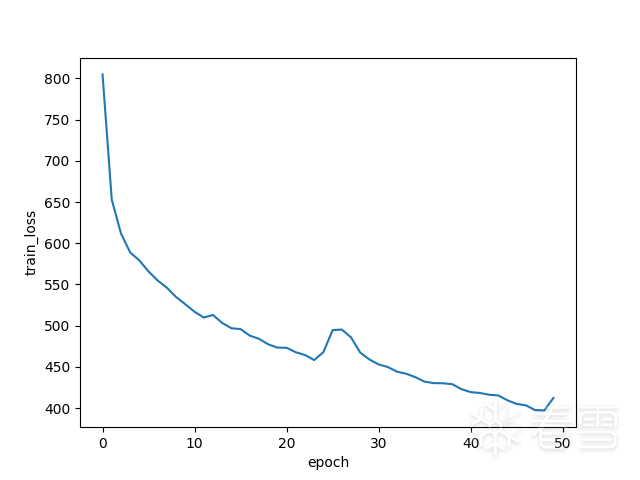
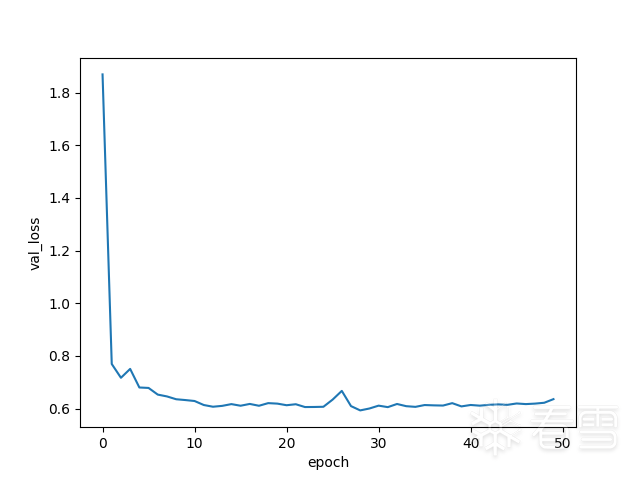

 The first two images show the loss of the training and validation sets decreasing with the number of iterations. It can be seen that the validation set loss has already converged without significant decrease, even when the training set loss has not yet converged. If training continues, it is likely to overfit, primarily due to insufficient data.
The first two images show the loss of the training and validation sets decreasing with the number of iterations. It can be seen that the validation set loss has already converged without significant decrease, even when the training set loss has not yet converged. If training continues, it is likely to overfit, primarily due to insufficient data.7
Conclusion
mov eax, [0x12345678] add eax, [0x12345678]shl eax, 2 shl eax, 2ret inc eaxReferences

KX ID: Flying Fish Oil
https://bbs.pediy.com/user-home-742617.htm

# Previous Recommendations
1. The House of Mind
2. CVE-2012-1889 Vulnerability Analysis and Exploitation Notes
3. AI Competition – Target Recognition Guide
4. Android Packing and Unpacking Learning – Detailed Explanation of Dynamic Loading and Class Loading Mechanisms
5. CVE-2021-26411 Vulnerability Analysis Notes
6. Analysis of Windows Local Privilege Escalation Vulnerability CVE-2014-1767 and EXP Writing Guidance

Share

Like

Watching