
Milvus Vector Database
The previous article introduced the installation and deployment of the Milvus vector database. This time, we will introduce an application example of Milvus.

With the similarity search feature of Milvus, there are many applicable scenarios:
-
• Image similarity search: Images can be searched and the most similar images can be returned immediately from a massive database.
-
• Video similarity search: By converting keyframes into vectors and then inputting the results into Milvus, it is possible to search and recommend billions of videos in near real-time.
-
• Audio similarity search: Quickly query massive audio data such as voice, music, and sound effects to find similar sounds.
-
• Recommendation system: Recommend information or products based on user behavior and needs.
-
• Question-Answering System: An interactive digital QA chatbot that automatically answers user questions.
-
• DNA sequence classification: By comparing similar DNA sequences, accurately classify genes within milliseconds.
-
• Text search engine: By comparing keywords with a text database, help users find the information they are looking for.
This time, we will introduce the combined application of Milvus and Hugging Face large models – Question-Answering System.
Hugging Face
Hugging Face is an open-source platform for natural language processing (NLP) tasks, providing a rich set of pre-trained models and datasets.
The models and datasets used this time:
Model:
https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France.
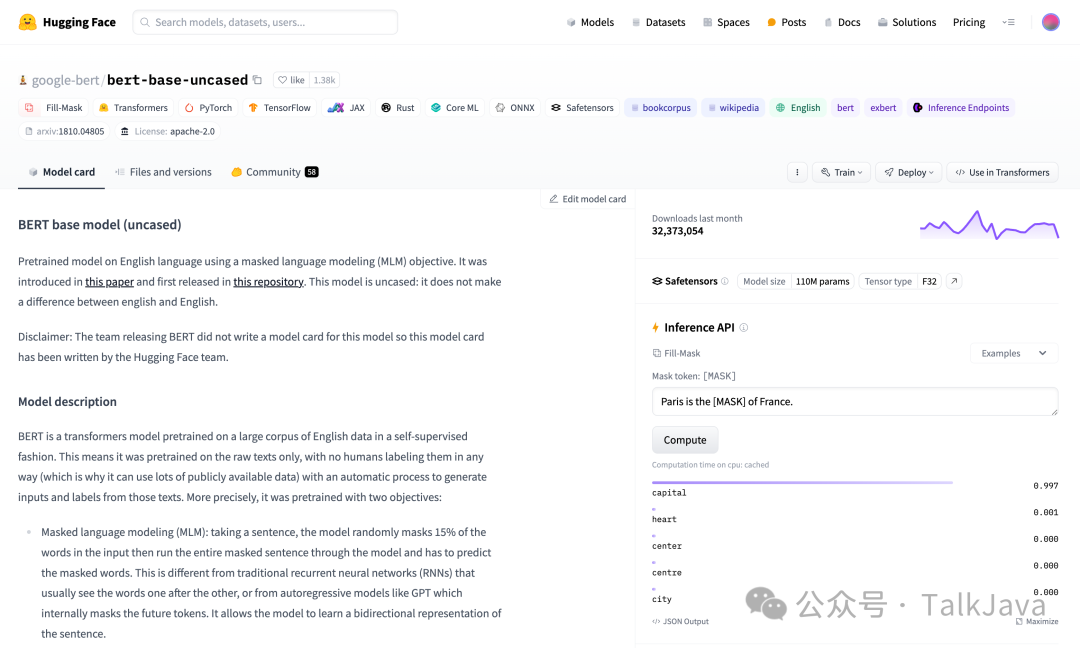
Dataset:
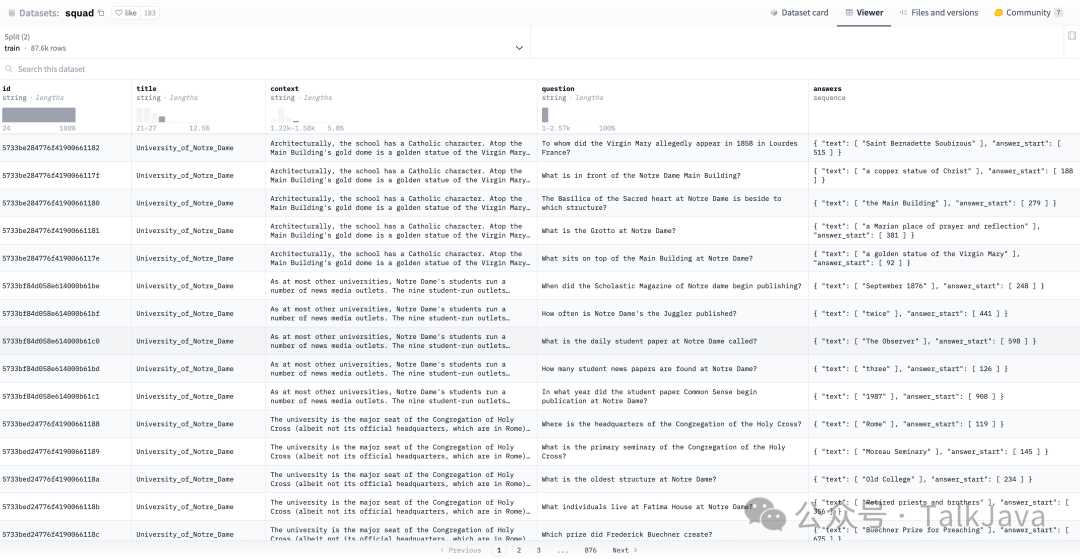
https://huggingface.co/datasets/squad
0. Before You Begin
Prepare the environment and download dependencies:
pip install transformers datasets pymilvus torch1. Create Collection
First, start Milvus locally:

Create a collection in Milvus and create an index:
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
DATASET = 'squad' # Huggingface Dataset to use
MODEL = 'bert-base-uncased' # Transformer to use for embeddings
TOKENIZATION_BATCH_SIZE = 1000 # Batch size for tokenizing operation
INFERENCE_BATCH_SIZE = 64 # batch size for transformer
INSERT_RATIO = .001 # How many titles to embed and insert
COLLECTION_NAME = 'huggingface_db' # Collection name
DIMENSION = 768 # Embeddings size
LIMIT = 10 # How many results to search for
URI = "http://192.168.153.100:19530"
TOKEN = "root:Milvus"
connections.connect(uri=URI, token=TOKEN)
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='original_question', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='answer', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='original_question_embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
index_params = {
'metric_type':'L2',
'index_type':"IVF_FLAT",
'params':{"nlist":1536}
}
collection.create_index(field_name="original_question_embedding", index_params=index_params)
print("Create index done.")2. Insert Data
After creating the collection, we start inserting data.
-
1. Tokenize the dataset’s data.
-
2. Convert the data into vectors.
-
3. Insert the question, the question’s vector, and the answer into Milvus.
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
from datasets import load_dataset_builder, load_dataset, Dataset
from transformers import AutoTokenizer, AutoModel
from torch import clamp, sum
DATASET = 'squad' # Huggingface Dataset to use
MODEL = 'bert-base-uncased' # Transformer to use for embeddings
TOKENIZATION_BATCH_SIZE = 1000 # Batch size for tokenizing operation
INFERENCE_BATCH_SIZE = 64 # batch size for transformer
INSERT_RATIO = .001 # How many titles to embed and insert
COLLECTION_NAME = 'huggingface_db' # Collection name
DIMENSION = 768 # Embeddings size
LIMIT = 10 # How many results to search for
URI = "http://192.168.153.100:19530"
TOKEN = "root:Milvus"
connections.connect(uri=URI, token=TOKEN)
data_dataset = load_dataset(DATASET, split='all')
data_dataset = data_dataset.train_test_split(test_size=INSERT_RATIO, seed=42)['test']
data_dataset = data_dataset.map(lambda val: {'answer': val['answers']['text'][0]}, remove_columns=['answers'])
tokenizer = AutoTokenizer.from_pretrained(MODEL)
def tokenize_question(batch):
results = tokenizer(batch['question'], add_special_tokens = True, truncation = True, padding = "max_length", return_attention_mask = True, return_tensors = "pt")
batch['input_ids'] = results['input_ids']
batch['token_type_ids'] = results['token_type_ids']
batch['attention_mask'] = results['attention_mask']
return batch
data_dataset = data_dataset.map(tokenize_question, batch_size=TOKENIZATION_BATCH_SIZE, batched=True)
data_dataset.set_format('torch', columns=['input_ids', 'token_type_ids', 'attention_mask'], output_all_columns=True)
model = AutoModel.from_pretrained(MODEL)
def embed(batch):
sentence_embs = model(
input_ids=batch['input_ids'],
token_type_ids=batch['token_type_ids'],
attention_mask=batch['attention_mask']
)[0]
input_mask_expanded = batch['attention_mask'].unsqueeze(-1).expand(sentence_embs.size()).float()
batch['question_embedding'] = sum(sentence_embs * input_mask_expanded, 1) / clamp(input_mask_expanded.sum(1), min=1e-9)
return batch
data_dataset = data_dataset.map(embed, remove_columns=['input_ids', 'token_type_ids', 'attention_mask'], batched = True, batch_size=INFERENCE_BATCH_SIZE)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='original_question', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='answer', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='original_question_embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
collection.load()
def insert_function(batch):
insertable = [
batch['question'],
[x[:995] + '...' if len(x) > 999 else x for x in batch['answer']],
batch['question_embedding'].tolist()
]
collection.insert(insertable)
data_dataset.map(insert_function, batched=True, batch_size=64)
collection.flush()
print("Insert data done.")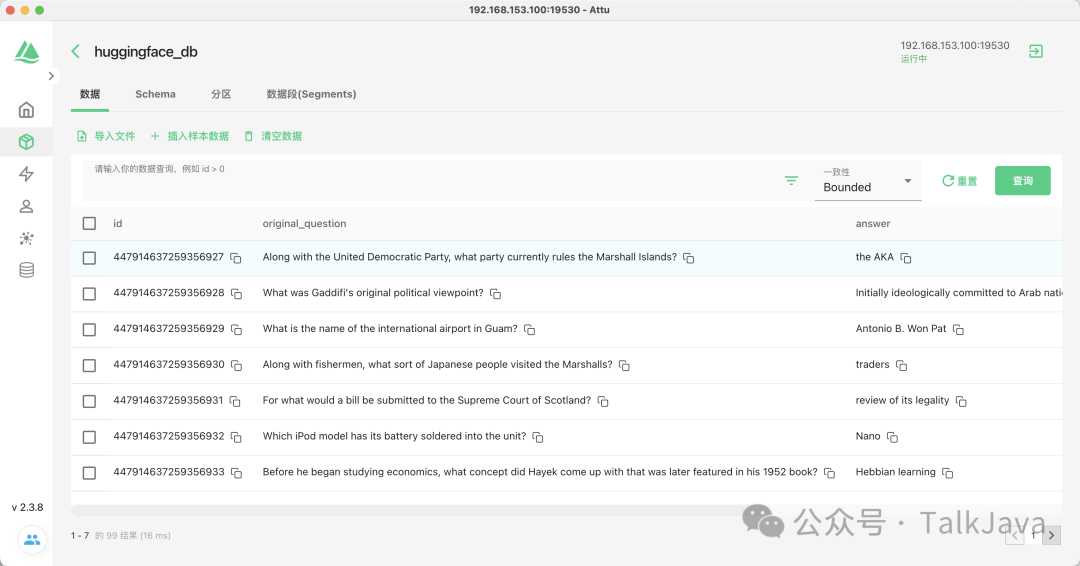
3. Ask Question
After all the data is inserted into the Milvus vector database, you can ask questions and view the most similar answers.
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
from datasets import load_dataset_builder, load_dataset, Dataset
from transformers import AutoTokenizer, AutoModel
from torch import clamp, sum
DATASET = 'squad' # Huggingface Dataset to use
MODEL = 'bert-base-uncased' # Transformer to use for embeddings
TOKENIZATION_BATCH_SIZE = 1000 # Batch size for tokenizing operation
INFERENCE_BATCH_SIZE = 64 # batch size for transformer
INSERT_RATIO = .001 # How many titles to embed and insert
COLLECTION_NAME = 'huggingface_db' # Collection name
DIMENSION = 768 # Embeddings size
LIMIT = 10 # How many results to search for
URI = "http://192.168.153.100:19530"
TOKEN = "root:Milvus"
connections.connect(uri=URI, token=TOKEN)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='original_question', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='answer', dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name='original_question_embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
collection.load()
tokenizer = AutoTokenizer.from_pretrained(MODEL)
def tokenize_question(batch):
results = tokenizer(batch['question'], add_special_tokens = True, truncation = True, padding = "max_length", return_attention_mask = True, return_tensors = "pt")
batch['input_ids'] = results['input_ids']
batch['token_type_ids'] = results['token_type_ids']
batch['attention_mask'] = results['attention_mask']
return batch
model = AutoModel.from_pretrained(MODEL)
def embed(batch):
sentence_embs = model(
input_ids=batch['input_ids'],
token_type_ids=batch['token_type_ids'],
attention_mask=batch['attention_mask']
)[0]
input_mask_expanded = batch['attention_mask'].unsqueeze(-1).expand(sentence_embs.size()).float()
batch['question_embedding'] = sum(sentence_embs * input_mask_expanded, 1) / clamp(input_mask_expanded.sum(1), min=1e-9)
return batch
questions = {'question':['When was chemistry invented?', 'When was Eisenhower born?']}
question_dataset = Dataset.from_dict(questions)
question_dataset = question_dataset.map(tokenize_question, batched = True, batch_size=TOKENIZATION_BATCH_SIZE)
question_dataset.set_format('torch', columns=['input_ids', 'token_type_ids', 'attention_mask'], output_all_columns=True)
question_dataset = question_dataset.map(embed, remove_columns=['input_ids', 'token_type_ids', 'attention_mask'], batched = True, batch_size=INFERENCE_BATCH_SIZE)
def search(batch):
res = collection.search(batch['question_embedding'].tolist(), anns_field='original_question_embedding', param = {}, output_fields=['answer', 'original_question'], limit = LIMIT)
overall_id = []
overall_distance = []
overall_answer = []
overall_original_question = []
for hits in res:
ids = []
distance = []
answer = []
original_question = []
for hit in hits:
ids.append(hit.id)
distance.append(hit.distance)
answer.append(hit.entity.get('answer'))
original_question.append(hit.entity.get('original_question'))
overall_id.append(ids)
overall_distance.append(distance)
overall_answer.append(answer)
overall_original_question.append(original_question)
return {
'id': overall_id,
'distance': overall_distance,
'answer': overall_answer,
'original_question': overall_original_question
}
question_dataset = question_dataset.map(search, batched=True, batch_size = 1)
for x in question_dataset:
print()
print('Question:')
print(x['question'])
print('Answer, Distance, Original Question')
for x in zip(x['answer'], x['distance'], x['original_question']):
print(x)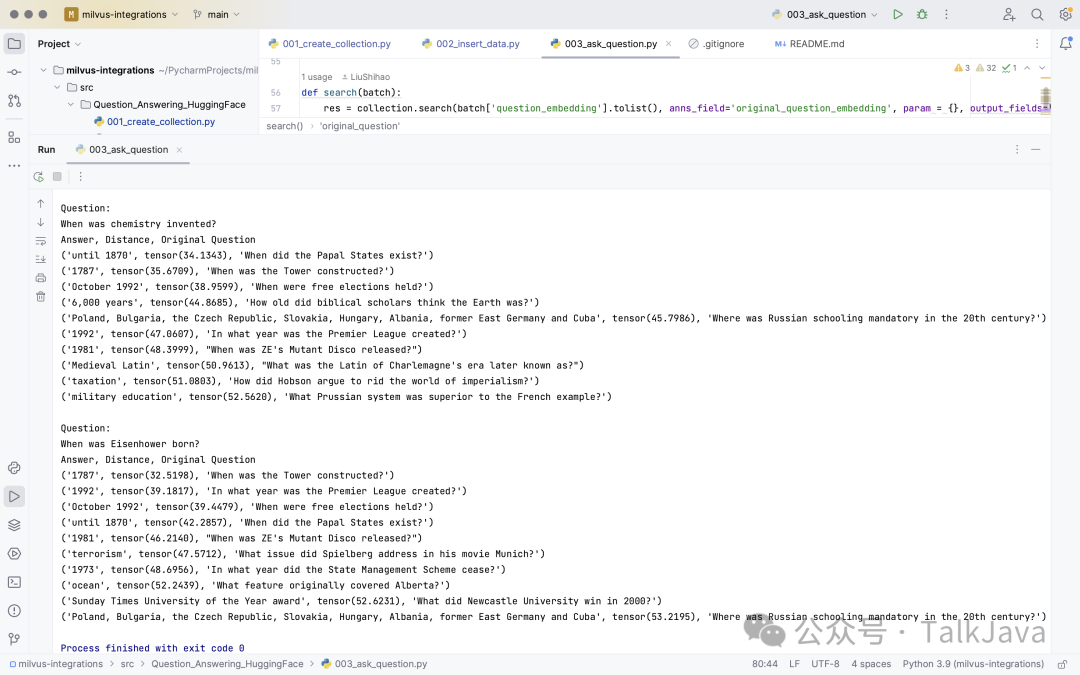
Question:When was chemistry invented?Answer, Distance, Original Question('until 1870', tensor(34.1343), 'When did the Papal States exist?')('1787', tensor(35.6709), 'When was the Tower constructed?')('October 1992', tensor(38.9599), 'When were free elections held?')('6,000 years', tensor(44.8685), 'How old did biblical scholars think the Earth was?')('Poland, Bulgaria, the Czech Republic, Slovakia, Hungary, Albania, former East Germany and Cuba', tensor(45.7986), 'Where was Russian schooling mandatory in the 20th century?')('1992', tensor(47.0607), 'In what year was the Premier League created?')('1981', tensor(48.3999), "When was ZE's Mutant Disco released?")('Medieval Latin', tensor(50.9613), "What was the Latin of Charlemagne's era later known as?")('taxation', tensor(51.0803), 'How did Hobson argue to rid the world of imperialism?')('military education', tensor(52.5620), 'What Prussian system was superior to the French example?')
Question:When was Eisenhower born?Answer, Distance, Original Question('1787', tensor(32.5198), 'When was the Tower constructed?')('1992', tensor(39.1817), 'In what year was the Premier League created?')('October 1992', tensor(39.4479), 'When were free elections held?')('until 1870', tensor(42.2857), 'When did the Papal States exist?')('1981', tensor(46.2140), "When was ZE's Mutant Disco released?")('terrorism', tensor(47.5712), 'What issue did Spielberg address in his movie Munich?')('1973', tensor(48.6956), 'In what year did the State Management Scheme cease?')('ocean', tensor(52.2439), 'What feature originally covered Alberta?')('Sunday Times University of the Year award', tensor(52.6231), 'What did Newcastle University win in 2000?')('Poland, Bulgaria, the Czech Republic, Slovakia, Hungary, Albania, former East Germany and Cuba', tensor(53.2195), 'Where was Russian schooling mandatory in the 20th century?')
This achieves a simple question-answering system.
In addition to integration with Hugging Face models, you can also integrate with OpenAI’s APIs and other models to achieve functionalities like image search, audio search, etc.
Finally
The project code has been uploaded to Github:
https://github.com/Liu-Shihao/milvus-python-demo
If you have any questions or experiences, feel free to share in the comments. If you find this article helpful, please like, comment, and share. Your support is my greatest motivation for creating.