Skip to content
The large models of artificial intelligence not only amaze people through conversation, but many projects have already been implemented.The key to all this is the magical “emergence” of large AI models, and this article explains this phenomenon.
1. Artificial Intelligence Is Booming Again
The popularity of large models triggered by ChatGPT remains unabated, with China launching more than 200 in a short time. The large model Gemini launched by Google on December 6th became a sensation, and its video demonstration left a deep impression, although it sparked controversy over forgery.
AIGC (Artificial Intelligence Generated Content) is making continuous progress. In a short video generated by HeyGen AI developed by Shenzhen Shiyun Technology, Guo Degang spoke fluent English, and Taylor Swift’s Chinese tone and lip movements matched perfectly, causing a stir. Video and image generation software like Runaway and Pika have performed excellently, becoming popular in the tech circles of China and the U.S. Midjourney’s image generation has achieved great success in the market, generating $200 million in annual revenue with only 40 employees and no investors. The development process of gaming companies has changed, and the efficiency of concept artists has greatly increased. Venture capital related to AI startups is currently the hottest, without exception.
In 2023, the popularity of artificial intelligence was somewhat unexpected. People originally thought this would be an “artificial intelligence winter.”
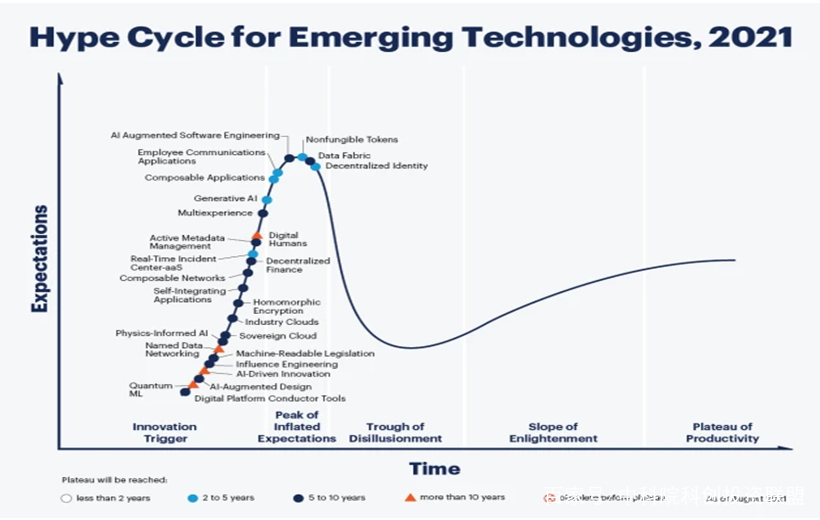
Gartner’s Emerging Technology Development Curve
In early 2016, DeepMind’s AlphaGo defeated humans in Go, triggering the largest wave of artificial intelligence enthusiasm in years, and people’s passion surged, making it a hot topic at every meeting. However, the enthusiasm gradually declined, as many industry insiders revealed and anticipated. Deep learning has both capabilities and flaws, and expectations should not be too high. Just like autonomous driving became a research pitfall, many companies invested heavily but struggled to make breakthroughs. The valuations of AI startups decreased, and venture capitalists were looking for breakthroughs. All of this seemed very “normal,” conforming to the laws of technological development; the overly high expectations generated during the boom period were shattered, enthusiasm waned, and industry insiders continued to accumulate knowledge, recovering from the trough and promoting the application of technology in the long term.
Even industry insiders did not expect that in 2023, the large models of artificial intelligence and AIGC would become so popular. Zhou Hongyi, the founder of 360, shared his observations from a trip to Silicon Valley on November 30th, stating that “investors no longer consider companies without AI concepts, functionalities, or components,” and that “the U.S. is betting on artificial intelligence; the entire investment system, entrepreneurial system, large company system, and traditional company system are fully embracing AI.”
From the perspective of industrial and technological impact, the intensity of the artificial intelligence boom in 2023 has already surpassed that of 2016. This is for a reason; many researchers believe that human society has experienced a significant breakthrough in scientific principles not seen in decades, which cannot be evaluated using the general technological development curve based on experience.
This major breakthrough is the “emergence” of the capabilities of large AI models. This article will explain from a technical perspective what the “emergence” of large models is and how significant it is.
2. Deep Learning as a Scientific Breakthrough of “Emergence”
The most classic and well-known field of human scientific breakthroughs is physics. Starting from Galileo’s experiments and Newton’s three laws, to the peak of relativity and quantum mechanics in the first half of the 20th century, this is the most profound development history in the field of science. New physical phenomena and laws have been continuously discovered, triggering scientific breakthroughs multiple times, some of which have also led to technological and industrial revolutions.
Since the second half of the 20th century, major physical discoveries have significantly decreased, and it seems that the basic laws of the universe that can be discovered are limited. Some people believe that human society has experienced a “technological stagnation,” with fewer major scientific discoveries and breakthroughs, even regressing, such as in space exploration. However, analyzing from the perspective of “emergence” would yield a different perspective.
Physics has had many “emergences” in the past. Technological advancements have allowed scientists to invent and create entirely new experimental tools, discovering exciting new phenomena and validating new theories. In the early days of quantum mechanics, there were many major breakthroughs within a few years. Scientific discoveries often do not require too deep an understanding; even with vague theories, as long as they are paired with suitable tools and detection instruments, major breakthroughs can occur. Before the 20th century, people realized that matter is composed of atoms, discovering many elements through methods like spectral analysis, while the microscopic theories of atoms remained unclear.
Although new physical phenomena have become rare, human technology has not stagnated. In fields such as biology and IT, exciting new discoveries continue to emerge, driving technological and industrial progress. Scientific laws and phenomena should not be ranked hierarchically; as long as they provide new capabilities for understanding and transforming the world, they all represent significant breakthroughs at the principle level. Artificial intelligence is built upon the knowledge system of physics, but its significance of discovery is not less than that of fundamental physical laws.
The emergence of capabilities demonstrated by large AI models can be likened to the discovery of electricity, leading to exciting new phenomena and representing a foundational scientific discovery with enormous potential. Although few truly understand it, industry insiders are exploring this new world with a scientific passion not seen in decades.
In the more than 60 years of development history of artificial intelligence, many new phenomena of interest have emerged. However, they often come with many controversies, and their value is not as imagined, clearly limited by the developmental stage and the capabilities of the “tools” (i.e., computer hardware) relied upon for AI development. Criticism of the capabilities of artificial intelligence and the revelation of major flaws have always accompanied its development, and even in the era of large models, issues like the indelible “hallucinations” in machine dialogue persist.
In the 1950s and 60s, simple structures like perceptrons and artificially written algorithm programs for playing chess made scholars realize that artificial intelligence (Artificial Intelligence) was a new scientific field. However, due to the overly simplistic structure of neural networks, the difficulty of meticulously coding AI programs, and the exponential complexity of algorithms, early artificial intelligence encountered a trough. In the 1980s, Japan chose artificial intelligence as the breakthrough direction for its “fifth generation computer” but ultimately failed, rendering the technical materials worthless.
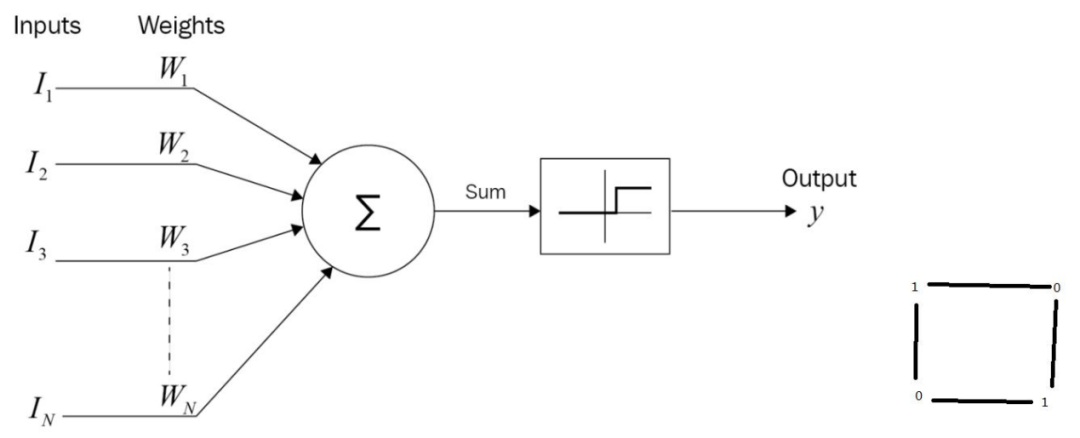
Perceptron Model and the “XOR Problem”
The famous “XOR problem” was pointed out by researchers like Minsky, who indicated that a single-layer perceptron could successfully output the AND, OR, and NOT of two input values by adjusting the neural network coefficients; however, no matter how the coefficients are adjusted, it cannot produce the XOR result. Theoretically, it is impossible, as illustrated in the right image where 0 and 1 are placed at the four corners, and a straight line cannot be drawn to separate 0 and 1. Generally speaking, if two patterns are “linearly separable” by a hyperplane, the perceptron can train and converge; however, in practical applications, the vast majority of pattern recognition problems are non-linear.
The problem of “linear separability” can be successfully trained using neural networks, which is a new phenomenon from the perspective of scientific discovery. The fundamental characteristics of large models with trillions of coefficients can be found in the initial perceptron, where coefficients are adjusted, and simple operations of addition, subtraction, multiplication, and division yield numerical results for interpretation and output. However, this is merely hindsight; due to the limitations of understanding at the time, the academic community generally regarded neural networks as insignificant “toys,” corresponding to the first artificial intelligence winter from 1974 to 1980. There are many such examples in the scientific community; research results may be somewhat interesting, but if there are no further developments, they gradually cool down and rarely heat up again.
In the 1980s, researchers like Yann LeCun and Hinton (along with Bengio, who won the Turing Award in 2018) introduced multi-layer neural networks and the highly significant “backpropagation algorithm” (BP), successfully achieving results like sufficiently accurate handwritten digit recognition, leading to applications like envelope postal code recognition and check recognition, with increasing industrial applications. With the rise in computer performance, the capabilities of meticulously coded chess programs left a deep impression, as they defeated human world champions in chess.
This period of artificial intelligence saw some development and minor achievements; however, it seemed less prominent in the IT wave of that time. This corresponds to the second artificial intelligence winter from 1987 to 2016, which can be understood from an investment perspective. People were enthusiastic about investment directions like software development, communications, the internet, and mobile apps, while artificial intelligence was not considered popular.
IBM’s Deep Blue was developed at a high cost, and after defeating Kasparov, it was shelved, with little subsequent development and technological impact. People realized that relying on meticulously coded algorithms to create AI would be hindered by the exponential complexity of game-theoretic problems, and the logical capabilities of coded expert systems were limited, making them difficult to handle complex issues. This “symbolism” development path was the mainstream of artificial intelligence at that time, representing the pinnacle of the industry, but the subsequent direction was unclear.
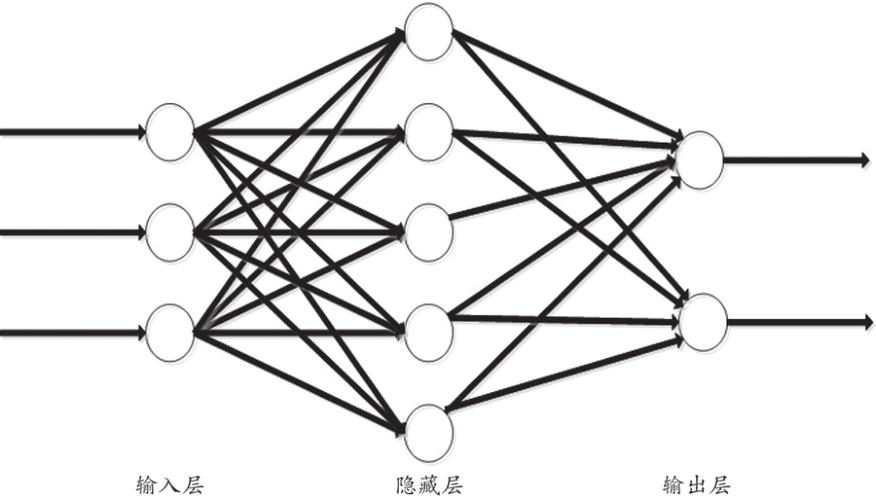
BP Neural Network Structure with One Hidden Layer
The deep learning and large models that later shone brightly already had their basic structures and training frameworks at this stage. Multi-layer neural networks are connected forward and backward, corresponding to the “connectionism” of artificial intelligence. Forward propagation computes the final node’s result, which is compared to the sample to produce an “error,” which is then backpropagated layer by layer, repeatedly modifying coefficients using methods like “gradient descent” to reduce the error and optimize the overall “loss function.” These seemingly simple basic techniques, through repeated training to reduce the loss function to a very low level, can produce astonishing pattern recognition effects, recognizing simple patterns like handwritten digits. However, the capabilities of multi-layer neural networks at this stage were still limited, and they performed poorly on slightly more complex image pattern recognition problems, which restricted technological applications.
In 2016, the artificial intelligence boom suddenly arose because AlphaGo defeated top human players in Go, a problem that was extremely difficult (beyond the capabilities of symbolism), which was quite unexpected and somewhat dramatic. In fact, for industry insiders, this was a natural outcome, resulting from a combination of various technological factors, including traditional MCTS (Monte Carlo Tree Search) game search algorithms, as well as the application of new technologies like deep neural networks, reinforcement learning, and generative adversarial networks (GANs). The results were good, but the technology was not particularly groundbreaking and was understandable, as many individual developers had created powerful Go AIs.
For the industry, the foundational significance of the image recognition neural network AlexNet in 2012 was even greater. The three-person development team of AlexNet included mentor Hinton and two students, one of whom is the core technology figure of ChatGPT, Ilya Sutskever, who also participated in the development of AlphaGo. AlexNet relied on deep convolutional neural networks, reducing the error rate in the ImageNet image recognition competition to 15%, a significant breakthrough compared to the 30% error rate of other technologies. This was a true advancement that excited the industry: deep learning demonstrated its magic.
Deep learning allowed the industry to find direction from confusion. The speed of computer hardware continued to improve, and GPU parallel acceleration was also rapidly increasing, with the training data volume skyrocketing. After breaking through the bottleneck, the capabilities of deep neural networks suddenly “emerged.” In a short period, deep learning results swept across almost all scientific fields, as people’s experiences were constructed and trained within various neural network structures. The quality of machine translation improved dramatically, facial recognition capabilities were astonishing, and painting became indistinguishable from reality. These advancements had actually occurred before the emergence of AlphaGo; society was aware that “deep learning is powerful,” but did not think too far ahead.
This was a true “emergence” in the scientific sense. Previously, computers served as tools to assist research in various scientific fields, with the dominant knowledge being field-specific expertise. However, suddenly, various disciplines discovered that even the research paradigm had changed.
The “emergence” of deep learning has two layers of meaning. One layer indicates that as the scale of neural networks, training machine speed, and sample quantity continue to increase, once a certain scale is reached, a sudden “quantitative change leads to qualitative change” occurs, and the capabilities of neural networks leap to “emerge,” significantly enhancing image recognition effects. The second layer indicates that deep learning performs exceptionally well in the field of image recognition, and this capability quickly spreads to other computer fields, even changing other disciplines, with the application range of this capability also emerging.
Interestingly, people paid great attention to AlphaGo because the ultimate meaning of “intelligence” sparked significant interest. Many imagined a humanoid machine thinking and defeating human chess players, proving that humanity’s last bastion of “wisdom” was inferior to machines, leading to many philosophical and social reflections. However, the artificial intelligence technology represented by AlphaGo is not fundamentally related to the essence of intelligence; it is an “artificial” illusion created by cleverly simulating a complex computational task. After society gradually became accustomed to it, the boundaries of artificial intelligence’s capabilities became clear, and discussions about machine intelligence rapidly cooled after 2018, seemingly returning to a winter period, with declining investment enthusiasm.
Of course, in the industry, since the artificial intelligence boom in 2016, there has been no winter. Developers have actively applied deep learning in various fields, and researchers have explored new neural network architectures and training methods, continuously producing various results, making the field very active. However, the outside world perceives it as “not so magical,” feeling bland.
According to Minsky’s mathematical understanding, this breakthrough in deep learning is to construct a large mathematical formula with a vast number of coefficients (from millions to billions) to fit and approximate the solution space of complex problems like Go and image recognition. It has evolved from the simplest capability of “linear separation planes” to using extremely large, complex hyper-surface curves to segment space. The construction method is statistical fitting, comparing statistical errors through massive samples, modifying coefficients through backpropagation to reduce errors, and after multiple learnings, the errors are minimized, achieving successful numerical simulations. Samples can be manually labeled or automatically generated, and the hardware foundation is GPU-accelerated parallel computing (with thousands of computing cores).
When I communicated with humanists, I clarified the mathematical significance of statistical simulation, which demystified artificial intelligence, and the magical sense of “intelligence” disappeared. Moreover, this statistical simulation evidently has flaws and lacks a solid logical foundation. Its success is statistical, and when bugs occur is difficult to predict.
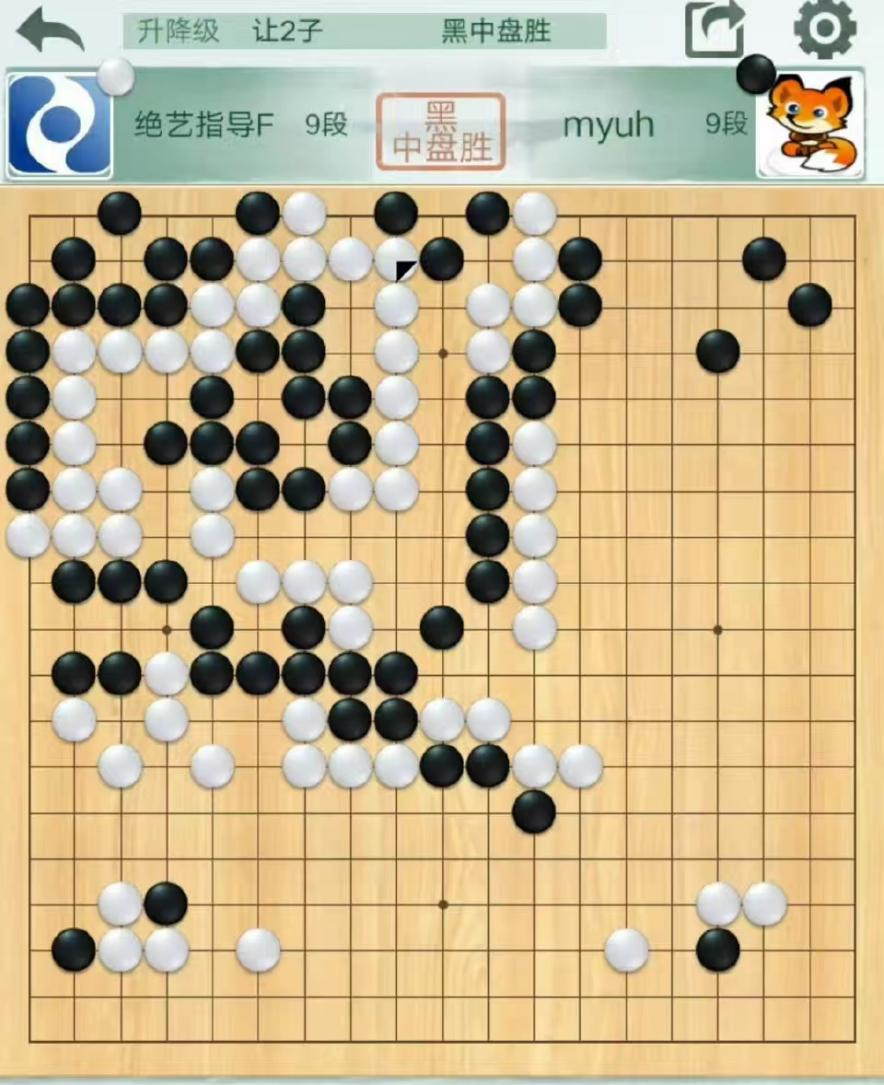 Just like AlphaGo’s 3:0 victory over the world’s top player Ke Jie, which was considered a complete victory over humanity, looking back, it may have significant flaws. Researchers constructed rare shapes like the “Dragon Eye” in Go, hitting the weakness of Go AI, causing the incredibly powerful AI to make simple mistakes. The image depicts a match in February 2023, where Japanese professional player Shibano Ryunosuke played black against the Go AI Zhi Yi. The black pieces induced the white pieces to make a move that encircled a live black piece. Because the AI rarely encountered such shapes during training, it developed a misconception about the life and death of the pieces, ultimately leading to a large group dying, and the industry believes that all Go AI will have this bug.
Such examples are everywhere in various fields. Pattern recognition based on deep neural networks will have indelible flaws, and applying it to safety-related fields like autonomous driving will pose significant troubles. To some extent, this is also the technical root of the “third artificial intelligence winter” narrative, failing to meet expectations, leaving some researchers feeling lost.
3. The Second Artificial Intelligence “Emergence”: Large Models
Just when the industry generally believed that artificial intelligence would not have significant breakthroughs in the short term, a more significant breakthrough arrived!
At the end of 2022, ChatGPT and GPT-4 ignited global attention, prompting major IT companies to urgently purchase NVIDIA GPUs to develop large models. The performance of this artificial intelligence, in the eyes of the industry, genuinely approached the original meaning of “intelligence,” although there were still controversies. The outside world, having experienced a wave of enthusiasm since 2016, learned from the overly high expectations and “lessons,” thus not being particularly “crazy.”
The breakthroughs in artificial intelligence often start from seemingly simple tasks. This time, the large model began with a “simple” task: predicting the next word. The basic operation of the “language large model” is simply to output words one after another; it is that simple in form. Past chatbots and poetry machines have shown people this without anything special, but nobody expected a huge breakthrough in this field that could potentially produce genuine “intelligence.”
Whether a machine can learn true intelligence by only studying human language is controversial; Yang Likun strongly denies this. However, this falls into the realm of “AI philosophy,” which we can set aside for now and see what happens when machines learn from massive amounts of “corpus.”
GPT stands for Generative Pre-Trained Transformer. Let’s take a look at its specific meaning. The Transformer is a type of neural network structure invented in 2017, which proved its capabilities in the task of machine translation. It is not complicated; it just holds a particularly large number of coefficients, amounting to hundreds of billions. Generative refers to the generative aspect; GPT generates dialogue text and other content, and the recently popular image and video software are also generative applications. Pre-Trained means that the entire internet-sized corpus is fed to the Transformer for learning, later supplemented with audio and video materials, making it multimodal. The corpus does not even require manual labeling (removing harmful content is another matter); pre-training simply involves having GPT predict the next word in the text corpus, and if it is incorrect, it backpropagates to adjust the coefficients.
This task sounds simple, but think about what GPT will learn from it. That’s not simple at all. It is essential to notice that researchers have dramatically expanded the machine’s storage and training “computing power,” sufficient to handle the vast corpus of the entire internet.
A traditional observation is that learning from the corpus can allow machines to learn “grammar” and “semantics.” In the field of NLP (Natural Language Processing), especially in machine translation tasks, researchers have experienced this deeply. Using manually coded implementations to achieve grammar and word associations is a dead end, leading to ugly translations. However, when machines automatically learn from training texts, they can establish grammar and semantic associations between words in a language, resulting in reasonably good translations. It understands that some words are related to each other, frequently appearing together, and under what conditions they appear, with these relationships recorded in the neural network coefficients. The Transformer data structure conveniently establishes associations between words in a sentence.
Even if machine translation has improved significantly, people know that machines do not understand what these words mean. Mathematically speaking, machines encode a passage using an encoder and then decode it into another language using a decoder. It is a coding and decoding algorithm, adjusted to make the translation seem decent to people. In reality, from the machine’s perspective, it only faces a series of “tokens” that are related to each other; what they actually represent does not need to be known. Just like in Go, where there is a definitive answer (a complete information game), the translation output is also relatively certain, making it a comparatively “easy” task (humans always feel that once a problem is solved, it becomes easy).
However, the task of GPT’s pre-training is not translation but predicting the next token. This is much more challenging than merely translating decently; to make the subsequent text sequence reasonable (so that it aligns with human corpus probabilities), it needs to understand “facts” and even learn to “reason!” At this point, a genuinely astonishing new scientific phenomenon has “emerged” in the field of artificial intelligence.
Just like AlphaGo’s 3:0 victory over the world’s top player Ke Jie, which was considered a complete victory over humanity, looking back, it may have significant flaws. Researchers constructed rare shapes like the “Dragon Eye” in Go, hitting the weakness of Go AI, causing the incredibly powerful AI to make simple mistakes. The image depicts a match in February 2023, where Japanese professional player Shibano Ryunosuke played black against the Go AI Zhi Yi. The black pieces induced the white pieces to make a move that encircled a live black piece. Because the AI rarely encountered such shapes during training, it developed a misconception about the life and death of the pieces, ultimately leading to a large group dying, and the industry believes that all Go AI will have this bug.
Such examples are everywhere in various fields. Pattern recognition based on deep neural networks will have indelible flaws, and applying it to safety-related fields like autonomous driving will pose significant troubles. To some extent, this is also the technical root of the “third artificial intelligence winter” narrative, failing to meet expectations, leaving some researchers feeling lost.
3. The Second Artificial Intelligence “Emergence”: Large Models
Just when the industry generally believed that artificial intelligence would not have significant breakthroughs in the short term, a more significant breakthrough arrived!
At the end of 2022, ChatGPT and GPT-4 ignited global attention, prompting major IT companies to urgently purchase NVIDIA GPUs to develop large models. The performance of this artificial intelligence, in the eyes of the industry, genuinely approached the original meaning of “intelligence,” although there were still controversies. The outside world, having experienced a wave of enthusiasm since 2016, learned from the overly high expectations and “lessons,” thus not being particularly “crazy.”
The breakthroughs in artificial intelligence often start from seemingly simple tasks. This time, the large model began with a “simple” task: predicting the next word. The basic operation of the “language large model” is simply to output words one after another; it is that simple in form. Past chatbots and poetry machines have shown people this without anything special, but nobody expected a huge breakthrough in this field that could potentially produce genuine “intelligence.”
Whether a machine can learn true intelligence by only studying human language is controversial; Yang Likun strongly denies this. However, this falls into the realm of “AI philosophy,” which we can set aside for now and see what happens when machines learn from massive amounts of “corpus.”
GPT stands for Generative Pre-Trained Transformer. Let’s take a look at its specific meaning. The Transformer is a type of neural network structure invented in 2017, which proved its capabilities in the task of machine translation. It is not complicated; it just holds a particularly large number of coefficients, amounting to hundreds of billions. Generative refers to the generative aspect; GPT generates dialogue text and other content, and the recently popular image and video software are also generative applications. Pre-Trained means that the entire internet-sized corpus is fed to the Transformer for learning, later supplemented with audio and video materials, making it multimodal. The corpus does not even require manual labeling (removing harmful content is another matter); pre-training simply involves having GPT predict the next word in the text corpus, and if it is incorrect, it backpropagates to adjust the coefficients.
This task sounds simple, but think about what GPT will learn from it. That’s not simple at all. It is essential to notice that researchers have dramatically expanded the machine’s storage and training “computing power,” sufficient to handle the vast corpus of the entire internet.
A traditional observation is that learning from the corpus can allow machines to learn “grammar” and “semantics.” In the field of NLP (Natural Language Processing), especially in machine translation tasks, researchers have experienced this deeply. Using manually coded implementations to achieve grammar and word associations is a dead end, leading to ugly translations. However, when machines automatically learn from training texts, they can establish grammar and semantic associations between words in a language, resulting in reasonably good translations. It understands that some words are related to each other, frequently appearing together, and under what conditions they appear, with these relationships recorded in the neural network coefficients. The Transformer data structure conveniently establishes associations between words in a sentence.
Even if machine translation has improved significantly, people know that machines do not understand what these words mean. Mathematically speaking, machines encode a passage using an encoder and then decode it into another language using a decoder. It is a coding and decoding algorithm, adjusted to make the translation seem decent to people. In reality, from the machine’s perspective, it only faces a series of “tokens” that are related to each other; what they actually represent does not need to be known. Just like in Go, where there is a definitive answer (a complete information game), the translation output is also relatively certain, making it a comparatively “easy” task (humans always feel that once a problem is solved, it becomes easy).
However, the task of GPT’s pre-training is not translation but predicting the next token. This is much more challenging than merely translating decently; to make the subsequent text sequence reasonable (so that it aligns with human corpus probabilities), it needs to understand “facts” and even learn to “reason!” At this point, a genuinely astonishing new scientific phenomenon has “emerged” in the field of artificial intelligence.
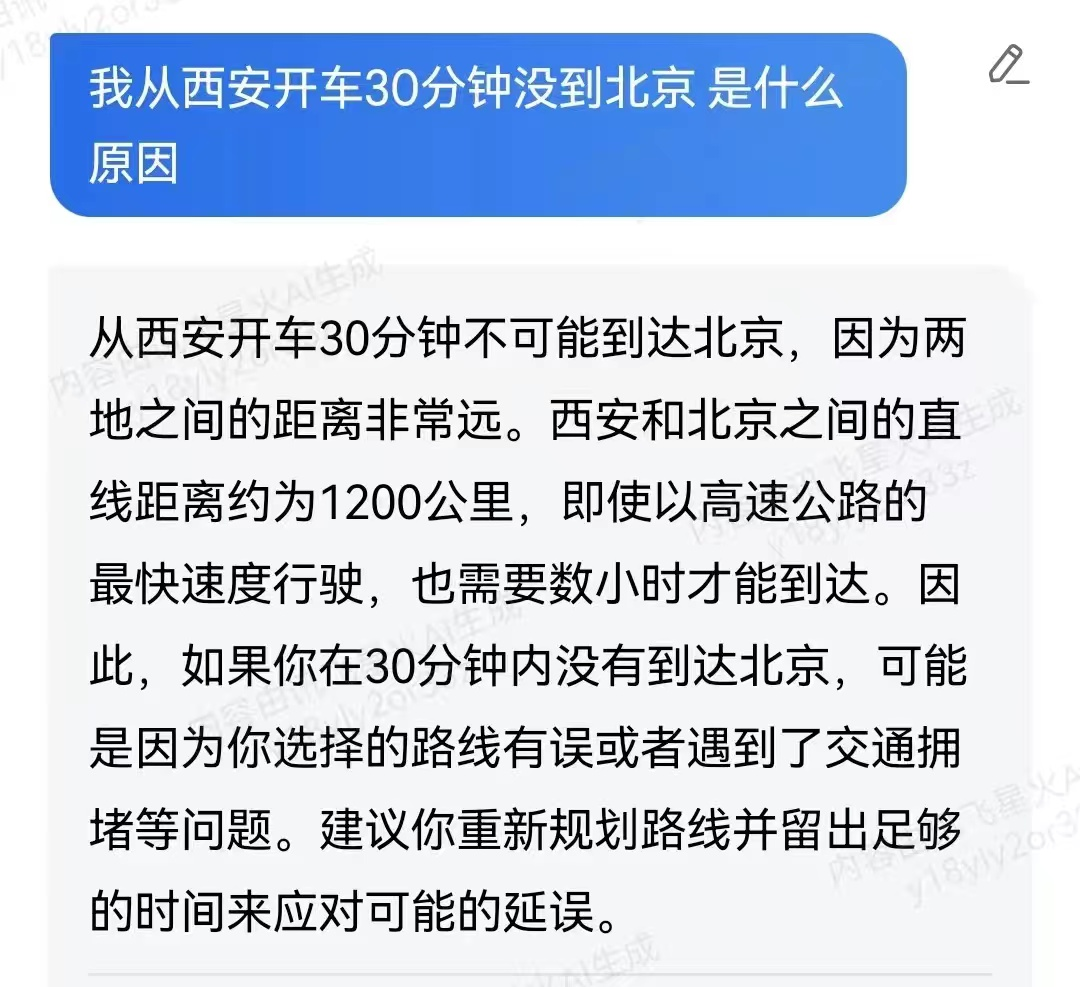 Taking the example of iFLYTEK’s “Spark Large Model,” which ranks among the top in Chinese large models, it faces the question, “Why haven’t I arrived in Beijing after driving for 30 minutes from Xi’an?” There is no direct answer in the corpus, so it needs to decompose the question. Understanding the relevant corpus about “not arriving after driving” will introduce “time” and “distance,” and then relate Xi’an and Beijing based on distance, also incorporating “speed,” ultimately combining to form an answer. This process intuitively is not simple and genuinely resembles reasoning.
In the applications of ChatGPT and GPT-4, there are many such cases, leading people to believe that machines truly possess powerful reasoning capabilities. OpenAI personnel have mentioned that sometimes they do not know how GPT-4 arrives at certain conclusions; the mechanisms inside are indeed very mysterious.
Of course, GPT also has many logical flaws, and it is not difficult to induce the machine to give absurd answers. However, from the perspective of scientific discovery, the new phenomena can be repeated, and even if applications require conditions and have flaws, it still represents a substantial breakthrough. Previously, researchers believed that chatbots were merely formal language imitators (many still hold this view of GPT), and they had never discovered that machines possess such powerful reasoning capabilities. After observing many dialogues with GPT, it is evident that the reasoning capability is genuinely contained within the machine’s data structure and cannot merely be mimicked.
The excitement over “new phenomena,” rather than focusing on absurd flaws, is a characteristic that distinguishes researchers from ordinary people. The outside world may demand that serious flaws be addressed; otherwise, it cannot pass the Turing test, and applications may not be trusted. However, researchers pay more attention to the new capabilities demonstrated by machines, knowing that this represents a “new world.” Physicists are extremely attentive to possible “new physics,” analyzing even the slightest clues, often leading to disappointment. Similarly, artificial intelligence researchers are concerned with questions like “How is the machine’s reasoning ability generated?” This collective excitement over the “great discovery ahead” has never been seen before in the industry.
In just ten years, the field of artificial intelligence has witnessed two instances of scientific principle-level “emergence”: one from deep learning and the other from large language models. Perhaps the outside world does not understand the significance, but industry insiders have truly developed an unprecedented enthusiasm.
How did large models learn to reason? This can also be described. A similar example is how Go AI learns to “capture pieces.” The training of AI continuously improves, with a set of “weights” corresponding to each version. In games like Go, where there are wins and losses, AI can start from knowing nothing, allowing various versions to “self-play” against each other, and improve weights based on the match results, with the successful weights continuing to develop. This training can be distributed, as LeelaZero is updated by numerous enthusiasts contributing their machines for self-play.
Taking the example of iFLYTEK’s “Spark Large Model,” which ranks among the top in Chinese large models, it faces the question, “Why haven’t I arrived in Beijing after driving for 30 minutes from Xi’an?” There is no direct answer in the corpus, so it needs to decompose the question. Understanding the relevant corpus about “not arriving after driving” will introduce “time” and “distance,” and then relate Xi’an and Beijing based on distance, also incorporating “speed,” ultimately combining to form an answer. This process intuitively is not simple and genuinely resembles reasoning.
In the applications of ChatGPT and GPT-4, there are many such cases, leading people to believe that machines truly possess powerful reasoning capabilities. OpenAI personnel have mentioned that sometimes they do not know how GPT-4 arrives at certain conclusions; the mechanisms inside are indeed very mysterious.
Of course, GPT also has many logical flaws, and it is not difficult to induce the machine to give absurd answers. However, from the perspective of scientific discovery, the new phenomena can be repeated, and even if applications require conditions and have flaws, it still represents a substantial breakthrough. Previously, researchers believed that chatbots were merely formal language imitators (many still hold this view of GPT), and they had never discovered that machines possess such powerful reasoning capabilities. After observing many dialogues with GPT, it is evident that the reasoning capability is genuinely contained within the machine’s data structure and cannot merely be mimicked.
The excitement over “new phenomena,” rather than focusing on absurd flaws, is a characteristic that distinguishes researchers from ordinary people. The outside world may demand that serious flaws be addressed; otherwise, it cannot pass the Turing test, and applications may not be trusted. However, researchers pay more attention to the new capabilities demonstrated by machines, knowing that this represents a “new world.” Physicists are extremely attentive to possible “new physics,” analyzing even the slightest clues, often leading to disappointment. Similarly, artificial intelligence researchers are concerned with questions like “How is the machine’s reasoning ability generated?” This collective excitement over the “great discovery ahead” has never been seen before in the industry.
In just ten years, the field of artificial intelligence has witnessed two instances of scientific principle-level “emergence”: one from deep learning and the other from large language models. Perhaps the outside world does not understand the significance, but industry insiders have truly developed an unprecedented enthusiasm.
How did large models learn to reason? This can also be described. A similar example is how Go AI learns to “capture pieces.” The training of AI continuously improves, with a set of “weights” corresponding to each version. In games like Go, where there are wins and losses, AI can start from knowing nothing, allowing various versions to “self-play” against each other, and improve weights based on the match results, with the successful weights continuing to develop. This training can be distributed, as LeelaZero is updated by numerous enthusiasts contributing their machines for self-play.
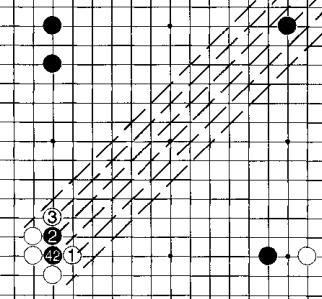 During training, enthusiasts have clearly observed that conventional Go tactics, such as capturing, escaping, and running away, are quickly learned by AI versions, while capturing pieces is much more challenging. This is because it involves diagonal relationships between pieces that are far apart, and whether they can be maneuvered to capture is difficult for AI. However, over time, a lucky version of the weights would learn to judge captures and use this ability to dominate other versions that cannot capture. Learning to capture requires the neural network structure of Go AI to be sufficiently large; for instance, 20 layers may be needed when 10 layers are insufficient, requiring extensive self-play training.
The pre-training of GPT to achieve reasoning capabilities is similar. First, the scale of the network structure must be large; OpenAI continuously expanded the scale from GPT-2 to GPT-3 and GPT-4, reaching hundreds of billions of coefficients. Next, the training corpus must be extensive, and the training time must be long. The remaining factor is how GPT’s capabilities gradually emerge, similar to the self-play training of Go AI, where simpler abilities are learned first, followed by more complex ones.
The shocking scientific discovery is that GPT-3 is extremely successful; it learned very complex reasoning during pre-training! This is akin to the significance of AlexNet for deep learning, as GPT-3 made the industry recognize the immense potential of large language models.
It can be understood that for some tasks predicting text using GPT, if reasoning is not involved, it definitely will not perform well. If it does poorly, the “loss” value will be relatively large. GPT undergoes repeated training, constantly modifying weights in various ways to attempt to reduce the “loss,” ultimately bringing it down at some point. This is equivalent to GPT acquiring reasoning capabilities, producing outputs that seem reasonable.
In fact, human learning of reasoning occurs similarly; once you learn, you can pass the exam; otherwise, you cannot. Each person has their own method, and exams and applications serve as the evaluation criteria. Philosophically, if machines are not reasoning but simply calculating and mimicking, it cannot be clearly defined as intelligence. A fair assessment is that if machines can accomplish tasks requiring reasoning, then they have acquired reasoning capabilities and mastered many “facts” necessary for reasoning.
OpenAI did not publish technical details of GPT-3 and GPT-4 according to conventional practices, and some training techniques can only be speculated upon. However, industry insiders always exchange ideas, and employees can be poached, making it impossible for technology to remain exclusive indefinitely. Therefore, the training techniques of GPT are spreading, and some cognitions are gradually becoming consensus in the industry. The success of GPT lies in the emergence it created, which is the consensus of the industry.
This emergence of GPT also carries philosophical significance, offering more to discuss compared to the previous emergence of deep learning.
1. Similar to deep learning, with the continuous growth of network scale, corpus, machine speed, and training time, new capabilities ultimately emerge, where quantitative changes lead to qualitative changes. This is a conventional expectation; people were previously uncertain whether the Transformer-based GPT could succeed and were reluctant to invest heavily. This barrier has now been crossed, and countless companies are willing to invest heavily.
2. The pre-training of GPT aims to reduce the “loss,” which is a unified value for the loss function. However, unlike AlexNet’s single task, GPT actually has many tasks for text output performance to improve. In some scenarios, the dialogue difficulty may be low, resulting in good performance, while in others, complex reasoning or even mathematical abilities are tested, leading to poor performance. The emergence of GPT is not a one-time event but involves various types of task abilities improving gradually from easy to difficult. In other words, the emergence of GPT itself is diverse, with many details worth exploring. For example, the ability for a certain type of task may suddenly emerge, even if the loss function appears to show little difference; this is fresh compared to other single-task training. Additionally, people have found GPT’s logical capabilities impressive, but it struggles with mathematics.
3. The emergence of GPT has not yet reached its endpoint. When people discover that good things happen when “quantitative changes lead to qualitative changes,” they become very excited; perhaps only a few small tasks’ successes can convince them of this. However, continued training will reveal even more good things; the types of tasks contained in human text are essentially infinite, and the difficulties will become increasingly challenging, testing various abilities. How powerful the GPT framework truly is remains unclear, and this sense of the unknown is even more exciting. People feel like treasure hunters in a cave, knowing there are treasures but not knowing what type, which attracts even more treasure seekers. The emergence of deep learning is easier to judge; abilities have emerged, but further training will not yield better results, as the entire process becomes familiar.
4. The scale of GPT should continue to expand, from hundreds of billions of parameters to trillions and even higher. For general deep learning tasks, having a sufficient network scale is enough, and further expansion may not be significant, potentially leading to “overfitting.” However, GPT needs to retain information about the “facts” of human society, and a few hundred billion coefficients are clearly insufficient. While it can perform “information compression,” this will inevitably lead to information loss. Another intuition is that as the network scale increases, GPT’s “potential” will also grow, allowing it to explore deeper correlations in a complex ocean of heuristic knowledge.
After understanding the emergence characteristics of GPT, one can comprehend why researchers’ excitement exceeds that of the deep learning wave. Some radical scholars believe that the GPT architecture inherently contains true intelligence, leading to genuine contemplation about the potential for machines to destroy humanity. A somewhat strange phenomenon is that OpenAI has invested considerable effort into AI safety research, even causing internal turmoil akin to a “coup” within the company. The emergence of GPT indeed possesses characteristics of human wisdom: diversity, complexity, unpredictability, and infinite potential. Therefore, this represents the closest approach to “Artificial General Intelligence” (AGI) in the field of artificial intelligence and scientific research as a whole. It also clarifies why scholars are seriously discussing GPT-related “AI philosophy” issues.
The outside world does not adequately understand GPT’s emergence, leading to an underestimation of its scientific discovery significance. Many people focus on various GPT chat performances, marveling at the strength of ChatGPT and GPT-4 while noting the gap with domestic models. Some are astonished by the strong reasoning capabilities displayed in AI conversations or shocked by the AI’s ability to fabricate and lie convincingly. The outside world tends to believe that the research on GPT primarily aims to improve its conversational capabilities, limiting imagination.
In reality, the core of GPT research should be to explore more details of the “emergence.” Major companies like Microsoft and Google are testing larger models, with the direct purpose not being to improve chatbot conversations but rather to explore the fascinating “emergence.” Perhaps through continuously fostering GPT’s emergence, the path to AGI will be reached; perhaps, as Yang Likun predicts, this route will not succeed. Nevertheless, now is not the time to focus on flaws and perfect products. Perhaps once the boundaries of GPT’s capabilities are clarified, developers can return to the task of utilizing these capabilities to develop and find ways to avoid flaws.
It is worth noting that the successful emergence of GPT-3 occurred as early as early 2022, with GPT-4 pre-trained as early as August 2022, but only a few professionals were amazed, and it did not gain widespread attention. It was not until ChatGPT (GPT-3.5) adjusted its output language through RLHF (Reinforcement Learning with Human Feedback) to make it more comfortable for humans that it exploded in global attention at the end of 2022.
This illustrates that humans are easily influenced by “appearances,” as even professional researchers were not exempt. Deep learning indeed represents a breakthrough in “emergence,” but it did not create the same buzz in the media as AlphaGo’s match against humans. The pre-training of GPT-3 and GPT-4 is the research framework that continuously generates “emergence,” with limitless potential, but the effects of RLHF have attracted more attention from the outside world.
Domestic large models are in a similar situation; over a hundred companies are developing them, and they should focus on the “emergence” of GPT. Even if some domestic large models have limitations in funding and hardware conditions, and their scales are not very large, exploring the characteristics of the models can still be beneficial, potentially accelerating the occurrence of emergence. There is no need to overly focus on the flaws of domestic large models; these are unavoidable and may stem from various reasons, such as insufficient corpus preparation, inadequate training time, or algorithmic issues. By establishing a research framework for large models and exploring the details of “emergence,” there will always be gains.
Regarding the application ecology of large models, understanding the emergence characteristics of GPT may evoke different feelings. Large models should not be treated merely as chatbots, as this limits imagination. The diverse capabilities that GPT has emerged, including reasoning, mathematics, information compression, multimodal capabilities, and content generation, open up entirely new research architectures. Much like deep learning, it serves as both an exploratory framework and an application architecture.
American IT companies are attempting to transform the entire software system using GPT. Major companies will continue to expand the scale of GPT in a manner akin to an arms race. A more common behavior is to develop toolchains that enable the application of GPT, allowing developers to engage in various industries. This latter aspect is a field that China should learn from and has advantages in.
Regarding the foundational capabilities of domestic large models, I am not worried. For example, iFLYTEK’s Spark Large Model 3.0 is assessed to be close to the level of ChatGPT, and they are preparing to launch Spark AI 4.0, which is close to GPT-4, in May 2024. Large model assessments are an important research field, and standards are not yet unified; however, it is evident that the capabilities of domestic large models are rapidly improving, with the gap with the U.S. being just about two years.
If the quality of responses from domestic large models is not as good as that of ChatGPT or GPT-4 for a particular question, public opinion will pay close attention. However, the focus should be on “emergence.” If the R&D structure of Chinese companies can foster various types of emergence, then essentially, China and the U.S. are competing on the same track. Perhaps American large models have achieved level 4 emergence, while China can only achieve level 3, and American companies have eliminated more bugs, making the gap appear significant. As Chinese companies delve deeper into the research of “emergence,” the gap will close.
The truly impactful factor is the application ecology of large models. Without an ecology, the large model development of companies will ultimately be unsustainable; even OpenAI finds the development and operation of large models too costly. If Chinese companies can establish a large model application ecology, they can iterate development and specifically improve defects in industry applications, which is a forte of Chinese companies. Some applications can succeed; even if the foundational technology is not very strong, if they address industry pain points and promote application, the ecology can develop, which in turn enhances the foundational technology.
China’s development history itself has been a continuous process of “emergence”. After 2000, numerous industrial miracles in China have emerged. Since 2013, I have been advocating for Hefei, the capital of Anhui Province, which has become the fastest-growing city in the world, with its GDP increasing 37 times compared to 2000. Initially, it had no particular industrial features but has emerged multiple trillion-yuan industrial clusters, such as new displays, integrated circuits, and new energy vehicles.
Even after years of advocacy, I am still continually amazed by the development of Hefei and Anhui. For instance, Anhui’s automobile production reached 2.491 million units in 2023, becoming the second in the country (with Guangdong far ahead). This year’s general artificial intelligence competition was held in Wuhu, where local company Chery produced 1.88 million cars in 2023, with both domestic brands and exports experiencing explosive growth, aiming for 4 million units in 2024. Hefei’s production of new energy vehicles reached 255,000 units in 2022, a year-on-year increase of 133%, and 746,000 units in 2023, another increase of 140%. Hefei has a solid layout, with companies like BYD, Volkswagen, and NIO coming in, aiming for 2 million units of new energy vehicles by 2025 and 3.4 million by 2027!
Using GPT as an analogy, China’s development mechanism changed after the reform to a Transformer (which inherently means transformation), leading to unbelievable industrial “emergence.”
Understanding GPT’s “emergence” helps clarify the U.S. government’s suppression of Chinese artificial intelligence, even prohibiting the sale of 4090 graphics cards. It becomes clear that the U.S. government is betting, believing that general artificial intelligence will have significant breakthroughs. U.S. Commerce Secretary Raimondo has said outright that they aim to slow down China’s artificial intelligence development.
However, China is already prepared, with companies like Huawei and iFLYTEK becoming the vanguard in the battle of artificial intelligence against the U.S. iFLYTEK, placed on the U.S. Entity List, has spent half a year adapting to domestic GPUs, leading the nation in this regard. Huawei Cloud has built three major AI computing power centers, one of which is in Wuhu, Anhui.
Industrial development has inertia; those that have already achieved industrial “emergence” have advantages in planning and implementing new emerging industrial policies. Regarding the development of general artificial intelligence, I similarly wish and have confidence in Anhui.
Chen Jing,obtained a Bachelor’s degree in Computer Science from the University of Science and Technology of China, a Master’s degree in Computer Science from the Hong Kong University of Science and Technology, a member of the Science and Strategy Forum, and the author of “China’s Official Economy.”
During training, enthusiasts have clearly observed that conventional Go tactics, such as capturing, escaping, and running away, are quickly learned by AI versions, while capturing pieces is much more challenging. This is because it involves diagonal relationships between pieces that are far apart, and whether they can be maneuvered to capture is difficult for AI. However, over time, a lucky version of the weights would learn to judge captures and use this ability to dominate other versions that cannot capture. Learning to capture requires the neural network structure of Go AI to be sufficiently large; for instance, 20 layers may be needed when 10 layers are insufficient, requiring extensive self-play training.
The pre-training of GPT to achieve reasoning capabilities is similar. First, the scale of the network structure must be large; OpenAI continuously expanded the scale from GPT-2 to GPT-3 and GPT-4, reaching hundreds of billions of coefficients. Next, the training corpus must be extensive, and the training time must be long. The remaining factor is how GPT’s capabilities gradually emerge, similar to the self-play training of Go AI, where simpler abilities are learned first, followed by more complex ones.
The shocking scientific discovery is that GPT-3 is extremely successful; it learned very complex reasoning during pre-training! This is akin to the significance of AlexNet for deep learning, as GPT-3 made the industry recognize the immense potential of large language models.
It can be understood that for some tasks predicting text using GPT, if reasoning is not involved, it definitely will not perform well. If it does poorly, the “loss” value will be relatively large. GPT undergoes repeated training, constantly modifying weights in various ways to attempt to reduce the “loss,” ultimately bringing it down at some point. This is equivalent to GPT acquiring reasoning capabilities, producing outputs that seem reasonable.
In fact, human learning of reasoning occurs similarly; once you learn, you can pass the exam; otherwise, you cannot. Each person has their own method, and exams and applications serve as the evaluation criteria. Philosophically, if machines are not reasoning but simply calculating and mimicking, it cannot be clearly defined as intelligence. A fair assessment is that if machines can accomplish tasks requiring reasoning, then they have acquired reasoning capabilities and mastered many “facts” necessary for reasoning.
OpenAI did not publish technical details of GPT-3 and GPT-4 according to conventional practices, and some training techniques can only be speculated upon. However, industry insiders always exchange ideas, and employees can be poached, making it impossible for technology to remain exclusive indefinitely. Therefore, the training techniques of GPT are spreading, and some cognitions are gradually becoming consensus in the industry. The success of GPT lies in the emergence it created, which is the consensus of the industry.
This emergence of GPT also carries philosophical significance, offering more to discuss compared to the previous emergence of deep learning.
1. Similar to deep learning, with the continuous growth of network scale, corpus, machine speed, and training time, new capabilities ultimately emerge, where quantitative changes lead to qualitative changes. This is a conventional expectation; people were previously uncertain whether the Transformer-based GPT could succeed and were reluctant to invest heavily. This barrier has now been crossed, and countless companies are willing to invest heavily.
2. The pre-training of GPT aims to reduce the “loss,” which is a unified value for the loss function. However, unlike AlexNet’s single task, GPT actually has many tasks for text output performance to improve. In some scenarios, the dialogue difficulty may be low, resulting in good performance, while in others, complex reasoning or even mathematical abilities are tested, leading to poor performance. The emergence of GPT is not a one-time event but involves various types of task abilities improving gradually from easy to difficult. In other words, the emergence of GPT itself is diverse, with many details worth exploring. For example, the ability for a certain type of task may suddenly emerge, even if the loss function appears to show little difference; this is fresh compared to other single-task training. Additionally, people have found GPT’s logical capabilities impressive, but it struggles with mathematics.
3. The emergence of GPT has not yet reached its endpoint. When people discover that good things happen when “quantitative changes lead to qualitative changes,” they become very excited; perhaps only a few small tasks’ successes can convince them of this. However, continued training will reveal even more good things; the types of tasks contained in human text are essentially infinite, and the difficulties will become increasingly challenging, testing various abilities. How powerful the GPT framework truly is remains unclear, and this sense of the unknown is even more exciting. People feel like treasure hunters in a cave, knowing there are treasures but not knowing what type, which attracts even more treasure seekers. The emergence of deep learning is easier to judge; abilities have emerged, but further training will not yield better results, as the entire process becomes familiar.
4. The scale of GPT should continue to expand, from hundreds of billions of parameters to trillions and even higher. For general deep learning tasks, having a sufficient network scale is enough, and further expansion may not be significant, potentially leading to “overfitting.” However, GPT needs to retain information about the “facts” of human society, and a few hundred billion coefficients are clearly insufficient. While it can perform “information compression,” this will inevitably lead to information loss. Another intuition is that as the network scale increases, GPT’s “potential” will also grow, allowing it to explore deeper correlations in a complex ocean of heuristic knowledge.
After understanding the emergence characteristics of GPT, one can comprehend why researchers’ excitement exceeds that of the deep learning wave. Some radical scholars believe that the GPT architecture inherently contains true intelligence, leading to genuine contemplation about the potential for machines to destroy humanity. A somewhat strange phenomenon is that OpenAI has invested considerable effort into AI safety research, even causing internal turmoil akin to a “coup” within the company. The emergence of GPT indeed possesses characteristics of human wisdom: diversity, complexity, unpredictability, and infinite potential. Therefore, this represents the closest approach to “Artificial General Intelligence” (AGI) in the field of artificial intelligence and scientific research as a whole. It also clarifies why scholars are seriously discussing GPT-related “AI philosophy” issues.
The outside world does not adequately understand GPT’s emergence, leading to an underestimation of its scientific discovery significance. Many people focus on various GPT chat performances, marveling at the strength of ChatGPT and GPT-4 while noting the gap with domestic models. Some are astonished by the strong reasoning capabilities displayed in AI conversations or shocked by the AI’s ability to fabricate and lie convincingly. The outside world tends to believe that the research on GPT primarily aims to improve its conversational capabilities, limiting imagination.
In reality, the core of GPT research should be to explore more details of the “emergence.” Major companies like Microsoft and Google are testing larger models, with the direct purpose not being to improve chatbot conversations but rather to explore the fascinating “emergence.” Perhaps through continuously fostering GPT’s emergence, the path to AGI will be reached; perhaps, as Yang Likun predicts, this route will not succeed. Nevertheless, now is not the time to focus on flaws and perfect products. Perhaps once the boundaries of GPT’s capabilities are clarified, developers can return to the task of utilizing these capabilities to develop and find ways to avoid flaws.
It is worth noting that the successful emergence of GPT-3 occurred as early as early 2022, with GPT-4 pre-trained as early as August 2022, but only a few professionals were amazed, and it did not gain widespread attention. It was not until ChatGPT (GPT-3.5) adjusted its output language through RLHF (Reinforcement Learning with Human Feedback) to make it more comfortable for humans that it exploded in global attention at the end of 2022.
This illustrates that humans are easily influenced by “appearances,” as even professional researchers were not exempt. Deep learning indeed represents a breakthrough in “emergence,” but it did not create the same buzz in the media as AlphaGo’s match against humans. The pre-training of GPT-3 and GPT-4 is the research framework that continuously generates “emergence,” with limitless potential, but the effects of RLHF have attracted more attention from the outside world.
Domestic large models are in a similar situation; over a hundred companies are developing them, and they should focus on the “emergence” of GPT. Even if some domestic large models have limitations in funding and hardware conditions, and their scales are not very large, exploring the characteristics of the models can still be beneficial, potentially accelerating the occurrence of emergence. There is no need to overly focus on the flaws of domestic large models; these are unavoidable and may stem from various reasons, such as insufficient corpus preparation, inadequate training time, or algorithmic issues. By establishing a research framework for large models and exploring the details of “emergence,” there will always be gains.
Regarding the application ecology of large models, understanding the emergence characteristics of GPT may evoke different feelings. Large models should not be treated merely as chatbots, as this limits imagination. The diverse capabilities that GPT has emerged, including reasoning, mathematics, information compression, multimodal capabilities, and content generation, open up entirely new research architectures. Much like deep learning, it serves as both an exploratory framework and an application architecture.
American IT companies are attempting to transform the entire software system using GPT. Major companies will continue to expand the scale of GPT in a manner akin to an arms race. A more common behavior is to develop toolchains that enable the application of GPT, allowing developers to engage in various industries. This latter aspect is a field that China should learn from and has advantages in.
Regarding the foundational capabilities of domestic large models, I am not worried. For example, iFLYTEK’s Spark Large Model 3.0 is assessed to be close to the level of ChatGPT, and they are preparing to launch Spark AI 4.0, which is close to GPT-4, in May 2024. Large model assessments are an important research field, and standards are not yet unified; however, it is evident that the capabilities of domestic large models are rapidly improving, with the gap with the U.S. being just about two years.
If the quality of responses from domestic large models is not as good as that of ChatGPT or GPT-4 for a particular question, public opinion will pay close attention. However, the focus should be on “emergence.” If the R&D structure of Chinese companies can foster various types of emergence, then essentially, China and the U.S. are competing on the same track. Perhaps American large models have achieved level 4 emergence, while China can only achieve level 3, and American companies have eliminated more bugs, making the gap appear significant. As Chinese companies delve deeper into the research of “emergence,” the gap will close.
The truly impactful factor is the application ecology of large models. Without an ecology, the large model development of companies will ultimately be unsustainable; even OpenAI finds the development and operation of large models too costly. If Chinese companies can establish a large model application ecology, they can iterate development and specifically improve defects in industry applications, which is a forte of Chinese companies. Some applications can succeed; even if the foundational technology is not very strong, if they address industry pain points and promote application, the ecology can develop, which in turn enhances the foundational technology.
China’s development history itself has been a continuous process of “emergence”. After 2000, numerous industrial miracles in China have emerged. Since 2013, I have been advocating for Hefei, the capital of Anhui Province, which has become the fastest-growing city in the world, with its GDP increasing 37 times compared to 2000. Initially, it had no particular industrial features but has emerged multiple trillion-yuan industrial clusters, such as new displays, integrated circuits, and new energy vehicles.
Even after years of advocacy, I am still continually amazed by the development of Hefei and Anhui. For instance, Anhui’s automobile production reached 2.491 million units in 2023, becoming the second in the country (with Guangdong far ahead). This year’s general artificial intelligence competition was held in Wuhu, where local company Chery produced 1.88 million cars in 2023, with both domestic brands and exports experiencing explosive growth, aiming for 4 million units in 2024. Hefei’s production of new energy vehicles reached 255,000 units in 2022, a year-on-year increase of 133%, and 746,000 units in 2023, another increase of 140%. Hefei has a solid layout, with companies like BYD, Volkswagen, and NIO coming in, aiming for 2 million units of new energy vehicles by 2025 and 3.4 million by 2027!
Using GPT as an analogy, China’s development mechanism changed after the reform to a Transformer (which inherently means transformation), leading to unbelievable industrial “emergence.”
Understanding GPT’s “emergence” helps clarify the U.S. government’s suppression of Chinese artificial intelligence, even prohibiting the sale of 4090 graphics cards. It becomes clear that the U.S. government is betting, believing that general artificial intelligence will have significant breakthroughs. U.S. Commerce Secretary Raimondo has said outright that they aim to slow down China’s artificial intelligence development.
However, China is already prepared, with companies like Huawei and iFLYTEK becoming the vanguard in the battle of artificial intelligence against the U.S. iFLYTEK, placed on the U.S. Entity List, has spent half a year adapting to domestic GPUs, leading the nation in this regard. Huawei Cloud has built three major AI computing power centers, one of which is in Wuhu, Anhui.
Industrial development has inertia; those that have already achieved industrial “emergence” have advantages in planning and implementing new emerging industrial policies. Regarding the development of general artificial intelligence, I similarly wish and have confidence in Anhui.
Chen Jing,obtained a Bachelor’s degree in Computer Science from the University of Science and Technology of China, a Master’s degree in Computer Science from the Hong Kong University of Science and Technology, a member of the Science and Strategy Forum, and the author of “China’s Official Economy.”