MLNLP(Machine Learning Algorithms and Natural Language Processing) community is a well-known natural language processing community both at home and abroad, covering NLP master’s and doctoral students, university teachers, and enterprise researchers.The vision of the community is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, and the vast number of enthusiasts, especially the progress of beginners.
Reprinted from | Jishi Platform
Author | Connolly@Zhihu
Source | https://zhuanlan.zhihu.com/p/424512257
The author has been researching distributed parallel computing and frequently uses the PyTorch framework in the past two years. Initially, I had a limited understanding of PyTorch’s memory mechanism and often searched for answers on Zhihu. Therefore, I have absorbed everyone’s views and made a small summary of PyTorch’s memory mechanism.Experimental EnvironmentOS: Ubuntu 18.04, Python: 3.7.4, PyTorch: 1.9.1, GPU: V100
Table of Contents
1 Theory Knowledge1.1 Deep Learning Training Process1.2 Forward Propagation1.3 Backward Propagation1.4 Gradient Update2 Memory Analysis Method and Torch Mechanism2.1 Analysis Method2.2 Torch Memory Allocation Mechanism2.3 Torch Memory Release Mechanism3 Training Process Memory Analysis3.1 Model Definition3.2 Forward Propagation Process3.3 Backward Propagation Process3.4 Parameter Update
1
『Theory Knowledge』
1.1 Deep Learning Training Process
To put it bluntly, when PyTorch is performing deep learning training, there are four major memory overheads: model parameters, gradients of model parameters, optimizer states, and intermediate activations or intermediate results.For the convenience of subsequent memory analysis, I define the deep learning training process in four steps:
Model Definition: Defines the network structure of the model and generates model parameters;
while(you want to train):
Forward Propagation: Executes the model’s forward propagation, generating intermediate activations;
Backward Propagation: Executes the model’s backward propagation, generating gradients;
Gradient Update: Executes the update of model parameters, generating optimizer states during the first execution.
After defining the model, steps 2 to 4 are executed in a loop.
1.2 Forward Propagation
Taking the Linear layer (also known as Dense layer, feedforward neural network, fully connected layer, etc.) as an example: assuming its weight matrix is W and bias vector is b, then its forward computation process is: ,where X is the input vector of this layer, and Y is the output vector (intermediate activation value).
1.3 Backward Propagation
Referring to this article “Mathematical Principles of Neural Network Backpropagation” https://zhuanlan.zhihu.com/p/22473137Backward propagation returns an output error matrix of layer l+1 , used to calculate the gradient and input error of that layer
1.4 Gradient Update
Next, we use W_diff and b_diff for updating:Of course, when using the Adam optimizer, the actual update process is not as simple as above. Currently, the most used is AdamW, which can refer to this article “The Fastest Way to Train Neural Networks: AdamW Optimization Algorithm + Super Convergence” https://zhuanlan.zhihu.com/p/38945390)However, using this type of optimizer will also incur additional memory overhead. For each parameter, Adam prepares two corresponding optimizer states: momentum and variance, to accelerate model training.
2
『Memory Analysis Method and Torch Mechanism』
2.1 Analysis Method
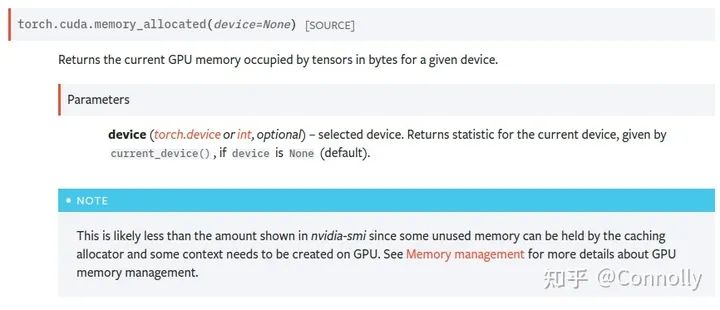
(1) No Nvidia-smiI see many people still using nvidia-smi to check PyTorch’s memory usage; isn’t it tiring to stare at the fluctuating torch cache analysis? (Here’s a picture of why Torch doesn’t use Nvidia-smi).Moreover, PyTorch has a buffer setting, meaning that even if a Tensor is released, the process will not return the freed memory to the GPU but will wait for the next Tensor to fill that released space.What are the benefits? The process does not need to reapply for memory from the GPU, which significantly speeds up execution. What are the downsides? It cannot accurately report the specific memory usage of a Tensor at a certain point in time, but rather shows the total allocated memory and the memory buffer.This is also the culprit that confuses many users regarding memory usage in PyTorch.(2) torch.cuda is all you needWhen analyzing PyTorch memory, it is essential to use the memory analysis functions in torch.cuda. The ones I use most are torch.cuda.memory_allocated() and torch.cuda.max_memory_allocated(). The former can accurately reflect the current process’s GPU memory occupied by Torch.Tensor, while the latter tells us the maximum memory usage in bytes reached up to the calling function.Functions like torch.cuda.memory_reserved() can check how much memory buffer is allocated for the current process.memory_allocated + memory_reserved equals the value in nvidia-smi.Very~good~to~useTorch Official Documentation2.2 PyTorch Context Overhead—– I didn’t mention PyTorch context overhead before, so here’s a supplement…I noticed that many students analyze memory usage to fully utilize the GPU memory during training, which I hadn’t considered before. In fact, PyTorch context is a significant overhead when using torch.The main reference is this discussion in the forum:How do I create Torch Tensor without any wasted storage space/baggage?https://discuss.pytorch.org/t/how-do-i-create-torch-tensor-without-any-wasted-storage-space-baggage/131134What is PyTorch context? Actually, its official name is CUDA context, which is created when executing the first CUDA operation, i.e., when using the GPU, to maintain relevant information for inter-device operations. As shown in the figure belowThis value is related to the CUDA version, PyTorch version, and the device used. Currently, I have tested the context overhead on RTX 3090 and V100 with torch 1.9 on Ubuntu. The context overhead for 3090 using CUDA 11.4 is 1639MB; for V100 using CUDA 10.2, it is 1351MB.Interested students can execute the following two lines of code in the shell and use nvidia-smi to check the context size in their environment. Then subtract the context size from the total size to perform memory analysis.
import torch
temp = torch.tensor([1.0]).cuda()
I estimate that someone will ask how to reduce this overhead… The official also provided a way, check which CUDA dependencies are unnecessary, such as cuDNN, and then recompile PyTorch. Set the corresponding package flags to false during compilation. I haven’t tried it yet; the compilation environment is too difficult to manage, and it often needs to be updated with libraries.
2.3 Torch Memory Allocation Mechanism
In PyTorch, memory is allocated in pages, which may be a limitation of the CUDA device. Even if we only want to request 4 bytes of memory, CUDA will allocate 512 bytes or 1024 bytes of space for us.
2.4 Torch Memory Release Mechanism
In PyTorch, as long as a Tensor object will not be used subsequently, PyTorch will automatically reclaim the memory occupied by that Tensor and continue to occupy memory in the form of a buffer.If you really don’t like the buffer, you can use torch.cuda.empty_cache() to reset it, but the program will run slower.
3
『Training Process Memory Analysis』
3.1 Model Definition
Conclusion: The memory usage is approximately the number of parameters multiplied by 4.
import torch
model = torch.nn.Linear(1024,1024, bias=False).cuda()
print(torch.cuda.memory_allocated())
The printed value is 4194304, which is exactly equal to 1024×1024×4.
3.2 Forward Propagation Process
Conclusion: The memory increase equals the sum of the memory of the results produced by each layer of the model, which is proportional to the batch_size.
In the code, outputs are the generated intermediate activation values, and they happen to be the output results of the model. After executing this step, the memory increased by 4096 bytes. (Not counting the memory of inputs)
3.3 Backward Propagation Process
Backward propagation will consume and release the model’s intermediate activation values and calculate the corresponding gradients for each parameter in the model. During the first execution, space will be allocated to store the gradients for the model parameters.
The first execution increases memory by: 4194304 bytes – size of activation; Subsequent executions reduce memory by: size of activation;Note: Since this intermediate activation value is assigned to outputs, you will find that the memory of outputs is not released during backward propagation. However, when the number of layers increases, the changes will be noticeable.To make everyone see the changes, I will write another piece of code~
optimizer.step() # First increases by 8388608, second time it remains unchanged
During the first execution, an optimizer state is initialized for each parameter. For AdamW, each parameter requires 4*2=8 bytes.From the second execution onward, no additional memory will be allocated.Memory overhead:First: increases by 8388608 bytesSecond and after: no increase or decrease3.5 NoteDue to the characteristics of computer calculations, some operations will incur additional memory overhead during the computation process. However, this overhead cannot be detected in torch.memory_allocated.For example, when AdamW updates a certain layer, it will incur temporary additional overhead equal to twice the size of that layer’s parameters. This can be seen in max_memory_allocated.In this example, it is 8388608 bytes.Technical Discussion Group Invitation
△ Press and hold to add the assistant
Scan the QR code to add the assistant on WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiaozhang-Harbin Institute of Technology-Dialogue System)to apply to join the Natural Language Processing/PyTorch technical discussion group
About Us
MLNLP Community is a grassroots academic community jointly built by natural language processing scholars from home and abroad. It has developed into a well-known natural language processing community, including well-known brands such as Top Conference Group, AI Selection, MLNLP Talent Exchange and AI Academic Exchange, aiming to promote progress between the academic and industrial sectors of machine learning and natural language processing and the vast number of enthusiasts.The community can provide an open communication platform for relevant practitioners in terms of further education, employment, and research. Everyone is welcome to follow and join us.