Skip to content
[CSDN Editor’s Note] Since its inception over half a century ago, speech recognition has remained somewhat dormant until the significant advancements in deep learning technology in 2009 greatly improved its accuracy. Although it still cannot be applied in unrestricted domains and among unlimited populations, it has provided a convenient and efficient means of communication in most scenarios. This article will review the development history and current status of speech recognition from both technical and industrial perspectives, and analyze some future trends, hoping to help more young technical personnel understand the speech industry and spark their interest in entering this field.
Speech recognition, commonly referred to as automatic speech recognition, abbreviated as ASR, primarily converts the lexical content of human speech into computer-readable input, usually understandable text, and may also be in binary encoding or character sequences. However, what we generally understand as speech recognition is actually the narrow sense of converting speech to text, more appropriately termed speech-to-text recognition (STT), which corresponds to speech synthesis (Text To Speech, TTS).
Speech recognition is a cutting-edge technology that integrates knowledge from multiple disciplines, covering foundational and advanced fields such as mathematics and statistics, acoustics and linguistics, computer science, and artificial intelligence. It is a key component of natural human-computer interaction technology. However, since its inception over half a century ago, speech recognition has not gained widespread recognition in practical applications. This is partly due to the technical flaws of speech recognition, as its accuracy and speed do not meet practical application requirements; on the other hand, it relates to the industry’s overly high expectations for speech recognition. In fact, speech recognition should be complementary to keyboards, mice, or touch screens, rather than a replacement.
Since the rise of deep learning technology in 2009, significant progress has been made. The accuracy and speed of speech recognition depend on the actual application environment, but in quiet environments, with standard accents and common vocabulary scenarios, the speech recognition rate has exceeded 95%, indicating a language recognition capability comparable to that of humans. This is also the reason why speech recognition technology is currently experiencing a surge in development.
With the advancement of technology, speech recognition in scenarios involving accents, dialects, and noise has also reached a usable state. In particular, far-field speech recognition has become one of the most successful technologies in the global consumer electronics field with the rise of smart speakers. As speech interaction provides a more natural, convenient, and efficient form of communication, speech is bound to become one of the primary human-computer interaction interfaces in the future.
Of course, current technologies still have many shortcomings. For example, significant improvements are needed for speech recognition in scenarios involving strong noise, ultra-far fields, strong interference, multiple languages, and large vocabularies. Additionally, multi-speaker speech recognition and offline speech recognition are also current issues that need to be addressed. Although speech recognition cannot yet be applied in unrestricted domains and among unlimited populations, at least we see some hope from practical applications.
This article will review the development history and current status of speech recognition from both technical and industrial perspectives and analyze some future trends, hoping to help more young technical personnel understand the speech industry and spark their interest in entering this field.
The Technical History of Speech Recognition
Modern speech recognition can be traced back to 1952 when Davis and others developed the world’s first experimental system capable of recognizing the pronunciations of 10 English digits, officially starting the process of speech recognition. Speech recognition has developed for over 70 years but can generally be divided into three stages from a technical perspective.
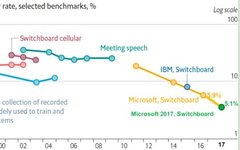
The following figure shows the progress of speech recognition rates on the Switchboard from 1993 to 2017. It can be seen that from 1993 to 2009, speech recognition was in the GMM-HMM era, with slow improvements in recognition rates, especially from 2000 to 2009, when the recognition rate was basically stagnant. In 2009, with the rise of deep learning technology, particularly DNN, the speech recognition framework transitioned to DNN-HMM, marking the entry into the DNN era, where the accuracy of speech recognition saw significant improvement. After 2015, due to the rise of ‘end-to-end’ technology, speech recognition entered a flourishing period, with the industry training deeper and more complex networks, further enhancing the performance of speech recognition using end-to-end technology. By 2017, Microsoft achieved a word error rate of 5.1% on Switchboard, allowing speech recognition accuracy to surpass that of humans for the first time, although this was an experimental result under certain controlled conditions and does not have universal representativeness.
 In the 1970s, speech recognition mainly focused on small vocabulary isolated word recognition, using simple template matching methods. The method involved first extracting features from the speech signal to construct parameter templates, then comparing and matching the test speech with the reference template parameters, labeling the word corresponding to the closest sample as the pronunciation of that speech signal. This method was effective for isolated word recognition but ineffective for large vocabulary and non-specific person continuous speech recognition. Therefore, in the 1980s, there was a significant shift in research thinking from traditional template matching-based techniques to statistical model (HMM)-based methods.
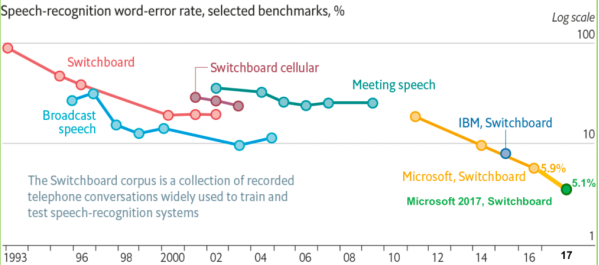
The theoretical foundation of HMM was established in the 1970s by Baum and others, and was subsequently applied to speech recognition by CMU’s Baker and IBM’s Jelinek. The HMM model assumes that a phoneme contains 3 to 5 states, with a relatively stable pronunciation within the same state, and transitions between different states occurring with certain probabilities. The feature distribution of a certain state can be described using a probabilistic model, with GMM being the most widely used model. Thus, in the GMM-HMM framework, HMM describes the short-term stability dynamics of speech, while GMM describes the pronunciation features within each state of HMM.
Based on the GMM-HMM framework, researchers proposed various improvement methods, such as dynamic Bayesian methods that incorporate contextual information, discriminative training methods, adaptive training methods, and HMM/NN hybrid models. These methods have had a profound impact on speech recognition research and laid the groundwork for the next generation of speech recognition technologies. Since the introduction of discriminative training criteria and model adaptation methods for speech recognition acoustic models in the 1990s, the development of speech recognition has been relatively slow, with the error rate line remaining stagnant for a long time.
In the 1970s, speech recognition mainly focused on small vocabulary isolated word recognition, using simple template matching methods. The method involved first extracting features from the speech signal to construct parameter templates, then comparing and matching the test speech with the reference template parameters, labeling the word corresponding to the closest sample as the pronunciation of that speech signal. This method was effective for isolated word recognition but ineffective for large vocabulary and non-specific person continuous speech recognition. Therefore, in the 1980s, there was a significant shift in research thinking from traditional template matching-based techniques to statistical model (HMM)-based methods.
The theoretical foundation of HMM was established in the 1970s by Baum and others, and was subsequently applied to speech recognition by CMU’s Baker and IBM’s Jelinek. The HMM model assumes that a phoneme contains 3 to 5 states, with a relatively stable pronunciation within the same state, and transitions between different states occurring with certain probabilities. The feature distribution of a certain state can be described using a probabilistic model, with GMM being the most widely used model. Thus, in the GMM-HMM framework, HMM describes the short-term stability dynamics of speech, while GMM describes the pronunciation features within each state of HMM.
Based on the GMM-HMM framework, researchers proposed various improvement methods, such as dynamic Bayesian methods that incorporate contextual information, discriminative training methods, adaptive training methods, and HMM/NN hybrid models. These methods have had a profound impact on speech recognition research and laid the groundwork for the next generation of speech recognition technologies. Since the introduction of discriminative training criteria and model adaptation methods for speech recognition acoustic models in the 1990s, the development of speech recognition has been relatively slow, with the error rate line remaining stagnant for a long time.
 In 2006, Hinton proposed the Deep Belief Network (DBN), which led to a resurgence in research on Deep Neural Networks (DNN). In 2009, Hinton applied DNN to acoustic modeling for speech, achieving the best results at the time on TIMIT. By the end of 2011, researchers Yu Dong and Deng Li from Microsoft Research applied DNN technology to large vocabulary continuous speech recognition tasks, significantly reducing the error rate of speech recognition. Thus, speech recognition entered the DNN-HMM era.
DNN-HMM primarily replaces the original GMM model with the DNN model, modeling each state. The benefit of DNN is that it no longer requires assumptions about the distribution of speech data, and by concatenating adjacent speech frames, it incorporates the temporal structure information of speech, significantly improving the classification probabilities of states. Additionally, DNN possesses strong environmental learning capabilities, enhancing robustness against noise and accents.
In 2006, Hinton proposed the Deep Belief Network (DBN), which led to a resurgence in research on Deep Neural Networks (DNN). In 2009, Hinton applied DNN to acoustic modeling for speech, achieving the best results at the time on TIMIT. By the end of 2011, researchers Yu Dong and Deng Li from Microsoft Research applied DNN technology to large vocabulary continuous speech recognition tasks, significantly reducing the error rate of speech recognition. Thus, speech recognition entered the DNN-HMM era.
DNN-HMM primarily replaces the original GMM model with the DNN model, modeling each state. The benefit of DNN is that it no longer requires assumptions about the distribution of speech data, and by concatenating adjacent speech frames, it incorporates the temporal structure information of speech, significantly improving the classification probabilities of states. Additionally, DNN possesses strong environmental learning capabilities, enhancing robustness against noise and accents.
 In simple terms, DNN provides the probability of each state corresponding to a given input feature sequence. Since speech signals are continuous, there are no clear boundaries between phonemes, syllables, and words, and each pronunciation unit is influenced by context. While frame concatenation can increase contextual information, it is still insufficient for speech. The emergence of Recurrent Neural Networks (RNN) allows for the retention of more historical information, which is beneficial for modeling the contextual information of speech signals.
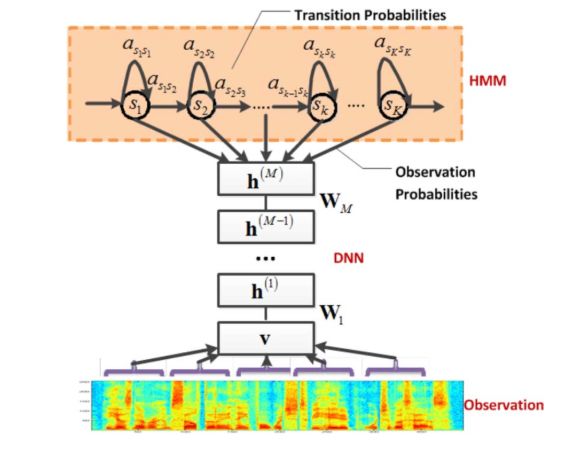
Due to the gradient explosion and gradient vanishing problems associated with simple RNNs, which make them difficult to train and unsuitable for direct application in speech signal modeling, scholars have further explored and developed many RNN structures suitable for speech modeling, the most famous of which is LSTM. LSTM can better control the flow and transmission of information through input gates, output gates, and forget gates, possessing long and short-term memory capabilities. Although the computational complexity of LSTM is higher than that of DNN, its overall performance has a relatively stable improvement of about 20% compared to DNN.
In simple terms, DNN provides the probability of each state corresponding to a given input feature sequence. Since speech signals are continuous, there are no clear boundaries between phonemes, syllables, and words, and each pronunciation unit is influenced by context. While frame concatenation can increase contextual information, it is still insufficient for speech. The emergence of Recurrent Neural Networks (RNN) allows for the retention of more historical information, which is beneficial for modeling the contextual information of speech signals.
Due to the gradient explosion and gradient vanishing problems associated with simple RNNs, which make them difficult to train and unsuitable for direct application in speech signal modeling, scholars have further explored and developed many RNN structures suitable for speech modeling, the most famous of which is LSTM. LSTM can better control the flow and transmission of information through input gates, output gates, and forget gates, possessing long and short-term memory capabilities. Although the computational complexity of LSTM is higher than that of DNN, its overall performance has a relatively stable improvement of about 20% compared to DNN.
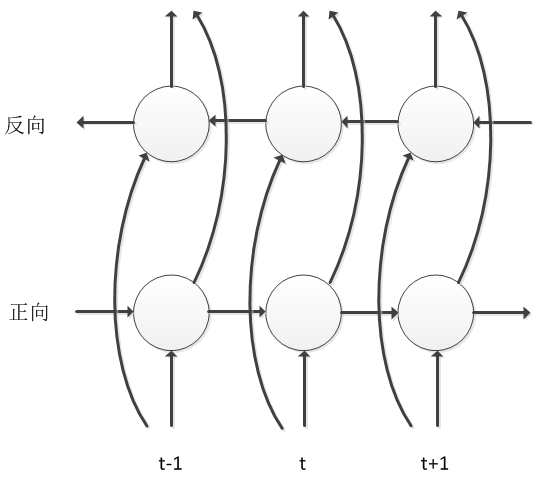
 BLSTM is a further improvement based on LSTM, which considers not only the influence of historical information on the current frame but also the influence of future information on the current frame. Therefore, there are both forward and backward information transmission processes in the network along the time axis, allowing the model to better consider the impact of context on the current speech frame, significantly improving the accuracy of speech state classification. The cost of considering future information in BLSTM is that it requires sentence-level updates, resulting in slower convergence speed during model training and introducing decoding delays. The industry has conducted engineering optimizations and improvements for these issues, and even now, many large companies still use this model structure.
BLSTM is a further improvement based on LSTM, which considers not only the influence of historical information on the current frame but also the influence of future information on the current frame. Therefore, there are both forward and backward information transmission processes in the network along the time axis, allowing the model to better consider the impact of context on the current speech frame, significantly improving the accuracy of speech state classification. The cost of considering future information in BLSTM is that it requires sentence-level updates, resulting in slower convergence speed during model training and introducing decoding delays. The industry has conducted engineering optimizations and improvements for these issues, and even now, many large companies still use this model structure.
 The mainstream model in image recognition is CNN, and the time-frequency diagram of speech signals can also be regarded as an image. Therefore, CNN has also been introduced into speech recognition. To improve speech recognition rates, it is necessary to overcome the diversity faced by speech signals, including the speaker themselves, their environment, and the collection devices. This diversity can be equated to various filters and convolutions with speech signals. CNN essentially designs a series of filters with local attention characteristics and learns the parameters of these filters through training, thereby extracting invariant parts from diverse speech signals. Compared to traditional DNN models, CNN requires fewer parameters for similar performance.
In summary, regarding modeling capabilities, DNN is suitable for mapping features to independent spaces, LSTM possesses long and short-term memory capabilities, and CNN excels at reducing the diversity of speech signals. Therefore, a good speech recognition system is a combination of these networks.
The end-to-end method for speech recognition primarily changes the cost function, but the neural network model structure has not changed significantly. Overall, end-to-end technology solves the problem of the input sequence length being much greater than the output sequence length. End-to-end technology can be divided into two categories: CTC methods and Sequence-to-Sequence methods. In traditional speech recognition DNN-HMM architecture, each input frame corresponds to a label category, and labels need to be iterated repeatedly to ensure more accurate alignment.
The acoustic model sequence using CTC as the loss function does not require pre-alignment of data; it only requires an input sequence and an output sequence for training. CTC focuses on whether the predicted output sequence is close to the true sequence, rather than whether each result in the predicted output sequence is perfectly aligned with the input sequence in terms of time. CTC modeling units are phonemes or characters, thus introducing a Blank. For a segment of speech, CTC finally outputs a sequence of peaks, with the positions of the peaks corresponding to the modeling unit’s label, while other positions are Blank.
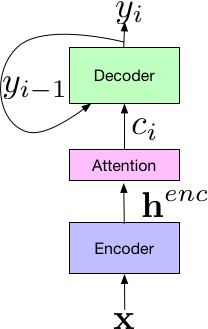
The Sequence-to-Sequence method was originally mainly applied in the field of machine translation. In 2017, Google applied it to the field of speech recognition, achieving very good results, reducing the word error rate to 5.6%. As shown in the figure below, Google proposed a new system framework consisting of three parts: the Encoder component, which is similar to standard acoustic models, with the input being the time-frequency features of speech signals; after a series of neural networks, it maps to high-level features henc, which are then passed to the Attention component that learns the alignment between the input x and the predicted sub-units using henc features. The sub-units can be a phoneme or a character. Finally, the output of the attention module is passed to the Decoder, generating a probability distribution for a series of hypothesized words, similar to traditional language models.
The mainstream model in image recognition is CNN, and the time-frequency diagram of speech signals can also be regarded as an image. Therefore, CNN has also been introduced into speech recognition. To improve speech recognition rates, it is necessary to overcome the diversity faced by speech signals, including the speaker themselves, their environment, and the collection devices. This diversity can be equated to various filters and convolutions with speech signals. CNN essentially designs a series of filters with local attention characteristics and learns the parameters of these filters through training, thereby extracting invariant parts from diverse speech signals. Compared to traditional DNN models, CNN requires fewer parameters for similar performance.
In summary, regarding modeling capabilities, DNN is suitable for mapping features to independent spaces, LSTM possesses long and short-term memory capabilities, and CNN excels at reducing the diversity of speech signals. Therefore, a good speech recognition system is a combination of these networks.
The end-to-end method for speech recognition primarily changes the cost function, but the neural network model structure has not changed significantly. Overall, end-to-end technology solves the problem of the input sequence length being much greater than the output sequence length. End-to-end technology can be divided into two categories: CTC methods and Sequence-to-Sequence methods. In traditional speech recognition DNN-HMM architecture, each input frame corresponds to a label category, and labels need to be iterated repeatedly to ensure more accurate alignment.
The acoustic model sequence using CTC as the loss function does not require pre-alignment of data; it only requires an input sequence and an output sequence for training. CTC focuses on whether the predicted output sequence is close to the true sequence, rather than whether each result in the predicted output sequence is perfectly aligned with the input sequence in terms of time. CTC modeling units are phonemes or characters, thus introducing a Blank. For a segment of speech, CTC finally outputs a sequence of peaks, with the positions of the peaks corresponding to the modeling unit’s label, while other positions are Blank.
The Sequence-to-Sequence method was originally mainly applied in the field of machine translation. In 2017, Google applied it to the field of speech recognition, achieving very good results, reducing the word error rate to 5.6%. As shown in the figure below, Google proposed a new system framework consisting of three parts: the Encoder component, which is similar to standard acoustic models, with the input being the time-frequency features of speech signals; after a series of neural networks, it maps to high-level features henc, which are then passed to the Attention component that learns the alignment between the input x and the predicted sub-units using henc features. The sub-units can be a phoneme or a character. Finally, the output of the attention module is passed to the Decoder, generating a probability distribution for a series of hypothesized words, similar to traditional language models.
 The breakthrough of end-to-end technology eliminates the need for HMM to describe the internal state changes of phonemes, unifying all modules of speech recognition into a neural network model, making speech recognition develop towards a simpler, more efficient, and more accurate direction.
The Current Status of Speech Recognition Technology
Currently, the mainstream speech recognition framework still consists of three parts: the acoustic model, the language model, and the decoder. Some frameworks also include front-end processing and post-processing. With the rise of various deep neural networks and end-to-end technologies, the acoustic model has become a very popular direction in recent years, with industries releasing new acoustic model structures and refreshing recognition records across various databases. Due to the complexity of Chinese speech recognition, domestic research on acoustic models has progressed relatively faster, with the mainstream direction being the integration of deeper and more complex neural network technologies with end-to-end techniques.
In 2018, iFlytek proposed the Deep Fully Sequence Convolutional Neural Network (DFCNN), which models entire speech signals using a large number of convolutions, mainly drawing on the network configuration from image recognition. Each convolutional layer uses small convolution kernels and adds pooling layers after multiple convolutional layers to accumulate a lot of convolutional pooling layers, allowing for more historical information to be captured.
In 2018, Alibaba proposed the LFR-DFSMN (Lower Frame Rate-Deep Feedforward Sequential Memory Networks). This model integrates low frame rate algorithms with the DFSMN algorithm, reducing the speech recognition error rate by 20% compared to the previous generation technology and increasing decoding speed by three times. FSMN effectively models the long-term correlation of speech by adding some learnable memory modules to the hidden layers of FNN. DFSMN avoids the gradient vanishing problem of deep networks through skipping, enabling the training of deeper network structures.
In 2019, Baidu proposed the Streaming Multi-Level Truncated Attention Model (SMLTA), which introduces an attention mechanism based on LSTM and CTC to acquire broader and more hierarchical contextual information. The streaming representation allows direct incremental decoding of speech in small segments; multi-level representation stacks multiple attention models; truncation utilizes the peak information from the CTC model to segment the speech into small pieces, allowing the attention model and decoding to unfold over these small segments. In online speech recognition, this model improves performance by about 15% compared to Baidu’s previous Deep Peak2 model.
The open-source speech recognition framework Kaldi is a cornerstone of the industry. Daniel Povey, the author of Kaldi, has long advocated the Chain model. This model is a technique similar to CTC, with modeling units that are coarser than traditional states, consisting of only two states: one state is CD Phone, and the other is the blank state of CD Phone. The training method employs Lattice-Free MMI training. This model structure can decode at a lower frame rate, with a decoding frame rate one-third of that of traditional neural network acoustic models, while achieving significant improvements in accuracy compared to traditional models.
Far-field speech recognition technology primarily addresses human-computer task dialogue and service issues within comfortable distances in real-world scenarios, emerging as a technology after 2015. As far-field speech recognition resolves recognition issues in complex environments, it has been widely applied in real-world scenarios such as smart homes, smart cars, smart meetings, and smart security. Currently, domestic far-field speech recognition technology frameworks focus on front-end signal processing and back-end speech recognition, utilizing microphone arrays for dereverberation and beamforming to clarify speech before sending it to the back-end speech recognition engine for recognition.
The other two technical components of speech recognition, the language model and the decoder, currently do not show significant technological changes. The mainstream language model is still based on traditional N-Gram methods, although there is research on neural network language models, they are mainly used for post-processing error correction in practical applications. The core metric for decoders is speed, with most industries employing static decoding methods, constructing the acoustic model and language model into a WFST network that includes all possible paths, with decoding being the search process within that space. Due to the maturity of this theory, the focus of both academia and industry is now more on engineering optimization.
Trends in Speech Recognition Technology
Speech recognition is primarily trending towards far-field and integration development, but there are still many challenges in far-field reliability that have not been overcome, such as multi-turn interactions, multi-speaker noise, etc., as well as pressing needs for technologies like voice separation. New technologies should thoroughly address these issues, enabling machines to hear far beyond human perceptual capabilities. This requires not only algorithmic advancements but also a collective technological upgrade across the entire industry chain, including more advanced sensors and more powerful chips.
From the perspective of far-field speech recognition technology, there are still many challenges, including:
(1) Echo cancellation technology. Due to the non-linear distortion of speakers, it is challenging to eliminate echoes purely through signal processing methods, which hinders the promotion of speech interaction systems. Existing deep learning-based echo cancellation technologies have not considered phase information, directly calculating the gain on various frequency bands. Whether deep learning can fit non-linear distortions while combining signal processing methods may be a promising direction.
(2) Speech recognition under noise still needs breakthroughs. Signal processing excels at handling linear problems, while deep learning is good at addressing non-linear issues. Since real-world problems are invariably a combination of linear and non-linear factors, a fusion of both approaches is likely necessary to better solve the problem of speech recognition under noise.
(3) The commonality of the above two issues is that current deep learning has only utilized the energy information of various frequency bands of speech signals, neglecting the phase information of speech signals, especially for multi-channel scenarios. How to enable deep learning to better utilize phase information could be a future direction.
(4) Additionally, under conditions of limited data, how to obtain a good acoustic model through transfer learning is also a hot research direction. For example, in dialect recognition, if there is a good Mandarin acoustic model, how to utilize a small amount of dialect data to obtain a good dialect acoustic model. If this can be achieved, it would greatly expand the application scope of speech recognition. Some progress has been made in this area, but more training techniques are still needed, and there is a certain distance to the ultimate goal.
(5) The goal of speech recognition is to enable machines to understand human language, so converting speech to text is not the final objective. How to combine speech recognition with semantic understanding may be a more important direction in the future. LSTM in speech recognition has already considered the historical moment information of speech, but semantic understanding requires more historical information to be useful. Therefore, how to convey more contextual conversation information to the speech recognition engine is a challenge.
(6) Enabling machines to understand human language is not sufficient with sound information alone; various physical sensing methods such as sound, light, electricity, heat, and magnetism must be integrated. Only then can machines perceive the real information of the world, which is a prerequisite for machines to learn human knowledge. Moreover, machines must surpass human senses, being able to see worlds invisible to humans and hear sounds inaudible to humans.
The Industrial History of Speech Recognition
In the more than half a century of industrial history of speech recognition, there have been three key milestones, two related to technology and one related to application. The first key milestone was a doctoral thesis in 1988 that developed the first speech recognition system based on Hidden Markov Models (HMM) — Sphinx, developed by the now-famous investor Kaifu Lee.
From 1986 to 2010, although the mixed Gaussian model continuously improved its performance and was applied to speech recognition, indeed enhancing its effectiveness, speech recognition had encountered a technical ceiling, with accuracy rates difficult to exceed 90%. Many may remember that around 1998, both IBM and Microsoft launched software related to speech recognition, but ultimately did not succeed.
The second key milestone was the systematic application of deep learning in the field of speech recognition in 2009. This led to a significant increase in accuracy, ultimately exceeding 90% and approaching 98% in standard environments. Interestingly, despite the technological breakthroughs and the emergence of related products such as Siri and Google Assistant, the actual achievements of these products fell short compared to the attention they garnered. When Siri was first launched, then-Google CEO Eric Schmidt proclaimed it would pose a fundamental threat to Google’s search business, but in reality, such a fundamental threat only became a concrete entity with the advent of Amazon Echo.
The third key milestone was the emergence of Amazon Echo. From the perspective of speech recognition and natural language understanding technology and functionality, this product did not fundamentally change compared to Siri and others; the core change was transforming near-field speech interaction into far-field speech interaction. Echo was officially launched in June 2015, and by 2017, sales had exceeded ten million. Meanwhile, Alexa, which plays a role similar to Siri on Echo, gradually formed an ecosystem, with its backend third-party skills surpassing 10,000. By achieving a breakthrough from near-field to far-field during its launch, Amazon transformed from a laggard in this field to an industry leader.
However, since the large-scale implementation of far-field speech technology, competition in the speech recognition industry has begun to shift from research and development to applications. R&D focuses on which algorithms have advantages in standard environments, while applications compare which technologies deliver superior user experiences in real-world scenarios. Once the competition shifts to user experiences in real-world scenarios, speech recognition loses its independent value, existing more as a segment of product experience.
Thus, by 2019, speech recognition seemed to enter a relatively calm period, with major global industry participants, including Amazon, Google, Microsoft, Apple, Baidu, iFlytek, Alibaba, Tencent, Cloudwalk, Sobot, and Voice AI, reflecting on their positioning and next strategies after a period of rapid development.
The flagship product in the speech track — smart speakers — appeared before the public in a leap forward manner. Before 2016, players in the smart speaker market viewed this product as merely Amazon’s Echo, which had similar functions to Siri. The early mover iFlytek’s Dingdong speaker had a poor launch, further heightening the wait-and-see attitude of others. The turning point that led many players from observation to active participation was the gradually revealed sales of Echo. By the end of 2016, Echo’s nearly ten million sales in the U.S. shocked the world. This was a peak never reached by smart devices before; aside from the Apple Watch and fitness bands, products like thermostats and cameras achieving over one million sales were already remarkable. Such sales and the AI attributes of smart speakers prompted major domestic players to simultaneously change their attitudes and actively develop their smart speakers in the latter half of 2016.
Looking back at the entire development process, 2019 marks a clear dividing line. Before this, the entire industry experienced rapid growth, but after 2019, it began to focus on penetrating and refining details. The focal point of attention shifted from mere technical metrics to a more general and pure business perspective of what value a new interaction method could bring. The relationship between technology and products and whether they need to be combined with specific images, such as character imagery; how process automation should integrate with speech; how this technology can enhance experiences in hotel scenarios, etc., will all present themselves to practitioners one by one. At this time, the industry’s protagonists will also transition from product providers to platform providers, as the depth of AIoT is so great that no single company can create all products across the board.
Trends in the Speech Recognition Industry
As the demand for speech technology blooms in various sectors, the speed of industry development is conversely limited by the supply capacity of platform service providers. Looking beyond specific cases, the essence of the next step in the industry’s development is whether the input-output ratio at each point reaches a universally accepted threshold.
The closer it gets to this threshold, the more the industry approaches a snowballing development critical point; otherwise, the overall growth rate will remain relatively flat. Whether in homes, hotels, finance, education, or other scenarios, if problem-solving involves very high investments and long cycles, the party bearing the cost will hesitate, as this equates to excessively high trial-and-error costs. If, after investment, no perceivable new experiences or sales boosts are achieved, the cost-bearing party will also hesitate, which evidently affects the judgment of whether it is worthwhile to engage. Ultimately, both of these issues must be resolved by platform providers, as product providers or solution providers are powerless to do so, given the foundational technical characteristics of intelligent voice interaction.
From a core technology perspective, the entire speech interaction chain comprises five key technologies: wake-up, microphone arrays, speech recognition, natural language processing, and speech synthesis. Other technologies, such as voiceprint recognition and crying detection, have relatively weak general applicability but appear in different scenarios and may become critical in specific contexts. Although the associated technologies seem relatively complex, switching to a business perspective reveals that there remains a significant distance to creating a product with an excellent experience.
All voice interaction products are end-to-end integrated products. If every manufacturer develops products based on these foundational technologies, each must establish its own cloud service to ensure response speed and adapt to the chosen hardware platform while integrating specific content (such as music, audiobooks). This is unacceptable from the perspective of product providers or solution vendors. This will inevitably give rise to corresponding platform service providers, who must simultaneously resolve technical, content integration, and engineering detail issues to achieve the goals of low trial-and-error costs and sufficiently good experiences.
Platform services do not need to reinvent the wheel; the premise of platform services is to have an operating system that can mask product differences. This is a characteristic of AI+IoT and has its references. Over the past decade, Amazon has simultaneously undertaken two tasks: continuously launching products aimed at end users, such as Echo and Echo Show, and platformizing the Alexa system built into all products, opening SDKs and debugging release platforms for device and skill endpoints. Although Google Assistant claims to have superior single-point technology, Alexa is undoubtedly the leading system platform based on various outcomes; unfortunately, Alexa does not support Chinese or corresponding backend services.
Domestically, there is a lack of a dominant system platform provider like Amazon. Current platform providers fall into two camps: one represented by traditional internet or listed companies such as Baidu, Alibaba, iFlytek, Xiaomi, and Tencent; the other represented by emerging AI companies like Voice AI. Emerging AI companies, compared to traditional companies, have lighter historical burdens in terms of products and services, allowing them to promote more future-oriented and distinctive foundational services; for instance, emerging companies tend to achieve greater compatibility, which is very beneficial for a product suite covering both domestic and international markets.
Similar to past Android developments, platform providers in voice interaction face even greater challenges, and their development processes may be more tortuous. The concept of operating systems frequently referenced in the past is being imbued with new meanings in the context of intelligent voice interaction. It is increasingly being divided into two different but closely integrated parts.
The past Linux and its various variants played the role of functional operating systems, while new systems represented by Alexa serve as intelligent operating systems. The former abstracts and manages hardware and resources, while the latter applies these hardware and resources. Only by combining the two can a perceivable experience for the end user be delivered. Functional operating systems and intelligent operating systems are destined to have a one-to-many relationship, with significant disparities in sensor (depth cameras, radar, etc.) and display (screened, non-screened, small screen, large screen, etc.) characteristics among different AIoT hardware products, leading to the continuous differentiation of functional systems (which can correspond to the differentiation of Linux). This also implies that a single intelligent system must simultaneously address the dual responsibilities of adapting to functional systems and supporting various backend content and scenarios.
Operationally, these two aspects have vastly different attributes. Solving the former requires participation in the traditional product manufacturing chain, while addressing the latter resembles the role of application store developers. This entails immense challenges and opportunities. In the past, the development of functional operating systems saw domestic programmers primarily as users, but for intelligent operating systems, while references can be drawn from others, a complete system must be built from scratch.
As platform service providers increasingly resolve issues on both sides, the fundamental computing model will gradually change, and people’s data consumption patterns will differ from today. Personal computing devices (currently mainly mobile phones, laptops, and tablets) will further diversify based on different scenarios, such as in cars, homes, hotels, workplaces, on the go, and during business transactions. However, while diversifying, the underlying services will be unified; individuals can freely migrate devices based on scenarios, with the underlying services optimized for different contexts but unified regarding personal preferences.
The interface between humans and the digital world is increasingly unified around specific product forms (like mobile phones), but with the emergence of intelligent systems, this unity will increasingly center around the system itself. As a result, this will lead to a continuous deepening of dataization, bringing us closer to a fully data-driven world.
The breakthrough of end-to-end technology eliminates the need for HMM to describe the internal state changes of phonemes, unifying all modules of speech recognition into a neural network model, making speech recognition develop towards a simpler, more efficient, and more accurate direction.
The Current Status of Speech Recognition Technology
Currently, the mainstream speech recognition framework still consists of three parts: the acoustic model, the language model, and the decoder. Some frameworks also include front-end processing and post-processing. With the rise of various deep neural networks and end-to-end technologies, the acoustic model has become a very popular direction in recent years, with industries releasing new acoustic model structures and refreshing recognition records across various databases. Due to the complexity of Chinese speech recognition, domestic research on acoustic models has progressed relatively faster, with the mainstream direction being the integration of deeper and more complex neural network technologies with end-to-end techniques.
In 2018, iFlytek proposed the Deep Fully Sequence Convolutional Neural Network (DFCNN), which models entire speech signals using a large number of convolutions, mainly drawing on the network configuration from image recognition. Each convolutional layer uses small convolution kernels and adds pooling layers after multiple convolutional layers to accumulate a lot of convolutional pooling layers, allowing for more historical information to be captured.
In 2018, Alibaba proposed the LFR-DFSMN (Lower Frame Rate-Deep Feedforward Sequential Memory Networks). This model integrates low frame rate algorithms with the DFSMN algorithm, reducing the speech recognition error rate by 20% compared to the previous generation technology and increasing decoding speed by three times. FSMN effectively models the long-term correlation of speech by adding some learnable memory modules to the hidden layers of FNN. DFSMN avoids the gradient vanishing problem of deep networks through skipping, enabling the training of deeper network structures.
In 2019, Baidu proposed the Streaming Multi-Level Truncated Attention Model (SMLTA), which introduces an attention mechanism based on LSTM and CTC to acquire broader and more hierarchical contextual information. The streaming representation allows direct incremental decoding of speech in small segments; multi-level representation stacks multiple attention models; truncation utilizes the peak information from the CTC model to segment the speech into small pieces, allowing the attention model and decoding to unfold over these small segments. In online speech recognition, this model improves performance by about 15% compared to Baidu’s previous Deep Peak2 model.
The open-source speech recognition framework Kaldi is a cornerstone of the industry. Daniel Povey, the author of Kaldi, has long advocated the Chain model. This model is a technique similar to CTC, with modeling units that are coarser than traditional states, consisting of only two states: one state is CD Phone, and the other is the blank state of CD Phone. The training method employs Lattice-Free MMI training. This model structure can decode at a lower frame rate, with a decoding frame rate one-third of that of traditional neural network acoustic models, while achieving significant improvements in accuracy compared to traditional models.
Far-field speech recognition technology primarily addresses human-computer task dialogue and service issues within comfortable distances in real-world scenarios, emerging as a technology after 2015. As far-field speech recognition resolves recognition issues in complex environments, it has been widely applied in real-world scenarios such as smart homes, smart cars, smart meetings, and smart security. Currently, domestic far-field speech recognition technology frameworks focus on front-end signal processing and back-end speech recognition, utilizing microphone arrays for dereverberation and beamforming to clarify speech before sending it to the back-end speech recognition engine for recognition.
The other two technical components of speech recognition, the language model and the decoder, currently do not show significant technological changes. The mainstream language model is still based on traditional N-Gram methods, although there is research on neural network language models, they are mainly used for post-processing error correction in practical applications. The core metric for decoders is speed, with most industries employing static decoding methods, constructing the acoustic model and language model into a WFST network that includes all possible paths, with decoding being the search process within that space. Due to the maturity of this theory, the focus of both academia and industry is now more on engineering optimization.
Trends in Speech Recognition Technology
Speech recognition is primarily trending towards far-field and integration development, but there are still many challenges in far-field reliability that have not been overcome, such as multi-turn interactions, multi-speaker noise, etc., as well as pressing needs for technologies like voice separation. New technologies should thoroughly address these issues, enabling machines to hear far beyond human perceptual capabilities. This requires not only algorithmic advancements but also a collective technological upgrade across the entire industry chain, including more advanced sensors and more powerful chips.
From the perspective of far-field speech recognition technology, there are still many challenges, including:
(1) Echo cancellation technology. Due to the non-linear distortion of speakers, it is challenging to eliminate echoes purely through signal processing methods, which hinders the promotion of speech interaction systems. Existing deep learning-based echo cancellation technologies have not considered phase information, directly calculating the gain on various frequency bands. Whether deep learning can fit non-linear distortions while combining signal processing methods may be a promising direction.
(2) Speech recognition under noise still needs breakthroughs. Signal processing excels at handling linear problems, while deep learning is good at addressing non-linear issues. Since real-world problems are invariably a combination of linear and non-linear factors, a fusion of both approaches is likely necessary to better solve the problem of speech recognition under noise.
(3) The commonality of the above two issues is that current deep learning has only utilized the energy information of various frequency bands of speech signals, neglecting the phase information of speech signals, especially for multi-channel scenarios. How to enable deep learning to better utilize phase information could be a future direction.
(4) Additionally, under conditions of limited data, how to obtain a good acoustic model through transfer learning is also a hot research direction. For example, in dialect recognition, if there is a good Mandarin acoustic model, how to utilize a small amount of dialect data to obtain a good dialect acoustic model. If this can be achieved, it would greatly expand the application scope of speech recognition. Some progress has been made in this area, but more training techniques are still needed, and there is a certain distance to the ultimate goal.
(5) The goal of speech recognition is to enable machines to understand human language, so converting speech to text is not the final objective. How to combine speech recognition with semantic understanding may be a more important direction in the future. LSTM in speech recognition has already considered the historical moment information of speech, but semantic understanding requires more historical information to be useful. Therefore, how to convey more contextual conversation information to the speech recognition engine is a challenge.
(6) Enabling machines to understand human language is not sufficient with sound information alone; various physical sensing methods such as sound, light, electricity, heat, and magnetism must be integrated. Only then can machines perceive the real information of the world, which is a prerequisite for machines to learn human knowledge. Moreover, machines must surpass human senses, being able to see worlds invisible to humans and hear sounds inaudible to humans.
The Industrial History of Speech Recognition
In the more than half a century of industrial history of speech recognition, there have been three key milestones, two related to technology and one related to application. The first key milestone was a doctoral thesis in 1988 that developed the first speech recognition system based on Hidden Markov Models (HMM) — Sphinx, developed by the now-famous investor Kaifu Lee.
From 1986 to 2010, although the mixed Gaussian model continuously improved its performance and was applied to speech recognition, indeed enhancing its effectiveness, speech recognition had encountered a technical ceiling, with accuracy rates difficult to exceed 90%. Many may remember that around 1998, both IBM and Microsoft launched software related to speech recognition, but ultimately did not succeed.
The second key milestone was the systematic application of deep learning in the field of speech recognition in 2009. This led to a significant increase in accuracy, ultimately exceeding 90% and approaching 98% in standard environments. Interestingly, despite the technological breakthroughs and the emergence of related products such as Siri and Google Assistant, the actual achievements of these products fell short compared to the attention they garnered. When Siri was first launched, then-Google CEO Eric Schmidt proclaimed it would pose a fundamental threat to Google’s search business, but in reality, such a fundamental threat only became a concrete entity with the advent of Amazon Echo.
The third key milestone was the emergence of Amazon Echo. From the perspective of speech recognition and natural language understanding technology and functionality, this product did not fundamentally change compared to Siri and others; the core change was transforming near-field speech interaction into far-field speech interaction. Echo was officially launched in June 2015, and by 2017, sales had exceeded ten million. Meanwhile, Alexa, which plays a role similar to Siri on Echo, gradually formed an ecosystem, with its backend third-party skills surpassing 10,000. By achieving a breakthrough from near-field to far-field during its launch, Amazon transformed from a laggard in this field to an industry leader.
However, since the large-scale implementation of far-field speech technology, competition in the speech recognition industry has begun to shift from research and development to applications. R&D focuses on which algorithms have advantages in standard environments, while applications compare which technologies deliver superior user experiences in real-world scenarios. Once the competition shifts to user experiences in real-world scenarios, speech recognition loses its independent value, existing more as a segment of product experience.
Thus, by 2019, speech recognition seemed to enter a relatively calm period, with major global industry participants, including Amazon, Google, Microsoft, Apple, Baidu, iFlytek, Alibaba, Tencent, Cloudwalk, Sobot, and Voice AI, reflecting on their positioning and next strategies after a period of rapid development.
The flagship product in the speech track — smart speakers — appeared before the public in a leap forward manner. Before 2016, players in the smart speaker market viewed this product as merely Amazon’s Echo, which had similar functions to Siri. The early mover iFlytek’s Dingdong speaker had a poor launch, further heightening the wait-and-see attitude of others. The turning point that led many players from observation to active participation was the gradually revealed sales of Echo. By the end of 2016, Echo’s nearly ten million sales in the U.S. shocked the world. This was a peak never reached by smart devices before; aside from the Apple Watch and fitness bands, products like thermostats and cameras achieving over one million sales were already remarkable. Such sales and the AI attributes of smart speakers prompted major domestic players to simultaneously change their attitudes and actively develop their smart speakers in the latter half of 2016.
Looking back at the entire development process, 2019 marks a clear dividing line. Before this, the entire industry experienced rapid growth, but after 2019, it began to focus on penetrating and refining details. The focal point of attention shifted from mere technical metrics to a more general and pure business perspective of what value a new interaction method could bring. The relationship between technology and products and whether they need to be combined with specific images, such as character imagery; how process automation should integrate with speech; how this technology can enhance experiences in hotel scenarios, etc., will all present themselves to practitioners one by one. At this time, the industry’s protagonists will also transition from product providers to platform providers, as the depth of AIoT is so great that no single company can create all products across the board.
Trends in the Speech Recognition Industry
As the demand for speech technology blooms in various sectors, the speed of industry development is conversely limited by the supply capacity of platform service providers. Looking beyond specific cases, the essence of the next step in the industry’s development is whether the input-output ratio at each point reaches a universally accepted threshold.
The closer it gets to this threshold, the more the industry approaches a snowballing development critical point; otherwise, the overall growth rate will remain relatively flat. Whether in homes, hotels, finance, education, or other scenarios, if problem-solving involves very high investments and long cycles, the party bearing the cost will hesitate, as this equates to excessively high trial-and-error costs. If, after investment, no perceivable new experiences or sales boosts are achieved, the cost-bearing party will also hesitate, which evidently affects the judgment of whether it is worthwhile to engage. Ultimately, both of these issues must be resolved by platform providers, as product providers or solution providers are powerless to do so, given the foundational technical characteristics of intelligent voice interaction.
From a core technology perspective, the entire speech interaction chain comprises five key technologies: wake-up, microphone arrays, speech recognition, natural language processing, and speech synthesis. Other technologies, such as voiceprint recognition and crying detection, have relatively weak general applicability but appear in different scenarios and may become critical in specific contexts. Although the associated technologies seem relatively complex, switching to a business perspective reveals that there remains a significant distance to creating a product with an excellent experience.
All voice interaction products are end-to-end integrated products. If every manufacturer develops products based on these foundational technologies, each must establish its own cloud service to ensure response speed and adapt to the chosen hardware platform while integrating specific content (such as music, audiobooks). This is unacceptable from the perspective of product providers or solution vendors. This will inevitably give rise to corresponding platform service providers, who must simultaneously resolve technical, content integration, and engineering detail issues to achieve the goals of low trial-and-error costs and sufficiently good experiences.
Platform services do not need to reinvent the wheel; the premise of platform services is to have an operating system that can mask product differences. This is a characteristic of AI+IoT and has its references. Over the past decade, Amazon has simultaneously undertaken two tasks: continuously launching products aimed at end users, such as Echo and Echo Show, and platformizing the Alexa system built into all products, opening SDKs and debugging release platforms for device and skill endpoints. Although Google Assistant claims to have superior single-point technology, Alexa is undoubtedly the leading system platform based on various outcomes; unfortunately, Alexa does not support Chinese or corresponding backend services.
Domestically, there is a lack of a dominant system platform provider like Amazon. Current platform providers fall into two camps: one represented by traditional internet or listed companies such as Baidu, Alibaba, iFlytek, Xiaomi, and Tencent; the other represented by emerging AI companies like Voice AI. Emerging AI companies, compared to traditional companies, have lighter historical burdens in terms of products and services, allowing them to promote more future-oriented and distinctive foundational services; for instance, emerging companies tend to achieve greater compatibility, which is very beneficial for a product suite covering both domestic and international markets.
Similar to past Android developments, platform providers in voice interaction face even greater challenges, and their development processes may be more tortuous. The concept of operating systems frequently referenced in the past is being imbued with new meanings in the context of intelligent voice interaction. It is increasingly being divided into two different but closely integrated parts.
The past Linux and its various variants played the role of functional operating systems, while new systems represented by Alexa serve as intelligent operating systems. The former abstracts and manages hardware and resources, while the latter applies these hardware and resources. Only by combining the two can a perceivable experience for the end user be delivered. Functional operating systems and intelligent operating systems are destined to have a one-to-many relationship, with significant disparities in sensor (depth cameras, radar, etc.) and display (screened, non-screened, small screen, large screen, etc.) characteristics among different AIoT hardware products, leading to the continuous differentiation of functional systems (which can correspond to the differentiation of Linux). This also implies that a single intelligent system must simultaneously address the dual responsibilities of adapting to functional systems and supporting various backend content and scenarios.
Operationally, these two aspects have vastly different attributes. Solving the former requires participation in the traditional product manufacturing chain, while addressing the latter resembles the role of application store developers. This entails immense challenges and opportunities. In the past, the development of functional operating systems saw domestic programmers primarily as users, but for intelligent operating systems, while references can be drawn from others, a complete system must be built from scratch.
As platform service providers increasingly resolve issues on both sides, the fundamental computing model will gradually change, and people’s data consumption patterns will differ from today. Personal computing devices (currently mainly mobile phones, laptops, and tablets) will further diversify based on different scenarios, such as in cars, homes, hotels, workplaces, on the go, and during business transactions. However, while diversifying, the underlying services will be unified; individuals can freely migrate devices based on scenarios, with the underlying services optimized for different contexts but unified regarding personal preferences.
The interface between humans and the digital world is increasingly unified around specific product forms (like mobile phones), but with the emergence of intelligent systems, this unity will increasingly center around the system itself. As a result, this will lead to a continuous deepening of dataization, bringing us closer to a fully data-driven world.
 From the perspectives of technological progress and industrial development, although speech recognition still cannot solve the general recognition problem across unrestricted scenarios and populations, it has been widely applied in various real-world scenarios and validated at scale. Furthermore, a positive iterative effect has formed between technology and industry; the more real-world scenarios are implemented, the more real data is collected, and the more accurately user needs are identified, which helps speech recognition technology advance rapidly and essentially meet industrial demands, solving many practical issues. This is also the most evident advantage of speech recognition compared to other AI technologies.
However, we must also recognize that the connotation of speech recognition must continuously expand. Narrow speech recognition must evolve into broad speech recognition, aiming to enable machines to understand human language. This will elevate speech recognition research to a higher dimension. We believe that the integration of multiple technologies, disciplines, and sensors will be the mainstream trend in the future of artificial intelligence development. Under this trend, many future issues need to be explored, such as how the relationship between keyboards, mice, touch screens, and speech interaction changes; whether search, e-commerce, and social interactions will be restructured; whether hardware will reverse its position to become more important than software; and how the relationships among sensors, chips, operating systems, products, and content vendors in the industry chain will evolve.
This article has received guidance from numerous experts in the field of speech recognition and has cited some reference materials and images, for which we express our gratitude. Any shortcomings in this article are welcome to be criticized and corrected.
Chen Xiaoliang, Founder, Chairman, and CEO of Voice AI Technology; Feng Dahang, Co-founder and CTO of Voice AI Technology; Li Zhiyong, Strategic Partner and CSO of Voice AI Technology.
Reprinted from AI Technology Camp
From the perspectives of technological progress and industrial development, although speech recognition still cannot solve the general recognition problem across unrestricted scenarios and populations, it has been widely applied in various real-world scenarios and validated at scale. Furthermore, a positive iterative effect has formed between technology and industry; the more real-world scenarios are implemented, the more real data is collected, and the more accurately user needs are identified, which helps speech recognition technology advance rapidly and essentially meet industrial demands, solving many practical issues. This is also the most evident advantage of speech recognition compared to other AI technologies.
However, we must also recognize that the connotation of speech recognition must continuously expand. Narrow speech recognition must evolve into broad speech recognition, aiming to enable machines to understand human language. This will elevate speech recognition research to a higher dimension. We believe that the integration of multiple technologies, disciplines, and sensors will be the mainstream trend in the future of artificial intelligence development. Under this trend, many future issues need to be explored, such as how the relationship between keyboards, mice, touch screens, and speech interaction changes; whether search, e-commerce, and social interactions will be restructured; whether hardware will reverse its position to become more important than software; and how the relationships among sensors, chips, operating systems, products, and content vendors in the industry chain will evolve.
This article has received guidance from numerous experts in the field of speech recognition and has cited some reference materials and images, for which we express our gratitude. Any shortcomings in this article are welcome to be criticized and corrected.
Chen Xiaoliang, Founder, Chairman, and CEO of Voice AI Technology; Feng Dahang, Co-founder and CTO of Voice AI Technology; Li Zhiyong, Strategic Partner and CSO of Voice AI Technology.
Reprinted from AI Technology Camp