
Selected from The M Tank
Translated by Machine Heart
Contributors: Jiang Siyuan, Liu Xiaokun
The M Tank has edited a report titled “A Year in Computer Vision,” documenting the research achievements in the field of computer vision from 2016 to 2017. This detailed material is invaluable for developers and researchers. The material consists of four main parts, and in this article, Machine Heart provides a compiled introduction to the first part, with subsequent content from other parts to be released later.
Table of Contents
Introduction
Part One
-
Classification/Localization
-
Object Detection
-
Object Tracking
Part Two
-
Segmentation
-
Super-Resolution, Style Transfer, Coloring
-
Action Recognition
Part Three
-
3D Objects
-
Human Pose Estimation
-
3D Reconstruction
-
Other Unclassified 3D
-
Summary
Part Four
-
Convolutional Architectures
-
Datasets
-
Other Unclassifiable Materials and Interesting Trends
Conclusion
Full PDF address: http://www.themtank.org/pdfs/AYearofComputerVisionPDF.pdf
Introduction
Computer vision is the discipline that studies the visual capabilities of machines, or more precisely, the discipline that enables machines to perform visual analysis of their environment and stimuli within it. Machine vision typically involves the evaluation of images or videos. The British Machine Vision Association (BMVA) defines machine vision as “the automatic extraction, analysis, and understanding of useful information from a single image or a sequence of images.”
A true understanding of our environment cannot be achieved solely through visual representation. More accurately, visual cues are transmitted through visual neurons to the primary visual cortex, where the brain analyzes them in a highly characterized form. The extraction of interpretations from this sensory information encompasses nearly all of our natural evolution and subjective experience, including how evolution has allowed us to survive and how we learn and understand the world throughout our lives.
In this regard, the visual process is merely a transmission of images and their interpretation. However, from a computational perspective, images are much closer to thought or cognition, involving many functions of the brain. Therefore, due to its significant interdisciplinary nature, many people believe that computer vision represents a true understanding of the visual environment and its contexts, leading us towards achieving strong artificial intelligence.
However, we are still in the embryonic stage of development in this field. The purpose of this article is to clarify the most significant advancements in computer vision from 2016 to 2017 and how these advancements promote practical applications.
For simplicity, this article will limit itself to basic definitions and will omit much content, especially regarding the design architectures of various convolutional neural networks.
Here are some recommended learning materials, with the first two suitable for beginners to quickly build a solid foundation, and the latter two for advanced study:
-
Andrej Karpathy: “What a Deep Neural Network thinks about your #selfie,” the best article for understanding CNN applications and design functions [4].
-
Quora: “What is a convolutional neural network?” Clear and straightforward explanation, especially suitable for beginners [5].
-
CS231n: Convolutional Neural Networks for Visual Recognition, a Stanford University course, an excellent resource for advanced study [6].
-
Deep Learning (Goodfellow, Bengio & Courville, 2016), this book provides detailed explanations of CNN features and architecture design in Chapter 9, with free resources available online [7].
For those who wish to further understand neural networks and deep learning, we recommend:
-
Neural Networks and Deep Learning (Nielsen, 2017), a free online book that provides readers with an intuitive understanding of the complexities of neural networks and deep learning. Even reading just Chapter 1 can help beginners thoroughly understand this article.
Next, we will briefly introduce the first part of this article, which mainly describes basic and popular computer vision tasks such as object classification and localization, object detection, and object tracking. Machine Heart will subsequently share the later three parts of the discussion on computer vision by Benjamin F. Duffy and Daniel R. Flynn, including Part Two’s semantic segmentation, super-resolution, style transfer, and action recognition, Part Three’s 3D object recognition and reconstruction, and Part Four’s convolutional network architectures and datasets.
Basic Computer Vision Tasks
Classification/Localization
Image classification tasks typically refer to assigning specific labels to an entire image, such as the label for the left image being CAT. Localization, on the other hand, refers to finding the position where the identified target appears in the image, usually indicated by some bounding boxes around the object. Currently, the accuracy of classification/localization on ImageNet [9] has surpassed that of a group of trained humans [10]. Therefore, compared to the basic concepts in the previous section, we will focus on later topics such as semantic segmentation and 3D reconstruction.
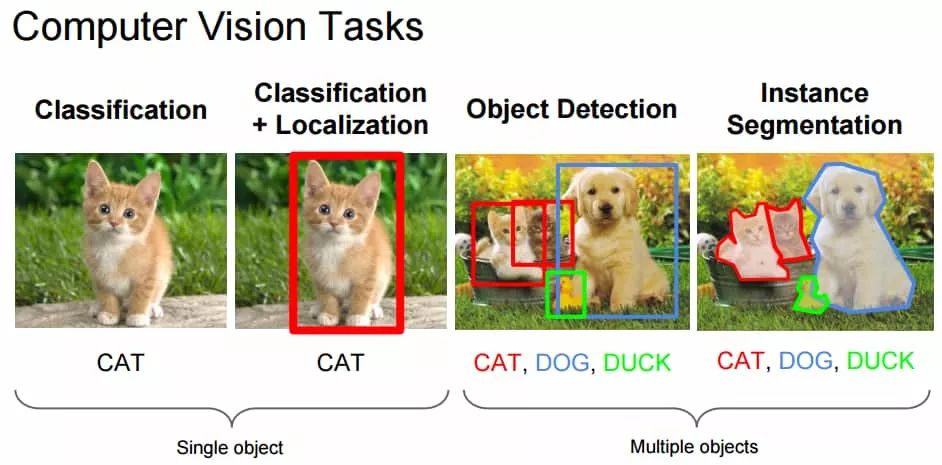
Figure 1: Computer vision tasks, source: CS231n course materials.
However, with the increase in object categories [11], introducing large datasets will provide new metrics for recent research advancements. In this regard, Keras [12] founder Francois Chollet applied architectures including Xception to large internal datasets at Google, which contains 17,000 object categories and a total of 350 million multi-category images.
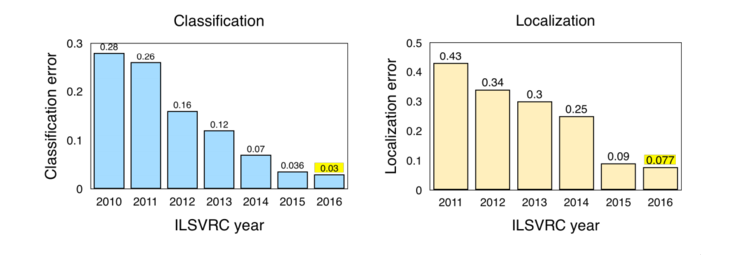
Figure 2: Yearly error rate for classification/localization in the ILSVRC competition, source: Jia Deng (2016), ILSVRC2016.
Highlights from ImageNet LSVRC (2016):
-
Scene classification refers to classifying images using specific scenes such as “greenhouse,” “stadium,” and “cathedral.” ImageNet held a scene classification challenge based on the Places2 [15] sub-dataset last year, which consists of 365 scenes and a total of 8 million training images. Hikvision [16] chose deep Inception-like networks and not very deep ResNet, achieving a 9% Top-5 error rate through their ensemble to win the competition.
-
Trimps-Soushen won the ImageNet classification task with a Top-5 classification error rate of 2.99% and a localization error rate of 7.71%. The team used an ensemble of classification models (i.e., Inception, Inception-ResNet, ResNet, and the average results of wide residual network modules [17]) along with a label-based localization model Faster R-CNN [18] to accomplish the task. The training dataset contained 1,000 categories with a total of 1.2 million image data, and the segmented test set included 100,000 test images unseen during training.
-
Facebook’s ResNeXt achieved a Top-5 classification error rate of 3.03% by extending the original ResNet [19] architecture.
Object Detection
Object detection, as the name suggests, is the detection of objects or targets contained in an image. ILSVRC 2016 [20] defines object detection as outputting a bounding box and label for a single object or target. This differs from classification/localization tasks, as object detection applies classification and localization techniques to multiple targets in an image instead of focusing on a single main target.

Figure 3: An example of object detection with only the face category. The image shows a face detection example, where the author states that a problem in target recognition is the detection of small objects, detecting smaller faces in the image helps to explore the model’s scale invariance, image resolution, and contextual reasoning capabilities, source: Hu and Ramanan (2016, p. 1)[21].
One of the main trends in the field of object recognition in 2016 was the shift towards faster and more efficient detection systems. This characteristic is particularly evident in methods such as YOLO, SSD, and R-FCN, which tend to share computation across the entire image. Thus, they can be distinguished from more costly sub-network techniques like Fast/Faster R-CNN. These faster and more efficient detection systems are often referred to as “end-to-end training or learning.”
The fundamental principle of this shared computation is to avoid focusing independent algorithms on their respective sub-problems, as this can prevent increases in training time and decreases in network accuracy. In other words, this adaptive end-to-end network typically occurs after initial solutions of sub-network solutions, making it a form of retrospective optimization. However, Fast/Faster R-CNN techniques remain very effective and are still widely used for object detection tasks.
-
SSD: Single Shot MultiBox Detector [22] utilizes a single neural network that encapsulates all necessary computations and eliminates high-cost communication, achieving 75.1% mAP and outperforming the Faster R-CNN model (Liu et al. 2016).
-
One of the most remarkable systems we saw in 2016 was “YOLO9000: Better, Faster, Stronger” [23], which introduced the YOLOv2 and YOLO9000 detection systems [24]. YOLOv2 significantly improved the performance of the YOLO model proposed in 2015 [25], achieving better results at a very high FPS (reaching 90FPS on low-resolution images using the original GTX Titan X). Besides speed, the system’s accuracy on specific target detection datasets surpassed that of Faster R-CNN with ReNet and SSD.
YOLO9000 accomplished joint training for detection and classification, extending its predictive generalization capabilities to unknown detection data, meaning it can detect targets or objects that have never been seen before. The YOLO9000 model provides real-time object detection with over 9,000 categories, bridging the gap between classification and detection datasets. For more detailed information and pre-trained models of this model, please check: http://pjreddie.com/darknet/yolo/.
-
Feature Pyramid Networks for Object Detection [27] proposed by FAIR [28] laboratory can utilize the internal multi-scale, pyramid-like hierarchical structure of deep convolutional networks to construct feature pyramids with marginal extra costs, meaning representations can be more powerful and faster. Lin et al. (2016) achieved top single model results on the COCO [29] dataset. When combined with the basic Faster R-CNN, it will surpass the best results of 2016.
-
R-FCN: Object Detection via Region-based Fully Convolutional Networks [30], another method that avoids applying hundreds of high-cost regional sub-networks on an image, performs fully convolutional and shared computation across the entire image with a region-based detector. “Our testing time per image is only 170ms, making it 2.5 to 20 times faster than Faster R-CNN” (Dai et al., 2016).
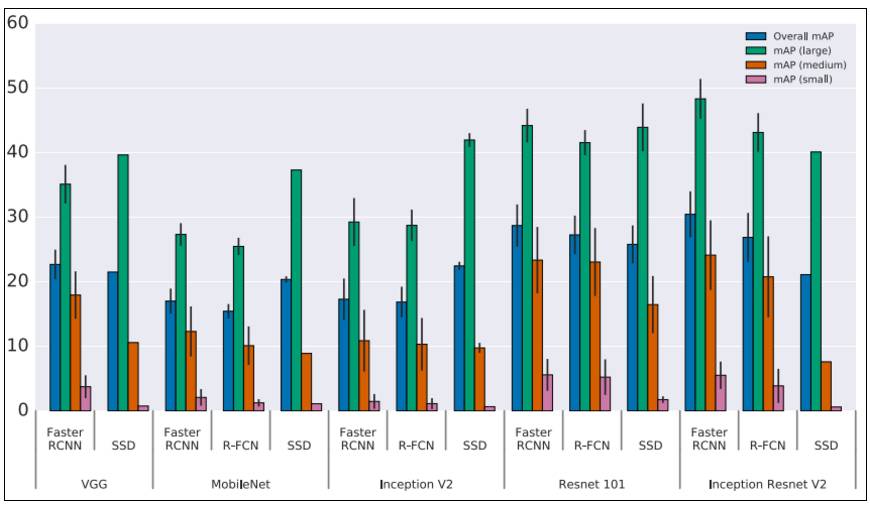
Figure 4: Accuracy trade-offs in object detection, source: Huang et al. (2016, p. 9)[31].
Note: The Y-axis represents average precision (mAP), and the X-axis represents various feature extractors (VGG, MobileNet… Inception ResNet V2) for different meta-architectures. Additionally, mAP small, medium, and large represent the average precision for detecting small, medium, and large targets, respectively. The accuracy is layered by “target size, meta-architecture, and feature extractor,” and the image resolution is fixed at 300. Although Faster R-CNN performs better in the above samples, it is of little value as that meta-architecture is much slower than R-FCN.
The paper by Huang et al. (2016)[32] provides a deep performance comparison of R-FCN, SSD, and Faster R-CNN. Due to issues in comparing machine learning accuracy, a standardized approach was used here. These architectures are considered meta-architectures as they can combine different feature extractors, such as ResNet or Inception.
The authors of the paper studied the trade-offs between accuracy and speed by altering the meta-architecture, feature extractor, and image resolution. For instance, the choice of different feature extractors can cause significant changes in the meta-architecture comparison.
Real-time commercial applications require low-power and efficient object detection methods that can maintain accuracy, especially for autonomous driving applications. SqueezeDet [33] and PVANet [34] described this development trend in their papers.
COCO [36] is another commonly used image dataset. However, it is smaller compared to ImageNet and is often used as an alternative dataset. ImageNet focuses on object recognition, providing a broader context for scene understanding. The organizers host an annual challenge that includes object detection, segmentation, and keypoint annotation. The results of the object detection challenges conducted on ILSVRC [37] and COCO [38] are as follows:
-
ImageNet LSVRC image object detection (DET): CUImage 66% average accuracy, winning in 109 out of 200 categories.
-
ImageNet LSVRC video object detection (VID): NUIST 80.8% average accuracy.
-
ImageNet LSVRC video tracking object detection: CUvideo 55.8% average accuracy.
-
COCO 2016 object detection challenge (bounding box): G-RMI (Google) 41.5% average accuracy (4.2 percentage points higher than the 2015 winner MSRAVC).
From the above results, it is evident that the results on ImageNet indicate that “the results of MSRAVC 2015 set a high standard with the introduction of ResNet.” There has been an improvement in object detection performance across all categories in the entire project. Significant improvements in performance regarding small target instances are detailed in the references” (ImageNet, 2016). [39]
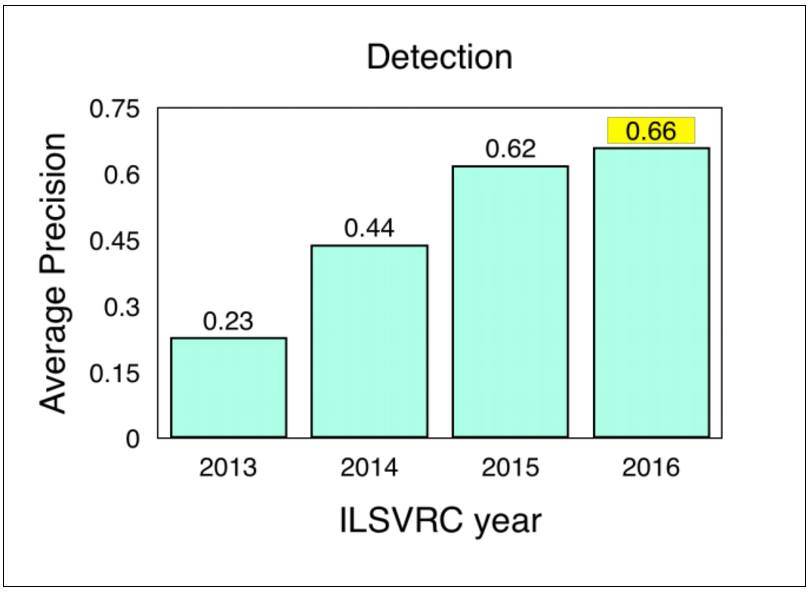
Figure 5: Image object detection results of ILSVRC (2013-2016), source: ImageNet. 2016. [Online] Workshop
Object Tracking
Object tracking refers to the process of tracking one or more specific targets of interest in a given scene, with many applications in video and real-world interactions (usually starting from the initial target detection) and is crucial for autonomous driving.
-
Fully-Convolutional Siamese Networks for Object Tracking [40] combines a Siamese network with a basic tracking algorithm, using an end-to-end training method to achieve the current best, with bounding box display rates exceeding real-time application requirements. This paper constructs a tracking model using traditional online learning methods.
-
Learning to Track at 100 FPS with Deep Regression Networks [41] attempts to improve the shortcomings of online training methods. They built a tracker that learns the universal relationships in target motion, appearance, and direction using a feedforward network, thus enabling effective tracking of new targets without online training. This algorithm achieved the current best results in a standard tracking benchmark while being able to track all targets at 100FPS (Held et al., 2016).
-
Deep Motion Features for Visual Tracking [43] combines handcrafted features, deep appearance features (using CNN), and deep motion features (trained on optical flow images), achieving the current best results. While deep motion features are common in action recognition and video classification, the authors claim this is the first application of them to visual tracking. This paper won the best paper award in the “Computer Vision and Robot Vision” category at ICPR2016.
“This paper demonstrates the impact of deep motion features on detection and tracking frameworks. We further illustrate that handcrafted features, deep RGB, and deep motion features contain complementary information. To our knowledge, this is the first study to propose the fusion of appearance information and deep motion features for visual tracking. Our comprehensive experiments show that the fusion method with deep motion features outperforms methods that solely rely on appearance information.”
-
Virtual Worlds as Proxy for Multi-Object Tracking Analysis [44] addresses the lack of real variability in existing virtual worlds for video tracking benchmarks and datasets. This paper proposes a new method for generating rich, virtual, synthetic, and photorealistic environments from scratch. Additionally, this method overcomes some of the content scarcity issues present in existing datasets. The generated images can be automatically annotated with correct ground truth and allow applications beyond target detection/tracking, such as optical flow.
-
Globally Optimal Object Tracking with Fully Convolutional Networks [45] focuses on addressing target changes and occlusions, which are two fundamental limitations of object tracking. “Our proposed method resolves changes in the appearance of objects or targets using fully convolutional networks while addressing occlusions through dynamic programming” (Lee et al., 2016).
References:
[1] British Machine Vision Association (BMVA). 2016. What is computer vision? [Online] Available at: http://www.bmva.org/visionoverview [Accessed 21/12/2016]
[2] Krizhevsky, A., Sutskever, I. and Hinton, G. E. 2012. ImageNet Classification with Deep Convolutional Neural Networks, NIPS 2012: Neural Information Processing Systems, Lake Tahoe, Nevada. Available: http://www.cs.toronto.edu/~kriz/imagenet_classification_with_deep_convolutional.pdf
[3] Kuhn, T. S. 1962. The Structure of Scientific Revolutions. 4th ed. United States: The University of Chicago Press.
[4] Karpathy, A. 2015. What a Deep Neural Network thinks about your #selfie. [Blog] Andrej Karpathy Blog. Available: http://karpathy.github.io/2015/10/25/selfie/ [Accessed: 21/12/2016]
[5] Quora. 2016. What is a convolutional neural network? [Online] Available: https://www.quora.com/What-is-a-convolutional-neural-network [Accessed: 21/12/2016]
[6] Stanford University. 2016. Convolutional Neural Networks for Visual Recognition. [Online] CS231n. Available: http://cs231n.stanford.edu/ [Accessed 21/12/2016]
[7] Goodfellow et al. 2016. Deep Learning. MIT Press. [Online] http://www.deeplearningbook.org/ [Accessed: 21/12/2016] Note: Chapter 9, Convolutional Networks [Available: http://www.deeplearningbook.org/contents/convnets.html]
[8] Nielsen, M. 2017. Neural Networks and Deep Learning. [Online] EBook. Available: http://neuralnetworksanddeeplearning.com/index.html [Accessed: 06/03/2017].
[9] ImageNet refers to a popular image dataset for Computer Vision. Each year entrants compete in a series of different tasks called the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Available: http://image-net.org/challenges/LSVRC/2016/index
[10] See「What I learned from competing against a ConvNet on ImageNet」by Andrej Karpathy. The blog post details the author’s journey to provide a human benchmark against the ILSVRC 2014 dataset. The error rate was approximately 5.1% versus a then state-of-the-art GoogLeNet classification error of 6.8%. Available: http://karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/
[11] See new datasets later in this piece.
[12] Keras is a popular neural network-based deep learning library: https://keras.io/
[13] Chollet, F. 2016. Information-theoretical label embeddings for large-scale image classification. [Online] arXiv: 1607.05691. Available: arXiv:1607.05691v1
[14] Chollet, F. 2016. Xception: Deep Learning with Depthwise Separable Convolutions. [Online] arXiv:1610.02357. Available: arXiv:1610.02357v2
[15] Places2 dataset, details available: http://places2.csail.mit.edu/. See also new datasets section.
[16] Hikvision. 2016. Hikvision ranked No.1 in Scene Classification at ImageNet 2016 challenge. [Online] Security News Desk. Available: http://www.securitynewsdesk.com/hikvision-ranked-no-1-scene-classification-imagenet-2016-challenge/ [Accessed: 20/03/2017].
[17] See Residual Networks in Part Four of this publication for more details.
[18] Details available under team information Trimps-Soushen from: http://image-net.org/challenges/LSVRC/2016/results
[19] Xie, S., Girshick, R., Dollar, P., Tu, Z. & He, K. 2016. Aggregated Residual Transformations for Deep Neural Networks. [Online] arXiv: 1611.05431. Available: arXiv:1611.05431v1
[20] ImageNet Large Scale Visual Recognition Challenge (2016), Part II, Available: http://image-net.org/challenges/LSVRC/2016/ [Accessed: 22/11/2016]
[21] Hu and Ramanan. 2016. Finding Tiny Faces. [Online] arXiv: 1612.04402. Available: arXiv:1612.04402v1
[22] Liu et al. 2016. SSD: Single Shot MultiBox Detector. [Online] arXiv: 1512.02325v5. Available: arXiv:1512.02325v5
[23] Redmon, J. Farhadi, A. 2016. YOLO9000: Better, Faster, Stronger. [Online] arXiv: 1612.08242v1. Available: arXiv:1612.08242v1
[24] YOLO stands for「You Only Look Once」.
[25] Redmon et al. 2016. You Only Look Once: Unified, Real-Time Object Detection. [Online] arXiv: 1506.02640. Available: arXiv:1506.02640v5
[26]Redmon. 2017. YOLO: Real-Time Object Detection. [Website] pjreddie.com. Available: https://pjreddie.com/darknet/yolo/ [Accessed: 01/03/2017].
[27] Lin et al. 2016. Feature Pyramid Networks for Object Detection. [Online] arXiv: 1612.03144. Available: arXiv:1612.03144v1
[28] Facebook’s Artificial Intelligence Research
[29] Common Objects in Context (COCO) image dataset
[30] Dai et al. 2016. R-FCN: Object Detection via Region-based Fully Convolutional Networks. [Online] arXiv: 1605.06409. Available: arXiv:1605.06409v2
[31] Huang et al. 2016. Speed/accuracy trade-offs for modern convolutional object detectors. [Online] arXiv: 1611.10012. Available: arXiv:1611.10012v1
[32] ibid
[33] Wu et al. 2016. SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving. [Online] arXiv: 1612.01051. Available: arXiv:1612.01051v2
[34] Hong et al. 2016. PVANet: Lightweight Deep Neural Networks for Real-time Object Detection. [Online] arXiv: 1611.08588v2. Available: arXiv:1611.08588v2
[35] DeepGlint Official. 2016. DeepGlint CVPR2016. [Online] Youtube.com. Available: https://www.youtube.com/watch?v=xhp47v5OBXQ [Accessed: 01/03/2017].
[36] COCO – Common Objects in Common. 2016. [Website] Available: http://mscoco.org/ [Accessed: 04/01/2017].
[37] ILSRVC results taken from: ImageNet. 2016. Large Scale Visual Recognition Challenge 2016.
[Website] Object Detection. Available: http://image-net.org/challenges/LSVRC/2016/results [Accessed: 04/01/2017].
[38] COCO Detection Challenge results taken from: COCO – Common Objects in Common. 2016. Detections Leaderboard [Website] mscoco.org. Available: http://mscoco.org/dataset/#detections-leaderboard [Accessed: 05/01/2017].
[39] ImageNet. 2016. [Online] Workshop Presentation, Slide 31. Available: http://image-net.org/challenges/talks/2016/ECCV2016_ilsvrc_coco_detection_segmentation.pdf [Accessed: 06/01/2017].
[40] Bertinetto et al. 2016. Fully-Convolutional Siamese Networks for Object Tracking. [Online] arXiv: 1606.09549. Available: https://arxiv.org/abs/1606.09549v2
[41] Held et al. 2016. Learning to Track at 100 FPS with Deep Regression Networks. [Online] arXiv: 1604.01802. Available: https://arxiv.org/abs/1604.01802v2
[42] David Held. 2016. GOTURN – a neural network tracker. [Online] YouTube.com. Available: https://www.youtube.com/watch?v=kMhwXnLgT_I [Accessed: 03/03/2017].
[43] Gladh et al. 2016. Deep Motion Features for Visual Tracking. [Online] arXiv: 1612.06615. Available: arXiv:1612.06615v1
[44] Gaidon et al. 2016. Virtual Worlds as Proxy for Multi-Object Tracking Analysis. [Online] arXiv: 1605.06457. Available: arXiv:1605.06457v1
[45] Lee et al. 2016. Globally Optimal Object Tracking with Fully Convolutional Networks. [Online] arXiv: 1612.08274. Available: arXiv:1612.08274v1
Original report address: http://www.themtank.org/a-year-in-computer-vision
This article is a translation by Machine Heart, please contact this public account for authorization to reprint.
✄————————————————
Join Machine Heart (Full-time reporter/intern): [email protected]
Submissions or requests for coverage: [email protected]
Advertising & Business cooperation: [email protected]