

Source | Heart of Autonomous Driving
Editor | Deep Blue Academy
How Does Computer Vision Effectively Perceive In Complex Environments?
In recent years, the application of computer vision in Intelligent Transportation Systems (ITS) and Autonomous Driving (AD) has gradually shifted towards deep neural network architectures. Although performance on benchmark datasets seems to have improved, many real-world challenges have not been adequately considered in research.This article extensively surveys the application of computer vision in ITS and AD, discussing challenges related to data, models, and complex urban environments.The challenges of data are related to the collection and labeling of training data and its relevance to real-world conditions, inherent biases in datasets, the large volume of data that needs to be handled, and privacy issues.Deep Learning (DL) models are often too complex for real-time processing on embedded hardware, lacking interpretability and generalizability, and are difficult to test in real-world environments.
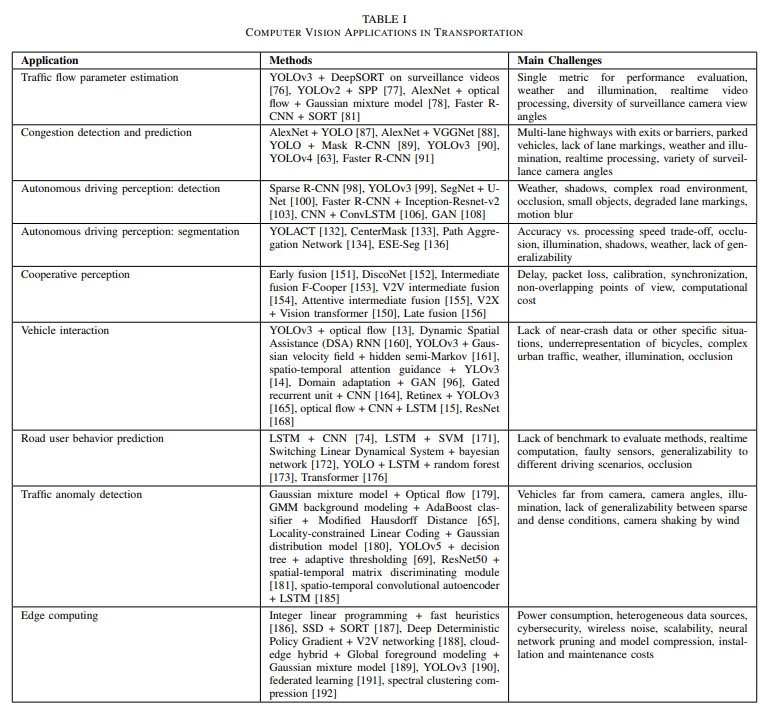
Although some literature has mentioned these issues, only a few methods have been developed to address them. Computer vision in intelligent transportation is a very active research field, and this article selects and reviews over 200 papers. Figure 1 summarizes the applications and challenges for quick reference, while Table 1 summarizes the methods used and related challenges for each application. The following sections (II, III, IV) discuss specific challenges related to data, models, and complex traffic environments. Section V explains some representative applications and solutions to address these challenges. Section VI outlines future directions for research in this field, and finally, Section VII presents some concluding remarks.
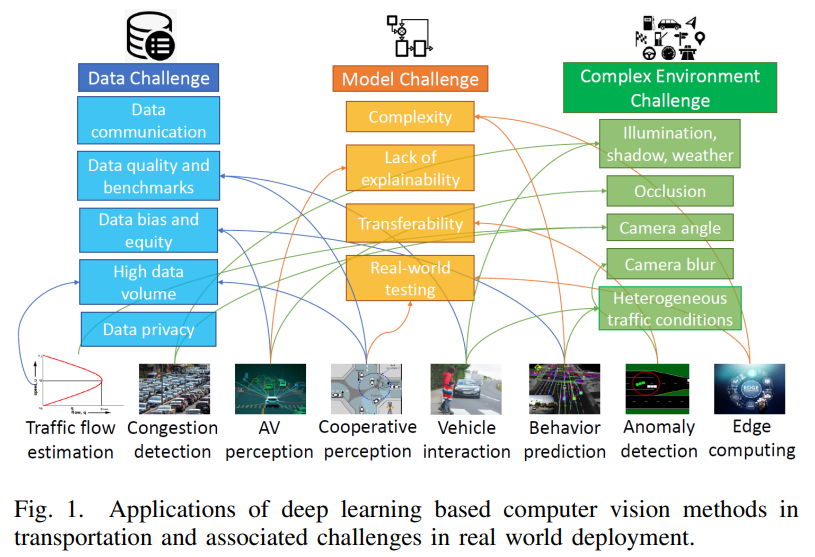
Data Challenges
1) Data Communication
Data communication, although not considered in most ITS and AV computer vision studies, is crucial for practical applications. In practice, individual camera-based deep learning tasks often require data communication between the TMC’s cameras and cloud servers. The volume of video data is large, which can lead to potential data communication issues such as transmission delays and packet loss. In a collaborative camera sensing environment, data communication occurs not only with the server but also between different sensors. Therefore, two additional issues are multi-sensor calibration and data synchronization, where calibration in collaborative environments aims to determine the perspective transformation between sensors to merge captured data from multiple views in a given frame. This task is very challenging in multi-user environments, as the transformation matrices between sensors change continuously with the movement of vehicles. In collaborative environments, calibration relies on the synchronization of elements in background images to determine transformations between static or moving sensors. There are multiple sources of desynchronization, such as clock offsets or variable communication delays. Although clocks may be synchronized, it is challenging to ensure data collection is triggered at the same moment, increasing the uncertainty in merging collected data. Similarly, different sampling rates require interpolation between collected or predicted data, which also increases uncertainty.
2) Quality of Training Data and Benchmarks
Traffic cameras are widely deployed on roads and vehicles, and DOT and city TMC constantly collect traffic camera data across networks, which is valuable for various ITS applications (such as event recognition and vehicle detection). However, labeled training data is far less common than unlabeled data. As graphical realism and simulated physics become increasingly realistic, many applications are slowly overcoming the issue of missing annotated datasets with synthetic data. For example, GT 3D information in requires high precision during training for monocular 3D detection and tracking, hence video game data is used. In addition to a realistic appearance, simulated scenes do not require manual labeling as labels are generated by the simulation and can support various lighting, viewpoints, and vehicle behaviors. However, if synthetic data is used, real-world applications still require additional learning processes, such as domain adaptation. Low-fidelity simulated data is used to train real-world object detectors with domain-randomized transfer learning. The lack of high-quality collision and near-collision data is often seen as a practical limitation, and more collision data would update attention guidelines in AD to capture long-term collision features, thereby improving collision risk assessment.
3) Data Bias
Although current vehicle detection algorithms perform well on balanced datasets, their performance on tail categories declines when faced with imbalanced datasets. In real-world scenarios, data often follows a Zipfian distribution, where a large number of tail categories have few samples. In long-tail datasets, a few head classes (frequent classes) contribute most of the training samples, while tail classes (rare classes) are underrepresented. Most DL models trained on such data minimize empirical risk for long-tail training data and are biased towards head classes since they contribute most of the training data. Some methods, such as data resampling and loss reweighting, can compensate for underrepresented classes. However, they require class divisions into several groups based on frequency. This hard partitioning between head and tail classes brings two problems: training inconsistency between adjacent classes and a lack of discernibility for rare classes.
Model Challenges
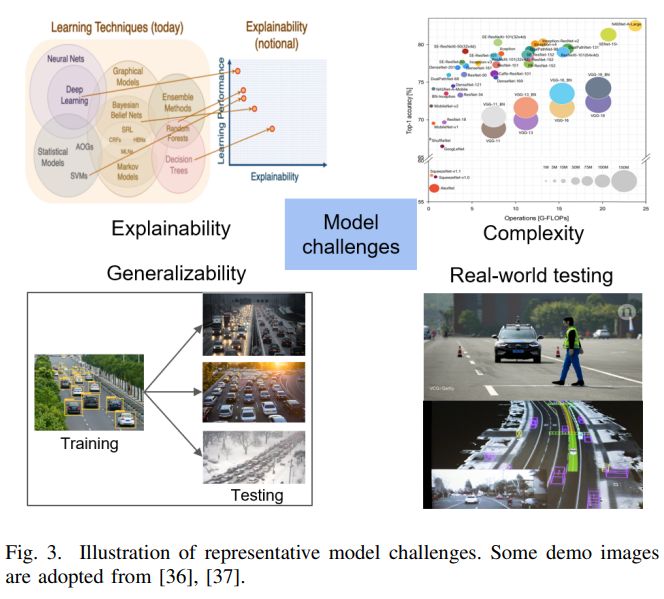
1) Complexity
DL computer vision models have high complexity in terms of neural network structure and training processes. Many DL models are designed to run on high-performance cloud centers or AI workstations, and a good model requires weeks or months of training, driven by high power consumption from GPUs or Tensor Processing Units (TPUs). Real-time applications often make some modifications, such as resizing videos to lower resolutions or model quantization and pruning, which may lead to performance loss. To meet efficiency and accuracy requirements, many practical applications require reducing the model complexity of state-of-the-art DL methods. For example, multi-scale deformable attention has been used with visual transformers for object detection to achieve high performance and rapid convergence, accelerating training and inference.
2) Lack of Interpretability
DNNs are largely seen as black boxes with multiple processing layers, whose workings can be examined using statistics, but the learned internal representations of the network are based on millions or billions of parameters, making analysis extremely difficult. This means that behaviors are inherently unpredictable, and there is little explanation for decisions, making it challenging to perform systematic validation for critical use cases like autonomous driving. It is widely believed that complex black boxes are necessary for good performance, a hypothesis that has been challenged. Recent studies have attempted to make DNNs more interpretable, introducing visualization tools for visual transformers that can be used to view internal mechanisms, such as hidden parameters, and gain insights into specific parts of the input that influence predictions.
3) Transferability and Generalizability
Generalization to non-distributed data is natural for humans but challenging for machines, as most learning algorithms strongly rely on the independent and identical distribution assumption of test data to training, which is often violated in practice due to domain shifts. Domain generalization aims to generalize models to new domains, and different methods have been proposed for learning transferable and generalizable representations. Most existing methods fall under the category of domain alignment, where the main idea is to minimize differences between source domains to learn domain-invariant representations. Features that are invariant to source domain shifts should also be robust to any undiscovered target domain shifts. Data augmentation is a common practice used to regularize the training of machine learning models to avoid overfitting and improve generalization, which is particularly important for over-parameterized DNNs. Visual attention in neural networks can be used to highlight the image regions involved in decisions and perform causal filtering to find the most relevant parts. Methods that estimate the importance of individual pixels by using random masked versions of images and comparing output predictions are not suitable for spatiotemporal methods or those considering relationships between objects in complex environments!
4) Real-World Testing
Generally, DL methods are prone to irregularities, which occur regardless of the model type or application. In other fields, the irregularities in computer vision have been analyzed, particularly concerning DL models, such as the commonly used ResNet-50 and the scaling transfer learning image classification model Big Transfer (BiT). Studies show that while benchmark scores improve with increased model complexity and training data, testing with real-world distortions leads to poor and highly variable performance, heavily reliant on the random seed used for initializing training. Actual systems need to be efficient in memory and computation for real-time processing on various low-cost hardware. Some methods that achieve efficient and low-cost computation include parameter pruning, network quantization, low-rank factorization, and model distillation. Methods like these are effective in providing real-time trajectory predictions, but they are not end-to-end, as they assume the existence of a pre-existing target tracking system to estimate the states of surrounding vehicles.
Vulnerable road users (VRUs), such as pedestrians and cyclists, present a unique problem as they can change direction and speed very quickly and interact with the traffic environment differently than vehicles. Some major obstacles to the practical deployment of computer vision models in ITS are the heterogeneity of data sources and software, sensor hardware failures, and extreme or unusual sensing conditions. Moreover, recent frameworks (e.g., edge computing-based frameworks) directly expose a growing potential attack surface for malicious actors through wireless communication signals from a variety of heterogeneous devices with various security implementations. Deep learning models have been developed to detect these attacks, but real-time applications and online learning remain active research areas. IoV faces fundamental practical issues due to mobile vehicles presenting highly variable processing demands at edge nodes while each vehicle can simultaneously run many edge and cloud-related applications, along with poor wireless communication environments. Other challenges related to edge computing for autonomous vehicles include collaborative perception, collaborative decision-making, and network security, where attackers can use lasers and bright infrared light to interfere with cameras and LiDAR, alter traffic signs, and replay attacks through communication channels. A visual description of the model challenges is shown in Figure 3!
Complex Environments
1) Shadows, Lighting, Weather
Shadows, adverse weather, similarity between background and foreground, strong or insufficient lighting in the real world are cited as common problems. It is well-known that the appearance of camera images is affected by adverse weather conditions such as heavy fog, sleet, snowstorms, and dust storms. A real-time collision detection method in uses Gaussian mixture models for foreground extraction and then tracks vehicles using an average moving algorithm. Vehicle position, speed, and acceleration are determined through a threshold function for collision detection. Although the computational efficiency is high, this method is severely affected in noisy, complex traffic environments and changing weather conditions. Under adverse weather conditions, the vehicles captured by the camera may suffer from underexposure, blurriness, and partial occlusion. Additionally, raindrops and snowflakes appearing in traffic scenes increase the difficulty for algorithms to extract vehicle targets. At night or in tunnels where vehicles are heading towards the camera, scenes may be completely obscured due to glare from high beams.
2) Occlusion
Occlusion is one of the most challenging problems, where the target object is only partially available to the camera or sensor due to another foreground object blocking it. Occlusion exists in various forms, from partial to heavy occlusion. In AD, target objects can be occluded by static objects such as buildings and lamp posts, and dynamic objects such as moving vehicles or other road users may occlude each other, for example, in crowds. Occlusion is also a common problem in object tracking, as once a tracked vehicle disappears from view and reappears, it is treated as a different vehicle, leading to inaccuracies in tracking and trajectory information.
3) Camera Angles
The diversity of monitoring cameras and their angles in traffic infrastructure applications poses challenges for DL methods trained on limited types of camera views. Although algorithms are computationally efficient and can work under different lighting conditions and traffic density scenarios, lower spacing camera views and road marking corners may introduce significant errors. Models can identify anomalies near cameras, including their start and end times, but are inaccurate for anomalies at a distance since vehicles occupy only a few pixels. An early survey of abnormal detection in surveillance videos concluded that lighting, camera angles, heterogeneous objects, and lack of real-world datasets are major challenges. Methods for sparse and dense traffic conditions are different, and there is a lack of generalizability. In multi-view visual scenes, matching objects across different views is another main issue, as multi-view ITS applications need to handle data from different images captured simultaneously by different cameras.
4) Camera Blur and Image Degradation
Monitoring cameras are affected by weather factors. Water, dust, and particulate matter can accumulate on lenses, leading to degraded image quality. Strong winds can cause camera shake, resulting in motion blur across the entire image. The front cameras on autonomous vehicles also face this issue, as insects can hit the glass, creating blind spots in the camera’s field of view. Specifically, target detection and segmentation algorithms are greatly affected; unless prepared in the model, erroneous detections can lead to severe safety issues in AD and miss important events in monitoring applications. Some methods to address this issue include training with degraded images, image restoration preprocessing, and fine-tuning pretrained networks to learn from degraded images. For example, a dense Gram network has been used to improve image segmentation performance in degraded images.
5) Heterogeneous Urban Traffic Conditions
Dense urban traffic scenes are filled with complex visual elements, not only in quantity but also in the variety of vehicles and their interactions. The presence of cars, buses, bicycles, and pedestrians at the same intersection is a significant issue for autonomous navigation and trajectory calculation. Different sizes, turning radii, speeds, and driver behaviors further complicate interactions between these road users. From a DL perspective, it is easy to find videos of heterogeneous urban traffic, but labeling ground truth is time-consuming. Simulation software often fails to capture the complex dynamics of such scenes, especially the rule-breaking behaviors that occur in dense urban centers. In fact, a specific dataset has been created to represent these behaviors. A simulator for uncontrolled dense traffic has been created, which is useful for autonomous driving perception and control but does not represent the trajectories and interactions of real road users.

Applications
1) Traffic Flow Estimation
Models and Algorithms: Traffic flow variables include traffic volume, density, speed, and queue length. Algorithms and models used to detect and track targets to estimate traffic flow variables from videos can be divided into one-stage and two-stage methods. In one-stage methods, variables are estimated based on detection results without further classification and location optimization, such as: 1) YOLOv3 + DeepSORT tracker; 2) YOLOv2 + spatial pyramid pooling; 3) AlexNet + optical flow + Gaussian mixture model; 4) CNN + optical flow based on drone video; 5) SSD (single-shot detection) based on drone video. Two-stage methods first generate region proposals containing all potential targets in the input image, followed by classification and location optimization. Examples of two-stage methods include: 1) Faster R-CNN + SORT tracker; 2) Faster R-CNN; 3) Faster R-CNN based on drone video.
Current Methods to Overcome Challenges: A DL method at the edge of ITS is proposed that performs real-time vehicle detection, tracking, and counting in traffic monitoring videos. The neural network captures appearance features using the YOLOv3 object detection method, detecting individual vehicles at a single frame level, and this method is deployed on edge devices to minimize bandwidth and power consumption. A method for vehicle detection and tracking that achieves an optimal trade-off between accuracy and detection speed in various traffic environments under adverse weather conditions is also discussed. Additionally, a new dataset called DAWN has been introduced for vehicle detection and tracking under adverse weather conditions such as heavy fog, rain, snow, and dust storms to reduce training bias.
2) Traffic Congestion Detection
Models and Algorithms: Computer vision-based traffic congestion detection methods can also be divided into single-stage and multi-step methods. Single-stage methods identify vehicles from video images and directly perform traffic congestion detection.
Current Methods to Overcome Challenges: Using sensor fusion solutions based on multiple sensors (including radar, laser, and sensor fusion) can improve congestion detection performance, as achieving ideal performance and accuracy with a single sensor in real-world scenarios is challenging. Decision algorithms are widely used to process fused data obtained from multiple sensors. CNN-based models trained on datasets of adverse weather conditions can improve detection performance, while style transfer methods based on Generative Adversarial Networks (GANs) have also been applied. These methods help minimize model challenges related to generalizability, thereby improving performance in the real world.
3) Autonomous Driving Perception: Detection
Models and Algorithms: Common detection tasks to assist AD are divided into traffic sign detection, traffic signal detection, road/lane detection, pedestrian detection, and vehicle detection.
Current Methods to Overcome Challenges: In traffic sign detection, existing traffic sign datasets are limited in terms of the types and severity of challenging conditions. Metadata corresponding to these conditions is unavailable, and due to the simultaneous change of many conditions, the influence of individual factors cannot be investigated. To overcome this issue, the CURE TSDReal dataset has been introduced, which is based on simulated conditions corresponding to real-world environments. An end-to-end traffic sign detection framework called Feature Aggregation Multi-path Network (FAMN) has been proposed, consisting of two main structures: feature aggregation and multi-path network structure to address small object detection and fine-grained classification issues in traffic sign detection. A vehicle highlight information-assisted neural network for nighttime vehicle detection has been proposed, which includes two innovations: establishing a vehicle label hierarchy based on vehicle highlights and designing a multi-layer fusion vehicle highlight information network. Real-time vehicle detection under nighttime conditions has been presented, where images include flashes occupying large image areas, and the actual shape of vehicles is not well defined. By using global image descriptors and central foveal classifier grids, vehicle positions can be estimated accurately and effectively. AugGAN is a non-paired image-to-image translation network for vehicle detection domain adaptation. With better image object preservation, it surpasses competing methods in achieving higher nighttime vehicle detection accuracy. A stepwise domain adaptation (SDA) detection method has been proposed to further improve CycleGAN’s performance by minimizing differences in cross-domain object detection tasks. In the first step, an unpaired image-to-image translator is trained to construct a pseudo target domain by translating source images into similar images in the target domain. In the second step, to further minimize cross-domain differences, an adaptive CenterNet is designed to align distributions at the feature level through adversarial learning.
4) Autonomous Driving Perception: Segmentation
Models and Algorithms: Image segmentation includes three sub-tasks: semantic segmentation, instance segmentation, and panoptic segmentation. Semantic segmentation is a fine-grained prediction task that labels each pixel of the image with the corresponding object class, instance segmentation aims to identify and segment the pixels belonging to each object instance, while panoptic segmentation unifies semantic segmentation and instance segmentation, providing class labels and instance IDs for all pixels.
Current Methods to Overcome Challenges: Recent segmentation directions include weakly supervised semantic segmentation, domain adaptation, multi-modal data fusion, and real-time semantic segmentation. TS Yolo is a CNN-based model for accurate traffic detection using new samples under adverse weather conditions through data augmentation. Data augmentation is performed using a copy-paste strategy, and a large number of new samples are constructed from existing traffic sign instances. MixConv is also used based on YoloV5 to mix different kernel sizes in a single convolution operation, allowing the capture of patterns with different resolutions. Detecting and classifying small traffic signs in real-life from large input images is challenging, as they occupy fewer pixels relative to larger targets. To address this issue, Dense RefineDet applies a single-shot object detection framework to maintain an appropriate accuracy-speed trade-off. An end-to-end traffic sign detection framework called Feature Aggregation Multi-path Network has been proposed to address small object detection and fine-grained classification issues in traffic sign detection.
5) Collaborative Perception
Models and Algorithms: In connected autonomous vehicles (CAV), collaborative perception can be performed at three levels based on data type: early fusion (raw data), intermediate fusion (pre-processed data), and late fusion (processed data), where intermediate neural features are extracted and transmitted, sharing detection outputs (3D bounding box locations, confidence scores). Collaborative perception research focuses on how to utilize visual clues from adjacent connected vehicles and infrastructure to improve overall perception performance!
1) Early Fusion: A point cloud-based 3D object detection method is proposed that fuses sensor data collected from connected vehicles at different locations and angles using raw data level LiDAR 3D point clouds to handle the diversity of aligned point clouds. DiscoNet enhances training by distilling knowledge, constraining corresponding features to the features used for early fusion.
2) Intermediate Fusion: F-Cooper provides a new framework for edge applications, serving autonomous driving vehicles and providing new strategies for 3D fusion detection. A vehicle-to-vehicle (V2V) method for perception and prediction transmits compressed intermediate representations of P&P neural networks. An attention-based intermediate fusion pipeline is proposed to better capture interactions between connected agents within the network, and a robust collaborative perception framework with vehicle-to-everything (V2X) communication using a novel visual transformer is presented.
3) Late Fusion: Car2X-based perception is modeled as a virtual sensor to integrate into advanced sensor data fusion architectures.
Current Methods to Overcome Challenges:
To reduce communication load and overhead, an improved algorithm for message generation rules in collective perception is proposed, enhancing the reliability of V2X communication by reorganizing the transmission and content of collective perception messages. A unified collaborative perception framework containing decentralized data association and fusion processes has been proposed and evaluated, which can scale based on participant variance. By employing existing models and simplifying algorithms for the views of individual vehicle onboard sensors, the assessment considers the impact of communication loss in self-organizing V2V networks and random vehicle movements in traffic. AICP is proposed as the first solution focusing on optimizing the informativeness of universal collaborative perception systems through effective filtering at the network and application layers. To facilitate system networking, they also utilize a network protocol stack that includes specialized data structures and lightweight routing protocols designed for information-dense applications!
6) Road User Behavior Prediction
Models and Algorithms: Trajectory prediction from videos is very useful for autonomous driving, traffic prediction, and congestion management. Older work in this field focused on homogeneous agents, such as cars on highways or pedestrians in crowds, while heterogeneous agents were only considered in sparse scenarios with certain assumptions, such as lane-based driving.
Current Methods to Overcome Challenges: The Switching Linear Dynamic System (SLDS) describes the dynamics of vulnerable road users and extends dynamic Bayesian networks using features extracted from onboard stereo cameras, focusing on static and dynamic cues. This method can work in real-time, providing accurate predictions of road user trajectories, which can be improved by adding environmental factors such as traffic lights and crosswalks. The use of onboard cameras and LiDAR alongside V2V communication to predict trajectories using random forests and LSTM architectures has been explored. YOLO is used to detect cars and provide bounding boxes, while LiDAR provides fine-grained changes in position, and V2V communication transmits raw values such as steering angles to reduce prediction uncertainty and latency. The TRAF dataset is used for robust end-to-end real-time trajectory prediction from static or moving cameras. Multi-vehicle tracking employs Mask R-CNN and inter-speed obstacle algorithms. As shown, tracking for the last three seconds is used to predict trajectories for the next five seconds, with the additional advantage of being end-to-end trainable without requiring annotated trajectory data. The article also provides TrackNPred, a Python-based library containing implementations of various trajectory prediction methods. It serves as a common interface for many trajectory prediction methods, allowing performance comparisons using standard error measurement metrics on real-world dense and heterogeneous traffic datasets. Most DL methods for trajectory prediction do not reveal the underlying reward functions; instead, they rely solely on previously seen examples, hindering generalizability and limiting their scope. In reverse reinforcement learning, it has been used to find reward functions, allowing the model to have a specific goal, enabling deployment in any environment. Transformer-based motion prediction is performed to achieve state-of-the-art multi-modal trajectory prediction in the Agroverse dataset. The network models the interactions between road geometry and vehicles. Predicting pedestrian intentions in complex urban scenes using spatiotemporal graph convolutional networks considers the relationship between pedestrians waiting to cross and vehicle movements. Although 80% accuracy has been achieved across multiple datasets, it can predict crossing intentions one second in advance. On the other hand, modeling pedestrians as robots, combined with SVMs without requiring pose information, results in longer predictions but lacks consideration of contextual information.
7) Traffic Anomaly Detection
Models and Algorithms: Traffic monitoring cameras can be used to automatically detect traffic anomalies such as parking and queuing. Low-level image features, such as vehicle corners, have been used to demonstrate queue detection and queue length estimation without object tracking or background removal under different lighting conditions. Optical flow-based tracking methods can provide not only queue length but also speed, vehicle count, waiting time, and headway.
Current Methods to Overcome Challenges: Anomaly detection relies on monitoring cameras, which can provide views far down the road, but distant vehicles occupy only a few pixels, making detection challenging. Therefore, in addition to multi-grained box-level tracking, pixel-level tracking is also used. The key idea is to extract masks based on frame differences and track vehicle trajectories based on Gaussian mixture models to eliminate moving vehicles, combined with segmentation based on frame changes to eliminate parking areas. Anomaly fusion uses box and pixel-level tracking features with backtracking optimization to refine predictions. Monitoring cameras are prone to shaking in the wind, so video stabilization preprocessing is performed before vehicle detection using Faster R-CNN and Cascade R-CNN forms of two-stage vehicle detection. Effective real-time methods for anomaly detection from monitoring videos separate appearance and motion learning into two parts. First, autoencoders learn appearance features, and then 3D convolution layers can predict future frame features using latent codes from multiple past frames. Significant differences between predicted features and actual features indicate anomalies, and this model can be deployed at edge nodes near traffic cameras, where latent features seem robust to lighting and weather changes compared to pixel methods. To eliminate reliance on annotated anomaly data, an unsupervised one-class method applies spatiotemporal convolutional autoencoders to obtain latent features, stacking them together, and learning temporal patterns with sequence-to-sequence LSTMs. This method performs well on multiple real-world monitoring video datasets but does not outperform supervised training methods. Its advantage is that it can be trained on normal traffic data indefinitely without any labeled anomalies.
8) Edge Computing
Models and Algorithms: Computer vision in ITS requires efficient infrastructure for real-time data analysis. If all acquired video streams are sent to a single server, the required bandwidth and computation will not provide usable services. For example, a framework for real-time automatic fault detection using video usefulness metrics is discussed. Only videos deemed useful are transmitted to the server, and camera failures or obstructed views are automatically reported. Edge cloud-based computing can implement DL models not only for computer vision tasks but also for resource allocation and efficiency. Passive monitoring has now been replaced by an increasing number of sensor-equipped vehicles in the literature, which can collaboratively perform perception and mapping. Onboard computing resources in vehicles are often not powerful enough to process all sensor data in real time, while applications like localization and mapping may require extensive computation.
Current Methods to Overcome Challenges: A significant issue with large-scale DL is that the massive amount of data generated cannot be sent to cloud computers for training. Federated learning has become a method to address this issue, especially considering heterogeneous data sources, bandwidth, and privacy issues. Training can be performed on edge nodes or edge servers, with results sent to the cloud for aggregation in shared deep learning models. Federated learning is also robust to failures of individual edge nodes, and incremental and unsupervised learning methods have been proposed to only transfer inference data from edge nodes to the cloud, addressing bandwidth, data privacy, and power demand issues. Typically, processing data at the edge to reduce bandwidth has the pleasant side effect of anonymizing transmitted data, and another method to reduce bandwidth demands is to perform spectral clustering compression on spatiotemporal features required for traffic flow prediction. Deep learning models cannot be directly exported to mobile edge nodes as they are often computationally intensive. Neural network pruning in terms of storage and computation has been introduced, and hardware implementations of generated sparse networks have been discussed, achieving multiple orders of magnitude efficiency improvement. A general lightweight CNN model has been developed for mobile edge units, which matches or outperforms AlexNet and VGG-16 in terms of size and computation cost. Traffic flow detection based on edge computing using deep learning has been deployed, with YOLOv3 trained and pruned for real-time performance on edge devices. A comprehensive review of compact DNNs deployed for IoT applications on low-power edge computers has been conducted, noting that the diversity and number of DNN applications require an automatic model compression method that goes beyond traditional pruning techniques.
Future Directions
1) Solving Data Challenge Issues
While large amounts of data are crucial for training deep learning models, quality often limits training performance. Data management is a necessary process to include edge cases and train models based on representative data from the real world. Labeling visual data, especially in complex urban environments, is a labor-intensive task performed by humans. Speed can be accelerated by first using existing task-related object detection or segmentation algorithms for automatic labeling of data. This can then be further checked to eliminate machine errors, creating a useful labeled dataset. Datasets from multiple sensors from different views also need to be included to train collaborative perception algorithms. Collecting such data is necessarily challenging due to hardware requirements and synchronization issues, but can be accomplished using connected vehicles and instrumented intersections similar to the configuration to be deployed. Data-driven simulators using high-fidelity datasets can be used to simulate cameras and LiDAR, which can be used to train DL models with data that is difficult to capture in the real world. This approach has shown promise in end-to-end reinforcement learning for autonomous vehicle control. Domain adaptation techniques are expected to further expand to leverage synthetic data and conveniently collected data.
The subfield of transfer learning, especially few-shot learning and zero-shot learning, will widely apply expert knowledge to address the challenges of data scarcity, such as edge case identification in ITS and AD. Similarly, new unsupervised learning and semi-supervised learning models are expected to find applications in the general field of real-world computer vision. Future work on the interpretability of visual transformers will allow for more comprehensive insights through aggregate metrics based on multiple samples. Interpretability research is also expected to evaluate the differences between model-based and model-free reinforcement learning approaches. Data decentralization is a recognized trend in ITS, and based on visual tasks, multi-sensing and federated learning are inevitable future directions in ITS and AD to address issues of data privacy, large-scale data processing, and efficiency. Furthermore, using general foundational models (e.g., Florence) to learn multiple downstream tasks is a promising trend for addressing various data challenges, differing from the traditional approach of training a single model for a single task. Another mechanism is the parallelism of data processing in ITS, combined with edge computing for multi-task learning (e.g., traffic monitoring and road surveillance).
2) Solving Model Challenge Issues
Deep learning models are trained to achieve good accuracy, but real-world testing often reveals weaknesses under edge cases and complex environmental conditions. Online learning is needed for such models to continuously improve and adapt to real-world scenarios; otherwise, they cannot be practically used. If online training is not possible due to the lack of real-time feedback on prediction accuracy, performance must be periodically analyzed using manually stored and labeled real data. This can serve as an iterative feedback loop where the model does not need significant changes but requires incremental retraining based on its most challenging inputs. One possible way to partially automate this is to make predictions using multiple different redundant architectures on the same input data and confidence scores. If outputs are inconsistent or if a particular output has a low confidence score, that data point can be manually labeled and added to the training set for the next iteration.
Complex deep learning models deployed on edge devices need to improve efficiency through methods such as pruning. Simple pruning methods can improve CNN performance by over 30%, and depending on the specific architecture, models can also be divided into different functional blocks to be deployed on independent edge units to minimize bandwidth and computation time. A foreseeable future phase of edge AI is “model training and inference at the edge” without the involvement of cloud data centers!
In recent years, extensive research has been conducted on explainable AI, particularly in computer vision. Three explainable methods have been used to address neural networks: gradient-based saliency maps, class activation mapping, and activation backpropagation. These methods have been extended to graph convolutional networks, pointing out patterns in the input corresponding to classifications. General solutions for the interpretability of self-attention and co-attention transformer networks have been provided. While applying these methods to traffic applications is not straightforward, some efforts have been made to understand deep spatiotemporal neural networks that handle video object segmentation and action recognition, quantifying static and dynamic information in the network, and gaining insights into the biases learned from datasets. To mitigate the impact of occlusion, noise, and sensor failures, the development of collaborative sensing models is a necessary direction for better perception in 3D. V2X networks and visual transformers have been used for robust collaborative perception, supporting connected autonomous vehicle platforms. Connected autonomous vehicles will also host other deep learning models that can learn from new data in a distributed manner. Consensus-driven distributed perception is expected to leverage future network technologies such as 6G V2X, enabling low-latency model training for truly Level 5 autonomous vehicles.
3) Addressing Challenges in Complex Traffic Environments
Multi-modal perception and collaborative perception are necessary pathways for practical future research. Different modalities such as video, LiDAR, and audio can be combined to improve the performance of purely vision-based approaches. Audio is particularly useful for early detection of anomalies among pedestrians, such as fights or disturbances, as well as vehicles at crowded intersections, as visual clutter may not immediately reveal mechanical failures or minor accidents. Collaborative perception will allow multiple sensor views of the same environment from different vehicles to construct a common picture containing more information than any individual agent can perceive, thereby addressing occlusion and lighting issues. The trend of using transfer learning to improve model performance in real-world tasks is growing. Initially, models are trained on synthetic data and fine-tuned with task-specific data, reducing the reliability of complex one-time deep learning models and improving real-world performance through retraining on challenging urban scenes. As previously mentioned, domain adaptation, zero-shot learning, few-shot learning, and foundational models are anticipated areas of transfer learning that can be utilized for this purpose. After deployment on embedded hardware, results of the unsupervised methods described can be further improved through online learning in crowded and challenging scenes, as there is an infinite amount of unlabeled data available. An important aspect of deep learning methods for anomaly detection as described involves discussing the lack of theoretical performance analysis regarding upper limits on false positive rates in complex environments, suggesting that future research should also include this analysis. It is difficult to imagine relying solely on monitoring cameras for robust, extensive, and economical traffic anomaly detection. Methods in include traffic, network, demographic, land use, and weather data sources to detect traffic. This idea can be combined with computer vision applications to achieve better overall performance.
The future direction of edge computing applications in ITS will consider multi-source data fusion and online learning. Many factors, such as unseen vehicle shapes, new surrounding environments, variable traffic densities, and rare events, are too challenging for DL models, and this new data can be used for online training of the system. Traditional applications can be expanded using edge computing and IoV/IoT frameworks, and re-identifying vehicles from videos is becoming the most robust solution for occlusion. However, including more spatiotemporal information for learning will lead to greater memory and computation usage. Using known features, trajectories from one camera view can be matched with others at different time points. Instead of using fixed windows, similarity and quality-based adaptive feature aggregation can be generalized to many multi-target tracking tasks. Transformers are particularly useful in learning dynamic interactions between heterogeneous entities, which is especially useful for detection and trajectory prediction in crowded urban environments. They can also be used to detect anomalies and predict potential hazardous situations, such as collisions in multi-user heterogeneous scenarios!
References
[1] Deep Learning based Computer Vision Methods for Complex Traffic Environments Perception: A Review
ABOUT
关于我们
深蓝学院是专注于人工智能的在线教育平台,已有数万名伙伴在深蓝学院平台学习,很多都来自于国内外知名院校,比如清华、北大等。