
Click the blue text above to follow me
This article: 4300 words, 10 minutes read
Why We Need Better Prompt Strategies
The traditional prompting methods often rely on a fixed set of examples, which limits the potential of the model. Recently, a research team from the University of Texas at Dallas and other institutions proposed a groundbreaking adaptive prompting method (Adaptive-Prompt), which significantly enhances the model’s reasoning ability by dynamically selecting the most informative examples. This research is not only innovative theoretically but also shows significant performance advantages in practice, which is worth a look.

Limitations of Traditional Methods
Before delving into this innovation, we need to recognize the main challenges faced by current prompting methods. Although traditional Chain-of-Thought (CoT) prompting methods have achieved significant results in enhancing model reasoning capabilities, their effectiveness largely depends on manually designed examples. This method has two main issues: First, manually designing examples requires a lot of expertise and time investment; second, a fixed set of examples may not adapt to different types of questions, leading to poor model performance in certain scenarios.
Core Principles of Adaptive Prompting Method
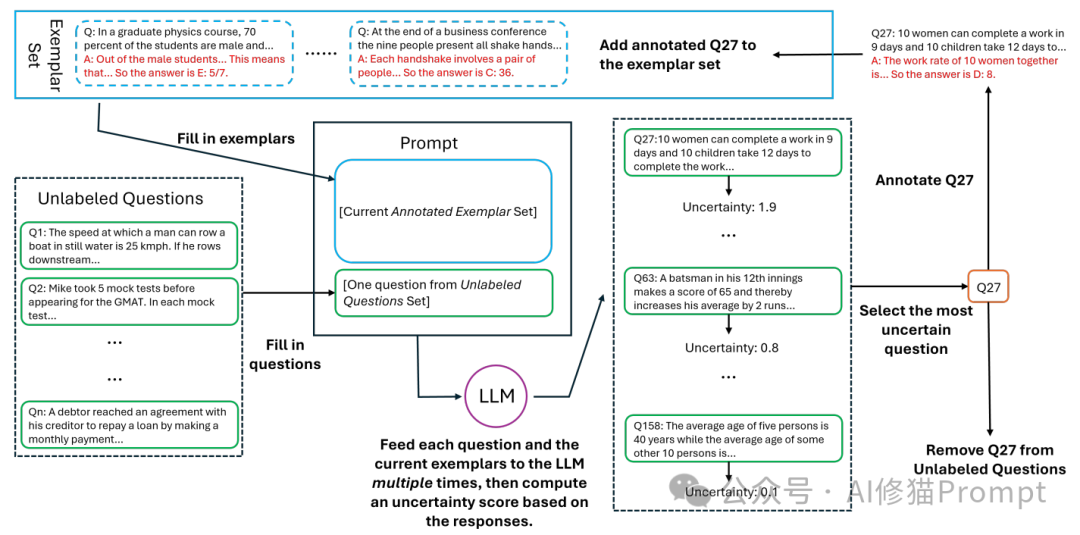
The left side of the diagram shows examples of an unlabeled question set. These questions cover queries from different fields, such as physics course statistics (“In the physics class, 75% of students…”) and minutes from business meetings. These unlabeled questions form the original input pool of the system.
The central area of the diagram depicts the core processing workflow, which includes three key components:
-
Prompt Template (at the top): used to organize the currently labeled example set
-
Large Language Model (LLM, at the center): serves as the core reasoning engine
-
Question Filling Area (located at the arrow from the left to center): shows how unlabeled questions are combined with existing examples
The right side of the diagram illustrates the mechanisms for uncertainty assessment and example selection. This part specifically labels three question examples and their corresponding uncertainty scores:
-
The first question has an uncertainty score of 1.9 (highest)
-
The second question has an uncertainty score of 0.8 (medium)
-
The third question has an uncertainty score of 0.1 (lowest)
The flow of arrows in the diagram reveals the entire workflow:
-
Starting from the unlabeled question pool on the left
-
Performing multiple inferences through the central LLM
-
Conducting uncertainty assessment on the right
-
Finally selecting the most uncertain question (e.g., the question with a score of 1.9 in the diagram) for labeling
Notably, the upper right corner of the diagram shows the process of adding the selected question (Q27) to the example set. The entire workflow is clearly presented through visual design, illustrating how the system identifies and selects the most valuable examples, including key steps such as question selection, label addition, example set updating, and re-evaluation.
Method Principles and Steps
The core of the Adaptive-Prompt method proposed by the research team lies in its adaptability and iterativeness. Unlike traditional methods, this approach does not select all examples at once but dynamically determines the next optimal example based on the performance of the already selected examples through an iterative process. The working principles of this method can be divided into several key steps:
-
Initialization: First, establish an empty example set.
-
Uncertainty Assessment: For each question in the training set, conduct multiple queries in conjunction with the current example set to calculate the uncertainty score of the model’s answers.
-
Example Selection: Select the question with the highest uncertainty for manual labeling and add it to the example set.
-
Iterative Optimization: Repeat steps 2 and 3 until the predetermined number of examples is reached.
The research team formalized this process into an algorithm:

To better understand how this algorithm works, let’s illustrate through a practical application scenario. Suppose you are a developer of a customer service system and need to build an AI assistant capable of automatically answering user questions. You have 1000 unlabeled customer service questions (this is Q in the algorithm), but due to resource constraints, you can only select 8 questions (this is k) for manual labeling as examples.
This algorithm acts like a savvy teaching assistant and works as follows:
-
First, it starts with no examples (E=empty set)
-
For each customer service question, it will have the AI (the model M in the algorithm) attempt to answer 10 times (l times). Just like you ask the same question 10 times to see if the AI’s answers are consistent.
-
Through these 10 answers, the algorithm calculates the “uncertainty score” for each question. For example:
-
If all 10 answers are different, it indicates that the AI is very uncertain about this question
-
If all 10 answers are the same, it indicates that the AI is confident about this question
Select the question with the highest score (most uncertain) and have a human expert write a standard answer and reasoning process
Add this question and the expert’s answer to the example set E
Repeat this process until 8 examples are selected
Thus, the final selected 8 examples will be:
-
The questions the AI is most uncertain about
-
The questions with the least knowledge overlap among themselves
-
The questions that most enhance the AI’s answering capability
The uniqueness of this method lies in its adaptability: every time a new example is selected, the influence of existing examples is considered, ensuring the diversity and effectiveness of the example set. This is akin to assembling an optimal teaching team, where each member brings unique knowledge and experience.
How to Achieve Adaptive Selection
The researchers adopted two uncertainty measurement methods in the implementation of adaptive selection: Disagreement and Entropy. For each candidate question, the model generates multiple answers, assessing the model’s certainty based on the consistency of these answers. Specifically:
-
Disagreement measurement: Calculate the ratio of different answers, i.e., unique(answers)/total_answers
-
Entropy-based measurement: Calculate the information entropy of the answer distribution, reflecting the uncertainty of the answer distribution
This dual measurement method ensures that the selected examples can maximize the learning effect of the model.
Concrete Evidence of Performance Improvement
The research team conducted extensive experiments on multiple standard datasets, including:
-
Arithmetic reasoning tasks: GSM8K, SVAMP, and AQuA
-
Common sense reasoning tasks: StrategyQA and CSQA
-
Symbolic reasoning tasks: Letter Concat
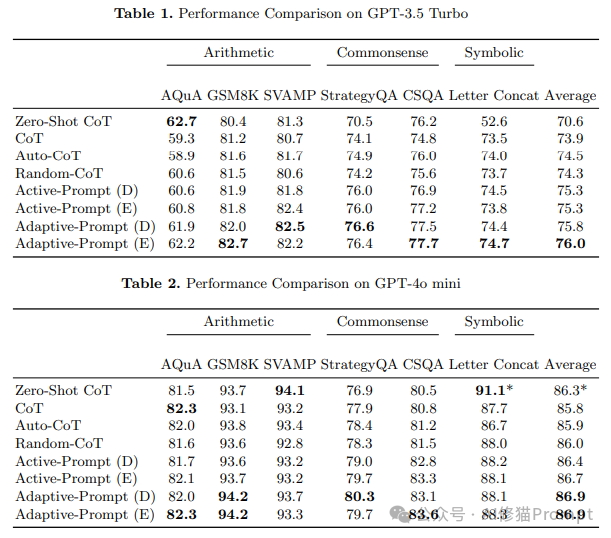
The research team conducted a comprehensive performance evaluation on two mainstream large language models, with the experimental results shown in Table 1 and Table 2. Table 1 presents the test results on GPT-3.5 Turbo, while Table 2 shows the performance on the more powerful GPT-4o mini model. These experimental results reveal several important findings:
-
Performance on GPT-3.5 Turbo:
-
Adaptive-Prompt (E) achieved an accuracy of 82.7% on the GSM8K dataset, improving by 0.8% over the baseline method
-
On the SVAMP dataset, Adaptive-Prompt (D) achieved an accuracy of 82.5%, outperforming all comparison methods
-
On the common sense reasoning task StrategyQA, this method reached an accuracy of 76.6%, 6.1 percentage points higher than Zero-Shot CoT
-
On average, Adaptive-Prompt achieved an overall accuracy of 76.0% across all tasks, significantly better than other methods
Performance on GPT-4o mini:
-
The overall performance of the model improved significantly, with all methods showing notable increases in accuracy
-
Adaptive-Prompt (E) reached an accuracy of 94.2% on GSM8K
-
On the CSQA task, this method achieved an accuracy of 83.6%, improving by 3.1 percentage points over the baseline method
-
The average accuracy across all tasks reached 86.9%, maintaining the method’s advantage
Comparison between methods:
-
Compared to traditional CoT methods, the adaptive method outperformed in almost all tasks
-
Compared to Active-Prompt, the new method showed a significant advantage in handling complex reasoning tasks
-
Zero-Shot CoT performed well on some simple tasks but underperformed on complex tasks
These experimental results not only validate the effectiveness of the Adaptive-Prompt method but also demonstrate its adaptability across different types of tasks and models. Particularly in handling complex reasoning tasks, this method exhibited significant advantages.
Why Adaptive Prompting is More Effective
The research findings revealed several important discoveries:
-
Redundancy Elimination: Compared to traditional one-time selection methods, adaptive selection effectively avoids knowledge redundancy among examples. For instance, when two questions essentially examine the same knowledge point, the system tends to select only one as an example.
-
Impact of Example Quantity: Experiments showed that the choice of the number of examples (k) has a significant impact on performance. The research team conducted a series of carefully designed control experiments to explore the relationship between the number of examples and model performance.
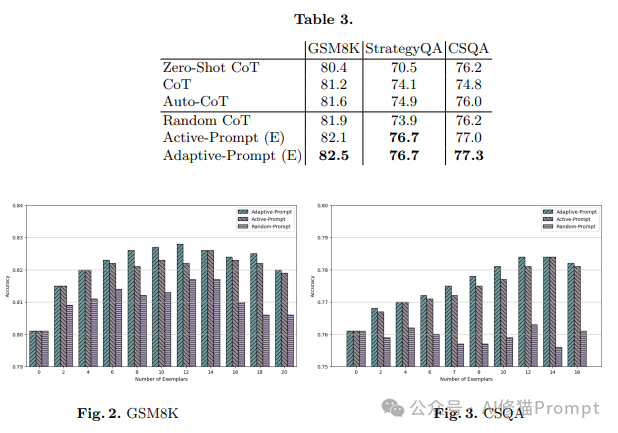
The researchers conducted detailed comparative experiments on three representative datasets (GSM8K, StrategyQA, and CSQA). The data in Table 3 shows that under the same controlled variables, Adaptive-Prompt (E) achieved the best performance across all tasks: an accuracy of 82.5% on GSM8K, 76.7% on StrategyQA, and 77.3% on CSQA.
More notably, the performance trends shown in Fig2 and Fig3 reveal how the number of examples (k) affects model performance:
-
Performance on the GSM8K dataset:
-
As k increases from 2 to 12, performance generally trends upward
-
Peaks around k=12
-
When k continues to increase, performance begins to decline slightly
-
Adaptive-Prompt consistently maintains its leading advantage
-
Performance on the CSQA dataset:
-
The performance improvement curve is smoother
-
Optimal performance occurs around k=10
-
The gap with the baseline method becomes more pronounced at larger k values
-
Random-Prompt shows limited performance improvement as k increases
This experimental data supports an important conclusion: there is an optimal range for the number of examples (usually between 8-12), within which the adaptive method can maximize its advantages. This finding has significant practical implications: one should neither select too few examples, limiting the method’s effectiveness, nor too many, which could increase computational overhead with limited benefits.
-
Impact of Model Capability: Experimental results indicate that the adaptive prompting method achieves more significant performance improvements on relatively weaker models (like GPT-3.5 Turbo), while the improvement is relatively smaller on more powerful models (like GPT-4).
How Prompt Engineers Can Apply This Method
Based on the research findings, we can summarize the following practical recommendations:
-
Example Selection Strategy:
-
Do not select all examples at once
-
Evaluate the uncertainty of candidate examples through multiple queries
-
Prioritize examples that can bring new knowledge points
Example Quantity Optimization:
-
Adjust the number of examples based on task complexity
-
Generally maintain between 8-12 examples
-
Regularly evaluate the effectiveness of the example set
Application Scenario Selection:
-
For complex reasoning tasks, prioritize using adaptive prompting
-
In resource-constrained scenarios, a smaller candidate pool can be used
-
Adopt different strategies for models of varying strengths
Conclusion: Rethinking the Paradigm of Prompt Engineering
The success of Adaptive-Prompt indicates that prompt engineering is shifting from a static paradigm to a dynamic one. This shift not only enhances model performance but, more importantly, provides a new way of thinking: improving AI systems’ capabilities through dynamic adaptation and continuous optimization. For prompt engineers, this means rethinking the methods of prompt design, shifting from fixed patterns to more flexible and intelligent adaptive solutions. This can not only enhance model performance but also reduce the labor costs of prompt engineering, driving AI applications towards more efficient and intelligent directions.
If you wish to learn more or need additional prompts, you can also refer to this article “AI Repair Cat Prompt Public Account Article Appreciation and Material Classification Summary“ to support me with appreciation, and you can receive more SYSTEM PROMPT.If you need more DSPy code that has been run, or case studies, you can check the following articles.I hope this article is helpful to you!

AI Repair Cat Prompt Public Account Article Appreciation and Material Classification Summary

Prompt under First Principles, a Guide to Help You Become a Master

Transforming Methodology into Complex Prompts? Advanced Guide to Prompt Principles and Algorithms to Help You Elevate Practice from Knowledge to Action

Local Offline Generative AI Document Generation Efficiency Guide, Safer, More Economical, and More Efficient
<End of Article>
-
For reproduction, please contact this cat. Unauthorized scraping will be prosecuted
