High-Precision Multilingual Speech Recognition Model
The high-precision multilingual speech recognition model usually refers to an artificial intelligence model that can accurately recognize and understand speech input in multiple languages.Such models have the following characteristics:
1. Wide Language Coverage: Capable of processing and understanding various languages and dialects, including not only common international languages but also less commonly used regional languages.
2. High-Precision Recognition: The model exhibits high accuracy in speech-to-text (STT) tasks, maintaining a high recognition rate even in noisy backgrounds, with different accents or speaking speeds.
3. Powerful Processing Capability: These models are typically based on deep learning technologies such as Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Long Short-Term Memory networks (LSTM), or Transformer architectures, capable of processing complex speech signals.
4. Real-Time Performance: For real-time applications, these models can complete speech recognition tasks in a short time to meet the demands of instant communication and interaction.
Here are some well-known high-precision multilingual speech recognition models:
– Google’s Speech-to-Text API: Google’s speech recognition service supports multiple languages and provides high-precision speech-to-text services.
– IBM Watson Speech to Text: IBM’s speech recognition service also supports multiple languages and has high recognition accuracy.
– Microsoft Azure Speech Service: Microsoft’s Azure platform provides speech services that support multiple languages, including speech recognition and speech synthesis functions.
– DeepSpeech by Mozilla: An open-source speech recognition engine launched by Mozilla, supporting multiple languages.
– Whisper by OpenAI: OpenAI’s Whisper is an open-source multilingual speech recognition model with strong cross-language capabilities.
Additionally, SenseVoice is another such model launched by Alibaba, focusing on high-precision multilingual speech recognition, with capabilities for emotion recognition and audio event detection.
Introduction
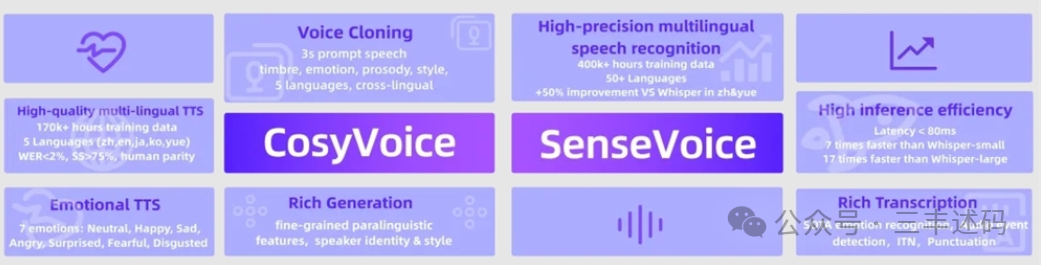
SenseVoice is a high-precision multilingual speech recognition model launched by Aliyun Tongyi. The uniqueness of this model lies in its wide language coverage, powerful emotion recognition capabilities, and efficient inference performance. SenseVoice is trained on over 400,000 hours of diverse speech data, capable of recognizing over 50 languages and demonstrating excellent cross-language recognition capabilities.
In addition to basic speech recognition functions, SenseVoice also has capabilities for emotion recognition and audio event detection. It can accurately capture emotional fluctuations in speech, such as joy, sadness, anger, etc., and has shown performance comparable to or even better than current best emotion recognition models on test data. Moreover, SenseVoice is equipped with sound event detection capabilities, able to recognize various common human-computer interaction events such as music, applause, laughter, crying, coughing, and sneezing.
In terms of performance optimization, SenseVoice adopts an advanced non-autoregressive end-to-end framework, achieving extremely low inference latency. For example, the SenseVoice-Small model requires only 70 milliseconds to complete inference when processing 10 seconds of audio, which is more than 15 times faster than the Whisper-Large model, providing strong support for real-time speech recognition applications.
Additionally, Aliyun Tongyi has also launched another speech generation model—CosyVoice, which also supports multilingual capabilities, tone and emotion control, and demonstrates outstanding performance in multilingual speech generation, zero-shot speech generation, cross-language speech cloning, and instruction following.
Installation and Usage
SenseVoice is an open-source speech large model project launched by Alibaba. Below are the general steps for installing and using SenseVoice, but please note that specific steps may vary based on the latest updates and documentation of the project.
Installation Steps:
1. Environment Preparation:
– Ensure that your computer or server meets the system requirements for SenseVoice, including operating system, processor, memory, and storage space.
– Install a Python environment, typically requiring Python 3.x.
2. Clone the Code Repository:
– Use Git to clone the official SenseVoice code repository to your local machine:
git clone https://github.com/alibaba/SenseVoice.git– Alternatively, you can download the ZIP file directly from the GitHub page and unzip it.
3. Install Dependencies:
– Navigate to the project directory and install the required dependency libraries. Usually, these dependencies are listed in the project’s `requirements.txt` file:
cd SenseVoice
pip install -r requirements.txt4. Model Download:
– According to the project documentation, download the pre-trained SenseVoice model. This may involve downloading model weights from a specific link.
5. Environment Configuration:
– Configure environment variables or relevant configuration files according to the project documentation, ensuring the model can be loaded and used correctly.
Usage Steps:
1. Start the Service:
– Use the provided script to start the SenseVoice service. This may be a command-line tool or a web service.
python run.py– If the project provides a WebUI, you may need to start a web server.
2. Audio Input:
– Pass the audio files that need to be recognized to the SenseVoice model. This may be done through command-line parameters, WebUI upload, or API calls.
3. Execute Recognition:
– Perform the speech recognition operation. SenseVoice will process the audio file and output the recognition results.
4. View Results:
– Check the recognition results, which may include text output from speech-to-text, emotion analysis results, and audio event detection information.
Notes:
– Before installation and usage, please ensure you have read the project’s README file and official documentation to understand the latest installation guidelines and usage instructions.
– SenseVoice may require substantial computational resources, especially during model inference, so ensure your hardware configuration meets the requirements.
– If you encounter issues, check the project’s ISSUES section to see if other users have encountered similar problems, or directly report a new issue.
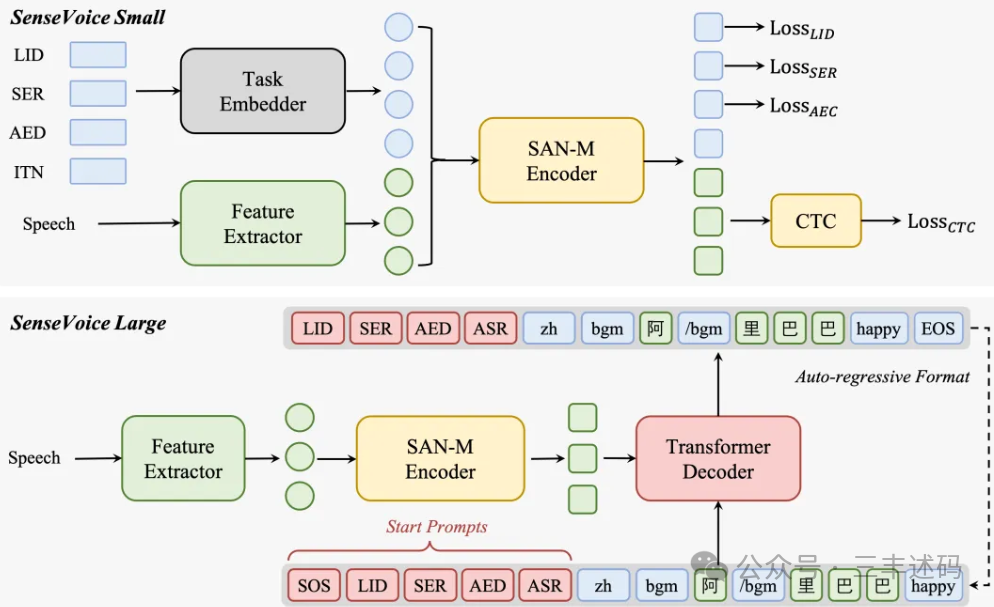
Speech Understanding Model: SenseVoice Small
SenseVoice Small is a speech foundation model that uses only the encoder, designed for fast speech understanding. It includes various features, including Automatic Speech Recognition (ASR), Language Identification (LID), Speech Emotion Recognition (SER), and Acoustic Event Detection (AED). SenseVoice Small supports multilingual recognition in Chinese, English, Cantonese, Japanese, and Korean. Additionally, it offers extremely low inference latency, being 7 times faster than Whisper Small and 17 times faster than Whisper Big.
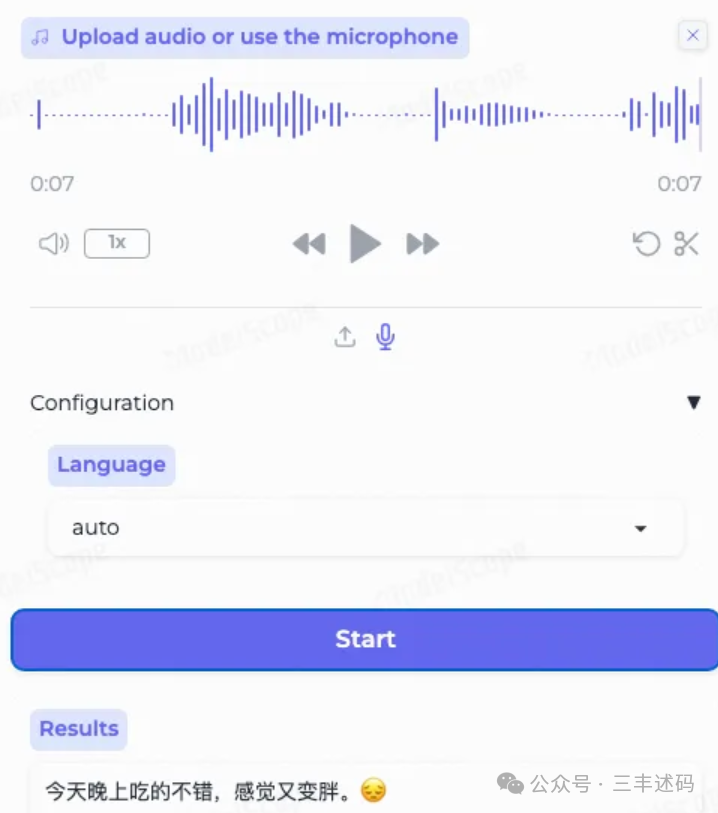
Usage
Upload audio files or input through a microphone, then select the task and language. The audio is transcribed into corresponding text (😊 Happy, 😡 Angry/Excited, 😔 Sad) along with the type of sound events (😀 Laughter 🎼 Music 👏 Applause 🤧 Coughing and Sneezing, 😭 Crying event labels placed before the text, emotions placed after the text).
It is recommended that audio input duration be less than 30 seconds. For audio exceeding 30 seconds, local deployment is recommended.
Repository
-
SenseVoice: Multilingual Speech Understanding Model
-
FunASR: Basic Speech Recognition Toolkit
-
CosyVoice: High-Quality Multilingual TTS Model
API Usage
pip install gradio_clientfrom gradio_client import Client
client = Client("https://s5k.cn/api/v1/studio/iic/SenseVoice/gradio/")
result = client.predict( "https://github.com/gradio-app/gradio/raw/main/test/test_files/audio_sample.wav", # filepath in 'Upload audio or use the microphone' Audio component "auto", # Literal['auto', 'zh', 'en', 'yue', 'ja', 'ko', 'nospeech'] in 'Language' Dropdown component api_name="/model_inference")
print(result)Open Source Address
Follow the public account and reply 20240715 to obtainYou may also like:
【Open Source】 20,000 Stars! Low-Code Platform, Saving You Hundreds of Hours of Work
【Open Source】 An AI-Driven Programming Assistant Designed to Help Developers Improve Coding Efficiency, Reduce Errors, and Accelerate Development Processes.
【Open Source】 Visual Drag-and-Drop Programming, Automatically Generate Projects, Automatically Generate Code, Self-Import Third-Party Components
【Open Source】 Zero-Code, Fully Functional, Strong Security ORM Library, Zero-Code Backend Interface and Documentation, Customize JSON Data and Structure for Frontend (Client)
【Open Source】 DingTalk and Lark Style, Including Frontend and Backend Code, Out-of-the-Box Low-Code Open Source Professional Workflow Engine Based on Flowable
Add WeChat to join relevant discussion groups,
Note “Microservices” to enter group discussions
Note “Low-Code” to enter low-code group discussions
Note “AI” to join AI Big Data and Data Governance group discussions
Note “Digital” to join IoT and Digital Twin group discussions
Note “Security” to join security-related group discussions
Note “Automation” to join automation operation and maintenance group discussions
Note “Trial” to apply for product trials
Note “Channel” for cooperation channel information
Note “Customization” for project customization, full source code delivery
