Introduction This sharing is titled “RAG 2.0 Engine Design Challenges and Implementation”.
Main content includes the following parts:
1. Pain points and solutions of RAG 1.0
2. How to effectively Chunking
3. How to accurately recall
4. Advanced RAG and preprocessing
5. How RAG will develop in the future
6. Q&A
Guest Speaker|Zhang Yingfeng Founder of InfiniFlow (Shanghai) Information Technology Co., Ltd.
Editor|Chen Wocheng
Content Proofreader|Li Yao
Produced by|DataFun
Pain Points and Solutions of RAG 1.0
1. RAG Architecture Model
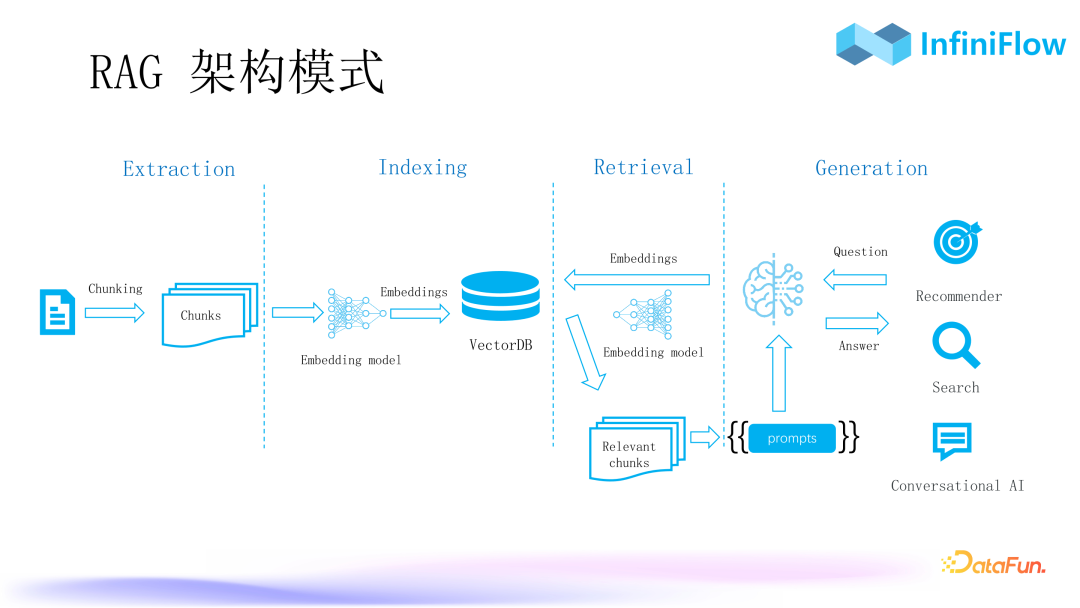
As shown in the above RAG architecture model, everyone should be familiar with it. The standard process of RAG includes four stages: Extraction, Indexing, Retrieval, and Generation.
2. Challenges Facing RAG

RAG usually encounters the following challenges:
-
The first challenge is that the recall of vectors cannot meet the requirements, i.e., the hit rate is very low. Currently, using a pure vector database for RAG often does not yield ideal results.
-
The second challenge is that the document structure is complex and the data is too messy, “Garbage In, Garbage Out”. Simple text is acceptable, but if it is slightly more complex, especially when it involves multimodal documents, the results will be poor.
-
The third challenge is that the questions and answers are not well associated with the documents, making it difficult to find the correct document through the questions, resulting in a semantic gap. For more macro questions, such as what an article is about, or some multi-hop Q&A, where a question is decomposed into several sub-questions requiring further reasoning based on sub-questions, it may not be possible to find the desired answers in these cases.
The above are some obstacles currently blocking RAG from achieving enterprise-level applications, and the next section will explore how to solve these issues.
3. Next Generation RAG Architecture
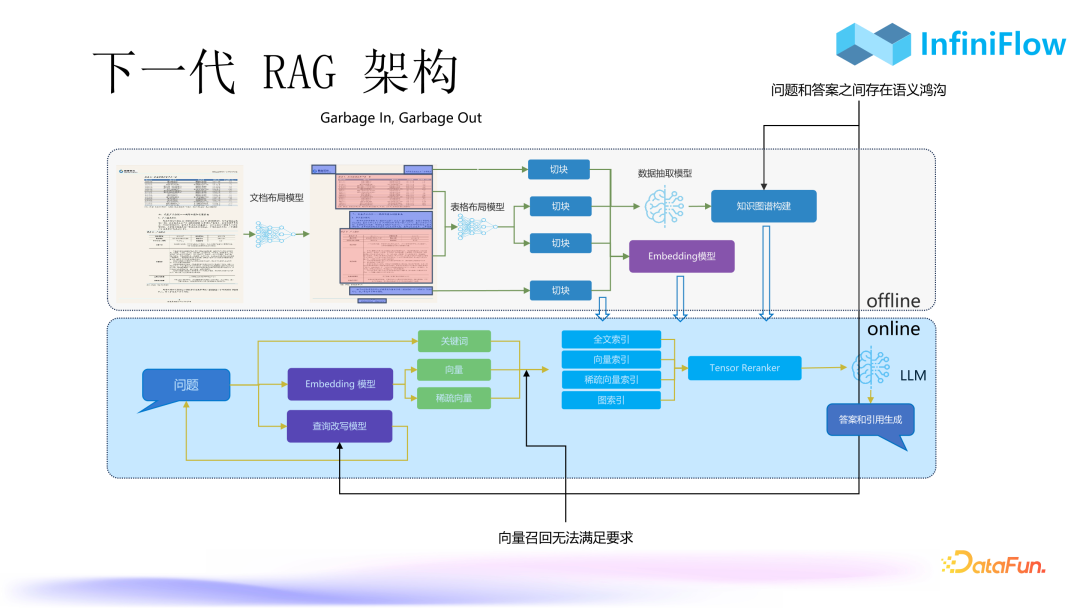
The next generation RAG, namely RAG 2.0, includes two parts: one is offline processing for handling some documents; the other is online processing.
The offline processing part needs to go through a series of deep document understanding models, which are the future multimodal models. By using multimodal models to semantically segment multimodal documents, we can obtain a result that ensures data quality, which in turn can lead to high-quality answers.
The online processing part involves creating knowledge graphs after obtaining the data, addressing the gap between answers and semantics. Then, we need to address the problem of low hit rates in vector recall, requiring multiple solutions such as hybrid search, query rewriting, etc., ultimately generating answers through LLM.
4. Infiniflow
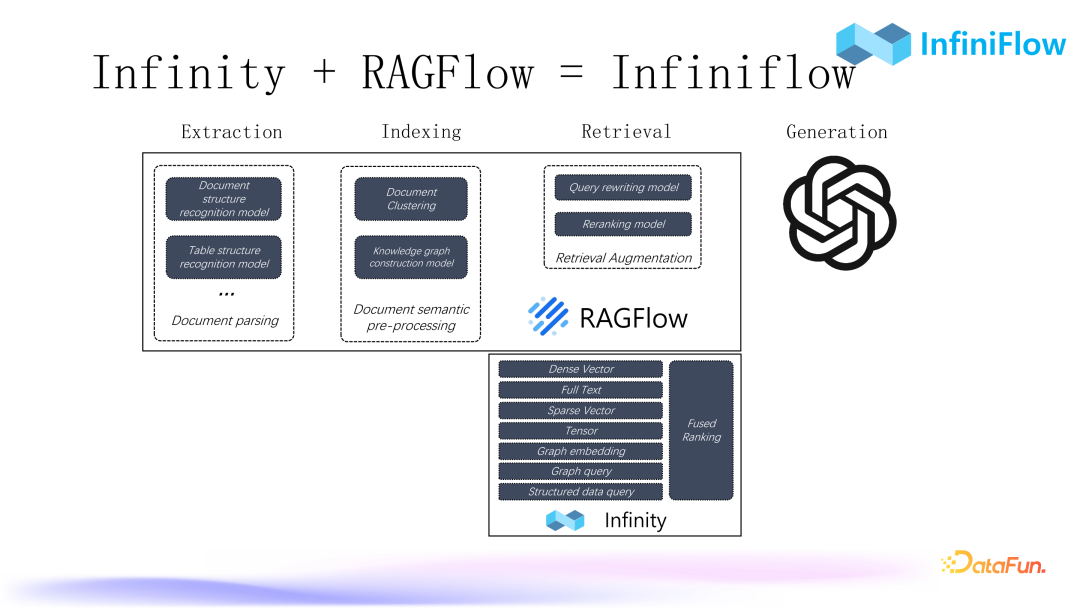
We plan to integrate RAGFlow and Infinity. Our RAGFlow was open-sourced on April 1 of this year and is continuously iterating. So far, RAGFlow is responsible for the final RAG dialogue effect, which can use these models to process data entry, including Graph RAG, and in the future, will add an open-source database Infinity. This product provides rich hybrid search capabilities for RAG scenarios, meeting all requirements for enterprise-level retrieval.
How to Effectively Chunking
1. Chunking Process
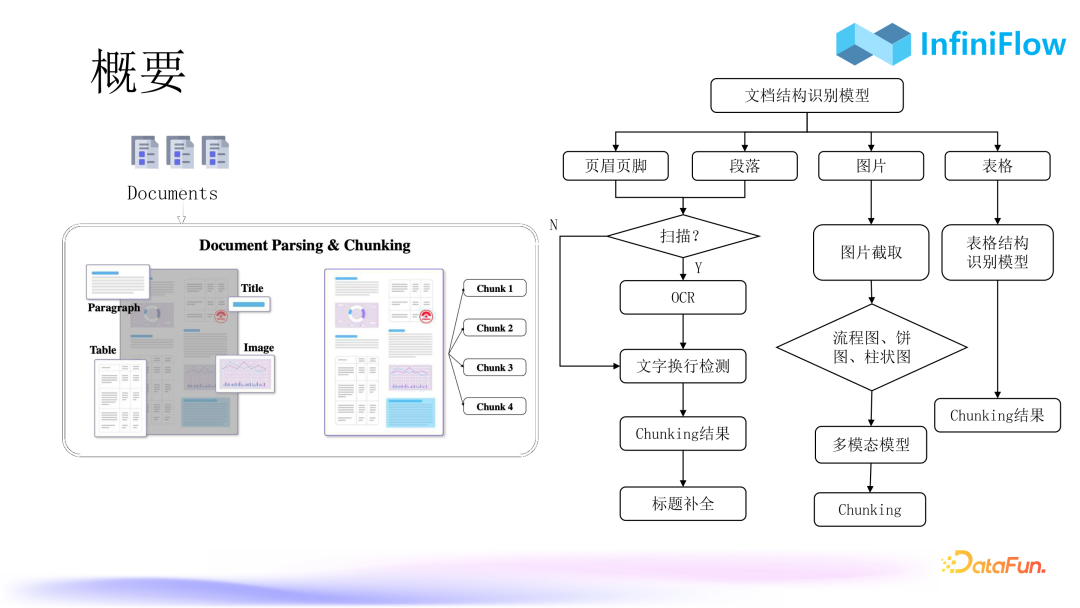
The chunking process is shown in the right diagram above:
-
The first step involves a dedicated document structure recognition model to determine the locations of headers, footers, paragraphs, images, tables, and their coordinates.
-
The second step is to determine whether the areas within these coordinates are text areas. If so, corresponding text processing is required. For example, for scanned PDF documents, OCR needs to be called. If it is not a scanned document, text extraction can be performed directly. It should be noted that text extraction typically involves extracting documents from PDFs, and the parsed text cannot distinguish line breaks. Whether it is a line break needs to be further judged by a classifier. If this is misclassified, the generated vectors will interfere with the final recall. Therefore, some additional, tedious dirty work is needed to ensure high-quality parsing of documents.
-
Next is to output the final answer through chunking.
This is the processing flow for text types. For tables, we currently use a table structure recognition model to extract the correspondence between headers and cells, and then obtain the final chunking result. For other images, such as flowcharts, pie charts, bar charts, line charts, etc., similar methods can also be applied using multimodal models. This is our solution to ensure data quality entry using deep document understanding models.
2. Comparison of RAGFlow Adjustment Extraction Models
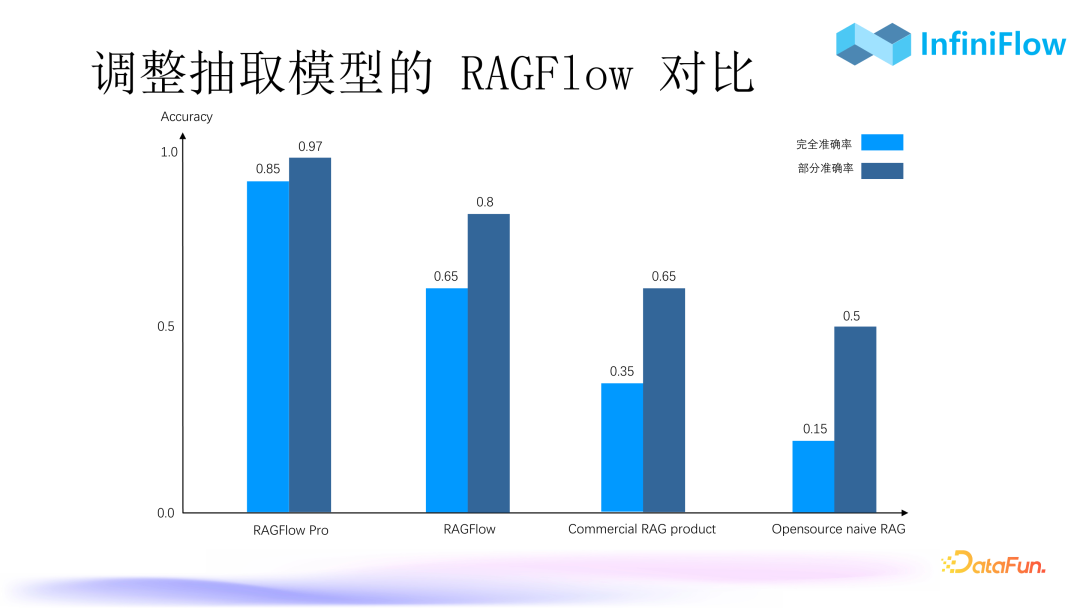
The above image shows a comparison of RAGFlow with some open-source RAG and commercial RAG products from leading large model companies. The evaluation metrics include two: complete accuracy rate and partial accuracy rate. It can be seen that through continuous adjustments in extraction, we have achieved a very high accuracy level. Based on our experience, truly utilizing RAG in enterprises is challenging with open-source RAG due to low hit rates.
3. Table Recognition Model
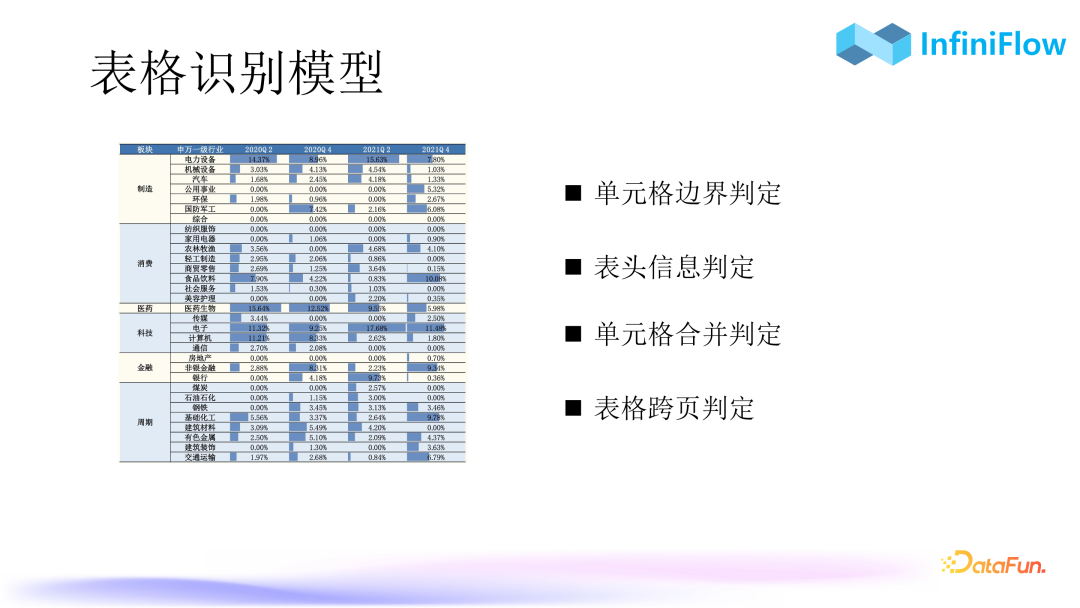
The table in the above image is relatively complex, with some cells having lines and some not, the left column having merged cells, and many shadows appearing in the table, all of which can interfere with the extraction of table content. This work falls within the scope of table structure recognition models. There are two approaches to table structure recognition models. Our earliest approach was to treat each cell as a sentence, but this method does not have high robustness. Our current approach is to convert the text recognized from the entire table into HTML format (HTML can ensure the structural layout of the table), and then input the entire content into the model for the model to respond to the table content. This approach has better robustness. Therefore, the accuracy of table structure recognition is crucial, and it can even be developed as a separate component to be provided to business parties in the form of an API.
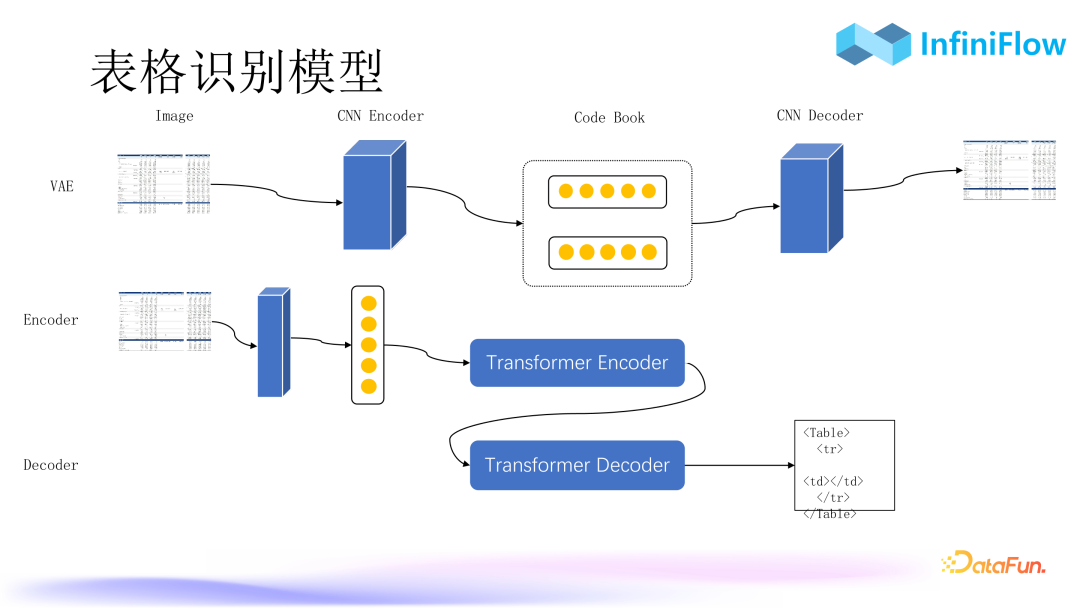
The RAGFlow in the above image adopts traditional CNN convolutional neural networks, treating the table as an object detection problem to obtain the final answer. The model we are currently training uses a transformer-based architecture, which can handle tables, flowcharts, pie charts, and bar charts, as it is a general solution that addresses the image-to-text and encoder-to-decoder problems.
The specific process is as follows: the first step is to use VAE (Variational Autoencoder) for feature extraction, first encoding the table image using a CNN encoder, and then restoring it using a CNN decoder, allowing our decoder and encoder to produce images as similar as possible to the original image, thus obtaining an intermediate Code Book (codebook). This is equivalent to an embedding of image patches, which can very accurately restore the representation of embeddings in the table scene; this Code Book is very important.
The second step is to train the Transformer Encoder. The encoder also takes images as input and should fit the above embedding as closely as possible in its output.
The third step is to jointly train the encoder and decoder. The decoder outputs the final HTML text.
This structure is somewhat similar to large models, but large models like GPT are decoder-only. However, if we want to create multimodal models, we must adopt an encoder-decoder architecture to obtain a unified image-to-text solution.
Although the model is still in training, the results obtained so far show that the table recognition effect is very good, significantly better than the robustness of previous CNNs. This is because the table recognition model is based on a transformer architecture, which has a relatively high threshold for training data sources. Our current approach is to generate data programmatically to cover more scenarios. For example, if users’ tables are not well done, we specifically simulate the generation of corresponding images for such scenarios, and then use these images to continuously iterate the model, ultimately forming a data flywheel that improves the model’s iteration effect and generalization ability.
4. Document “Large” Model
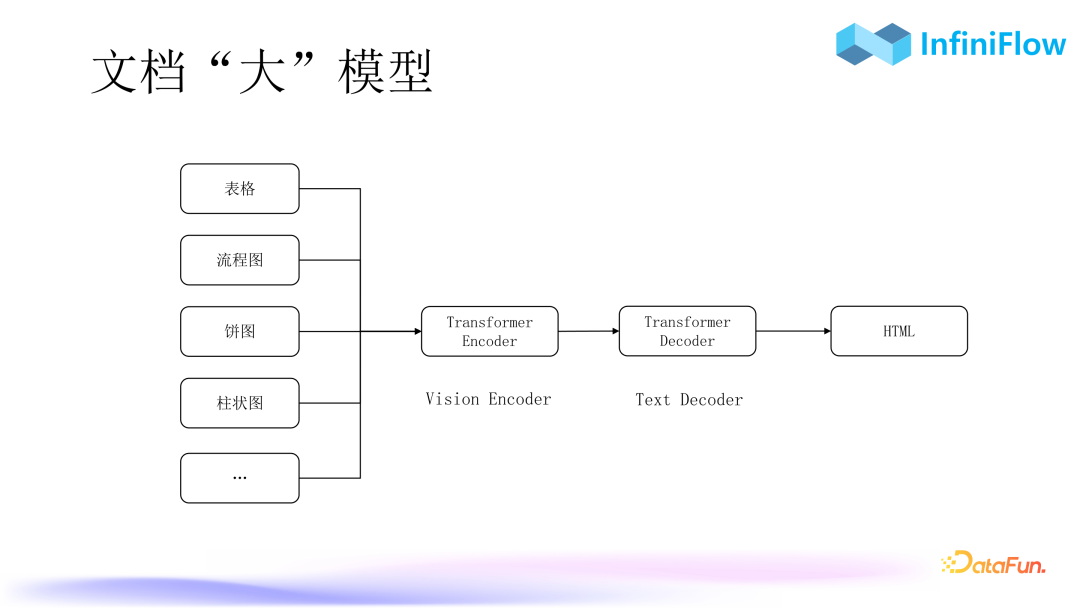
Next, based on tables, we will also include flowcharts, pie charts, bar charts, and other charts to obtain semantically informative HTML format text, which will be sent to the large model to get the final answer.
How to Accurately Recall
Next, we will introduce how to ensure accurate recall.
1. Indexing Database
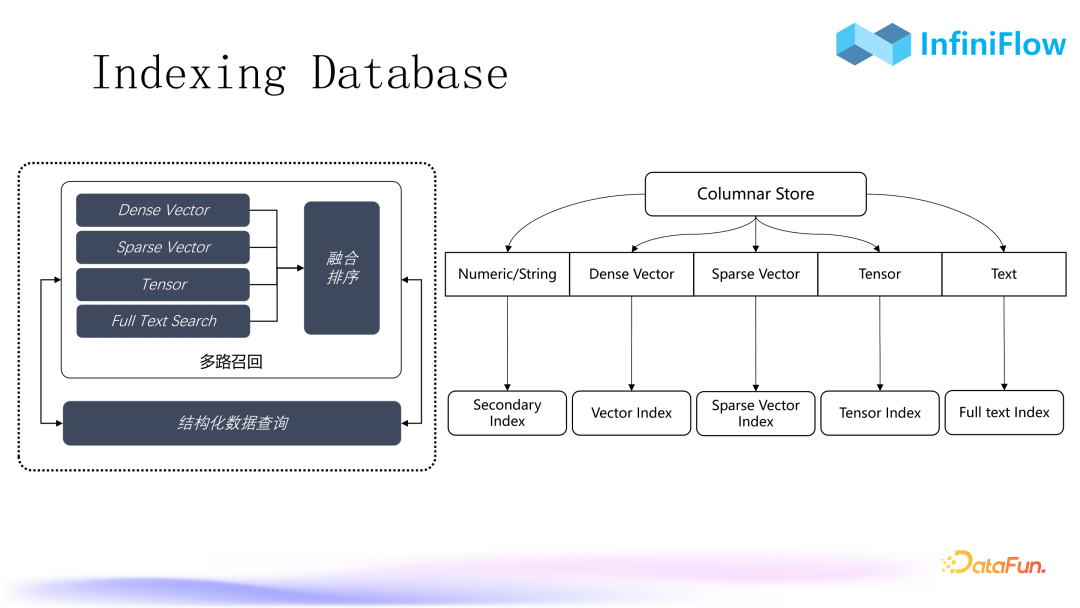
To achieve accurate recall, we began developing an indexing database two years ago. As shown in the image, when we create a table with different types of data, we create corresponding indexes based on the data types in the column storage. For instance, for vectors, we create vector indexes; for sparse vectors, we create sparse vector indexes; and for text, we create full-text indexes. It is worth mentioning that full-text indexing is currently the only indexing method that guarantees that whatever the question is, it will be found; it is a must-have for RAG. Additionally, there is tensor indexing. Finally, once fusion ranking is completed, we can solve all retrieval issues related to RAG in one stop.
2. Benchmark
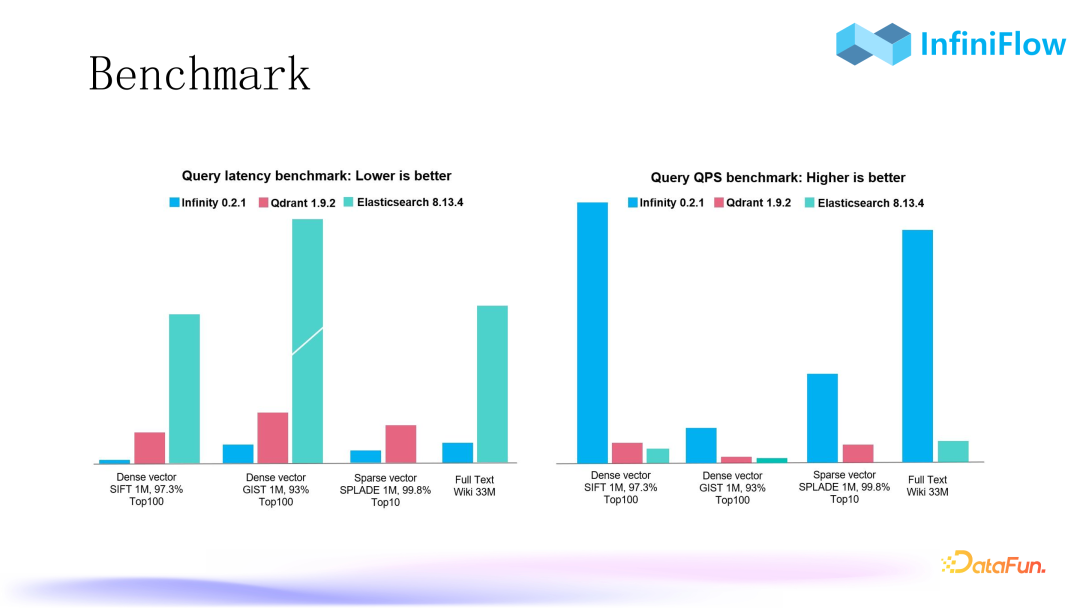
The image above shows some metrics we are currently using, compared with popular open-source vector databases and search engines. The left shows latency, where lower values are better, and the right shows QPS, where higher values are better. It can be seen that we currently have a leading advantage on these datasets.
3. Comparison of RAG Database Selection
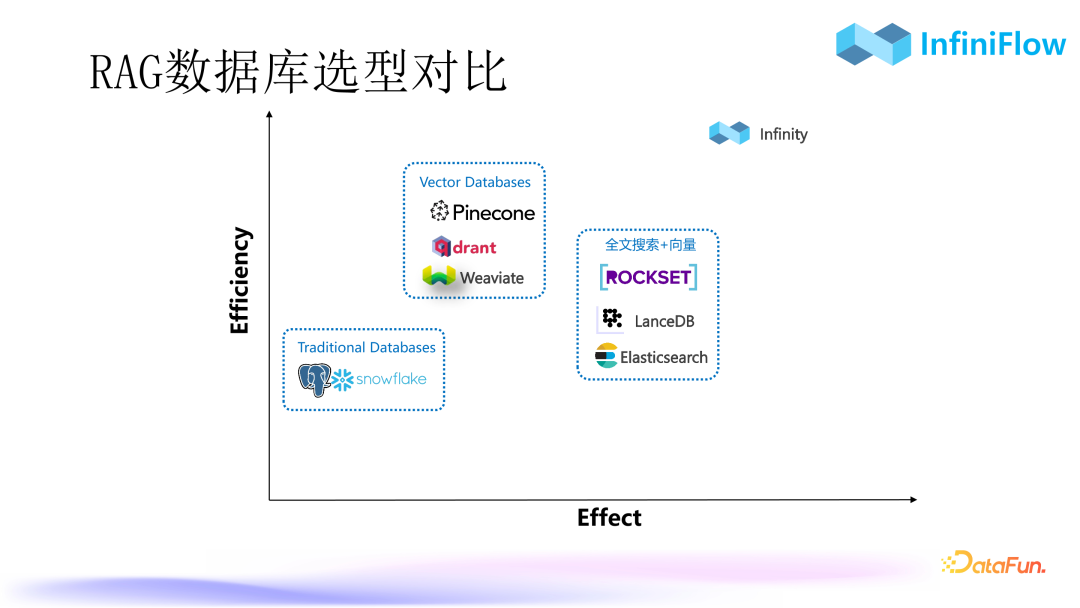
Currently, the databases used for RAG can be divided into three categories:
-
The first category is traditional databases. This type of database can theoretically be used for RAG as long as vector capabilities are added. For example, PostgreSQL has a well-known plugin called PG Vector for supporting vector access, and Snowflake is a data warehouse that also has vector capabilities.
-
The second category is typical vector databases, such as Pinecone, Qdrant, and Weaviate.
-
The third category includes databases with full-text search + vector capabilities, such as ROCKSET, LanceDB, and Elasticsearch.
In enterprise-level scenarios, full-text search is an essential capability. Currently, well-known databases with full-text search and vector capabilities include the ones mentioned above. LanceDB is a database recently incubated in North America, using the well-known Tantivy library for full-text indexing. ROCKSET is a database company acquired by Open AI in June this year; it is an indexing database that has built full-text indexes for each column, so it was initially intended to replace Elasticsearch. However, later, due to the popularity of RAG, it added vector indexing, thus achieving dual hybrid search for better recall results. We are also integrating the Infinity database into RAGFlow. As RAGFlow currently uses Elasticsearch, it will take some time to replace it with Infinity.
4. Multi-Recall?
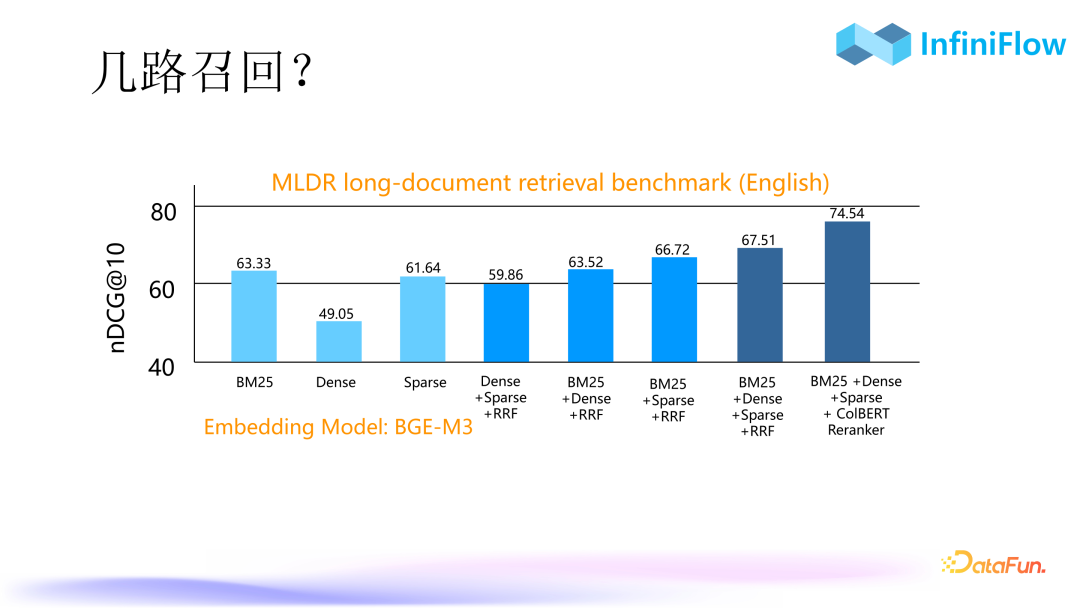
Next, we will discuss some technical issues. The first question is, since we already have vector, sparse vector, tensor, and other search methods, does hybrid search and multi-recall still make sense?
We used the MLDR dataset for evaluation. MLDR is a long document dataset, and we ran our own database to produce the metrics shown in the image above, where the vertical axis represents nDCG@10, which requires a weighted score for each result’s position. Therefore, if something originally ranked first is moved to second, it will also affect the score. The three lightest colors in the image represent searches using three methods: BM25 is full-text search, Dense is vector search, and Sparse is sparse vector search. It can be seen that using only vectors yields the lowest score of 49. The middle colors are two-way recalls, which combine sparse vectors and full-text searches, along with a basic fusion ranking, resulting in a mixed search that indeed performs better than single-route searches. The second to last one is the combination of three-way searches, along with RRF, achieving a higher score. This result comes from a paper titled “BlendedRAG: Improving RAG” published by researchers at IBM Research Zurich in April of this year (paper link: https://arxiv.org/pdf/2404.07220), concluding that three-way recall yields the best results. We have also replicated this conclusion using our database. The far-right shows a significant improvement because we implemented a tensor in the form of ColBERT, which greatly enhanced the final recall performance.
5. Ranking Models
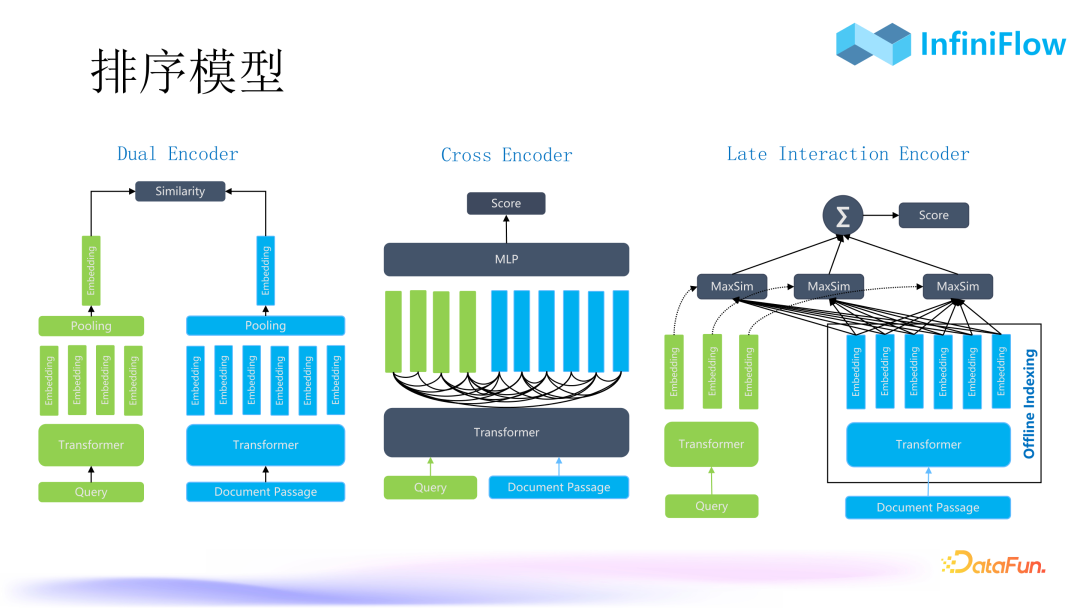
The second question is what exactly are tensors?
The image above shows the three types of current ranking models:
-
The first type is dual encoders. Dual encoders align with the vector search concept, where the query and document are input into the model separately for encoding. A key point here is that after encoding, each token generates an embedding, but after passing through the pooling layer, it ultimately becomes a vector, leading to some semantic loss.
-
The second type is cross-encoders. The query and document are input together into the model for cross-encoding. Cross-encoding can capture the interaction relationship between each token of the query and each token of the document. As long as these tokens appear in our training dataset, we can capture this relationship, and finally output one result. Therefore, cross-encoders generally perform much better than dual encoders; a common example is BGE, which is a typical cross-encoder.
-
The third type is delayed interaction encoders. In the offline phase, the model generates embeddings for each token and stores them. For each document, it stores not just one vector but a tensor or multiple vectors, as we will store the vectors for each token. When querying, we only need to encode the query again, which turns the query into many token vectors. The query and results are also vectors, and the scores between these vectors are calculated pairwise and then summed. This method also captures the interaction relationships between tokens, making it theoretically close to cross-encoders, but it has additional benefits when placed in a database.
6. Benefits of ColBERT
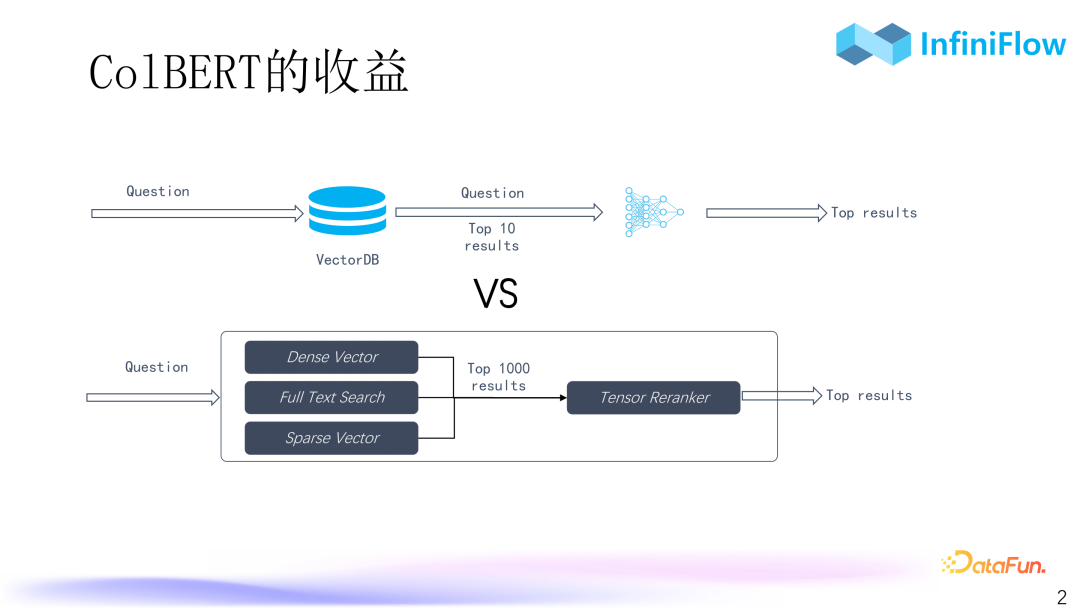
The additional benefit is that its efficiency is significantly higher. According to our evaluation, it can be approximately two orders of magnitude higher. The re-ranking model must be run on GPU and can only target the top results, such as the top 10 or top 20 for re-ranking. However, re-ranking the top 100 or top 1000 results can have a significant impact on performance, as both encoding and transmission performance will be poor. However, if we have a re-ranking model running in the database, and its performance is two orders of magnitude higher than that of GPU-based cross-encoders, we can run it on CPU and even re-rank the top 100 or even top 1000 results. In this case, if our initial search results are poor, there is still a high probability of recovery. Therefore, the significance of this approach is to enhance efficiency while maintaining similar effectiveness. Thus, it can significantly improve the final ranking.
However, there are also risks. ColBERT essentially stores each token, leading to significant space inflation. Each embedding in the ColBERT model is approximately 128 dimensions, meaning each token is 128 dimensions, which implies that the final tensor space expands by two orders of magnitude compared to the original text. If we use larger embeddings, such as a typical BGE output embedding which is around 1000 dimensions, it could lead to a three-order magnitude expansion. For example, if the original text is 1G, it could become 1T.
7. Benefits of ColBERT
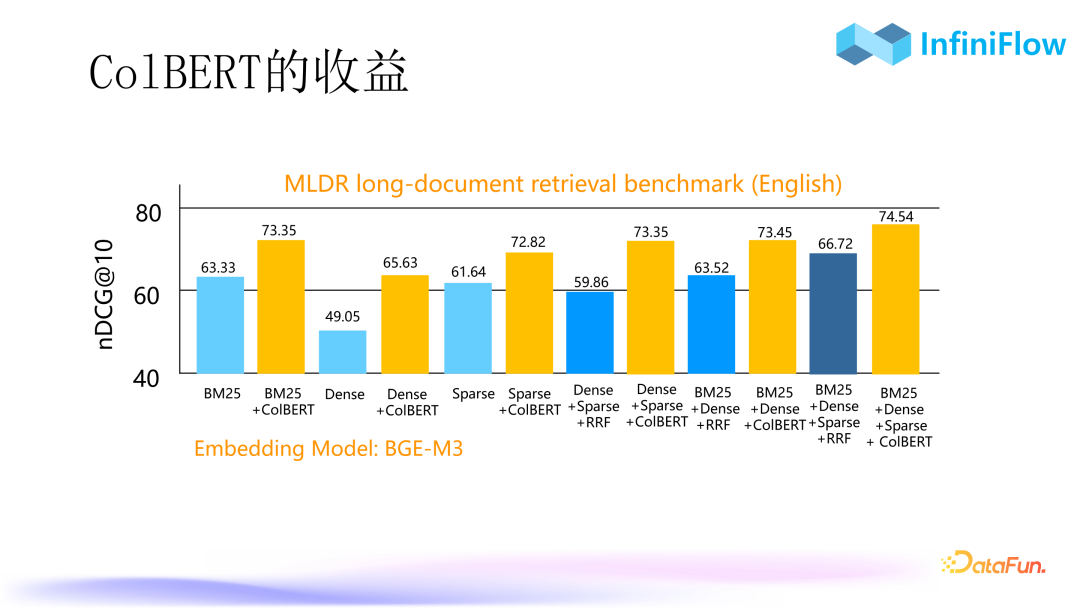
We compared ColBERT with and without its implementation, and it can be seen that whether it is single, dual, or triple recall, adding tensor-based re-ranking can yield significant improvements. Even for semantics, where the loss is the largest, the score can increase from the 40s to the 60s after adding tensors. This re-ranking is not applied to the top 10 or top 20 but to the top 100 and above for achieving such good results.
8. ColBERT Ranker or Re-ranker

Now let’s talk about efficiency. There are two approaches to tensors: one is to use tensors to establish indexes, treating them as a means of recall, similar to vectors; the other is to use tensors as a re-ranking solution. The image above shows a comparison of the two methods: the first uses tensor indexing, which we internally call EMVB. EMVB is essentially a vector indexing improvement applied to tensor space, allowing similar indexing for tensors. The middle uses ColBERT for re-ranking. The far-right uses tensors for brute-force searching, with no re-ranking or indexing, theoretically resulting in no loss of precision.
It can be seen that the highest score is 74, but our middle re-ranking even performs better than searching using indexing. This indicates that we do not need to implement indexing for tensor models. Currently, models like ColBERT provided by the official offer this indexing scheme, but its cost-effectiveness is low, while re-ranking is much more cost-effective. Additionally, a very clear advantage of re-ranking is that we can avoid storing the original tensor and only store its binary quantization. This means using one bit to represent one floating point number, allowing for a 32-fold space compression. If we use a 128-dimensional ColBERT model, the last token would only need to occupy 16 bytes, which is an acceptable cost. We exchange a small amount of space inflation for a significantly higher quality ranking, which is worth it. Therefore, in the future, re-ranking will also be a standard feature of RAG.
9. Delayed Interaction is the Future of RAG
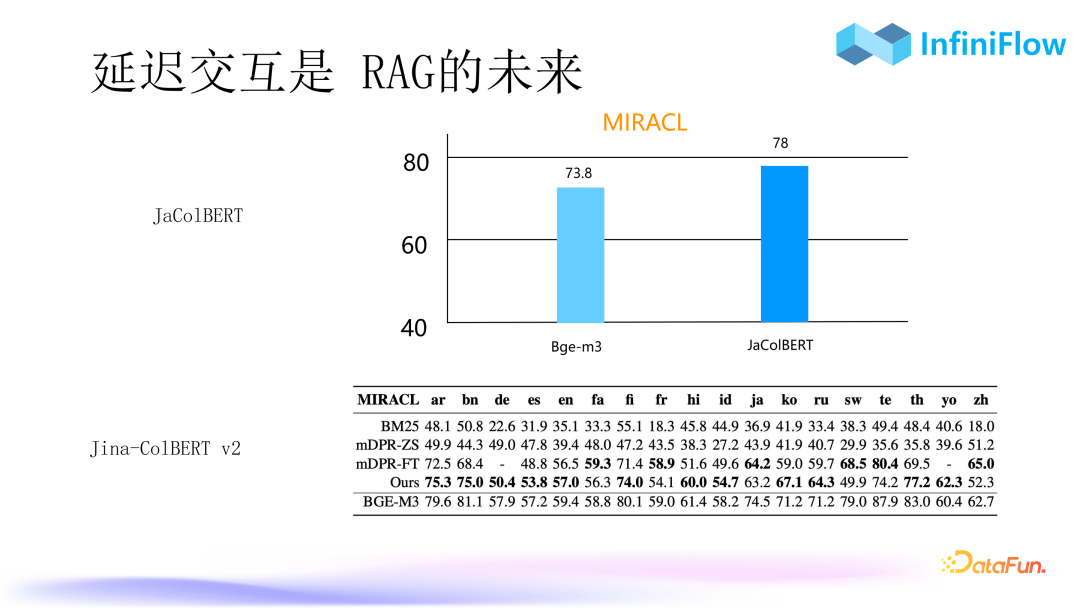
Based on our observations, delayed interaction encoding is not a trade-off for cross-encoding; it can even perform better than cross-encoding. The first image is from JaColBERT data, a model specifically trained for Japan by a North American company called Ansliya in August of this year. It can be seen that on the MIRACL dataset, its performance is even better than that of BGE-M3. Therefore, we believe that models based on delayed interaction may bring higher precision. Thus, we consider tensors to be the future development direction of RAG.
The second image is from Jina’s work. We have been looking for a Chinese ColBERT model, and even we have been training one ourselves. Later, we found that Jina recently released a model called Jina-ColBERT v2, which is the first multilingual ColBERT model on the market, capable of generating text tensors. However, Jina’s work has not yet advanced further, and currently, its results are somewhat lower than BGE. But as we can see from the above JaColBERT, the performance of delayed interaction models is comparable to cross-encoders, and we have incorporated these capabilities into our database.
10. Delayed Interaction is the Future of RAG
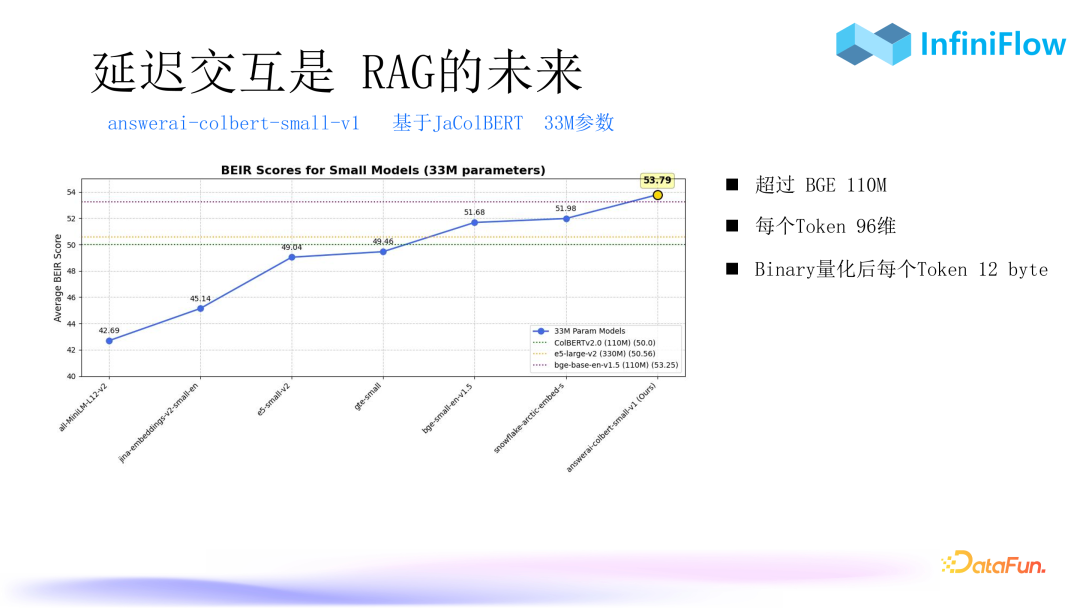
Another model is answerai. It compresses the parameters of ColBERT to only 33 million but achieves better results than BGE’s model with over 100 million parameters. Moreover, each token is only 96 bits, which greatly reduces space waste after binary quantization. We believe that more such ColBERT models will emerge in the future, especially for Chinese ColBERT models, to ensure recall effectiveness.
Advanced RAG and Preprocessing
The third part will introduce how to solve the semantic gap, that is, preprocessing methods.
1. Document Preprocessing for Complex Q&A – RAPTOR
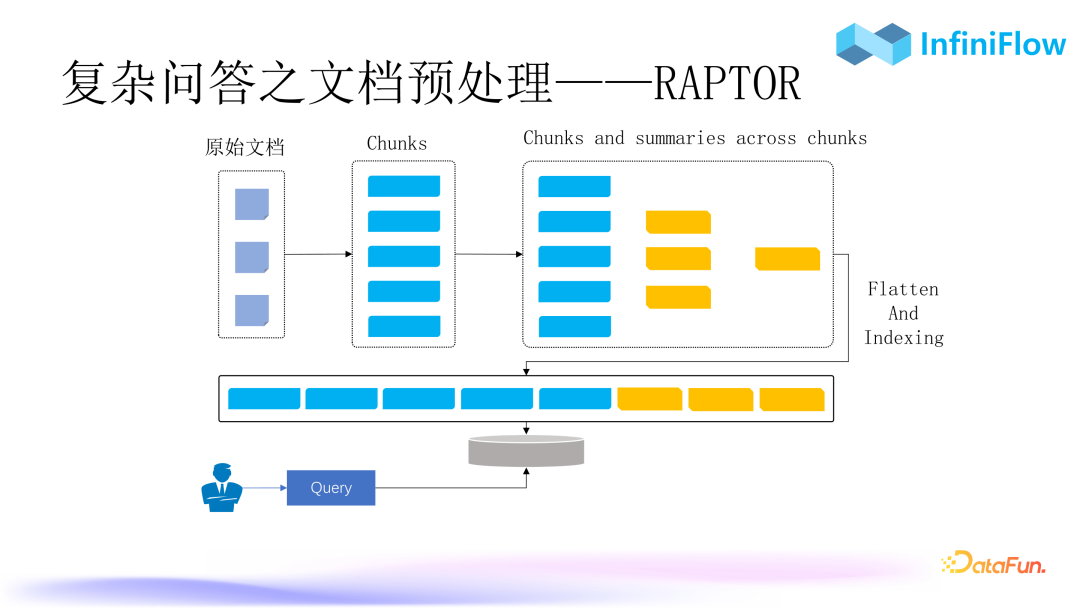
The first preprocessing method is called RAPTOR. It starts with clustering documents, and after clustering, generates summaries, which along with this information are sent as chunks into the RAG system. During the search, we can search for this clustered information. The entire document has semantic information across chunks, allowing RAPTOR to solve multi-hop Q&A or more macro questions.
2. Complex Q&A with Agentic RAG
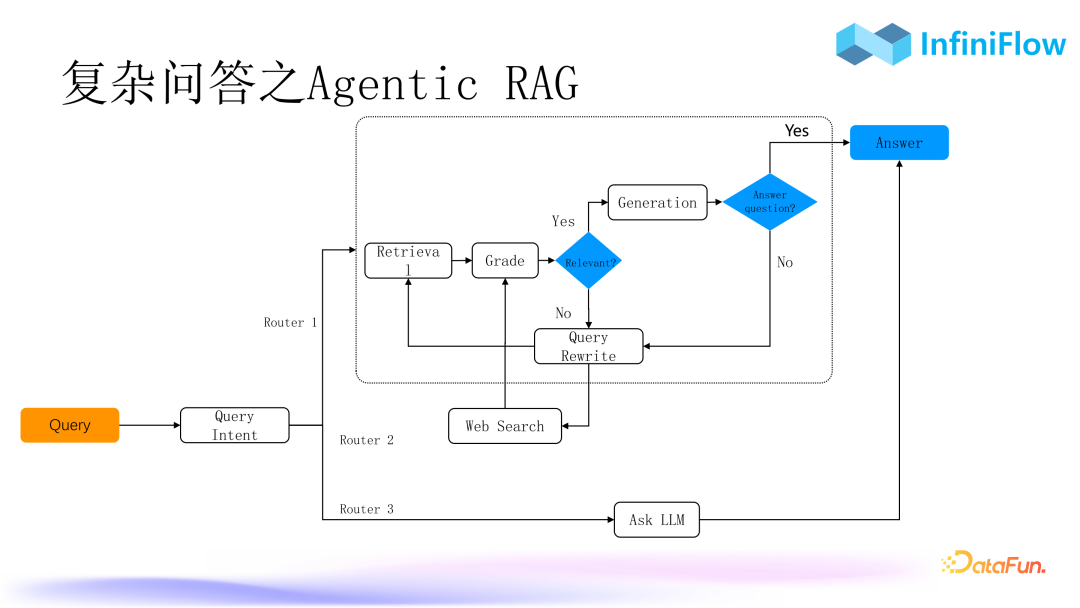
The second method is AgenticRAG. Many may wonder what the relationship between RAG and Agents is. In our view, RAG serves as the foundation for Agents, which are more business-oriented, while RAG acts as a technical middle platform or central layer. Therefore, we can use Agents to make RAG more complex, such as orchestrating more RAG processes. In this context, we need various operators, such as query intent libraries and query rewriting. With these operators, we can orchestrate the entire dialogue, iterating continuously to achieve an ideal outcome.
3. Complex Q&A with Knowledge Graphs
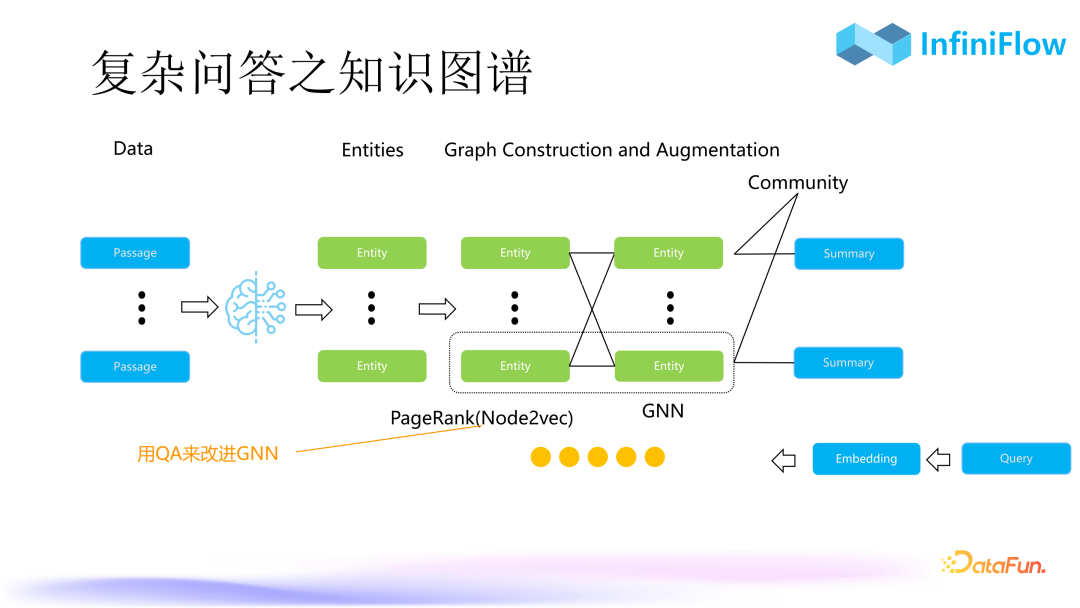
The third method involves knowledge graphs. Knowledge graphs emerged more than a decade ago, and previously, using them required high accuracy and substantial manual effort to verify the accuracy of the knowledge graph, making implementation difficult. Moreover, the relationships between entities in knowledge graphs are quite complex, often involving dozens of types, thus making automated construction of knowledge graphs a high barrier.
However, with the advent of Graph RAG, many tasks have been simplified. First, we use large models to extract entities from the text, then we only need to determine whether the entities are related. In other words, we simplify the relationships between entities in traditional knowledge graphs from dozens to a single association, making automated construction of knowledge graphs possible. After generating the knowledge graph, we can continue to produce node embeddings, which can be used for retrieval in a graph vector manner.
Graph embedding can also be further improved. A simple example is approximating a graph neural network for internal enterprise Q&A systems, enhancing the quality of node embeddings. Generating embeddings directly is akin to traversing the knowledge graph, similar to PageRank. Why does PageRank yield results that align well with our answer demands? Because it mirrors the associative process of our brain, which resembles a random walk. This process can be transformed into graph embedding using an algorithm called node2Vect. Thus, with knowledge graphs and graph embedding, we can effectively handle multi-hop Q&A or more macro question styles.
You may be curious about which of these three methods is better.
The first method, RAPTOR, is clearly simpler. The second method, AgenticRAG, relies on some internal operators, such as query intent, which can vary across different scenarios, making standardization difficult. The third method, knowledge graphs, is more than just clustering; it extracts more entities, so its effectiveness is generally superior to RAPTOR. However, it also has drawbacks, as knowledge graphs require us to process all user documents through the model, which can be costly unless fully privatized. We recommend using fine-tuned smaller models. There are already some overseas solutions, such as Triplex, which specializes in knowledge graph extraction, and we believe this approach will become a standard in the future.
How RAG Will Develop in the Future
1. Multimodal RAG-G—”Carving Flowers” or?
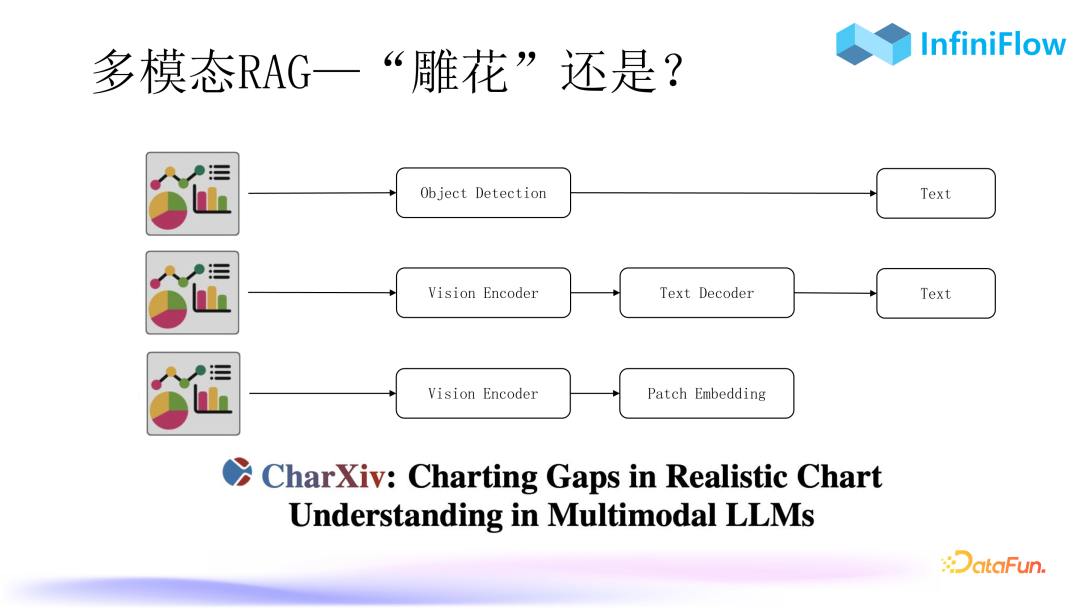
We predict that next year will be the year of the explosion of multimodal RAG. Based on our current observations, multimodal technology is gradually maturing. The above image summarizes three processing methods for multimodal data:
-
The first is our open-source RAGFlow, which uses object detection algorithms to convert charts into text.
-
The second method we are currently training has achieved excellent results, based on the principle of using multimodal models with Encoder input and Decoder output to convert images into text.
-
The third method directly generates Patch Embedding from images, where Patch is a unit in images similar to text tokens, transforming it into an embedding. In fact, the second and third methods can share the same encoder, as they are entirely compatible. We have not yet implemented the third route, as its cognition is not yet precise enough. However, its development will be rapid. Recently, we saw a paper titled “ColPali: Efficient Document Retrieval with Vision Language Models,” which refuted the traditional first route: “Performing OCR and layout recognition on multimodal documents, followed by layout detection to obtain text, before sending it to RAG,” comparing it to “carving flowers,” as it is indeed very tedious.
2. Multimodal RAG and Delayed Interaction Models
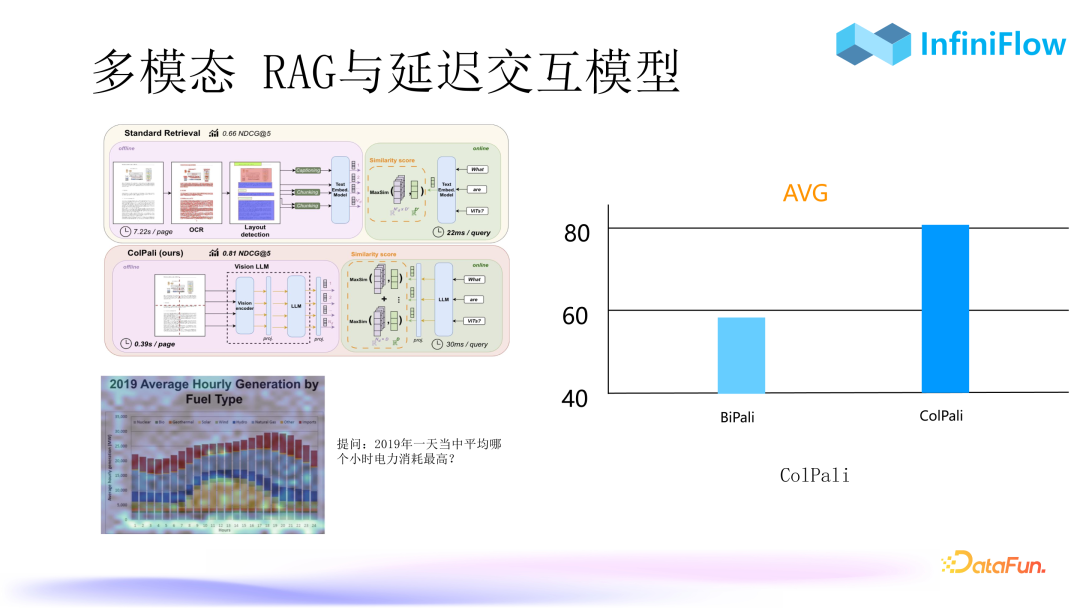
This method directly inputs multimodal documents as images to generate embeddings, allowing for direct responses to queries based on embeddings. For example, in the case shown in the image, we can directly ask the bar chart: “Which hour of the day had the highest electricity consumption in 2019?”. It can be seen that after using ColPali on the right, its evaluation metric NDCG exceeds 80, which is very high, indicating that it is already production-ready. ColPali is closely related to the previously mentioned ColBERT, where “Col” means that queries and documents are jointly encoded. ColPali outputs a tensor instead of a vector for multimodal data, and the semantic similarity evaluation results can increase from below 60 to above 80, indicating a significant difference between toy-level and production-ready.
3. Memory-Enhanced Agents

Agents need to further develop by incorporating memory, preserving different information in various fields, such as cases, knowledge, market information, or successful experiences in medical, financial, and legal sectors, while retaining personalized behaviors in gaming. In recommendation systems, it can store users’ historical context. Thus, the memory module of Agents imposes requirements on databases as well. In the future, RAG will demand more from database capabilities, not just hybrid search; the data stored in Agent memory may include vectors, tensors, text, or structured data. Therefore, RAG will impose higher demands on databases in the future, and only by meeting these requirements can we unlock more complex memory-enhanced Agents for deployment in enterprise scenarios.

This concludes our sharing. If you are interested in our products or articles, please follow the InfiniFlow official account or our project. Thank you.
Q&A
Q1: What models are used for the benefits of ColBERT in the image?
A1: Sparse Vector uses BGE-M3. BGE-M3 is a model we frequently use, capable of outputting vectors, sparse vectors, and tensors. However, the tensor output has some issues, as it reaches 1024 dimensions, which is entirely unnecessary; for tensors, 128 dimensions are sufficient.
As for BERT, we are currently using the ColBERT model, which you can download from HuggingFace. Jina-ColBERTv2 is a model recently open-sourced by Jina; you can try it out. Its Chinese metrics are still lower than BGE-M3, so there is significant room for improvement.
Q2: Are tables stored in HTML format? Will this lead to information loss in vector models due to maximum length? The large model for table Q&A is not very sensitive to table numbers and is prone to hallucination.
A2: We currently store tables in two parts: HTML and vectors. Since HTML uses full-text indexing, tables are primarily recalled through full-text indexing, while vectors serve as a supplement. In enterprises, if not used in a multilingual context, full-text indexing will generally have a higher weight.
Regarding the statement that “large models are not very sensitive to table numbers and are prone to hallucination,” we still must rely on large models because initially, we treated each cell as a sentence, which performs better under absolute accuracy conditions. If even one cell is misidentified, it can lead to errors in the alignment of the entire relationship. Therefore, if one or two cells are not identified accurately, there is still an opportunity for large models to recover. In the future, we hope the table model can achieve as close to 100% accuracy as possible, and we may revert to treating it as a sentence.
Q3: Can cross-encoding be accelerated using GPU?
A3: Yes, cross-encoding can utilize GPU. Models like BGE or other Reranker models on MTEB rankings typically use cross-encoding. Most of these models require running on GPU; otherwise, the performance is hard to bear. A delay could be several seconds or over ten seconds, which is sensitive for RAG as an online application.
Thank you for your attention to this sharing.
Founder of InfiniFlow (Shanghai) Information Technology Co., Ltd.
Founder of InfiniFlow, with years of experience in search engines, Infra, database kernels, and AI development. Previously responsible for building products with tens of millions of daily active searches, as well as digitalization efforts for several large enterprises.
How Douyin Group Cleverly Uses “Data Warehouse” to Reduce Costs
In-Depth: What is Fei Fei Li’s AI “World Model” and Why is it Important?
A Comprehensive Overview of Embodied Intelligence (Part 1)
Smart Retail 2.0: New Solutions for Abundant Food
Practice of Tencent’s Intelligent Data Analysis Platform OlaChat Based on LLM
Large Models vs. Search and Promotion? How Should Algorithm Engineers Choose Career Paths?
Practice of Douyin Group’s Indicator Management and Consumption System Construction
Practice of Kuaishou E-commerce Data Indicator System Construction
Zhi Hui Jun’s Big Move: Open Source Humanoid Robot Full Set of Schematics + Code
Decoding Intelligent Recommendations: Innovative Applications of Multimodal Large Models in NetEase Cloud Music
Click to See More You at Your Best








