

Authorized Reprint from OReillyData
Author | Raul Puri et al.
How to Build and Train an Image Captioning Generator Using TensorFlow
The image captioning model combines advances in computer vision and machine translation in recent years, using neural networks to generate captions for real images. For a given input image, the neural image captioning model is trained to maximize the likelihood of generating a caption. It can be used to produce novel image descriptions. For example, below are the captions generated by a neural image captioning generator trained on the MS COCO dataset.

Figure 1. Source: Paul Puri. Image from the MS COCO dataset
In this article, we will present an intermediate-level tutorial teaching you how to use a variant of Google’s “Show and Tell” model and the Flickr30k dataset to train an image captioning generator. We use TensorFlow’s framework to build, train, and test our model because it is relatively easy to use and has a growing online community.
Why Generate Captions?
The success of deep neural networks applied to computer vision and natural language processing tasks in recent years has inspired AI researchers to explore new research opportunities, bridging these previously independent fields. Caption generation models must balance the understanding of visual cues and natural language.
The intersection of these traditionally unrelated fields has the potential to produce transformative changes on a larger scale. This technology now has some direct applications, such as automatically generating summaries for YouTube videos or labeling untagged images. More creative applications could significantly improve the quality of life for a broader audience. Like traditional computer vision aims to help computers better perceive and understand the world, this new technology has the potential to further make the world more accessible and understandable for humans. It can act as a guide or even provide visual assistance services in daily life, as demonstrated by the Horus wearable device developed by the Italian AI company Eyra.
Some Setup Work Required
Before we officially start, we need to do some housekeeping.
First, you need to install TensorFlow. If this is your first time using TensorFlow, we recommend you first take a look at this article “Hello, TensorFlow! Building and Training Your First TensorFlow Graph from Scratch”.
You will need to install the pandas, OpenCV2, and Jupyter libraries to ensure the related code runs. However, to simplify the installation process, we strongly recommend using the Docker installation guide from the GitHub repository associated with this article.
You also need to download the Flickr30k image files and the image caption dataset. Our GitHub repository provides download links as well.
Now, let’s get started!
Image Captioning Model
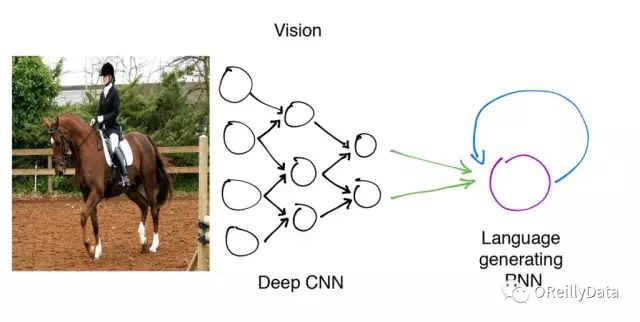
Figure 2. Source: Shannon Shih from the Berkeley Machine Learning Organization. Image of a horse from MS COCO
In summary, this is the model we will be training. Each image can be encoded into a 4096-dimensional vector representation by a deep convolutional neural network. A language generation RNN (recurrent neural network) will sequentially decode this representation and generate a natural language description.
Caption Generation as an Extension of Image Classification
As a task in computer vision, image classification has a long history and many excellent models. Classification requires the model to stitch together visual information related to shapes and objects in the image and then categorize the image into a class. Other computer vision machine learning models, such as object detection and image segmentation, not only recognize the presented information but also learn how to interpret two-dimensional space and integrate these two understandings to determine the object information distributed in the image. For caption generation, there are two main questions:
-
How can we leverage the successful results of image classification models to extract important information from images?
-
How can our model learn to integrate the understanding of language and the understanding of images?
Using Transfer Learning
We can leverage existing models to help achieve image caption generation. Transfer learning allows us to apply the transformations learned from neural networks trained on other tasks to our own data. In our scenario, the VGG-16 image classification model takes 224 x 224 pixel images as input and produces a 4096-dimensional feature vector representation for classifying images.
We can use these representations generated by the VGG-16 model (also known as image vectors) to train our own model. Due to the length of this article, we will omit the architecture of VGG-16 and directly use the pre-computed 4096-dimensional features to speed up the training process.
Importing VGG image features and image captions is quite straightforward:
def get_data(annotation_path, feature_path):
annotations = pd.read_table(annotation_path, sep='\t', header=None, names=['image', 'caption'])
return np.load(feature_path, 'r'), annotations['caption'].valuesUnderstanding Captions
Now that we have the image representations, we also need our model to learn how to decode these representations into understandable captions. Due to the inherent sequential nature of text, we will utilize the recurrent characteristics of an RNN/LSTM network (for more information, please refer to the article “Understanding LSTM Networks”). These networks are trained to predict the next word given a series of preceding words and image representations.
Long Short-Term Memory (LSTM) units allow this model to better select what information to use for the caption word sequence, what to remember, and what information to forget. TensorFlow provides a wrapper function to generate an LSTM layer for given input and output dimensions.
To convert words into fixed-length representations suitable for LSTM input, we use a vector layer to map words into 256-dimensional features (also known as word vectors). Word vectors help us represent words as vectors, while similar word vectors are also semantically similar. To learn more about how word vectors capture relationships between different words, please see the article “Using Deep Learning to Capture Text Semantics”.
In this VGG-16 image classifier, the convolutional layers extract 4096-dimensional representations, which are then fed into the final softmax layer for classification. Since the LSTM units require 256-dimensional text input, we need to convert the image representations into this desired representation for the target captions. To achieve this, we need to add another vector layer to learn how to map the 4096-dimensional image features into the 256-dimensional text feature space.
Building and Training the Model
Overall, the Show and Tell model looks something like this:
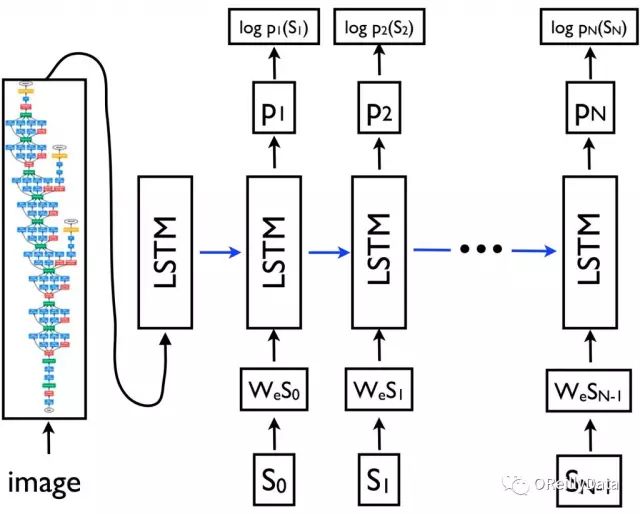
Figure 3. Source: “Show and Tell: Lessons Learned from the 2015 MSCOCO Image Captioning Challenge”
In Figure 3, {s0, s1, …, sN} represents the vocabulary of caption words we are trying to predict, and {wes0, wes1, …, wesN-1} are the word vectors for each word. The LSTM output {p1, p2, …, pN} is the probability distribution of the next word in the sentence generated by this model. The training objective of the model is to minimize the negative sum of the logarithm of the probabilities for all words.
def build_model(self):
# declaring the placeholders for our extracted image feature vectors, our caption, and our mask
# (describes how long our caption is with an array of 0/1 values of length `maxlen`
img = tf.placeholder(tf.float32, [self.batch_size, self.dim_in])
caption_placeholder = tf.placeholder(tf.int32, [self.batch_size, self.n_lstm_steps])
mask = tf.placeholder(tf.float32, [self.batch_size, self.n_lstm_steps])
# getting an initial LSTM embedding from our image embedding
image_embedding = tf.matmul(img, self.img_embedding) + self.img_embedding_bias
# setting initial state of our LSTM
state = self.lstm.zero_state(self.batch_size, dtype=tf.float32)
total_loss = 0.0
with tf.variable_scope("RNN"):
for i in range(self.n_lstm_steps):
if i > 0:
# if this isn’t the first iteration of our LSTM we need to get the word embedding corresponding
# to the (i-1)th word in our caption
with tf.device("/cpu:0"):
current_embedding = tf.nn.embedding_lookup(self.word_embedding, caption_placeholder[:,i-1]) + self.embedding_bias
else:
# if this is the first iteration of our LSTM we utilize the embedded image as our input
current_embedding = image_embedding
if i > 0:
# allows us to reuse the LSTM tensor variable on each iteration
tf.get_variable_scope().reuse_variables()
out, state = self.lstm(current_embedding, state)
print(out, self.word_encoding, self.word_encoding_bias)
if i > 0:
# get the one-hot representation of the next word in our caption
labels = tf.expand_dims(caption_placeholder[:, i], 1)
ix_range = tf.range(0, self.batch_size, 1)
ixs = tf.expand_dims(ix_range, 1)
concat = tf.concat([ixs, labels], 1)
onehot = tf.sparse_to_dense(
concat, tf.stack([self.batch_size, self.n_words]), 1.0, 0.0)
# perform a softmax classification to generate the next word in the caption
logit = tf.matmul(out, self.word_encoding) + self.word_encoding_bias
xentropy = tf.nn.softmax_cross_entropy_with_logits(logits=logit, labels=onehot)
xentropy = xentropy * mask[:,i]
loss = tf.reduce_sum(xentropy)
total_loss += loss
total_loss = total_loss / tf.reduce_sum(mask[:,1:])
return total_loss, img, caption_placeholder, maskUsing Inference to Generate Captions
Once training is complete, we have a model that can provide the probability of the next word in the caption given an image and all preceding vocabulary. So how do we use this model to generate captions?
The simplest method is to take an image as input and iteratively output the next word with the highest probability, thus generating a caption.
def build_generator(self, maxlen, batchsize=1):
# same setup as `build_model` function
img = tf.placeholder(tf.float32, [self.batch_size, self.dim_in])
image_embedding = tf.matmul(img, self.img_embedding) + self.img_embedding_bias
state = self.lstm.zero_state(batchsize, dtype=tf.float32)
# declare list to hold the words of our generated captions
all_words = []
print(state, image_embedding, img)
with tf.variable_scope("RNN"):
# in the first iteration we have no previous word, so we directly pass in the image embedding
# and set the `previous_word` to the embedding of the start token ([0]) for the future iterations
output, state = self.lstm(image_embedding, state)
previous_word = tf.nn.embedding_lookup(self.word_embedding, [0]) + self.embedding_bias
for i in range(maxlen):
tf.get_variable_scope().reuse_variables()
out, state = self.lstm(previous_word, state)
# get a one-hot word encoding from the output of the LSTM
logit = tf.matmul(out, self.word_encoding) + self.word_encoding_bias
best_word = tf.argmax(logit, 1)
with tf.device("/cpu:0"):
# get the embedding of the best_word to use as input to the next iteration of our LSTM
previous_word = tf.nn.embedding_lookup(self.word_embedding, best_word)
previous_word += self.embedding_bias
all_words.append(best_word)
return img, all_wordsIn many cases, this method works well. However, “greedily” using the next word with the highest probability may not yield the most suitable overall captions.
One feasible way to mitigate this issue is through “beam search”. This algorithm recursively searches for the k best candidates in sentences of maximum length t to generate a sentence of length t+1, retaining only the best k results at each iteration. This allows exploration of a larger optimal caption space while keeping inference within manageable computational bounds. In the example below, the algorithm maintains a series of k=2 candidate sentences at each vertical time step (bolded).
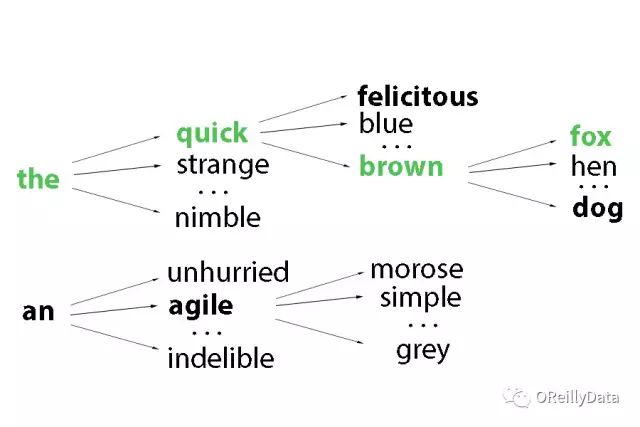
Figure 4 Source: Daniel Ricciardelli
Limitations and Discussion
The neural image captioning generator provides a useful framework for learning the mapping from images to human-understandable captions. By training on a large number of image-caption pairs, this model learns to extract the relationship between visual features and relevant semantic information.
However, for a static image, our caption generator focuses on features that are beneficial for classification, which may not necessarily be advantageous for caption generation. To improve the information relevant to captions within each feature, we can incorporate this image vector model (the VGG-16 model used to encode features) as part of the overall caption generation model. This would allow us to fine-tune the image encoder more precisely to fulfill the role of caption generation.
Additionally, if we closely observe the generated captions, we may find that they are often quite vague and generalized. For example, in the following image-caption pair:

Figure 5. Source: Raul Puri, image from the MS COCO dataset
This image is certainly “a giraffe standing next to a tree”. However, if we look at other images, we might notice that it generates “a giraffe standing next to a tree” for any image with a giraffe, as giraffes usually appear near trees in the training set.
Next Steps
First, if you want to improve the model presented here, please read Google’s open-source “Show and Tell Network”. It can be trained using Inception-v3 image vectors and the MS COCO dataset.
The state-of-the-art image captioning models now include a visual attention mechanism, allowing the model to selectively focus on interesting areas in the image when producing captions.
Also, if you are interested in the implementation of cutting-edge caption generators, please read the paper “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”.
Note: Don’t forget to visit the GitHub repository corresponding to this article for the Python code and iPython notebook.

👇 Click Read Original, fill out the questionnaire, and get benefits
1. Raul Puri
Paul Puri is an undergraduate researcher who graduated from UC Berkeley in 2017. Raul has contributed to research projects across multiple domains, including but not limited to: robotics and automation, computer vision, medical imaging, and bio-mimetic devices. However, all this research work focuses on the application of machine learning and machine learning systems in safety, autonomous driving, natural language processing, computer vision, and robotics. Raul is also passionate about giving back to the community by teaching applied machine learning concepts. He is also a teaching assistant and lecturer for several machine learning courses at Berkeley.
2. Daniel Ricciardelli
Dan Ricciardelli is an undergraduate researcher at UC Berkeley. His research interests include natural language processing for finance and industry, computer vision, deep active learning, and automated knowledge discovery. Dan is very enthusiastic about making machine learning accessible to both technical and non-technical students and professionals through the Berkeley Machine Learning Organization.
Click the image to read the article
Warning! This may be a mind map that will change your programming learning!


