
Introduction to Basic Components of CNN
1. Local Receptive Field
In images, the connections between local pixels are relatively tight, while the connections between distant pixels are relatively weak. Therefore, each neuron does not need to perceive the entire image globally but only needs to perceive local information, which can be integrated at higher levels to obtain global information. The convolution operation is the realization of the local receptive field, and it also reduces the number of parameters due to weight sharing.
2. Pooling
Pooling reduces the size of the input image, minimizing pixel information while retaining important information, primarily to reduce computational load. It mainly includes max pooling and average pooling.
3. Activation Function
The activation function is used to introduce non-linearity. Common activation functions include sigmoid, tanh, and ReLU, with the first two often used in fully connected layers and ReLU commonly found in convolutional layers.
4. Fully Connected Layer
The fully connected layer acts as a classifier in the entire convolutional neural network. The outputs from previous layers need to be flattened before entering the fully connected layer.
Classic Network Structures
1. LeNet5
Composed of two convolutional layers, two pooling layers, and two fully connected layers. The convolutional kernel is 5×5, stride=1, and the pooling layer uses max pooling.
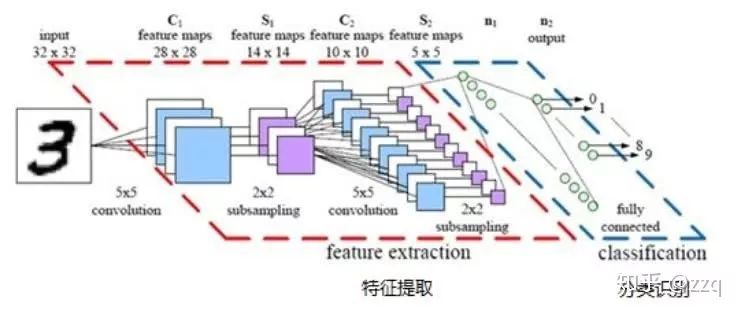
2. AlexNet
The model consists of eight layers (excluding the input layer), including five convolutional layers and three fully connected layers. The last layer uses softmax for classification output.
AlexNet uses ReLU as the activation function; it employs dropout and data augmentation to prevent overfitting; it implements dual GPU; and it uses LRN.

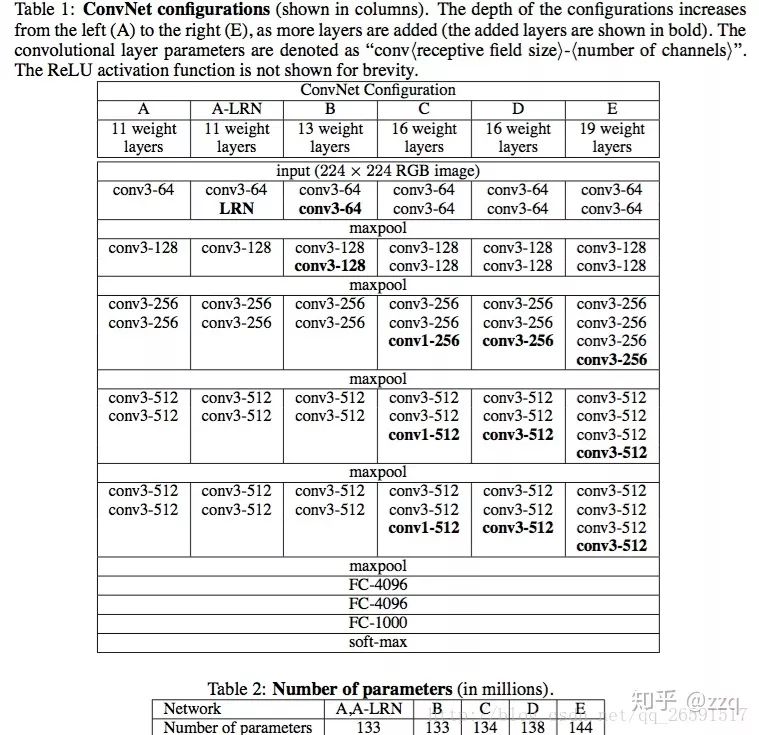
3. VGG
Uses a stack of 3×3 convolutional kernels to simulate a larger receptive field, and the network has more layers. VGG has five segments of convolution, each followed by a max pooling layer. The number of convolutional kernels increases gradually.
Summary: LRN has little effect; deeper networks perform better; 1×1 convolutions are also effective but not as good as 3×3.
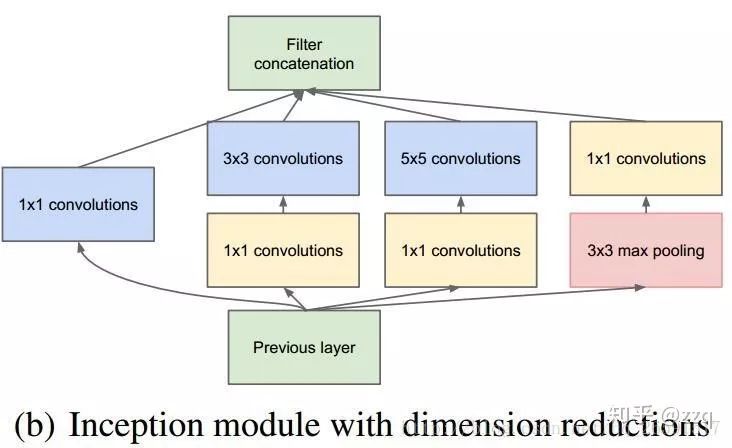
4. GoogLeNet (Inception v1)
From VGG, we learn that deeper networks yield better results. However, as the model deepens, the number of parameters increases, making the network more prone to overfitting and requiring more training data. Additionally, complex networks imply more computational load and larger model storage, requiring more resources and slower speeds. GoogLeNet is designed to reduce parameters.
GoogLeNet increases network complexity by widening the network, allowing it to choose convolutional kernels autonomously. This design reduces parameters while enhancing the network’s adaptability to multiple scales. Using 1×1 convolutions increases network complexity without adding parameters.
Inception-v2
Based on v1, batch normalization technology is added. In TensorFlow, using BN before the activation function is more effective; 5×5 convolutions are replaced with two consecutive 3×3 convolutions to deepen the network and reduce parameters.
Inception-v3
The core idea is to decompose convolutional kernels into smaller convolutions, such as decomposing 7×7 into 1×7 and 7×1, reducing network parameters while increasing depth.
Inception-v4
Introduces ResNet to accelerate training and improve performance. However, when the number of filters exceeds 1000, training becomes unstable, and an activation scaling factor can be added to mitigate this.
5. Xception
Proposed based on Inception-v3, the basic idea is depthwise separable convolutions, but with distinctions. The model parameters are slightly reduced, but accuracy is higher. Xception first performs 1×1 convolutions followed by 3×3 convolutions, merging channels before spatial convolutions. Depthwise does the opposite, performing spatial 3×3 convolutions first and then channel 1×1 convolutions. The core idea is to separate channel convolutions from spatial convolutions during convolution. MobileNet-v1 uses the depthwise order and adds BN and ReLU. Xception’s parameter count is similar to Inception-v3, increasing network width to enhance accuracy, while MobileNet-v1 aims to reduce parameters and improve efficiency.
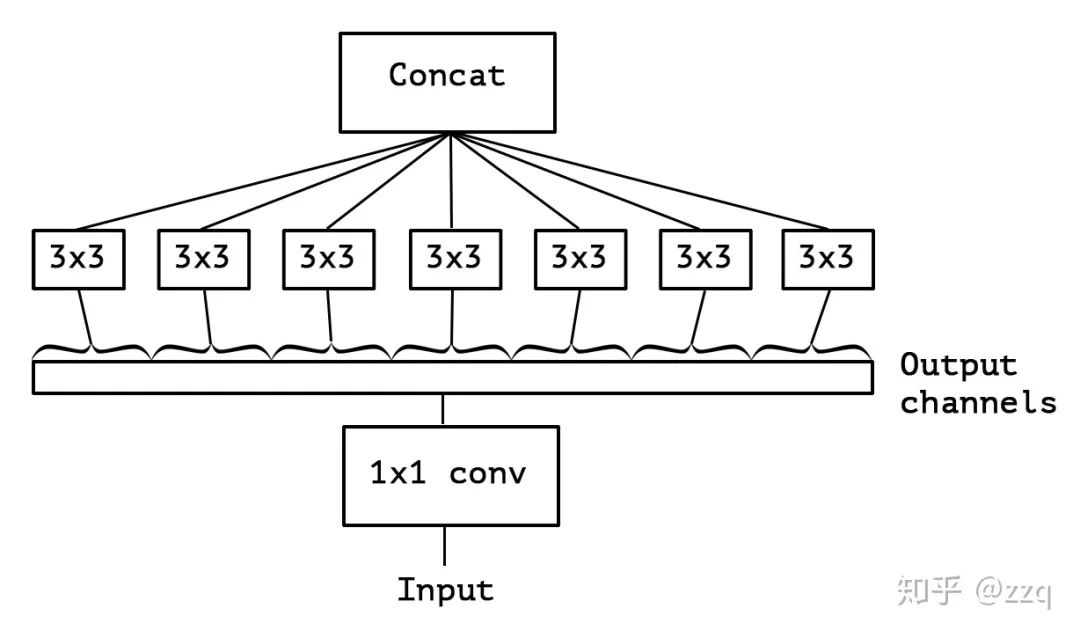
6. MobileNet Series
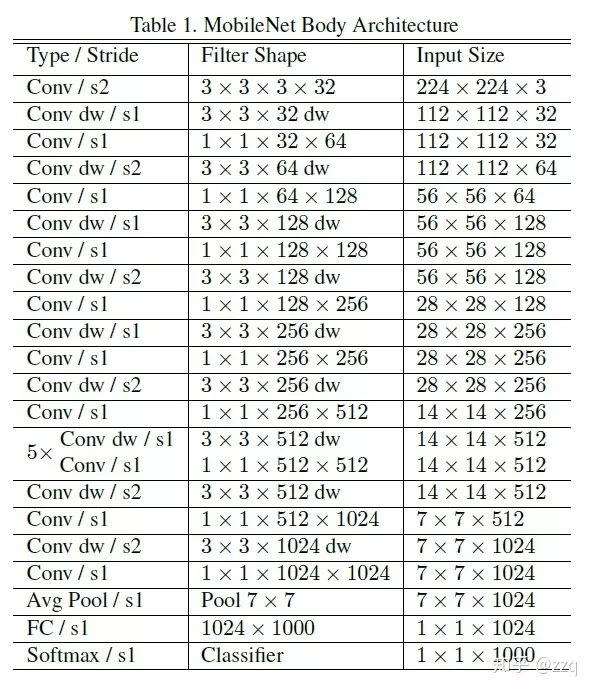
V1
Uses depthwise separable convolutions; eliminates pooling layers, using stride=2 convolutions instead. The number of channels in standard convolutions equals the number of input feature map channels; however, the depthwise convolution kernel channel count is 1. Two parameters control the input-output channel count (a) and the image (feature map) resolution (p).

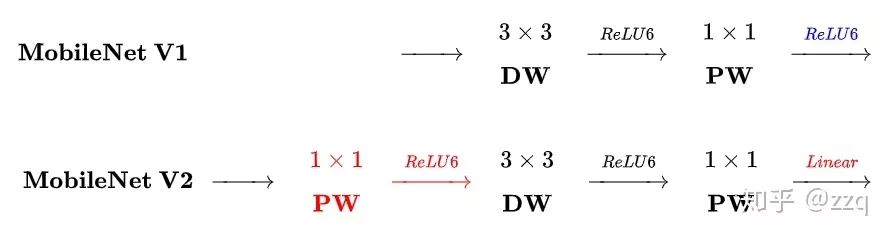
V2
Compared to v1, there are three differences: 1. Introduced residual structure; 2. A 1×1 convolution is performed before the dw to increase feature map channel count, differing from the typical residual block; 3. After pointwise, ReLU is replaced with a linear activation function to prevent ReLU from damaging features. This is because the features extracted by the dw layer are limited by the input channel count. If traditional residual blocks are used, the features that dw can extract become even fewer. Thus, initially expanding rather than compressing is preferred. However, when using expansion-convolution-compression, a problem arises where ReLU damages features. Since features are already compressed, applying ReLU will further lose some features, so linear should be used.
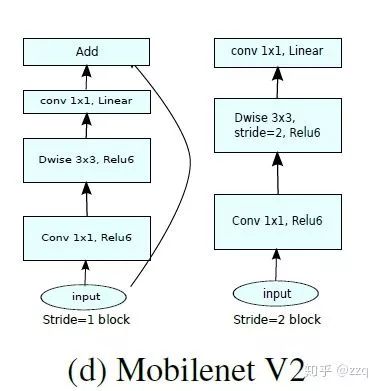
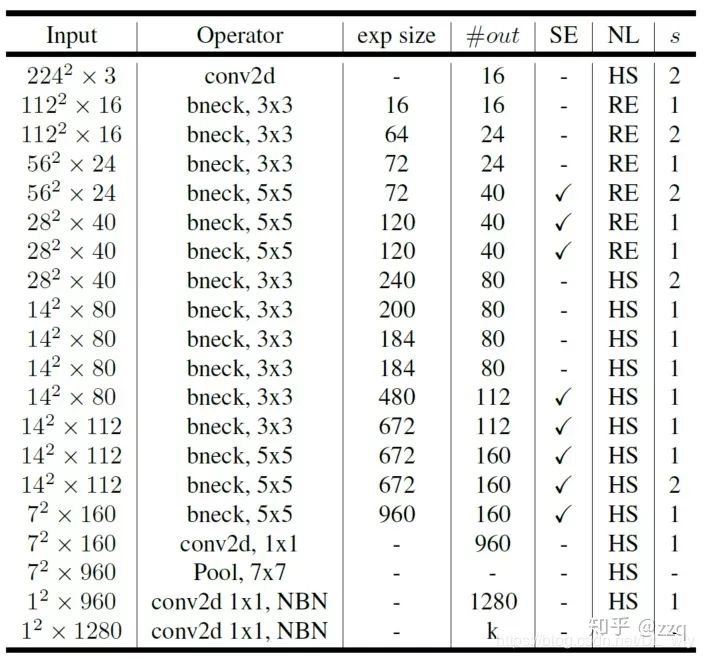
V3
Complementary search technology combination: resource-constrained NAS executes module set searches, NetAdapt executes local searches; network structure improvements: moving the last average pooling layer forward and removing the last convolutional layer, introducing h-swish activation function, modifying the initial filter group.
V3 integrates depthwise separable convolutions from v1, the linear bottleneck residual structure from v2, and the lightweight attention model of SE structure.
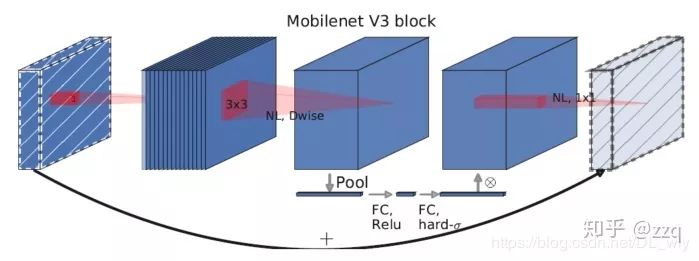
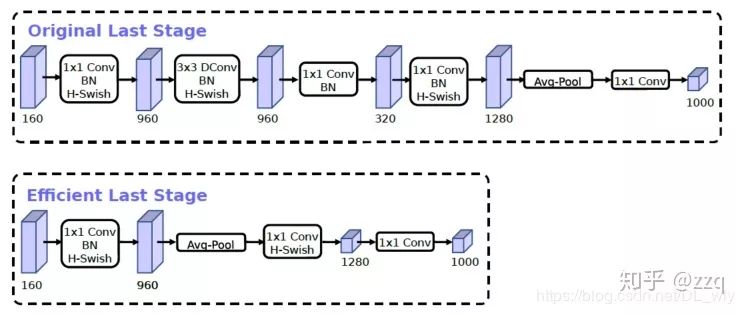
7. EffNet
EffNet is an improvement over MobileNet-v1, primarily based on the idea of decomposing the dw layer of MobileNet-1 into two 3×1 and 1×3 dw layers, allowing pooling to be applied after the first layer, thus reducing the computational load of the second layer. EffNet is smaller than MobileNet-v1 and ShuffleNet-v1 models, with higher progress.
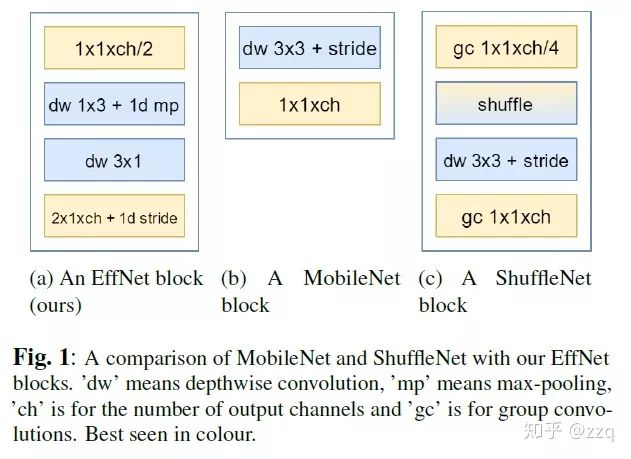
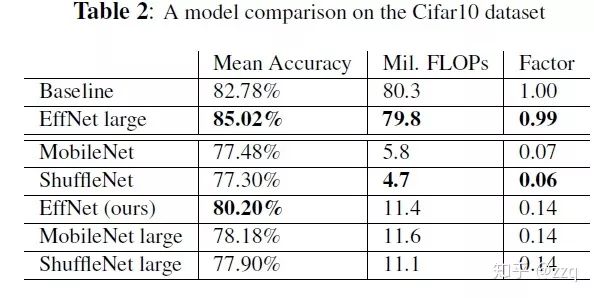
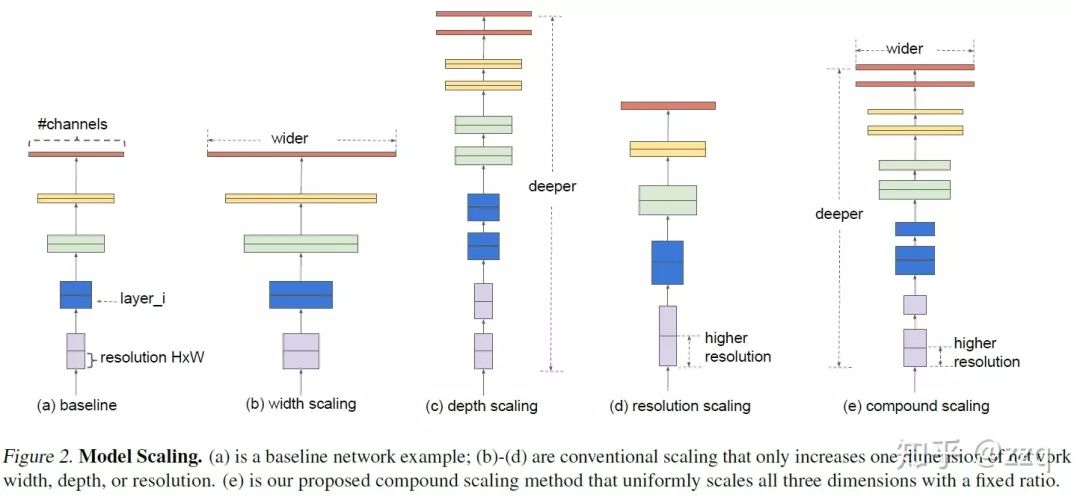
8. EfficientNet
Researches the methods of expanding network design in depth, width, and resolution, and the interrelationships between them. Higher efficiency and accuracy can be achieved.
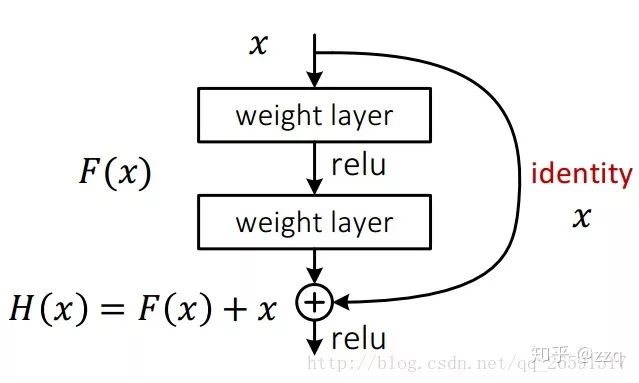
9. ResNet
VGG proves that increasing the depth of the network is an effective means to improve accuracy; however, deeper networks are prone to gradient vanishing, which can prevent convergence. Tests show that beyond 20 layers, convergence worsens with increasing depth. ResNet effectively addresses the gradient vanishing problem (actually mitigates it, not truly solves it) by adding shortcut connections.
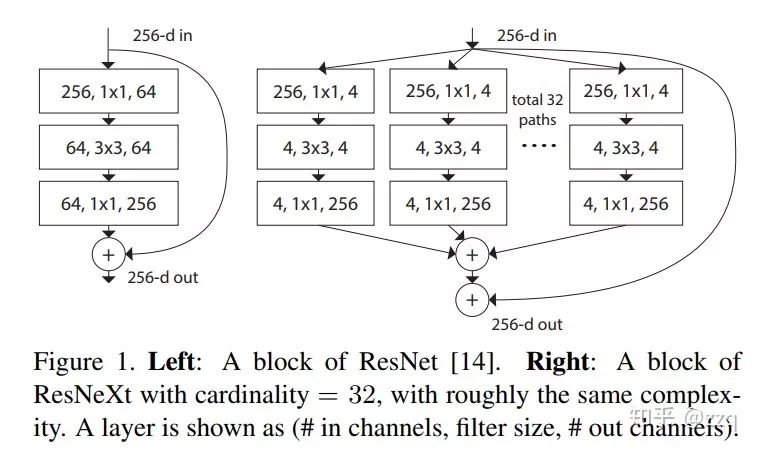
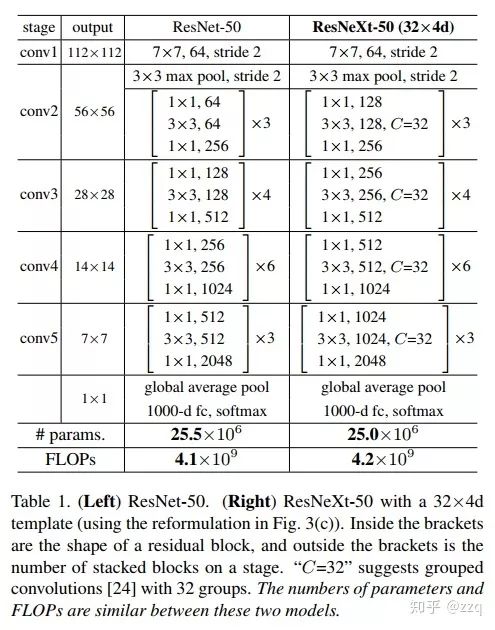
10. ResNeXt
Based on ResNet and Inception, combining split+transform+concatenate. However, its performance surpasses that of ResNet, Inception, and Inception-ResNet. Group convolution can be utilized. Generally, there are three ways to enhance network expressive power: 1. Increase network depth, such as from AlexNet to ResNet, but experimental results show that the improvement brought by depth becomes smaller; 2. Increase the width of network modules, but this inevitably leads to exponential parameter growth, which is not mainstream in CNN design; 3. Improve CNN network structure design, such as Inception series and ResNeXt. Experiments have found that increasing cardinality, or the number of identical branches in a block, can better enhance model expressive power.
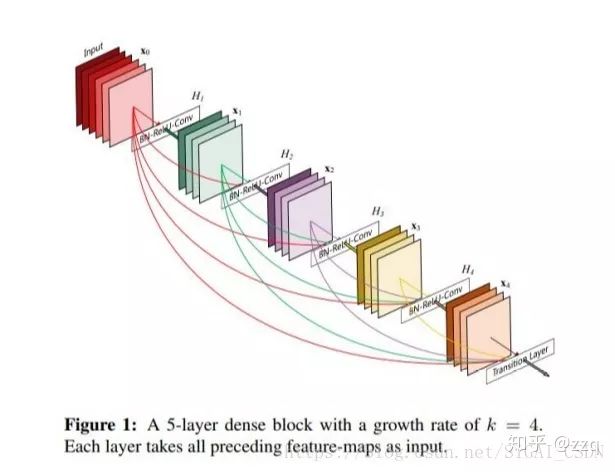
11. DenseNet
DenseNet significantly reduces the number of parameters through feature reuse and alleviates the gradient vanishing problem to some extent.
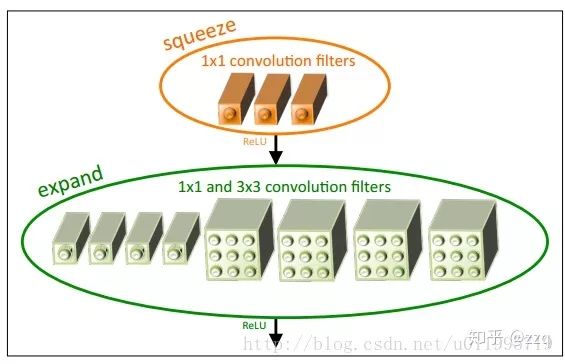
12. SqueezeNet
Proposed the fire-module: squeeze layer + expand layer. The squeeze layer uses 1×1 convolutions, while the expand layer uses both 1×1 and 3×3 convolutions, followed by concatenation. SqueezeNet has 1/50 the parameters of AlexNet and 1/510 after compression, but achieves comparable accuracy.
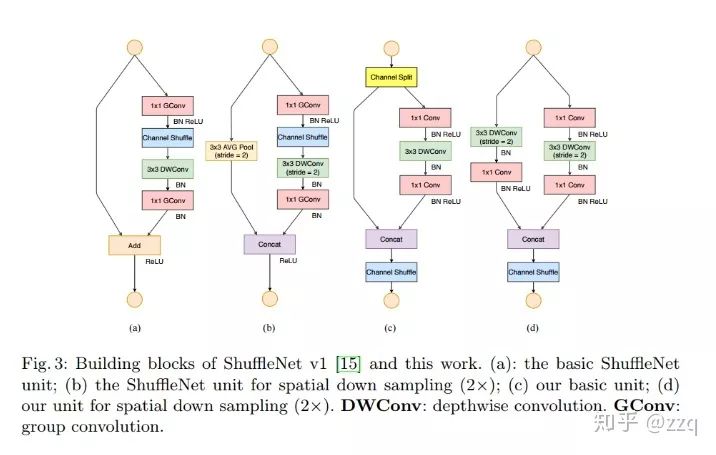
13. ShuffleNet Series
V1
Reduces computational load through grouped convolutions and 1×1 pointwise group convolutions, enriching the information of each channel through channel reorganization. Xception and ResNeXt are inefficient in small network models due to resource-intensive 1×1 convolutions, thus proposing pointwise group convolutions to lower computational complexity. However, using pointwise group convolutions can have side effects, so channel shuffle is introduced to facilitate information flow. Although dw can reduce computational and parameter load, its efficiency in low-power devices is poorer compared to dense operations; hence, ShuffleNet aims to use deep convolutions at bottlenecks to minimize overhead.
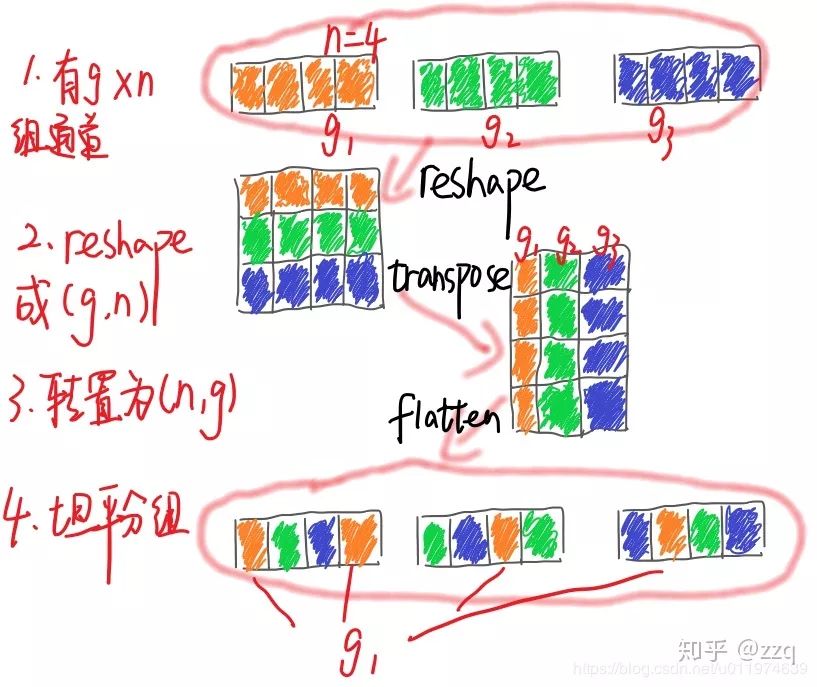
V2
Design principles for making neural networks more efficient:
Keeping the input and output channel counts equal minimizes memory access costs.
Using too many groups in grouped convolutions increases memory access costs.
Overly complex network structures (too many branches and basic units) reduce network parallelism.
Element-wise operations should not be ignored.
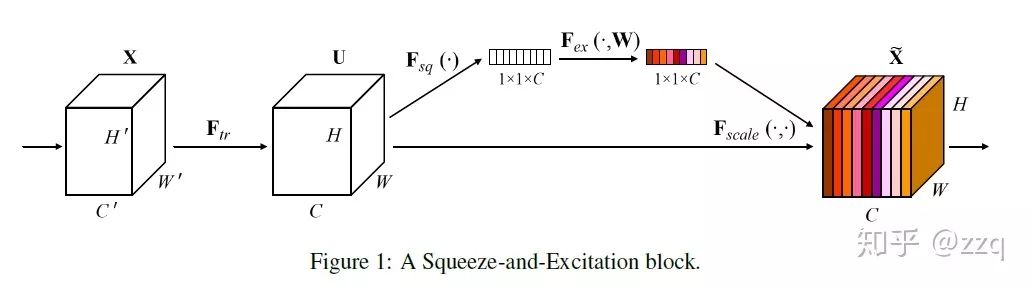
14. SENet
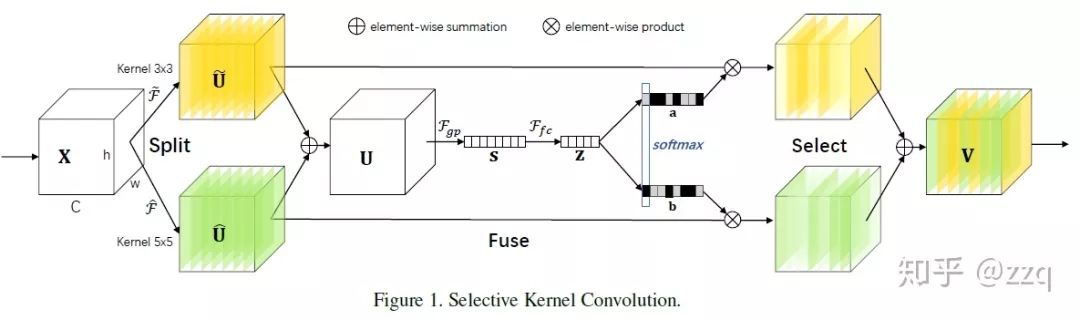
15. SKNet
—The End—
Recommended for you:
A Simple Overview of the Core Ideas of Generative Adversarial Networks (GAN)
About KN95 Masks: How Long Can They Be Used? How to Wear Them?
IBM Watson Lays Off 70% of Employees, Unveiling the Last Veil of Many Domestic Pseudo-AI Companies!
Many Universities Nationwide Postpone the Start of School, Not Just Wuhan!
13 Probability Distributions You Must Know in Deep Learning