

After more than seventy days, Mianbi has released four distinct models following the launch of MiniCPM-2B, and it has also officially announced new financing worth hundreds of millions.
This financing was led by Chuanghua Venture Capital and Huawei Hubble, with the Beijing Artificial Intelligence Industry Investment Fund and others participating. Zhihu continues to support as a strategic shareholder. This is the largest financing since its establishment. This company, often compared to Mistral, is not satisfied with just being a “Chinese Mistral”; with ample ammunition, it aims to excel in the pursuit of excellence.
1
Small Yet Powerful: The MiniCPM Series
In early February this year, Mianbi launched the open-source edge model MiniCPM-2B with 2B parameters, dubbed the “Mini Cannon,” achieving performance comparable to Mistral-7B and Llama2-13B with smaller parameters. Since its release, MiniCPM-2B has repeatedly topped GitHub Trending and has received praise from Thomas Wolf, co-founder of Hugging Face.
After more than seventy days, Mianbi has released four models at once; let’s take a look at their performance.
Multimodal Model MiniCPM-V 2.0
MiniCPM-V 2.0 is a deployable multimodal large model for mobile devices, with a scale of only about 2.8B, yet achieving excellent scores in mainstream evaluations. On the OpenCompass leaderboard, it surpassed Qwen-VL-Chat-10B, CogVLM-Chat-17B, and Yi-LV-34B in general capabilities across 11 mainstream evaluation benchmarks.
Mianbi particularly emphasizes that MiniCPM-V 2.0 has a very low hallucination probability, comparable to GPT-4V. In the Object HalBench leaderboard evaluating large model hallucinations, MiniCPM-V 2.0 stands at 14.5%, while GPT-4V is at 13.6%.
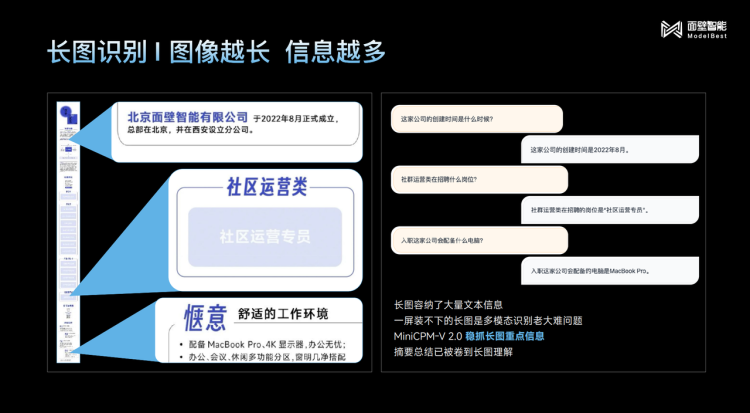
In terms of OCR capability, MiniCPM-V2.0 surpassed the entire series of 13B models on the TextVQA leaderboard for scene image text recognition, standing shoulder to shoulder with Gemini Pro. MiniCPM-V2.0 has also enhanced its recognition and understanding of long images and optimized compatibility for images of various sizes, supporting high-definition large images from 448×448 pixels to 1.8 million pixels, and even extreme aspect ratios of 1:9.

Long Text Model MiniCPM-2B-128K
Long text has become a standard feature of large models, and MiniCPM-2B-128K achieves 128K long text capability with a 2B scale, averaging scores on the InfiniteBench leaderboard that exceed Yarn-Mistral-7B-128K, Yi-6B-200K, ChatGLM3-6B-128K, and LWM-Text-128K, achieving the best performance among models below 7B.
“The long text aspect is just beginning; although it is a 2B model, it still requires a very large memory to run the model. The next step will further explore more extreme technical explorations to enable long text models to run on the edge.”
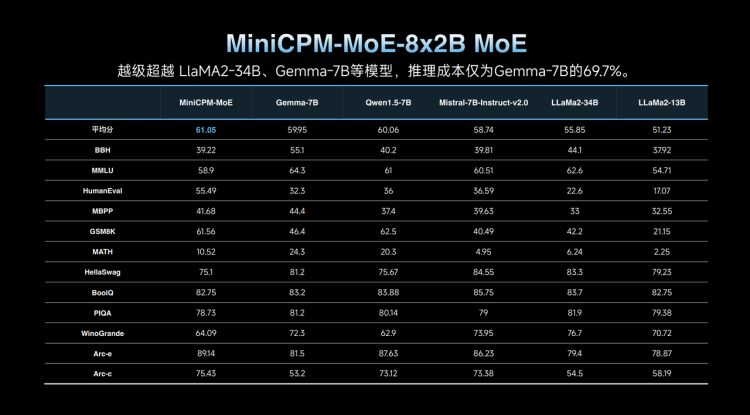
MOE Version MiniCPM-MoE-8x2B
MiniCPM-MoE-8x2B introduces the MoE architecture, enhancing performance and allowing the model to achieve an average improvement of 4.5% over the original basis. This saves training costs compared to training from scratch. With the MOE approach, the average activated parameters are only 4B, yet it performs better than models like LiaMA2-34B and Gemma-7B, with inference costs only 69.7% of that of Gemma-7B.
The “More Mini” MiniCPM-1.2B
MiniCPM-1.2B reduces parameters by half while maintaining 87% of the overall performance of the previous generation 2.4B model. This involves many optimizations, such as replacing infrequently used words in the vocabulary. In multiple leaderboard tests, MiniCPM-1.2B outperformed Qwen1.8B, llama2-7B, and even llama2-13B.

By allowing the 1.2B model to outperform the 1.8B model, it achieves 25tokens/s on mobile devices. As the model size decreases, cost and memory usage also decrease; compared to MiniCPM-2.4B, MiniCPM-1.2B has a 51.9% reduction in memory and a 60% decrease in cost.
“The model is smaller, but the usage scenarios are broader.” MiniCPM-1.2B not only supports lower-configured phones but also has extensive applications in areas such as emotional companionship and real-time translation. “They are very much looking forward to smaller and stronger models.”
1
More Than Just a “Chinese Mistral”
Mianbi’s CEO Li Dahai summarized the series of models released this time as “small yet powerful, small yet comprehensive,” and emphasized Mianbi’s underlying logic: a company pursuing efficient large models. This easily evokes thoughts of Mistral, which also pursues efficiency, produces small parameter high-performance models, and is similarly favored by the open-source community.
However, Mianbi clearly does not want to merely be the second Mistral. This company, which gathers some of the earliest researchers of large models in China, has its own distinct technical judgment and product route.
Mianbi’s efficient training methodology is reflected in the scientific approach to model training experiments. In terms of infrastructure, Mianbi has early self-developed frameworks like BMTrain to support large model training, thus reducing training costs.
At the algorithmic level, Mianbi conducts numerous “sandbox experiments” to explore optimal training configurations such as batch sizes and hyperparameter settings, theoretically seeking optimal solutions to understand patterns with lower costs and expenses. For instance, performing a large number of sandbox experiments on smaller parameter models allows for scientific experimentation to estimate the performance and parameter schemes of larger scale models, ultimately achieving significant results with smaller models.
“Continuously researching better Scaling Laws, using larger models for compression effects, and training better models and smaller models with less data.”
Additionally, beyond the foundational model, another key direction for Mianbi is AI Agents, which sets it apart from Mistral.
Mianbi is one of the earliest teams to conduct Agent research. ChatDev is a large model + Agent project co-open-sourced by Mianbi, OpenBMB, and Tsinghua University’s NLP lab. ChatDev operates like a software development company with multiple cooperating Agents. After users specify their needs, different roles of Agents interact collaboratively to produce complete software, including source code, environment dependency documentation, and user manuals. Through multi-agent collaboration, better results can be achieved within existing models. This aligns with what Andrew Ng mentioned at the Sequoia AI Summit, stating that GPT3.5 + Agentic Workflow > GPT4; in fact, he directly used ChatDev as a case study in his speech.
Agents are a significant breakthrough for Mianbi’s commercialization. ChatDev has transitioned from research papers and open-source products to commercialization, and Mianbi has launched the SaaS product ChatDev for AI Agents, attempting to help software developers and entrepreneurs complete software development tasks at lower costs and thresholds. Meanwhile, Mianbi is also exploring the commercial application of large models + Agents in finance, education, government affairs, and smart terminal scenarios.
OpenAI’s powerful approach provides a path to AGI, but there is not just one way to reach the other side. In the large model industry, which is frantically burning money to compete on computing power, relying solely on a single-dimensional enhancement can lead to bottlenecks, and such enhancements may be affected by diminishing marginal returns. Mianbi adopts a scientific approach to foundational model research, emphasizing efficiency, and in a way, pursues a form of “cost-effectiveness.” Given the same resources, Mianbi can leverage “efficiency” to achieve higher returns. The MiniCPM series models have already proven that it is feasible to perform better within the same resources; we can expect Mianbi to continue this approach and deliver GPT-4 level model products.
In contrast, while Mistral has launched a large model product claiming to challenge GPT-4, it increasingly resembles OpenAI in its business model. Mistral Large is no longer open-source, raising questions about whether Mistral, after receiving investment from Microsoft, is following the old path of OpenAI, ultimately becoming another “vassal” of Microsoft.
If pursuing efficiency is a similarity between Mianbi and Mistral, then the investment and accumulation in Agent research has given Mianbi a different path to commercialization. From websites to apps, we have witnessed the transformation of the main carriers of internet-native applications. In the AI era, Agents possess new potential, and the Mini Cannons have become the best carriers to tap into this potential.
From benchmarking Mistral to surpassing Mistral, Mianbi may have chosen a less-traveled path, but it is already confident enough to continue moving forward.



