
Original Title: An Intuitive Introduction to Generative Adversarial Networks
Authors: Keshav Dhandhania, Arash Delijani
Translation: Shen Libin
Proofreading: He Zhonghua
This article is about 4000 words and is recommended to be read in 10 minutes. The article introduces the GAN model through the problem of image generation, discusses the mathematical principles and training process of GANs, and finally provides a wealth of learning resources for GANs.
This article discusses Generative Adversarial Networks, abbreviated as GANs. In generative tasks or more broadly in unsupervised learning, GANs are one of the few machine learning techniques that perform well in this field. In particular, they excel in tasks related to image generation. Deep learning pioneer Yann LeCun praised GANs as the best idea in machine learning in the last decade. Most importantly, the core concepts related to GANs are easy to understand (in fact, after reading this article, you will have a clear understanding of them).
We will apply GANs to image generation tasks and explain GANs through this context. Below is an overview of this article:
-
Brief Review of Deep Learning
-
Image Generation Problem
-
Key Issues in Generative Tasks
-
Generative Adversarial Networks
-
Challenges
-
Further Reading
-
Summary
Brief Review of Deep Learning
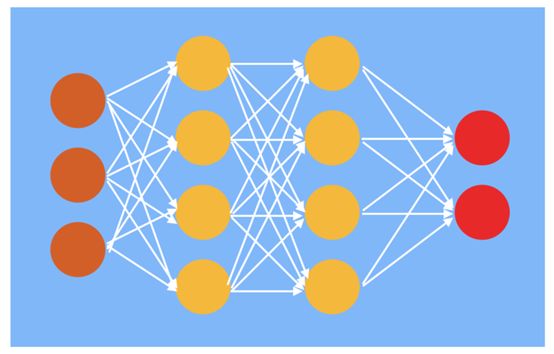
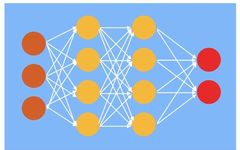
(Feedforward) Neural Network Diagram, with brown as the input layer, yellow as the hidden layer, and red as the output layer
Let’s start with a brief introduction to deep learning. The image above is a diagram of a neural network, which is composed of neurons connected by edges, arranged in layers, with the hidden layer in the middle, and the input and output layers on either side. Each connection between neurons has a weight, and each neuron computes a weighted sum of the input values from the connected neurons, which is then passed through a nonlinear activation function. Common activation functions include Sigmoid and ReLU. For example, the first hidden layer neuron computes the weighted sum of values from the input layer neurons and then applies the ReLU function. The activation function introduces non-linearity, allowing the neural network to model complex phenomena (multiple linear layers are equivalent to a single linear layer).
Given a specific input, we compute the output values of each neuron (also known as the neuron’s activation) sequentially. From left to right, we use the values computed from the previous layers to calculate each layer, ultimately obtaining the output layer’s values. We then define a loss function based on the output layer’s values and the desired values (target values), such as the mean squared error loss function.
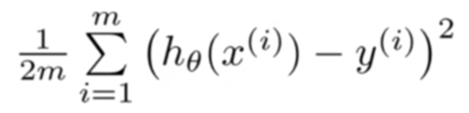
Where x is the input, h(x) is the output, and y is the target value, with the sum including all data points in the dataset.
In each step, our goal is to optimize the weights of each edge with appropriate values to minimize the size of the loss function as much as possible. We calculate the gradient values and then use the gradient to specifically optimize each weight. Once we calculate the loss function value, we can use the backpropagation algorithm to compute the gradients. The main result of the backpropagation algorithm is: using the chain rule and the gradient values of the parameters from the subsequent layer to compute the gradients of the current layer. Then, we update each weight proportionally to the respective gradient (i.e., gradient descent).
If you want to learn more about the details of neural networks and the backpropagation algorithm, I recommend reading Nikhil Buduma’s Deep Learning in a Nutshell http://nikhilbuduma.com/2014/12/29/deep-learning-in-a-nutshell/
Image Generation Problem
In the image generation problem, we want the machine learning model to generate images. To train the model, we obtain an image dataset (for example, 1,000,000 images downloaded from the internet). During testing, the model can generate images that look like they belong to the training set, but are not actually images from the training set. In other words, we want to generate new images (as opposed to simply memorizing), but still capture the patterns from the training dataset so that the new images feel similar to the training dataset.
Image Generation Problem: No input, the required output is an image
It is important to note that during the testing or prediction phase, there is no input for this problem. Each time we “run the model,” we want it to generate (output) a new image. It can be said that the input will be randomly sampled from an easily sampled distribution (such as uniform distribution or Gaussian distribution).
Key Issues in Generative Tasks
The key issue in generative tasks is: what is a good loss function? Suppose you have two images generated by a machine learning model, how do we decide which one is better, and by how much?
In previous methods, the most common solution to this problem was to calculate the distance between the output image and the nearest image in the training set, using some predefined distance metric to calculate the distance. For example, in language translation tasks, we typically have a source statement and a small set of target sentences (about 5), which are translations provided by different translators. When the model generates a translation, we compare the translation with the provided target sentences and assign a corresponding score based on which target sentence it is closest to (specifically, we use the BLEU score, which is a distance metric based on how many n-grams match between the two sentences). However, this is a single-sentence translation method, and when the target is a larger text, the same approach can severely degrade the quality of the loss function. For example, our task might be to generate a paragraph summary of a given article, and this degradation arises from the fact that a small number of samples cannot represent the range of variations observed among all possible correct answers.
Generative Adversarial Networks
GANs address the above problem by using another neural network—a scoring neural network (called the Discriminator)—which evaluates the authenticity of the images output by the generative neural network. These two neural networks have opposing objectives (adversarial); the goal of the generative network is to produce a fake image that looks real, while the goal of the discriminative network is to distinguish between fake and real images.
This sets up the generative task similarly to a two-player game in reinforcement learning (like chess, Atari games, or Go), where we have a machine learning model that continuously improves itself through self-adversarial training. In games like chess or Go, the two opposing sides are always symmetric (though not always), but in the setting of GANs, the goals and roles of the two networks are different. One network produces fake samples, while the other network distinguishes between real and fake samples.
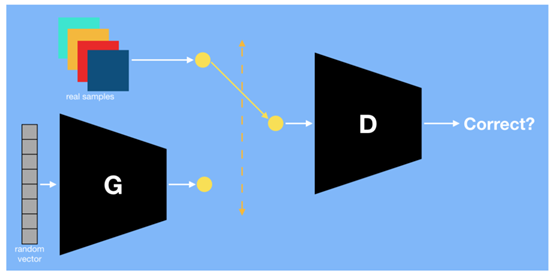
Diagram of Generative Adversarial Networks, with the generator network labeled as G and the discriminator network labeled as D
As shown in the diagram above, the generative network G and the discriminative network D are engaged in a minimax game. First, to better understand this adversarial mechanism, it is important to note that the input to the discriminative network (D) can be samples drawn from the training set or outputs from the generative network (G), but generally, 50% comes from the training set and the remaining 50% from G. To generate samples from G, we extract latent vectors from a Gaussian distribution and input them into the generative network (G). If we want to generate a 200*200 grayscale image, then the output of the generative network (G) should be a 200*200 vector. Below is the objective function, which is the standard log-likelihood function for the predictions made by the discriminative network (D).
The generative network (G) minimizes the objective function, which means reducing the log-likelihood function or “confusing” the discriminative network (D). In other words, whenever a sample is drawn from the output of the generative network (G) as input to the discriminative network (D), the goal is for the discriminative network to recognize it as a real sample. The discriminative network (D) maximizes the objective function, which means increasing the log-likelihood function or distinguishing between real and generated samples. In other words, if the generative network (G) effectively “confuses” the discriminative network (D), it will minimize the objective function by increasing the second term in the formula D(G(z)). Conversely, if the discriminative network (D) performs well, it will increase the objective function when selecting samples from the training data (because D(x) is large) and decrease it (because D(x) is small) through the second term.
Just like the usual training process, we use random initialization and backpropagation; additionally, we need to iteratively update the generator and discriminator separately. Below is a description of the end-to-end workflow for applying GANs to a specific problem:
1. Decide the GAN network architecture: What is the architecture of G? What is the architecture of D?
2. Training: A certain number of alternating updates
-
Update D (fix G): Half of the samples are real, the other half are fake
-
Update G (fix D): Generate all samples (note that even if D remains unchanged, the gradient flow will still pass through D)
3. Manually check some fake samples; if the quality is high (or quality has not improved), stop; otherwise, repeat step 2.
When both G and D are feedforward neural networks, the results we obtain are as follows (trained on the MNIST dataset)

From Goodfellow et al., starting from the training set, the rightmost column (yellow box) contains images that are closest to the images in the adjacent left column. All other images are generated samples.
Regarding G and D, we can use more complex architectures, such as using strided convolutions and the Adam optimizer instead of stochastic gradient descent. Additionally, there are other improvements, such as optimizing the architecture, using hyperparameters, and optimizers (for specifics, refer to the papers). After improvements, we obtained the following results:

Bedroom image, from Alec Radford et al.
Challenges
The most critical challenge in training GANs is the potential for non-convergence, which is sometimes referred to as mode collapse. To explain this problem simply, suppose the task is to generate digit images, like those in the MNIST dataset. A possible issue (which indeed occurs in practice) is that the generator G starts generating the digit 6 and fails to generate other digits. Once D adapts to G’s current behavior to maximize classification accuracy, it starts classifying all digit 6s as fake and all other digits as real (assuming it cannot distinguish between fake 6s and real 6s). Then G adapts to D’s current behavior and begins to generate only the digit 8 and no other digits. D then adapts again, starting to classify the digit 8 as fake and the others as real. G then starts generating only the digit 3, and so on, in a cycle. Essentially, the generator G only generates images that resemble a small subset of the training dataset, and once the discriminator D starts distinguishing this small subset from the rest, G switches to another subset, oscillating back and forth. Although this problem has not been completely solved, there are some methods to mitigate it. These methods involve minibatch features and multiple updates to D’s backpropagation. We will not discuss the details of these methods here, but for more information, please refer to the recommended reading materials in the next section.
Further Reading
If you want to delve deeper into GANs, I recommend reading the ICCV 2017 tutorials on GANs (https://sites.google.com/view/iccv-2017-gans/home), which contain many up-to-date tutorials that focus on different aspects of GANs.
I would also like to mention the concept of Conditional GANs, which generate outputs based on input conditions. For example, the task may be to output an image that matches the input description. So, when you input a dog, the output should be an image of a dog.
Below are some recent research results (with paper links).

Text to Image Synthesis results, by Reed et al.

Image Super-resolution results, by Ledig et al.

Image to Image Translation results, by Isola et al.

Generating High Resolution ‘Celebrity-like’ Images, by Karras et al.
Lastly, and most importantly, if you want to read more about GANs, please check this list of papers categorized by GAN applications: https://github.com/zhangqianhui/AdversarialNetsPapers
100+ Variants of GAN Papers List: https://deephunt.in/the-gan-zoo-79597dc8c347
Summary
Through this article, I hope you can understand a new technology in the field of deep learning—Generative Adversarial Networks. They are one of the few successful techniques in unsupervised machine learning, and this technology is rapidly transforming our ability to perform generative tasks. Over the past few years, we have seen some impressive results. GANs are being applied in language tasks, improving the stability and ease of training in language tasks, and more, making them a hot research topic. GANs are also widely used in industry, from interactive image editing, 3D shape estimation, drug discovery, semi-supervised learning to robotics. Finally, I hope this article marks the beginning of your journey into adversarial machine learning.
Original link: http://blog.kaggle.com/2018/01/18/an-intuitive-introduction-to-generative-adversarial-networks/

Shen Libin, currently a graduate student, mainly researching big data machine learning. Currently studying the application of deep learning in NLP, hoping to learn and progress with friends who are interested in big data on the THU Data Platform.
Recruitment Information for the Translation Team
Job Description: A meticulous heart is needed to translate selected foreign articles into fluent Chinese. If you are a data science/statistics/computer major student, working overseas in related jobs, or confident in your language skills, you are welcome to join the translation team.
What You Get: Regular translation training to improve volunteers’ translation skills, enhance understanding of cutting-edge data science, and overseas friends can maintain contact with domestic technological applications. The THU Data Platform’s industry-academia-research background provides good development opportunities for volunteers.
Other Benefits: You will have the opportunity to work with data scientists from well-known companies, students from top universities like Peking University and Tsinghua University, as well as overseas students who will become your partners in the translation team.
Click on the end of the article “Read the Original” to join the Data Team~
Reprinting Notice
If you need to reprint, please indicate the author and source prominently at the beginning (reprinted from: Data Platform ID: datapi), and place a prominent QR code of the Data Platform at the end of the article. For articles with original markings, please send [Article Name – Pending Authorized Public Account Name and ID] to the contact email to apply for whitelist authorization and edit according to requirements.
After publication, please feedback the link to the contact email (see below). Unauthorized reprints and adaptations will be pursued for legal responsibility.

Click “Read the Original” to embrace the organization