Are you still troubled by the mixed quality and poor performance of domestic AI?
Then let’s take a look at Dev Cat AI (3in1)!
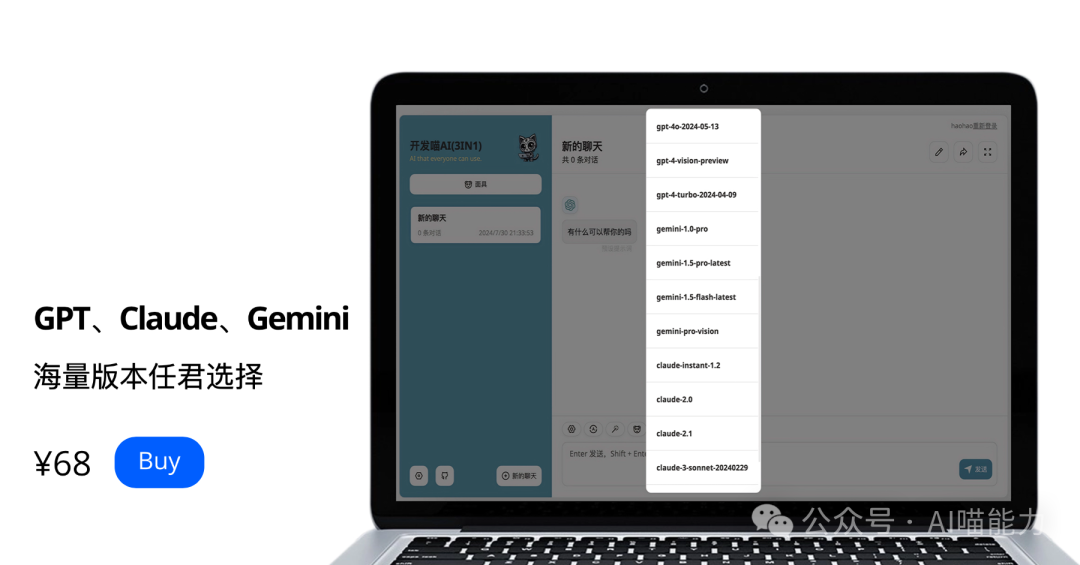
This is an integrated AI assistant that combines GPT-4, Claude3, and Gemini.
It covers all models of these three AI tools.
Including GPT-4o and Gemini flash
Now you can own them for just ¥68.
The official value is ¥420+.
Send “Dev Cat” in the backend to start using.
Become a member now to enjoy one-on-one private service, ensuring your usage is well supported.
In today’s technology-driven world, automation is revolutionizing recruitment. Imagine having a virtual IT interviewer that can not only interact intelligently with candidates but also communicate verbally. This article will guide you in building an IT interviewer using Ollama and Python, integrating audio features for a more immersive experience.
IntroductionFinding the right talent can be challenging and time-consuming. With advancements in AI and audio processing technology, the initial interview phase can be automated. This project demonstrates how to create an interactive IT interviewer using Ollama and Google Cloud’s speech-to-text and text-to-speech APIs, asking questions and processing answers through voice.
What You Will Learn
-
How to set up Ollama for conversational processing.
-
Integrate Google Cloud’s speech-to-text and text-to-speech APIs for audio functionality.
-
Build a Python project to automate the interview process.
Prerequisites
-
Python 3.7+
-
Google Cloud account: for speech-to-text and text-to-speech APIs
-
Ollama account: for conversational AI
Project Setup1. Clone the repositoryFirst, clone the project repository:
git clone https://github.com/819-hao/ollama-it-interviewer.git
cd ollama-it-interviewer2. Create and activate a virtual environmentSet up a virtual environment to manage dependencies:
python -m venv venv
source venv/bin/activate3. Install dependenciesInstall the required Python packages:
pip install -r requirements.txt4. Configure Google Clouda. Enable APIsEnable the speech-to-text and text-to-speech APIs in the Google Cloud Console.
b. Create a service account and download the JSON key
-
Go to IAM & Admin > Service Accounts.
-
Create a new service account, grant it the necessary roles, and download the JSON credentials file.
c. Set environment variablesSet the environment variable to point to your credentials file.
export GOOGLE_APPLICATION_CREDENTIALS="/path/to/your/service-account-file.json"Replace /path/to/your/service-account-file.json with the actual path to your credentials file.
-
Prepare audio files Add sample audio files in the audio_samples/ directory. You will need a candidates-response.mp3 file to simulate the candidate’s response. You can record your own voice or use a text-to-speech tool to generate this file.
-
Update configuration Edit src/config.py to configure your Ollama credentials:
OLLAMA_API_URL = 'https://api.ollama.com/v1/conversations' # Or replace with your Ollama local
OLLAMA_MODEL = 'your-ollama-model' # Replace with your Ollama model5. Run the projectRun the interviewer script:
# Option 1: Run as a module from the project root
python3 -m src.interviewerOr
# Option 2: Ensure PYTHONPATH is set and run directly
export PYTHONPATH=$(pwd)
python3 src/interviewer.pyDetailed Explanationinterviewer.py orchestrates the interview process:
from pydub import AudioSegment
from pydub.playback import play
from src.ollama_api import ask_question
from src.speech_to_text import recognize_speech
from src.text_to_speech import synthesize_speech
from dotenv import load_dotenv
import os
# Load environment variables
load_dotenv()
# Configure FFmpeg for macOS/Linux
os.environ["PATH"] += os.pathsep + '/usr/local/bin/'
def main():
question = "Tell me about your experience with Python."
synthesize_speech(question, "audio_samples/question.mp3")
question_audio = AudioSegment.from_mp3("audio_samples/question.mp3")
play(question_audio)
candidate_response = recognize_speech("audio_samples/candidate-response.mp3")
ollama_response = ask_question(candidate_response)
print(f"Ollama Response: {ollama_response}")
synthesize_speech(ollama_response, "audio_samples/response.mp3")
response_audio = AudioSegment.from_mp3("audio_samples/response.mp3")
play(response_audio)
if __name__ == "__main__":
main()ollama_api.py handles interactions with the Ollama API:
import requests
from src.config import OLLAMA_API_URL, OLLAMA_MODEL
def ask_question(question):
response = requests.post(
OLLAMA_API_URL,
json={"model": OLLAMA_MODEL, "input": question}
)
response_data = response.json()
return response_data["output"]Using Google Cloud to convert audio to text:
from google.cloud import speech
import io
def recognize_speech(audio_file):
client = speech.SpeechClient()
with io.open(audio_file, "rb") as audio:
content = audio.read()
audio = speech.RecognitionAudio(content=content)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.MP3,
sample_rate_hertz=16000,
language_code="en-US",
)
response = client.recognize(config=config, audio=audio)
for result in response.results:
return result.alternatives[0].transcripttext_to_speech.py uses Google Cloud to convert text to audio:
from google.cloud import texttospeech
import os
def synthesize_speech(text, output_file):
# Verify that the environment variable is set
assert 'GOOGLE_APPLICATION_CREDENTIALS' in os.environ, "GOOGLE_APPLICATION_CREDENTIALS not set"
client = texttospeech.TextToSpeechClient()
synthesis_input = texttospeech.SynthesisInput(text=text)
voice = texttospeech.VoiceSelectionParams(
language_code="en-US",
ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3
)
response = client.synthesize_speech(
input=synthesis_input, voice=voice, audio_config=audio_config
)
with open(output_file, "wb") as out:
out.write(response.audio_content)
print(f"Audio content written to file {output_file}")ConclusionBy integrating Ollama and Google Cloud’s audio features, you can create a virtual IT interviewer that enhances the recruitment process by automating initial candidate interactions. This project demonstrates the powerful combination of conversational AI and audio processing in Python.
Project Structure
ollama-it-interviewer/
│
├── audio_samples/
│ ├── candidate-response.mp3
│
├── src/
│ ├── interviewer.py
│ ├── ollama_api.py
│ ├── speech_to_text.py
│ ├── text_to_speech.py
│ └── config.py
│
├── requirements.txt
├── README.md
└── .gitignore
If this helps you, don’t rush to leave. 😝 Click “Share and Read” before you go.🫦