
The entire process requires three software:
-
Ollama. Used to run local large models. If using the API of a closed-source large model, there is no need to install Ollama. -
Docker. Used to run AnythingLLM. -
AnythingLLM. The platform for running the knowledge base, providing functions for building and running the knowledge base.
1 Install Ollama
-
Download Ollama (URL: https://ollama.com/download)
After downloading, install it directly, then open the command line window and enter the command to load the model. The command can be viewed by clicking on Models on the official website, searching for the required model, and then selecting it.
-
Input qwenin the search box
-
After selecting the model, copy the corresponding command
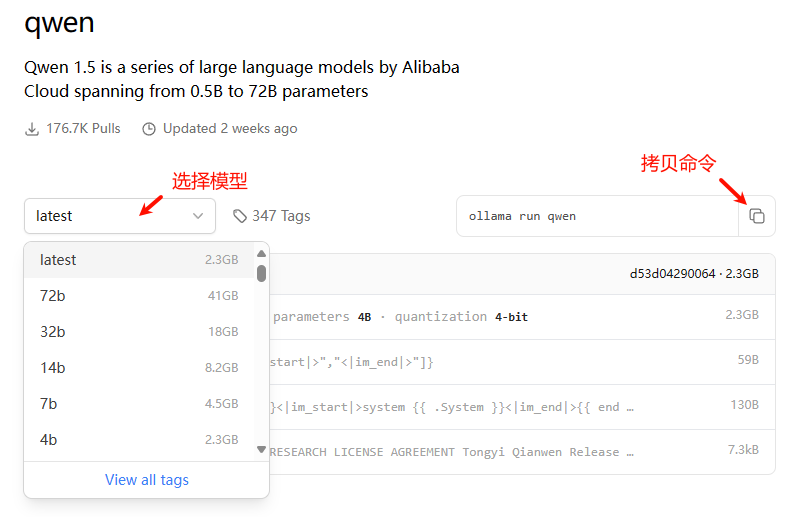
Note: Ollama supports loading and running large models in GGUF format, please check the official website for details.
”
-
Open the command line window, copy the command and run it. If this is your first time running, Ollama will automatically download and start the model. If the qwen:14b model is already installed on your machine, the model will start directly after entering the command.
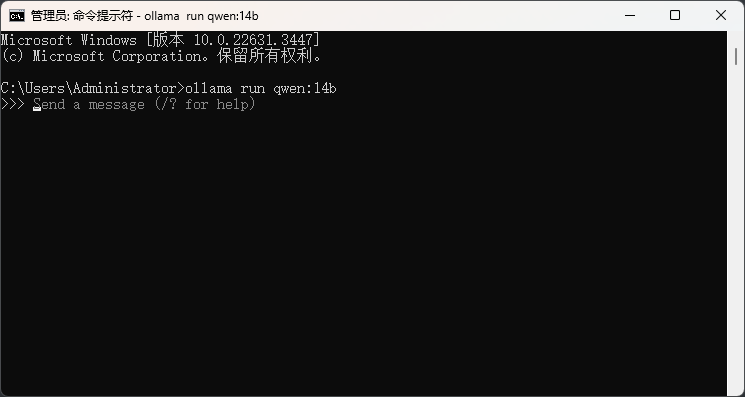
At this point, Ollama installation is complete.
2 Install Docker
Docker is an open-source application container engine that allows developers to package their applications and dependencies into a portable image, which can then be published on any popular operating system machine, thus achieving virtualization.
-
Install Docker Desktop (Download URL: https://www.docker.com/products/docker-desktop/)
After downloading, simply double-click to install. The installation process of Docker is very simple, with no parameters to set; just click next.
3 Install AnythingLLM
AnythingLLM can be installed on Docker.
-
Start Docker Desktop. The first time you start, you may need to register an account or log in directly using your Google or GitHub account. -
Click the search box at the top or use the shortcut Ctrl + Kto open the search window, enteranythingllmto search. As shown below, click the Pull button to pull the image
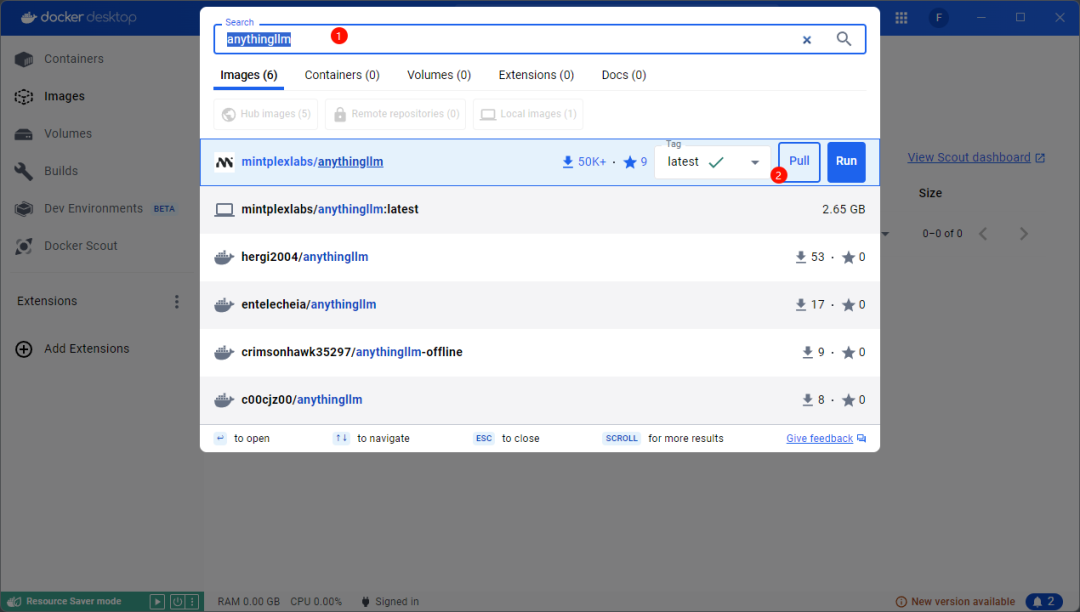
-
After the model is pulled, click Images and click the Run button next to anythingllm in the image list on the right to start the image
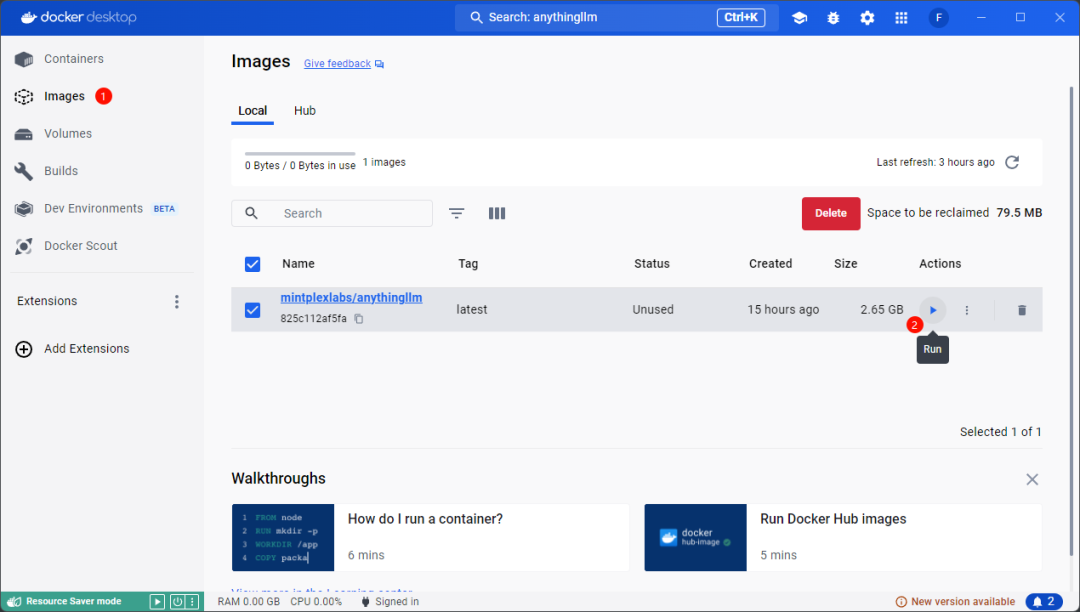
-
As shown in the figure below, enter the container name and port number. You can enter any name but it must not duplicate any existing container names or port numbers (if any).
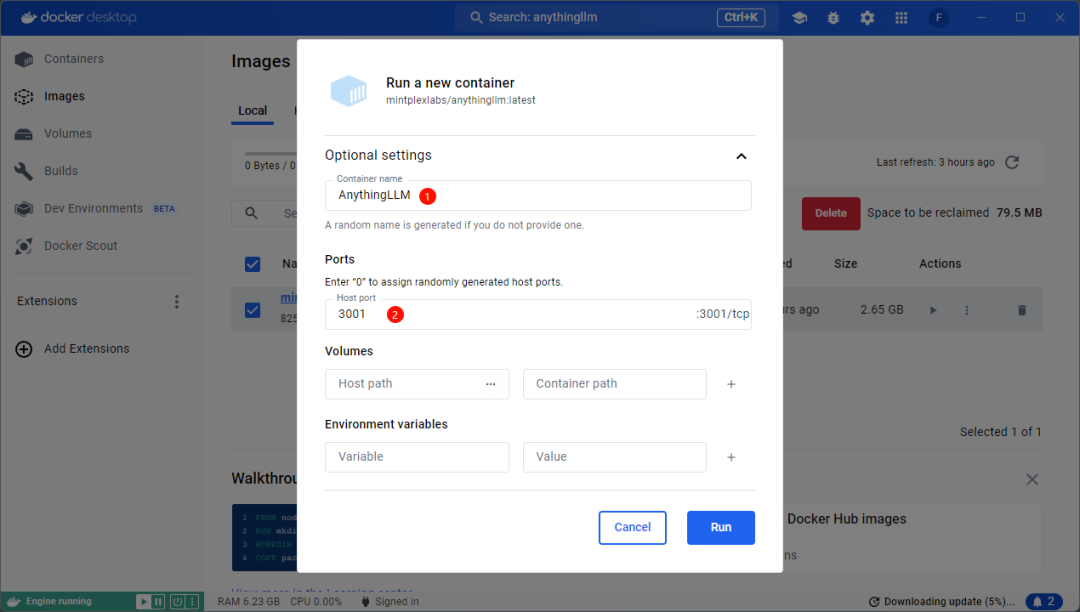
-
After the image starts, you can click the link in the position shown in the figure below, or directly enter localhost:3001in the browser to start AnythingLLM
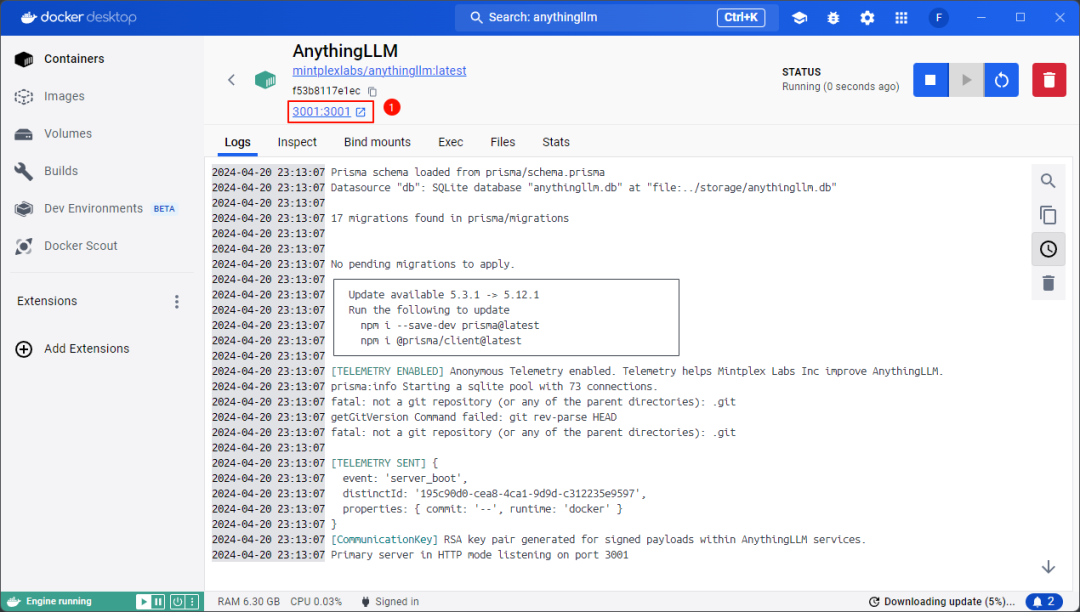
4 Configure AnythingLLM
-
Click the Get started button to enter the setup wizard interface
-
Select the large model. As shown in the figure below, set to use Ollama, then set the parameters -
Specify Ollama Base URLas http://host.docker.internal:11434 -
Specify Chat Model Selectionas qwen:14b -
Specify Token context windowas 4096
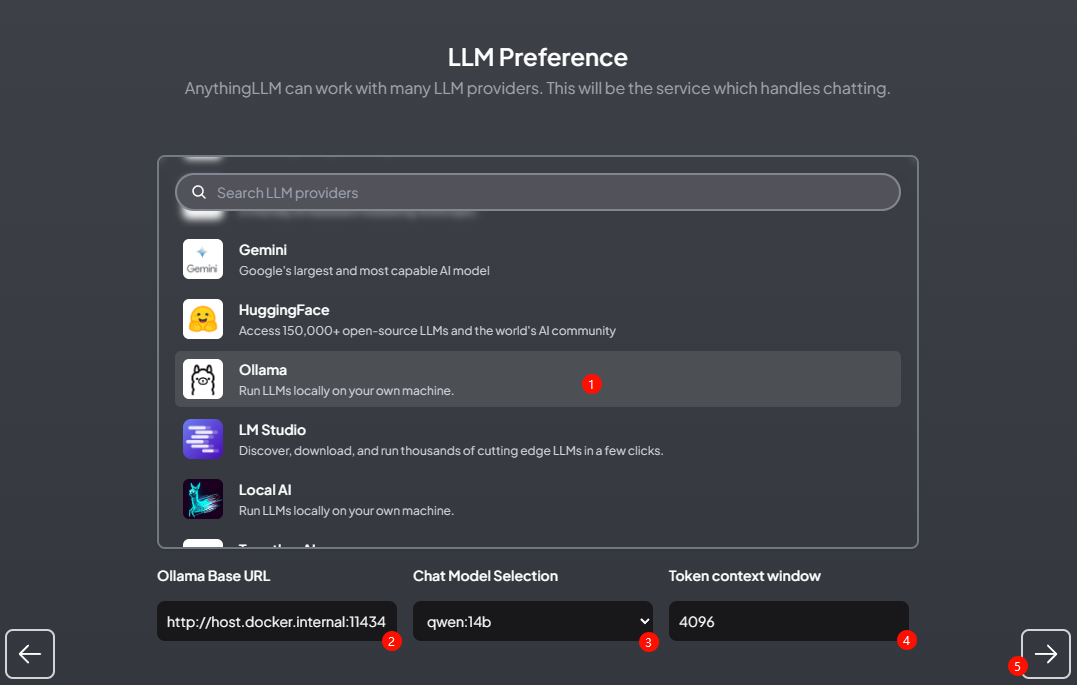
Note: AnythingLLM supports using the API of closed-source models.
”
-
Select the default AnythingLLM Embedder
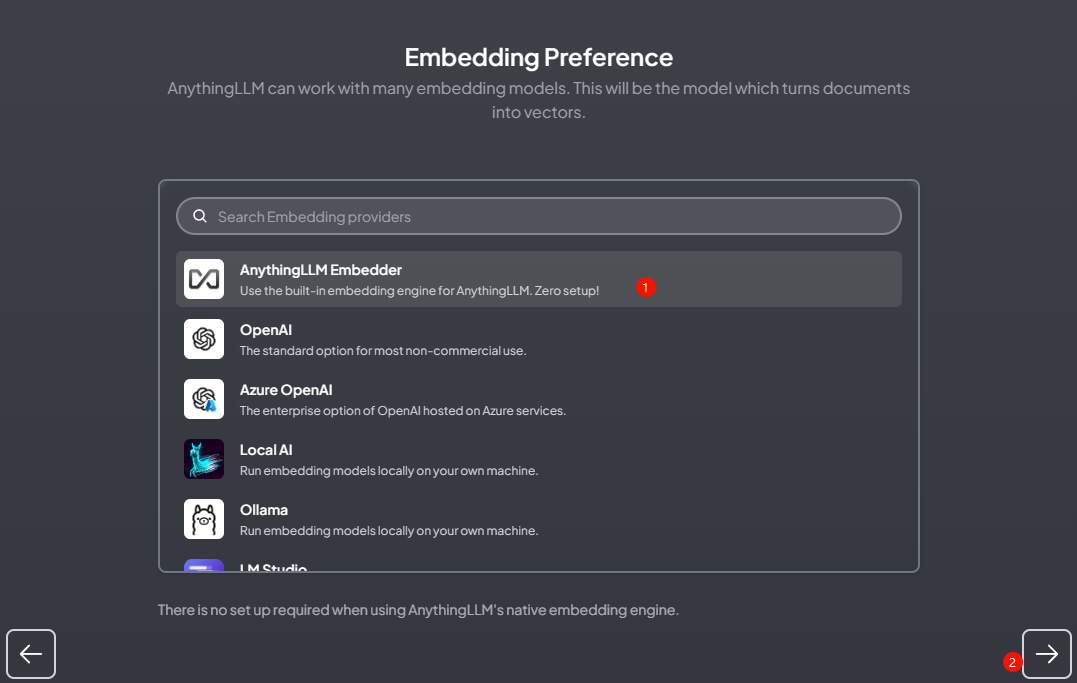
-
Select to use the default LanceDBas the vector data sink
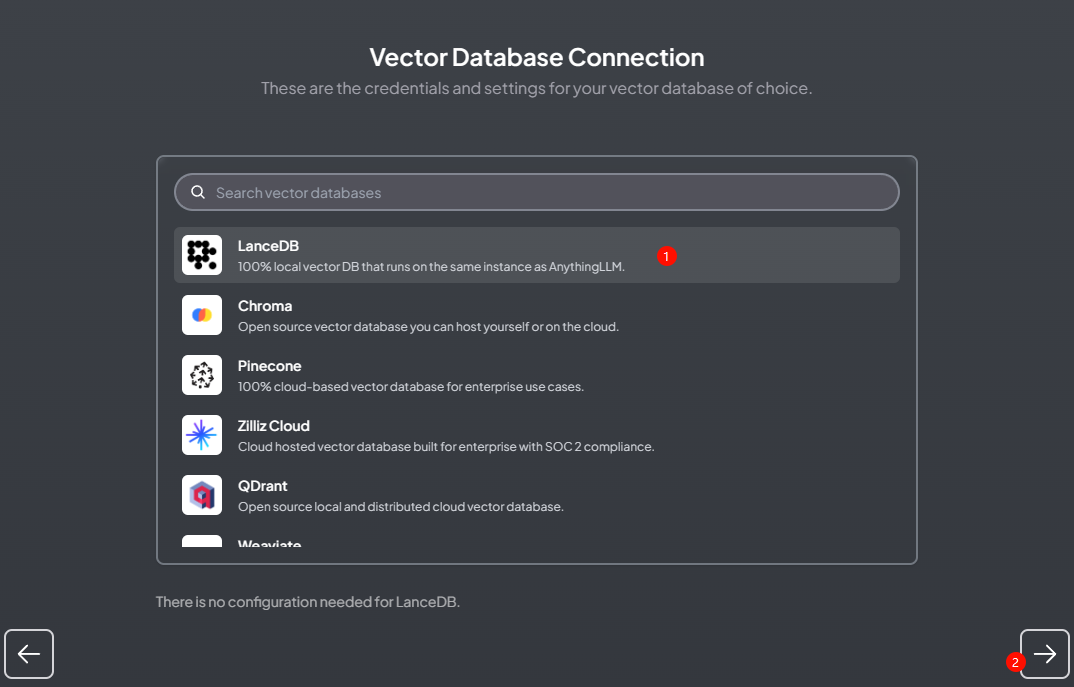
-
Set as shown in the figure below
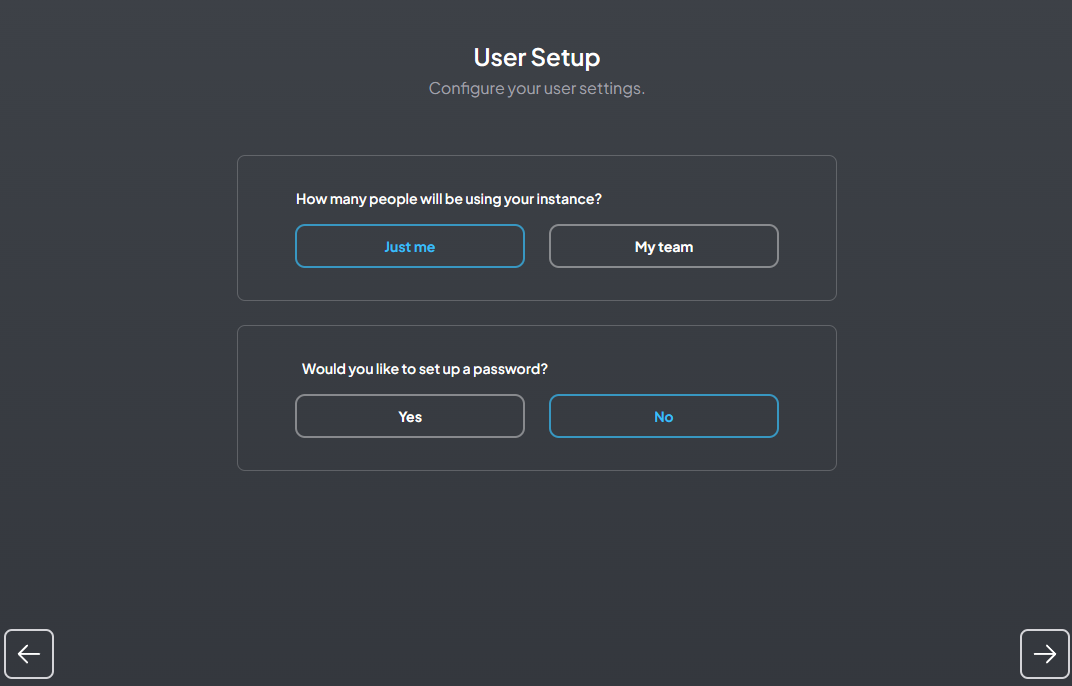
-
Check and confirm the previous settings
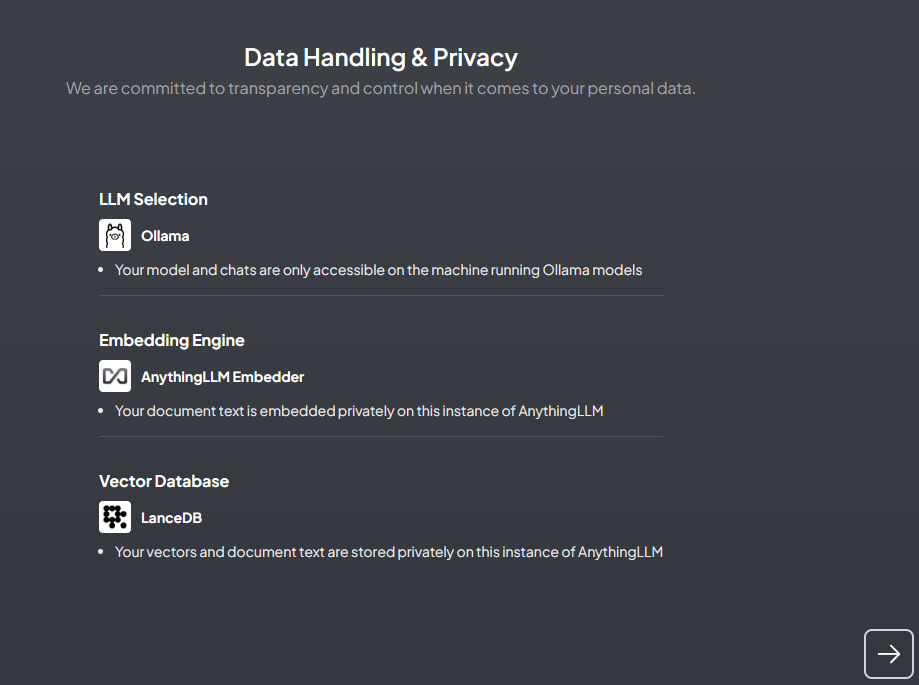
-
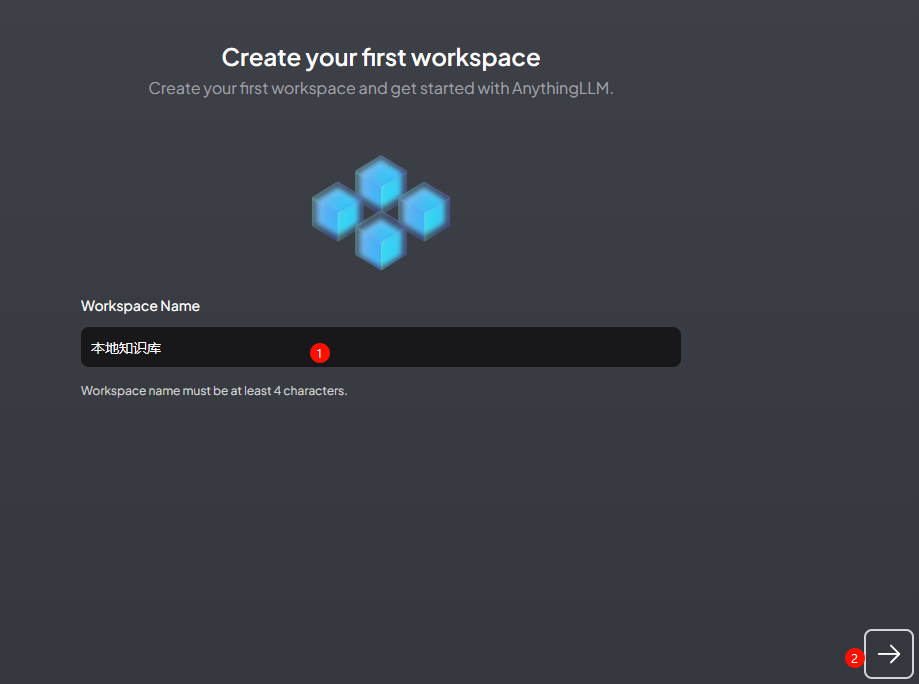
Specify a name for the workspace and proceed to the next step
-
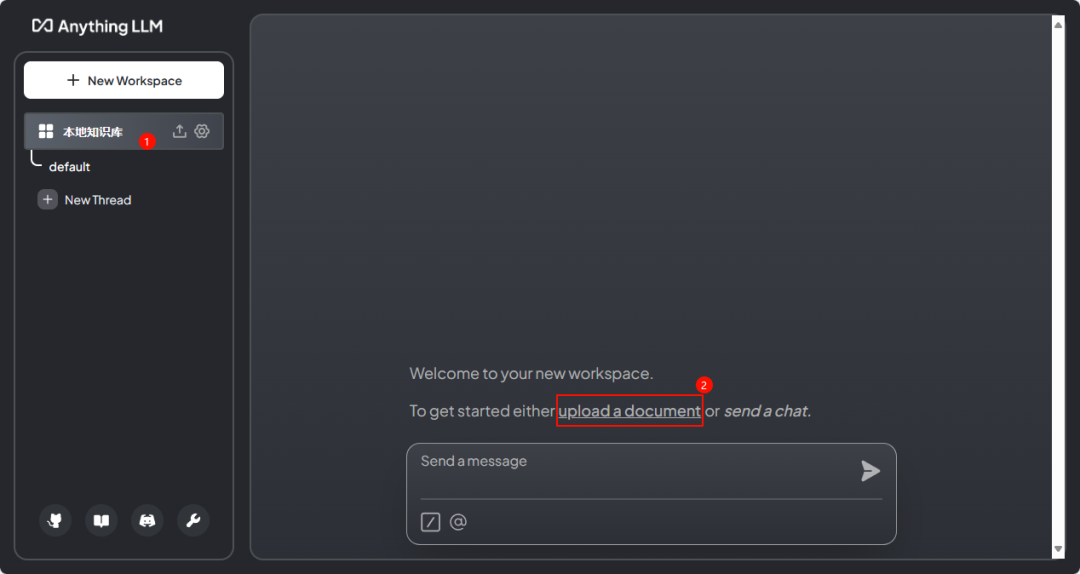
As shown in the figure below, click the link upload a documentto open the document upload interface
-
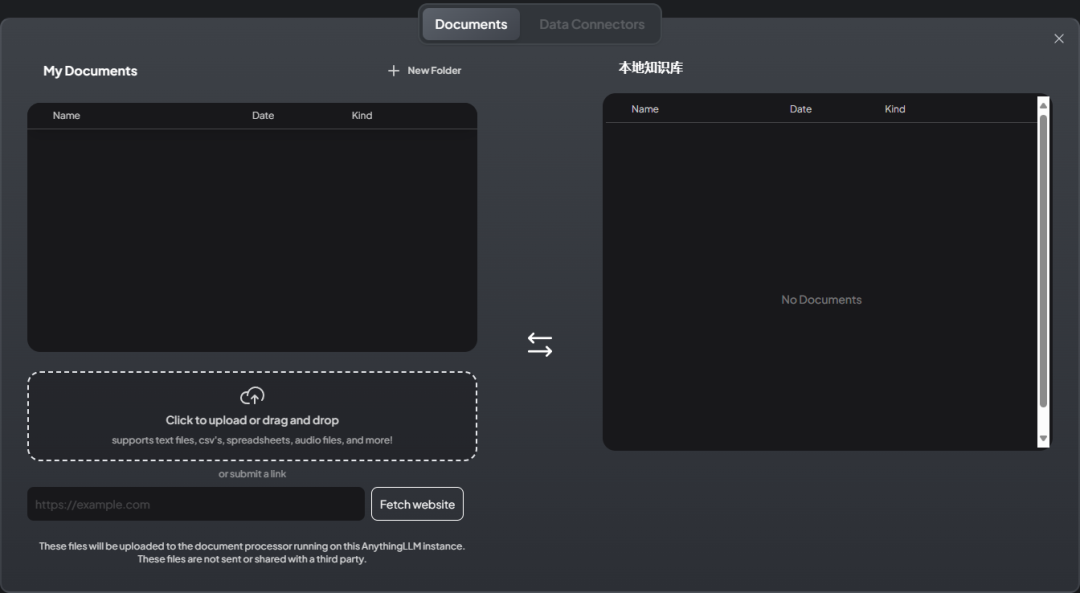
The document upload interface is as shown in the figure below
-
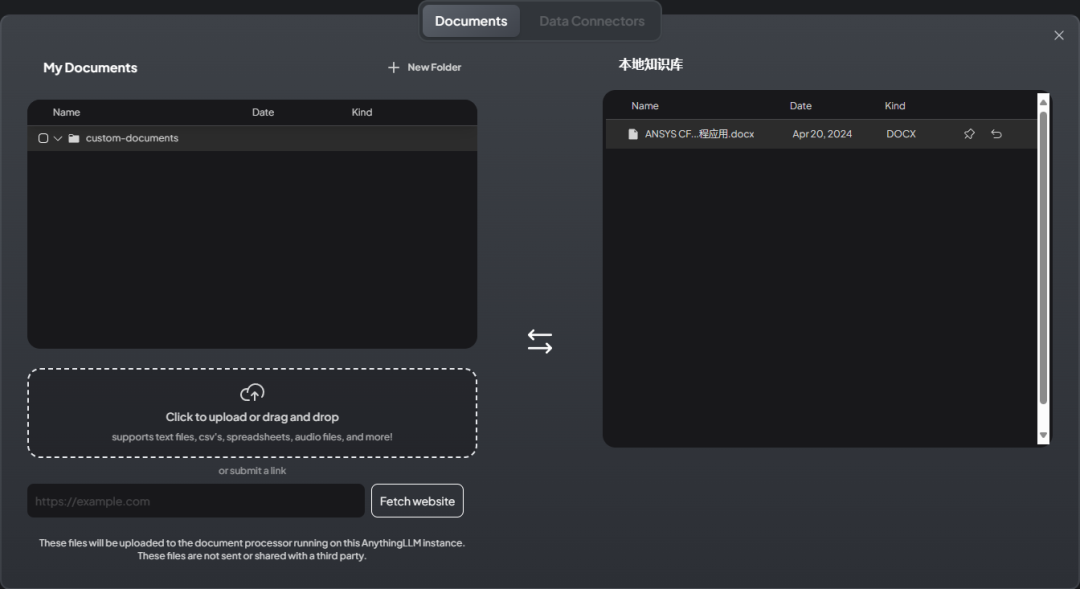
You can add your own documents and move them into the workspace
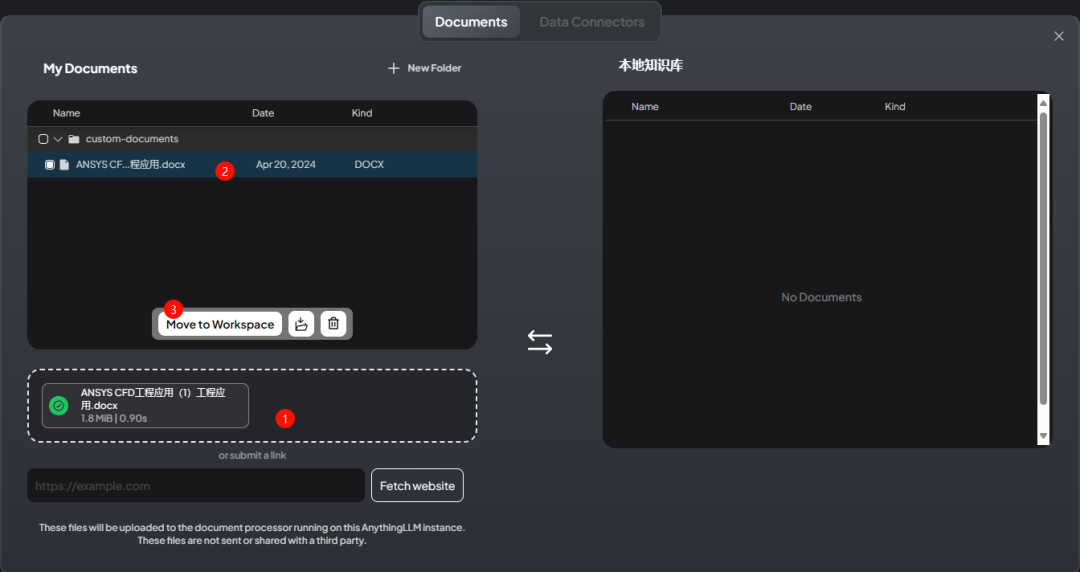
-
After moving the document, it looks like the figure below
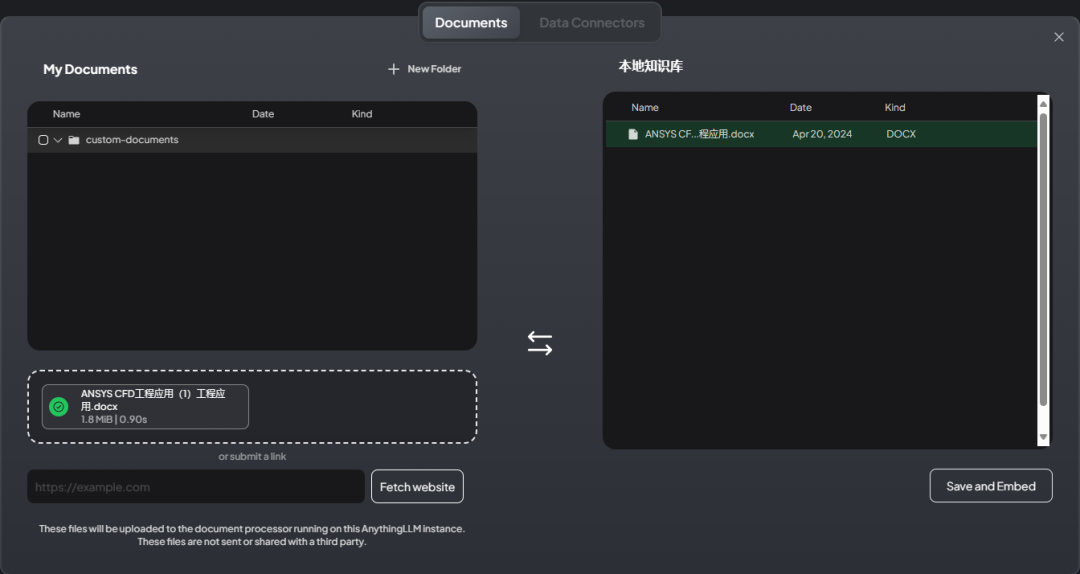
-
Click the Save and Embed button to process the document
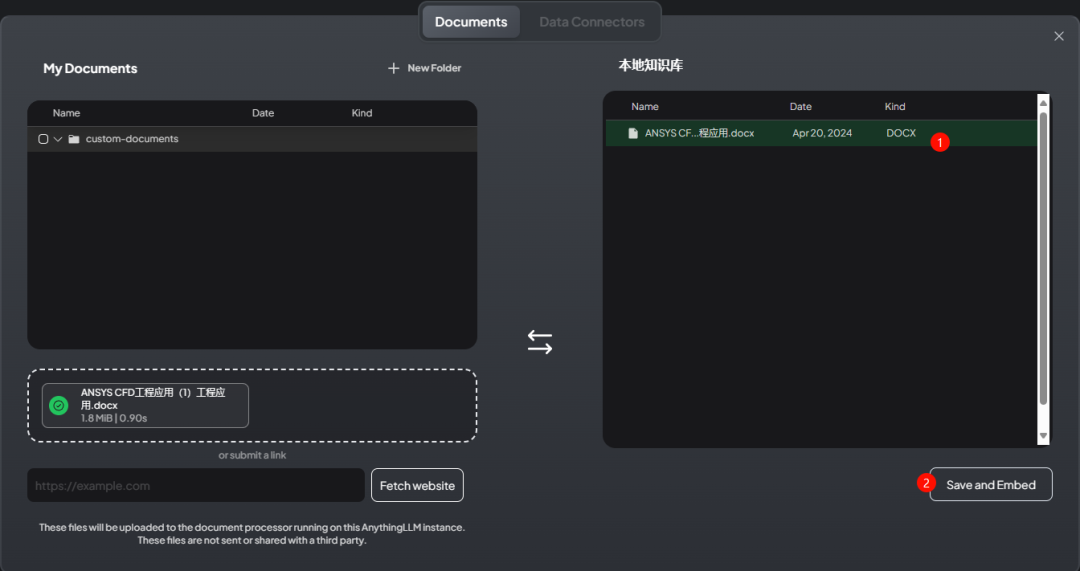
-
After processing the document, you can test it, as shown in the figure below
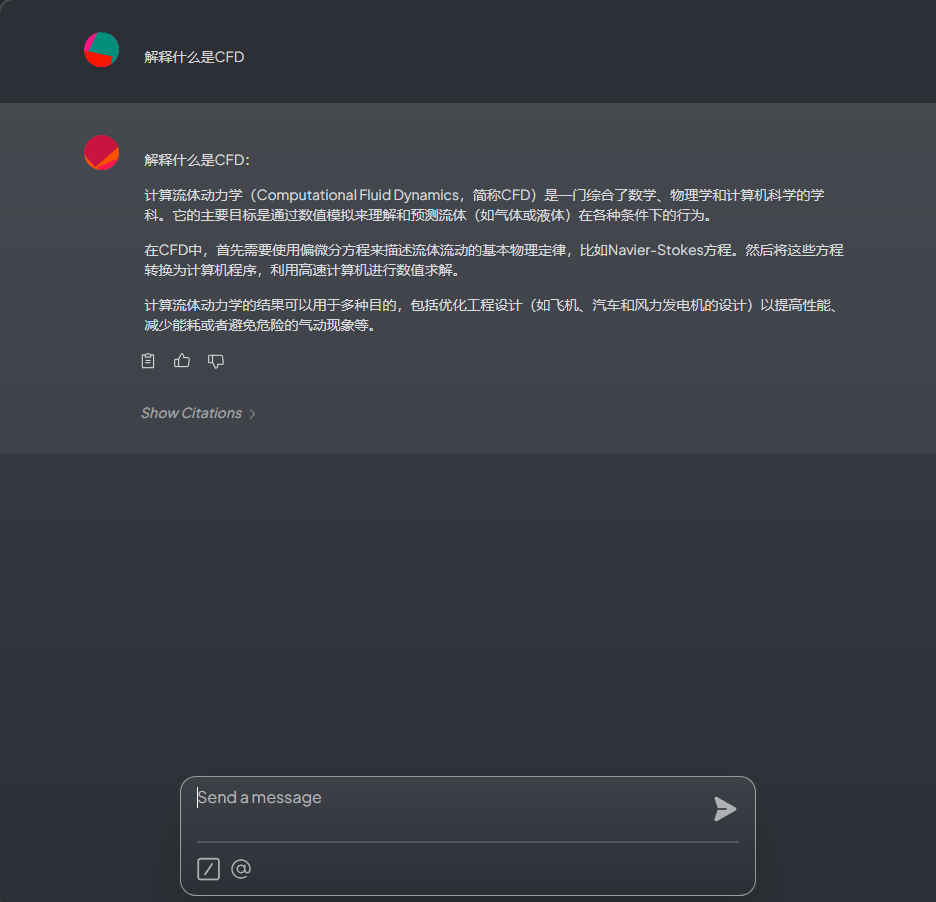
5 Knowledge Base Management
-
You can click the settings button in the lower left corner to open the settings panel
-
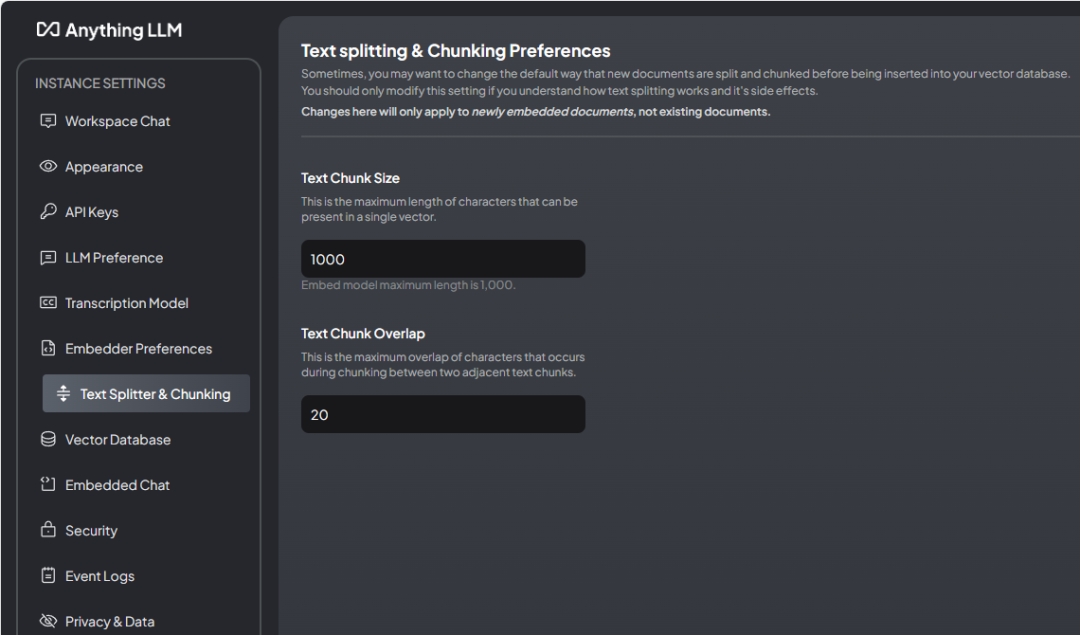
You can set the corpus segmentation parameters as shown in the figure below
-
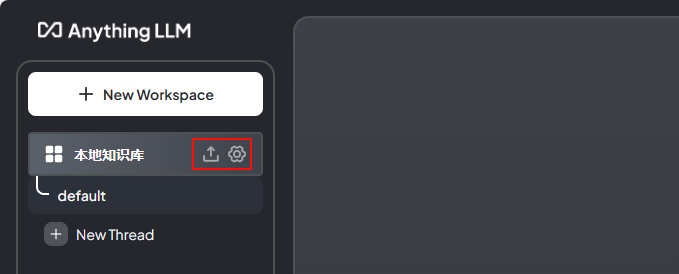
You can also click the button in the upper left corner, as shown in the figure below
-
The first button opens the document management dialog
-
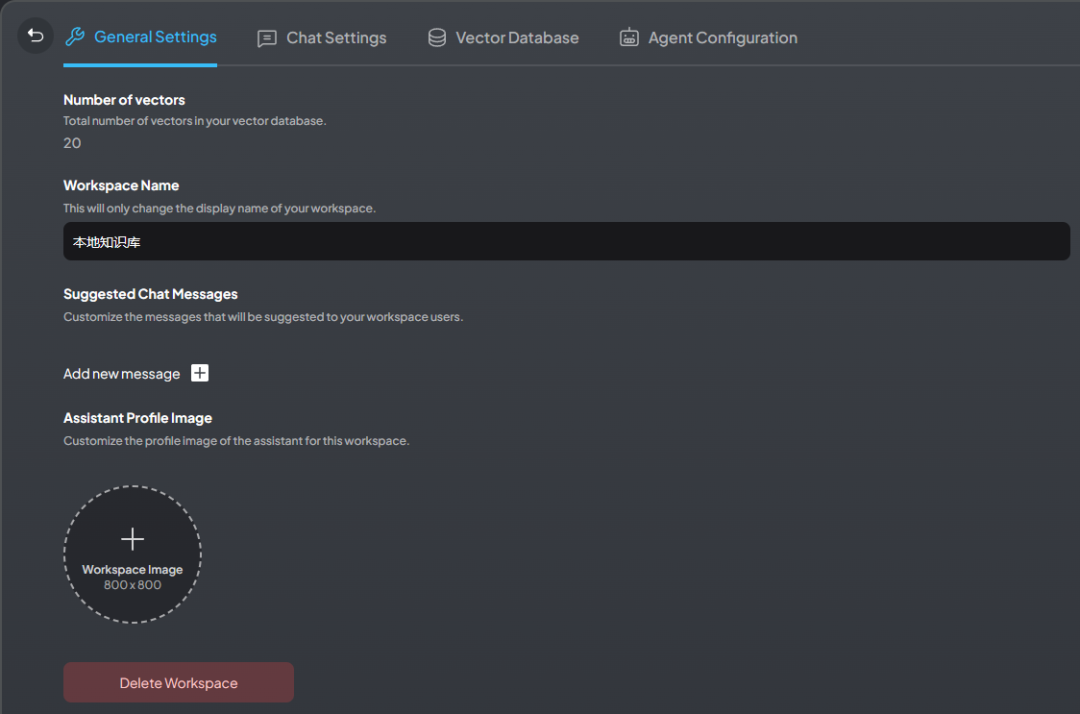
The second button opens the model settings panel
For specific settings, please refer to the documentation. Some methods to improve the performance of the knowledge base include:
-
Using a more powerful base model. The base model is used for data input and output. Using GPT-4 will definitely be more effective than using a small-scale open-source model. AnythingLLM supports calling large models like GPT-4, Claude3, Gemini Pro via API. Currently, it seems that there are no interfaces provided for domestic large models. -
Using a better embedding model. Currently, AnythingLLM has a built-in embedding model. It also supports calling other embedding models provided by OpenAI, Ollama, etc. -
Tokenization parameters. Used for data segmentation. This parameter adjustment requires experimentation. -
Using a more efficient vector library. -
Good raw data.
6 Shut Down Docker
When not using the large model, you can choose to shut down the container to save resources.
-
Click Containers, and click the shutdown button to close the container
(End)