Originally from Python Artificial Intelligence Frontier
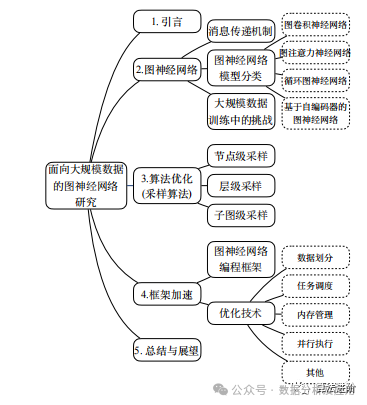
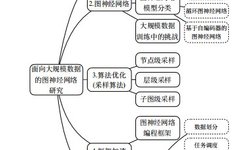
Figure 2 Organization of this article
1 Introduction
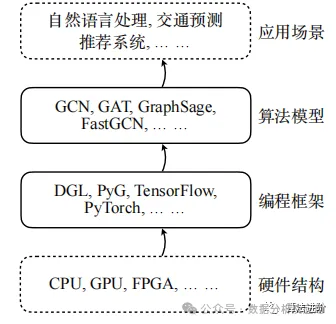
Figure 1 Overall framework of GNN
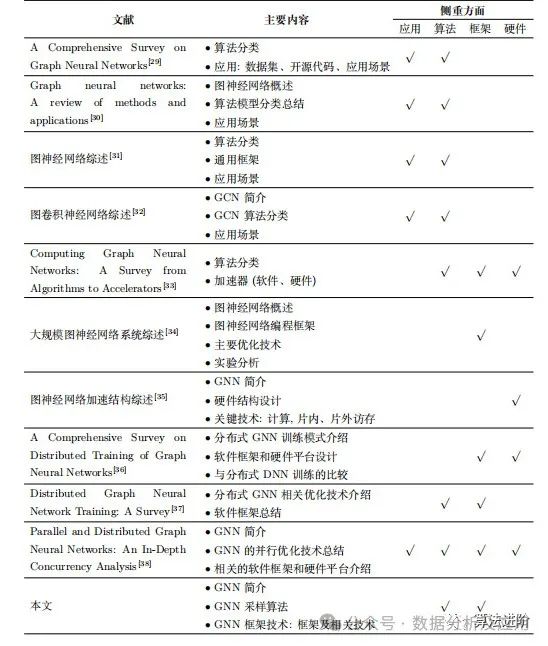
Table 1 Related reviews on Graph Neural Networks
2 Graph Neural Network Models
Table 3 Challenges faced by Graph Neural Networks in large-scale data applications
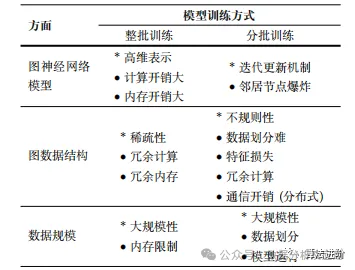
(* Indicates the main reasons for the related challenges)
3 Graph Neural Network Sampling Algorithms
3.1 Node-based Sampling Algorithms
GraphSage performs representation learning through node sampling, optimizing model parameters. It randomly samples a fixed number of neighbors for the target node, uses an aggregation function for feature aggregation, and learns through backpropagation. This method achieves new data representation and regularizes irregular graph structured data for parameter sharing.
PinSage combines random walks and graph convolution operations for large-scale recommendation systems. It constructs a computational graph through node sampling, capturing graph structural features and enhancing the scalability of graph convolutional networks on large-scale data. PinSage employs an importance-based node sampling algorithm, using random walk strategies to assess node importance and perform importance weighting.
VR-GCN is a new sampling algorithm that addresses the parameter sharing issue in large-scale Graph Neural Networks. It samples only two nodes, utilizing historically activated nodes to reduce variance, significantly decreasing the bias and variance of gradient estimation. This method greatly reduces the time and memory overhead of model training.
LGCL structures graph data to meet the requirements of convolution operations, transforming irregular graph structured data into Euclidean space for CNN algorithm optimization. However, this significant feature-based restructuring may compromise the diversity of node features, exacerbating the problem of over-smoothing in node representations.
In summary, GraphSage employs a node-based sampling algorithm, adapting to inductive tasks. PinSage uses an importance-based sampling algorithm with importance weighting. VR-GCN focuses on the convergence of sampling algorithms, reducing bias and variance in gradient estimation. LGCL filters features to reorganize them into new nodes for aggregation. These algorithms each tackle different issues within Graph Neural Networks.
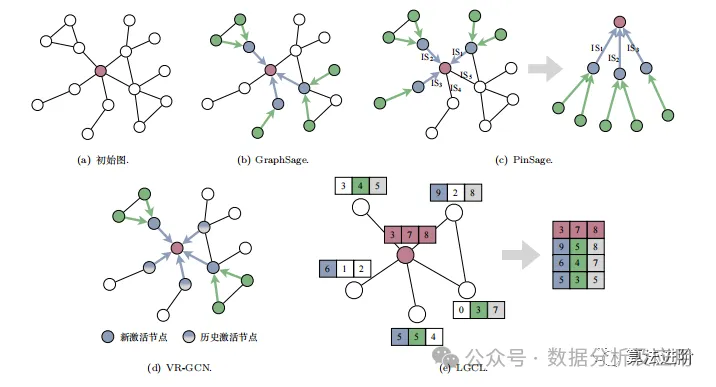
Figure 3 Node-based sampling algorithm
3.2 Layer-based Sampling Algorithms
FastGCN: Transforms graph convolution operations into probability distribution integrals and estimates using Monte Carlo methods, reducing the time and memory consumption of GCN large-scale training. It utilizes layer sampling to prevent neighbor node explosion and combines importance sampling to enhance performance.
AS-GON: Adopts adaptive layer sampling, fixing the number of sampled nodes per layer to prevent neighbor node explosion. It captures second-order similarity through connecting jumps, propagating high-order neighbor features without additional sampling overhead.
LADIES: A new sampling algorithm that constructs bipartite graphs to compute importance scores as sampling probabilities, iteratively constructing the entire computational graph to reduce computational and memory overhead.
In summary: PastGCN avoids neighbor node explosion through layer sampling but faces sparse connections and redundant node issues. AS-GCN ensures convergence and captures second-order correlations. LADIDS mitigates neighbor node explosion but has limited global node reuse.
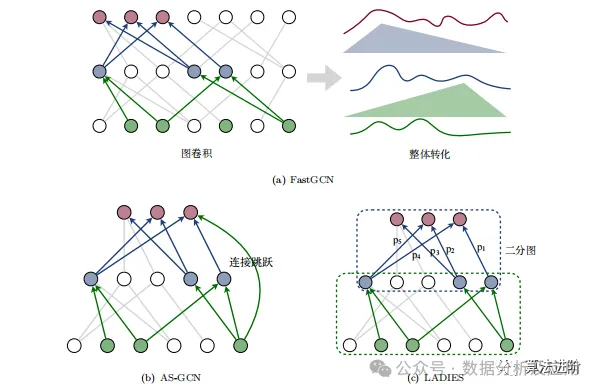
Figure 4 Layer-based sampling algorithm
3.3 Subgraph-based Sampling Algorithms
Cluster-GCN uses subgraph sampling algorithms, dividing nodes into c blocks through the Metis clustering algorithm, transforming the adjacency matrix into diagonal matrices A and B, and then decomposing the GCN function into different clusters, randomly combining blocks to reduce omissions and errors. In batch training, multiple clustered blocks are selected as training data.
RWT is a layer-wise walking training strategy aimed at reducing the time and space overhead of Cluster-GCN. It implements batch training through subgraph sampling, considering randomness and graph structural connectivity, expanding sampling layer by layer and updating subgraphs until a threshold is reached. RWT has been validated effective on GCN and GAT.
GraphSAINT is based on sampling, first sampling subgraphs and then constructing network models, eliminating batch training bias and reducing variance. It estimates the sampling probabilities of nodes and edges, sampling subgraphs in each training batch and constructing complete GON models for training. Normalization is used to eliminate bias, optimizing sampling with random walk strategies. GraphSAINT proposed by Zeng et al. improves accuracy and presents a parallel training framework to enhance program parallelism and reduce communication overhead.
SHADOW-GNN aims to address challenges in large-scale data and the over-smoothing problem. By decoupling the node acceptance region from the depth of the Graph Neural Network, it achieves the expressive power of deep networks while avoiding over-smoothing. It employs a subgraph sampling strategy to form different subgraphs and applies Graph Neural Network models of arbitrary depth on these subgraphs.
In summary: Cluster-GCN improves utilization through node clustering; RWT expands subgraphs layer by layer; GraphSAINT reduces estimation bias and variance; SHADOW-GNN enhances model scalability and mitigates the over-smoothing issue.
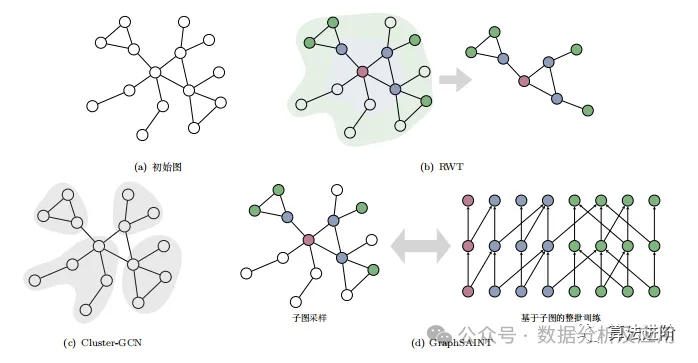
Figure 5 Subgraph-based sampling algorithm
Zeng et al. compared the accuracy performance of four sampling algorithms on node classification tasks across five datasets (Table 4), showing that subgraph-based sampling algorithms performed better across different datasets, with higher micro F1 scores and lower variance. GraphSage’s node classification accuracy on datasets such as Flickr, Reddit, Yelp, and Amazon is close to that of subgraph-based sampling algorithms, but with longer training times.
Table 4 Dataset statistics

Table 5 Node classification performance comparison
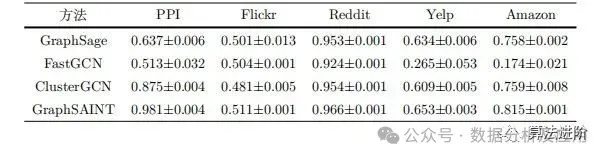
Table 6 Summary of sampling algorithms

4 Graph Neural Network Frameworks
The computation process of Graph Neural Networks involves irregular memory access and complex feature calculations, and traditional frameworks perform poorly in graph computation. To address this issue, researchers have proposed programming frameworks for Graph Neural Networks and explored optimization techniques, laying the groundwork for the operation and optimization of large-scale GNN models.
4.1 Graph Neural Network Programming Frameworks
This section summarizes mainstream programming frameworks such as Deep Graph Library, PyTorch Geometric, Graph-Learn, etc., as shown in Table 7:
Table 7 Graph Neural Network programming frameworks

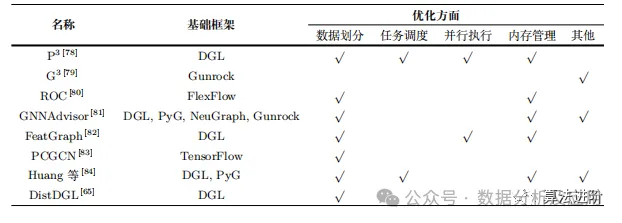
4.2 Optimization Techniques Related to Frameworks
Table 8 Optimization techniques related to Graph Neural Network frameworks
5 Summary and Outlook
This article first introduces four common Graph Neural Network models: Graph Convolutional Networks, Graph Attention Networks, Gated Graph Neural Networks, and Self-Decoder based Graph Neural Networks. It then analyzes the challenges these models face when processing large data and categorizes these challenges. Next, the article summarizes and analyzes existing research from the perspectives of algorithm models and programming frameworks.
First, regarding algorithm models, many optimization efforts have focused on sampling algorithms to address the challenges posed by large data in Graph Neural Network training. Based on the sampling methods, the article categorizes these efforts into three types: node-based sampling, layer-based sampling, and subgraph-based sampling. For each type of sampling algorithm, the article introduces related models and provides detailed analyses. Finally, the article offers a comprehensive summary.
Next, concerning programming frameworks, the article lists mainstream frameworks like DGL and PyG, categorizing their optimization techniques into five types: data partitioning, task scheduling, parallel execution, memory management, and others. It briefly introduces the objectives of each type of optimization technique and lists some specific strategies. Finally, the article also provides a comprehensive summary.
Looking ahead, the article summarizes the progress of Graph Neural Networks in optimizing big data, covering both model optimization and framework acceleration. Next, we will look forward to future work directions from these two aspects, as illustrated in Figure 6.
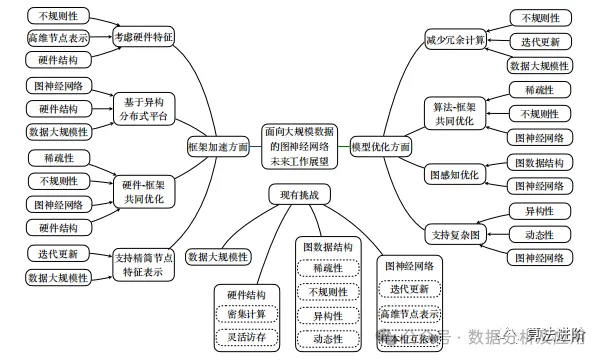
Figure 6 Future work outlook
[Disclaimer] This is a non-commercial reproduction for educational and research purposes, solely for the dissemination of academic news information. Copyright belongs to the original author. If there is any infringement, please contact us immediately, and we will delete it promptly.