
Machine Heart reported
Machine Heart Editorial Department
Can neural networks complete various tasks without learning weights? Are the image features learned by CNN just what we think they are? Are neural networks merely combinations of functions with no other meaning? From this paper, the answers to these questions seem to be affirmative.
Yesterday, a paper titled “Weight Agnostic Neural Networks” by David Ha and others from Google Brain sparked a sensation in the machine learning community. Its “disruptive” theory made people exclaim: “In the end, do we know nothing about neural networks?”
Some researchers on Reddit believe that the more interesting significance of the paper “Weight Agnostic Neural Networks” lies in its proclamation that the explanation of deep learning’s hierarchical coding features has come to an end.
Typically, weights are thought to be trained to represent intuitive features like edges and curves in MNIST. If the algorithms in the paper can handle MNIST, then they are not features but sequences/combinations of functions. This could be a blow to AI interpretability.
It is easy to understand that neural network architectures are not “born equal”; for certain tasks, the performance of some architectures is significantly better than that of others. But how important are the neural network weight parameters compared to the architecture?
A new study from Bonn-Rhein-Sieg University of Applied Sciences in Germany and Google Brain proposes a neural network architecture search method that can perform various tasks without explicit weight training.
To evaluate these networks, the researchers used a single shared weight parameter sampled from a uniform random distribution to connect network layers and assess expected performance. The results showed that this method could find a small number of neural network architectures that could perform multiple reinforcement learning tasks or supervised learning tasks like MNIST without weight training.
Here are two examples of neural networks that do not require weight learning: a bipedal walking agent (top) and a racing car (bottom):


Why Neural Networks Do Not Need to Learn Weights
In biology, precocial species refer to those young organisms that are born with some innate abilities. There is much evidence that animals like lizards and snakes instinctively know how to evade predators, and ducklings can learn to swim and feed themselves shortly after hatching.
In contrast, when training agents to perform tasks, we typically choose a standard neural network framework and believe it has the potential to encode specific strategies for the task. Note that this is only “potential”; we still need to learn weight parameters to transform this potential into capability.
Inspired by the precocial behaviors and innate abilities found in nature, the researchers constructed a neural network that can “naturally” perform a given task. In other words, they found an innate neural network architecture that can perform tasks using only randomly initialized weights. The researchers stated that this neural network architecture, which does not require learning parameters, performs well in both reinforcement learning and supervised learning.
In our understanding, if we imagine that the neural network architecture provides a circle, then conventional weight learning is akin to finding an optimal “point” (or optimal parameter solution). However, for neural networks that do not require weight learning, it introduces a very strong inductive bias, such that the entire architecture is biased toward directly solving a specific problem.
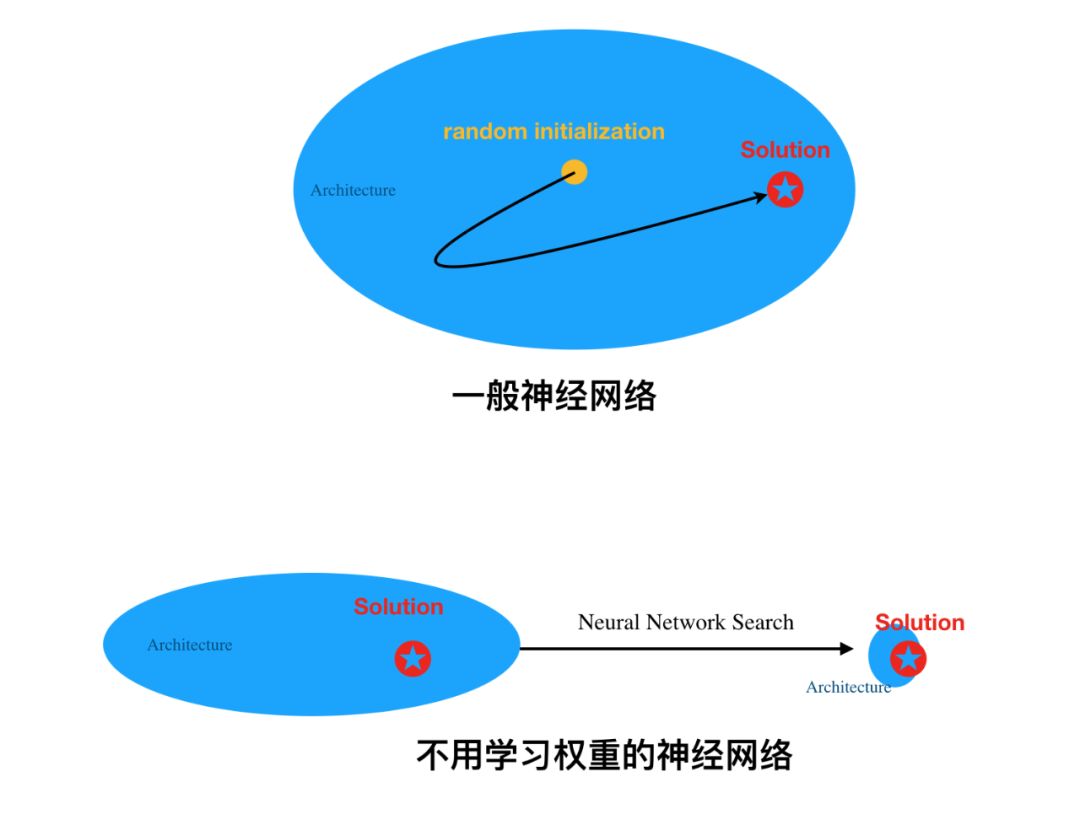
As mentioned above, our intuitive understanding of the two types of networks is as follows. General neural networks randomly initialize weights within the architecture, then learn weights to find the optimal solution, allowing the model to complete specific tasks. As long as the architecture is sufficiently “large”, it is likely to contain the optimal solution, and gradient descent can roughly find it.
However, for neural networks that do not require weight learning, it is equivalent to continuously specializing the architecture, or reducing model variance. Thus, when the architecture becomes smaller and contains only the optimal solution, randomized weights can solve practical problems. Of course, as researchers have done, searching from small architectures to large architectures is also feasible, as long as the architecture can precisely surround the optimal solution.
There Have Been Lazy Neural Networks Before
Decades of neural network research have provided strong inductive bias building blocks for different tasks. For example, convolutional neural networks are particularly suitable for processing images.
Ulyanov et al. [109] demonstrated that randomly initialized CNNs can be used as handcrafted priors in standard inverse problems (such as denoising, super-resolution, and image restoration) with superior performance.
Schmidhuber et al. [96] showed that randomly initialized LSTMs with learned linear input layers could predict sequences, whereas traditional RNNs could not. Recent research in self-attention [113] and capsule networks [93] has expanded the range of building blocks for creating architectures suitable for multiple tasks.
Inspired by randomly initialized CNNs and LSTMs, this research aims to search for weight-agnostic neural networks, which are networks with strong inductive bias that can perform different tasks using random weights.
Core Idea
To find neural network architectures with strong inductive bias, the researchers propose searching architectures by reducing the importance of weights. The specific steps are: 1) provide a single shared weight parameter for each network connection; 2) evaluate the network over a large range of weight parameter values.
The study did not adopt the approach of optimizing fixed network weights but instead optimized architectures that perform well across a wide range of weight values. The researchers demonstrated that this method could generate networks that perform different continuous control tasks using random weight parameters.
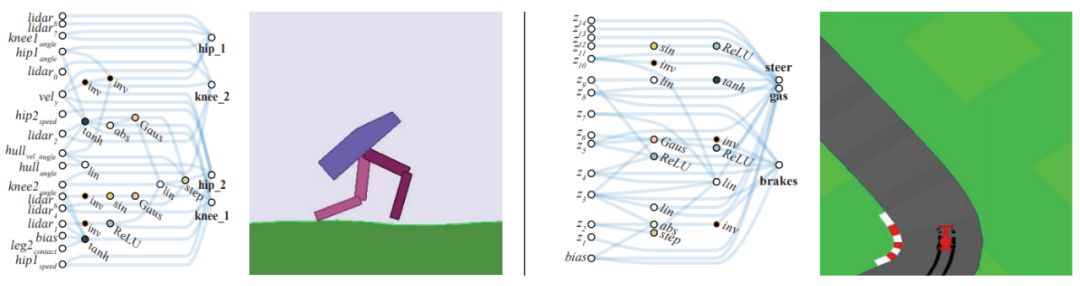
Figure 1: Weight-agnostic neural network example: bipedal walking agent (left), racing car (right). The researchers search architectures by reducing the importance of weights. The networks use a single shared weight value. All architectures perform optimization over a wide range of weight values while still being able to execute different tasks without weight training.
Weight-Agnostic Neural Network Search
Creating network architectures that encode solutions is fundamentally different from the problems solved by neural architecture search (NAS). The goal of NAS technology is to generate architectures that can outperform human-designed architectures after training. No one has ever claimed that the solution is inherent to that network architecture.
To generate architectures that can encode solutions, the importance of weights must be minimized. When assessing network performance, the researchers did not choose networks with optimal weight values but instead sampled weight values from a random distribution. Replacing weight training with weight sampling ensures that performance is only related to network topology.
However, due to high dimensionality, reliable sampling of weight space is not feasible across all networks except for the simplest ones. Although dimensionality issues hinder researchers from efficiently sampling high-dimensional weight spaces, performing weight sharing across all weights reduces the number of weight values to 1.
Systematically sampling a single weight value is very simple and efficient, allowing us to approximate network performance with just a few trials. This approximation can then be used to search for better architectures.
Main Process
The process of searching for weight-agnostic neural networks (WANN) is as follows:
-
Create an initial group of minimal neural network topologies;
-
Evaluate each network over multiple rollouts, assigning a different shared weight value to each rollout;
-
Rank them based on network performance and complexity;
-
Create new groups by altering the top-ranked network topologies, selected probabilistically via tournament selection.
Next, the algorithm repeats from (2), generating increasingly complex weight-agnostic topologies that outperform previous generations.
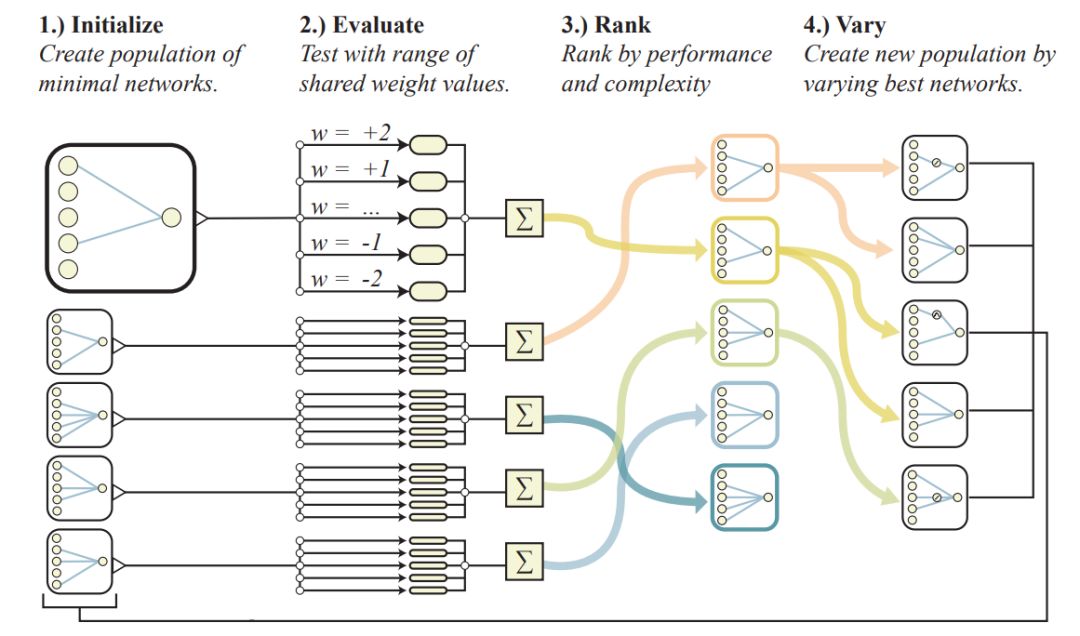
Figure 2: Illustration of weight-agnostic neural network search.
By sampling a single shared weight during each rollout, weight-agnostic neural network search explores the space of neural network topologies while avoiding weight training. Researchers evaluate networks based on multiple rollouts, assigning corresponding values to a single shared weight during each rollout and recording cumulative rewards during the experiment.
Then, they rank the network groups based on performance and complexity. The top-ranked networks are then selected probabilistically to generate new groups, with the top-ranked networks being randomly varied. This process is then repeated.
The Core Topology Search
The operators used for searching neural network topologies are inspired by the Neuroevolution of Augmenting Topologies (NEAT). However, in NEAT, topologies and weight values are optimized simultaneously, while this study ignores weights and only uses topology search operators.
The initial search space includes multiple sparsely connected networks, networks without hidden nodes, and networks with only a few possible connections between input and output layers. One of the three operators—insert node, add connection, or change activation—is used to modify existing networks to create new networks. The activation function of new nodes is randomly assigned.
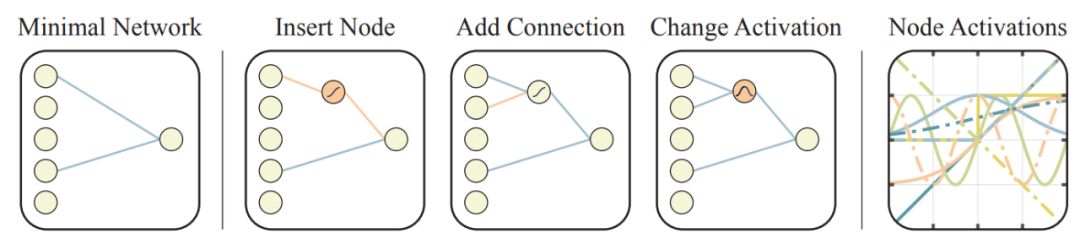
Figure 3: Operators for searching the network topology space.
Given the feedforward nature of networks, new connections are added between previously unconnected nodes. When the activation function of hidden nodes is changed, it enters a random assignment mode. Activation functions include common functions (like linear activation, sigmoid, ReLU) and less common ones (like Gaussian, sinusoid, step), encoding various relationships between inputs and outputs.
Experimental Results
The study evaluates weight-agnostic neural networks (WANN) on three continuous control tasks: CartPoleSwingUp, BipedalWalker-v2, and CarRacing-v0. The researchers created weight-agnostic network architectures based on standard feedforward network strategies commonly used in previous studies, selecting the best WANN architecture for average performance comparison (100 trials).
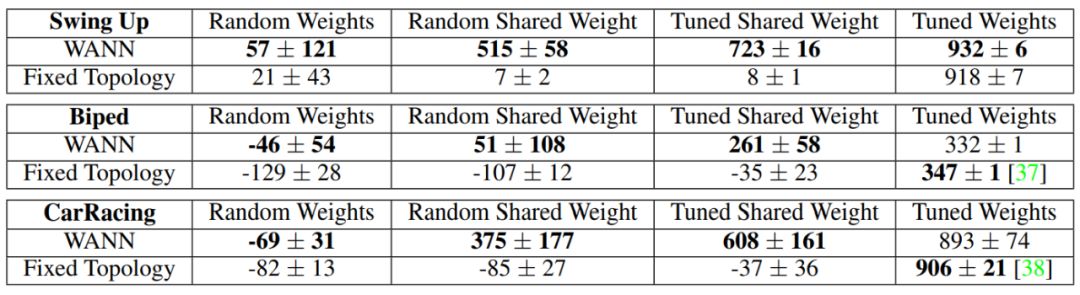
Table 1: Performance of randomly sampled networks and networks using weight training on continuous control tasks.
Traditional fixed topology networks can only generate useful behavior after extensive parameter tuning, while WANN can perform tasks using randomly shared weights.
Due to the small size of WANN, it is easy to explain, so we can examine the following network diagram to understand how it works.
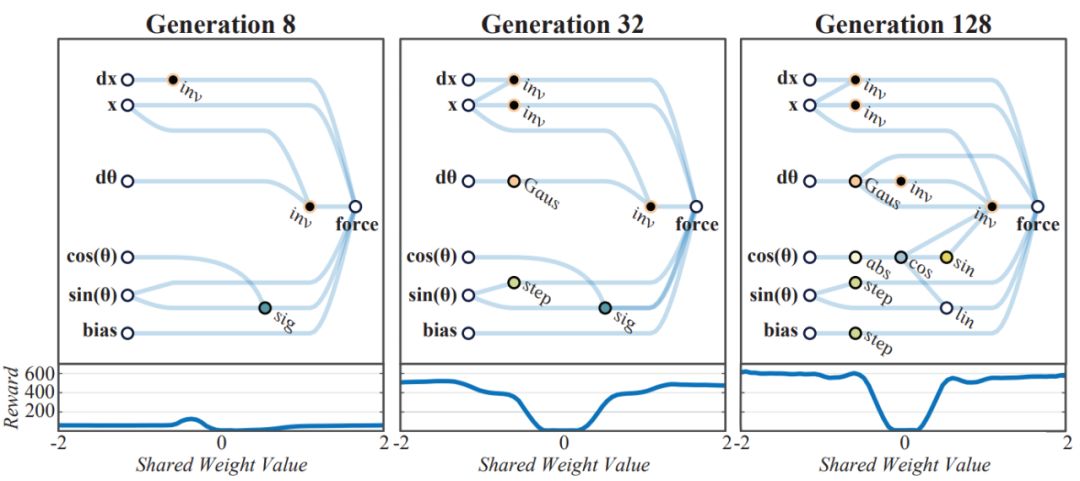
Figure 4: Weight-agnostic topology changes over time. Generation 128: Adding complexity to improve the balance action of the cart.
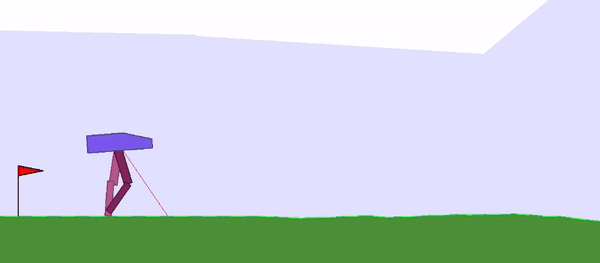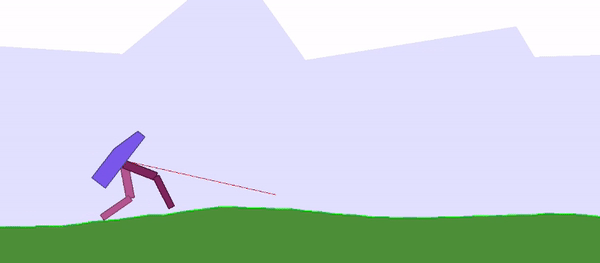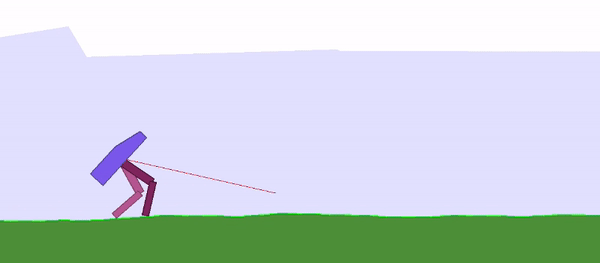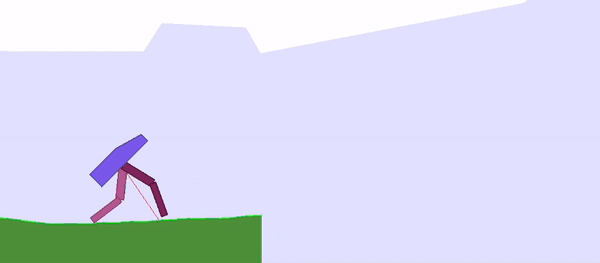
The model ultimately achieved the best performance on the BipedalWalker-v2 task.

The model ultimately achieved the best performance on the CarRacing-v0 task.
What About Supervised Classification Problems?
The results of the WANN method on reinforcement learning tasks lead us to ponder what other problems it can be applied to? WANN can encode relationships between inputs, making it very suitable for reinforcement learning tasks: low-dimensional inputs combined with internal states and environmental interactions allow for the discovery of reactive and adaptive controllers.
However, classification problems are not as ambiguous; they are clearly defined—right is right, and wrong is wrong. As a proof of concept, the researchers investigated the performance of WANN on the MNIST dataset.
Even in high-dimensional classification tasks, the WANN method still performs very well (as shown in Figure 5 left). Although limited to a single weight value, the WANN method can classify MNIST digits, with performance comparable to single-layer neural networks with thousands of weights (weights trained via gradient descent). The created architecture still retains the flexibility required for weight training, further enhancing accuracy.
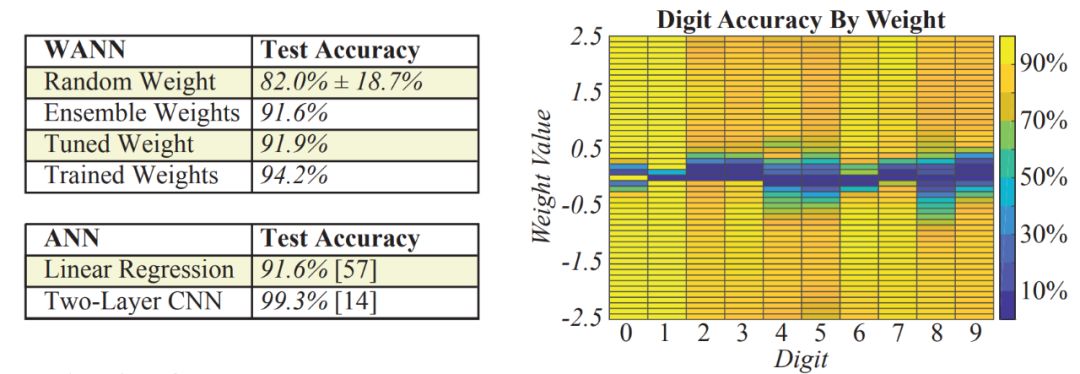
Figure 5: Classification accuracy on the MNIST dataset.
Left: WANN instantiated with multiple weight values performs much better than networks with random weight sampling, and its performance is equivalent to that of a linear classifier with thousands of weights. Right: There is no single weight value that has a higher accuracy across all digits. WANN can be instantiated as multiple different networks, allowing for the possibility of creating ensembles.
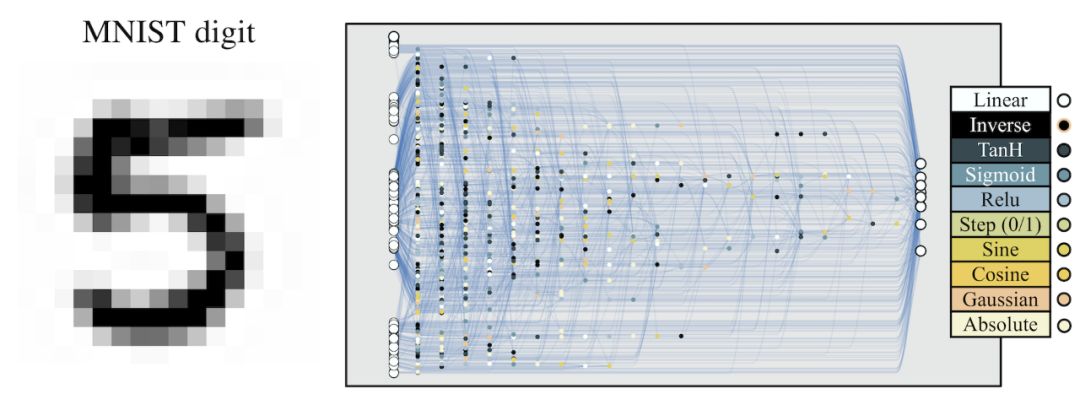
MNIST classification network evolves to use random weights.
Author Biography
The first author of this paper, ADAM GAIER, is currently conducting doctoral research at Bonn-Rhein-Sieg University of Applied Sciences in Germany and the National Institute for Research in Computer Science and Automation (INRIA) in France. He joined Google Brain in January 2019 as a Research Intern.

ADAM GAIER
From his resume, he has strong connections with China. From January 2010 to June 2011, he served as the head of computer science at Tsinghua International School.

David Ha
The second author, David Ha, is a research scientist at Google Brain, primarily working on machine intelligence. He has published papers as the first author or as a contributor at top conferences multiple times. Machine Heart has previously reported on a paper he authored titled “World Models” (see: Simulating Worlds: Google Brain and Jürgen Schmidhuber Propose “AI Dreams”).
References:https://arxiv.org/abs/1906.04358
https://www.reddit.com/r/MachineLearning/comments/bzka5r/r_weight_agnostic_neural_networks/

Shibei · GMIS 2019The Global Data Intelligence Summit will be held from July 19-20 in Jing’an District, Shanghai. This summit focuses on the theme of “Data Intelligence”, highlighting cutting-edge research directions and paying more attention to the development of the data intelligence economy and its industrial ecosystem, providing references for technology from research to implementation.
This summit includes keynote speeches, thematic talks, an AI art exhibition, the release of the “AI00” data intelligence list, a closed-door dinner, and the following confirmed guests:

The conference’s early bird tickets are now on sale, and we have also prepared the highest discount for student users. Click Read the original text to register immediately.