
This year’s Nobel Prize in Physics was awarded to AI pioneer Hinton, whose major contribution is the invention of a new neural network – the Boltzmann machine, which has shone brightly in the field of machine learning.
So what is a neural network? The essence of the large models that have been popular in recent years is it. Today, I will explain this neural network in simple terms.
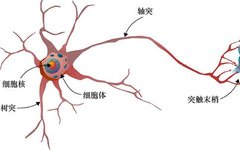
A neural network did not arise out of nowhere; its inspiration comes from the neurons in the brain. Neurons are responsible for transmitting information, and their general structure is as follows:
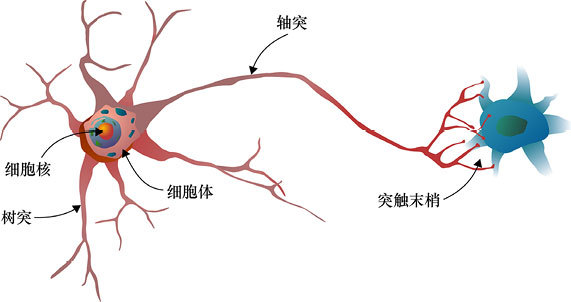
You just need to remember three points: Dendrites receive signals; Axons transmit signals; Synapses release signals. From dendrites to synapses, one by one, the neurons are activated, transmitting information to each other.
In the field of machine learning, we can also create our own neuron, the simplest neuron is the perceptron.
The principle of the perceptron is very simple, see the diagram below:
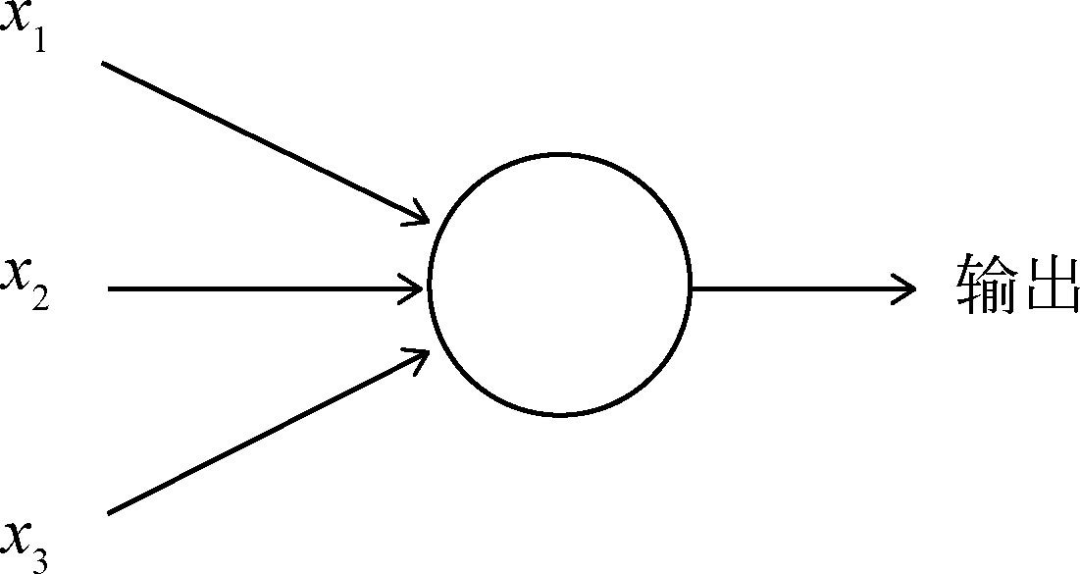
Give a few inputs, and you get an output; this model is called a perceptron. Its output generally has two values – 0 and 1, and which value is output depends on a threshold. If it is less than or equal to the threshold, it outputs 0; if it is above the threshold, it outputs 1. How is this threshold obtained? By assigning different weights to the inputs and finally deriving the weighted sum.
You may ask, now I know the principle, but what is its use?
For example, if you want to buy a house, the final result is either buying or not buying. You will score various factors affecting the purchase (transportation, amenities, environment, etc.) and assign them different weights, then judge based on the results – if it is above a certain score, you buy; if below, you do not buy.
This decision-making is the application of the perceptron.
Of course, in reality, there are many perceptrons, and the output is not just two, as shown below:
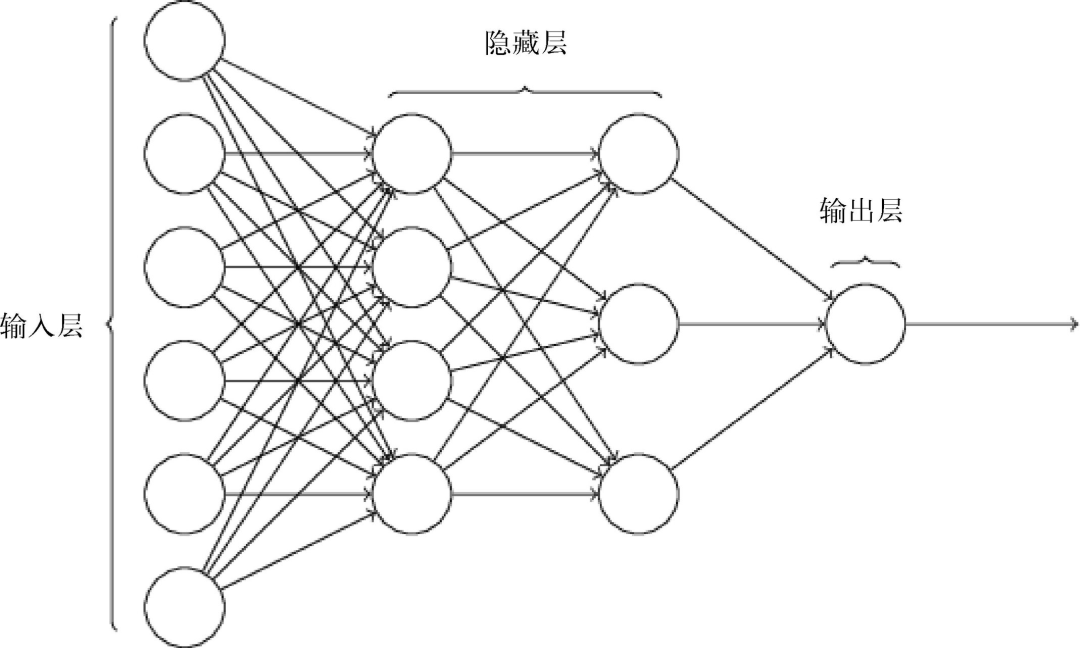
From input to output, there may be many layers in between, each layer taking the output of the previous layer as the input for this layer. You see, doesn’t this resemble how neurons in the brain transmit information?
From a distance, it looks like a big net, and we give it a new name, called multilayer neural networks.
What is the use of multilayer neural networks? The simplest example is recognizing handwritten characters. For instance, if you are given an image with various handwritten fonts, you want the computer to recognize them all:
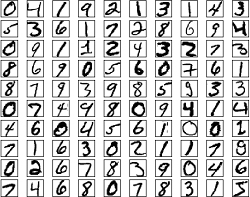
So what do we do? We know that images are made up of pixels. If we enlarge one of the handwritten characters, it looks like this:

You can see that the small squares inside are pixels.
We treat these pixels as inputs; the number of pixels corresponds to the number of inputs, and then through the layers of calculations in the neural network, we finally output a number between 0 and 9.
As for how to calculate specifically, you don’t need to worry about the mathematical details; it ultimately also judges based on thresholds or probabilities.
This is the principle of neural networks. Generally, the more layers there are, the more accurate the output result. However, the computational cost also increases, so you need to balance cost and effectiveness.
As for the significance of the results from so many layers in between, you may not know, and even those neural network experts do not know; you just need to let it adjust itself.
A neural network is a black box; you give some inputs, adjust it a few times, and you will get the results you desire.
Because it is a black box, it has raised concerns among many people, fearing that it will develop intelligence beyond humans and dominate humanity.
I am an AI optimist; let’s not talk about how far it is from the stage of general artificial intelligence; even if it reaches that point, I believe that humanity will not sit idly by and let AI take over.
I am Wang Dayou, an official book reviewer. The Wang Group welcomes you:
The Wang Group is recruiting!
Add me on WeChat, and I will send you a nice gift:
