
-
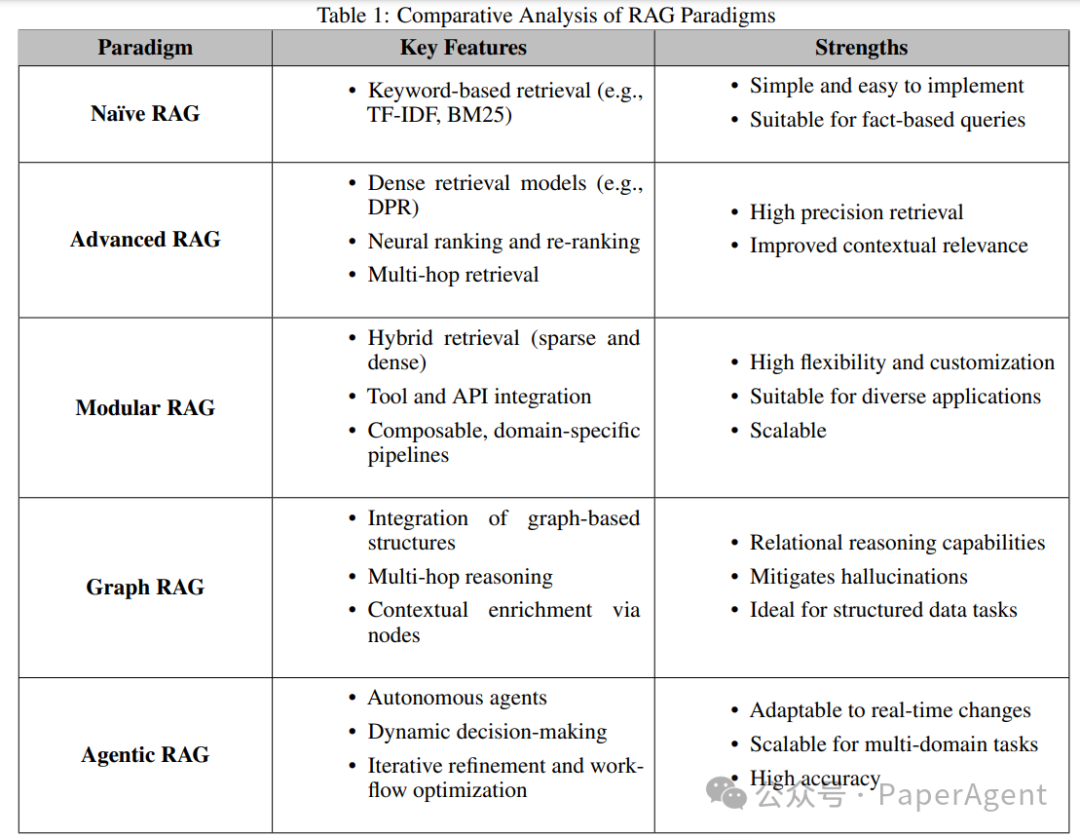
A comprehensive review of the development history of RAG, from the initial Naïve RAG to Advanced RAG, and then to Modular RAG and Graph RAG, each paradigm has its strengths and weaknesses. Agentic RAG, as the latest paradigm, achieves dynamic decision-making and workflow optimization by introducing autonomous agents. -
A detailed exploration of the fundamental principles, architectural classifications, key applications, and implementation strategies of Agentic RAG full-stack technology.
The Development History of RAG
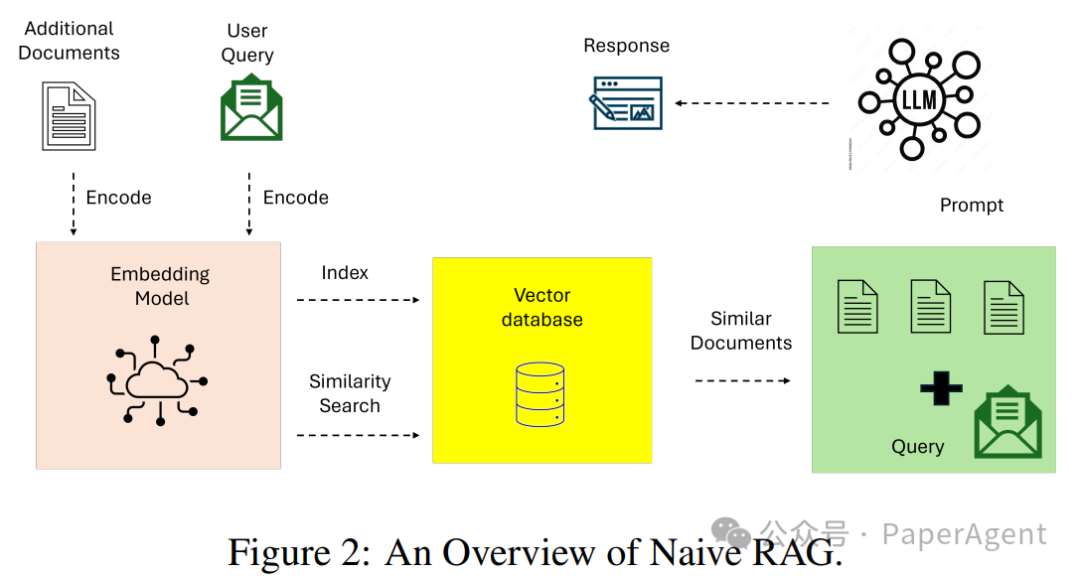
Naïve RAG
-
Lack of contextual awareness: Due to reliance on lexical matching rather than semantic understanding, retrieved documents often fail to capture the semantic nuances of queries. -
Fragmented output: The lack of advanced preprocessing or contextual integration often leads to incoherent or overly generalized answers. -
Scalability issues: Keyword retrieval techniques often fail when handling large datasets, unable to identify the most relevant information.
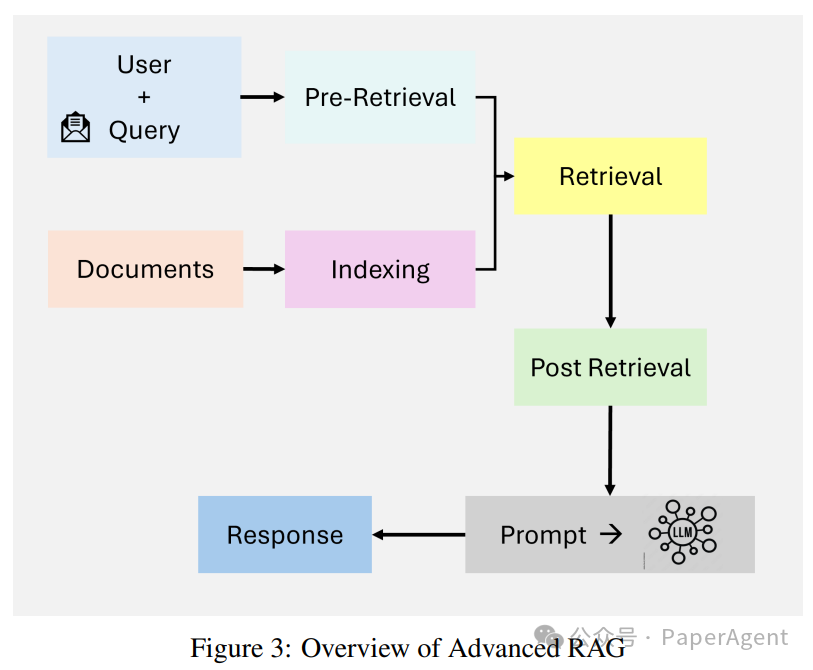
Advanced RAG
-
Dense vector search: Queries and documents are represented in high-dimensional vector space, achieving better semantic alignment between user queries and retrieved documents. -
Contextual re-ranking: Neural models re-rank retrieved documents, prioritizing the most contextually relevant ones. -
Iterative retrieval: Advanced RAG introduces a multi-hop retrieval mechanism that allows for reasoning across multiple documents for complex queries.
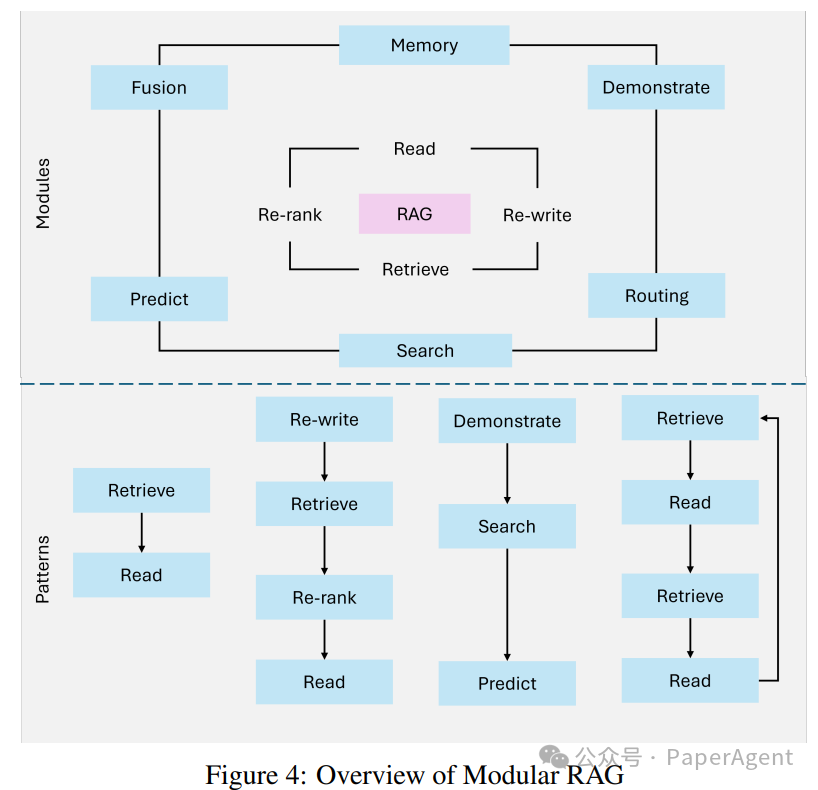
Modular RAG
-
Hybrid retrieval strategies: Combining sparse retrieval methods (e.g., sparse encoder-BM25) with dense retrieval techniques (e.g., DPR – Dense Passage Retrieval) to maximize accuracy for different query types. -
Tool integration: Integrating external APIs, databases, or computational tools to handle specialized tasks, such as real-time data analysis or computations specific to a domain. -
Composable workflows: Modular RAG allows for independent replacement, enhancement, or reconfiguration of retrievers, generators, and other components, providing high adaptability for specific use cases.
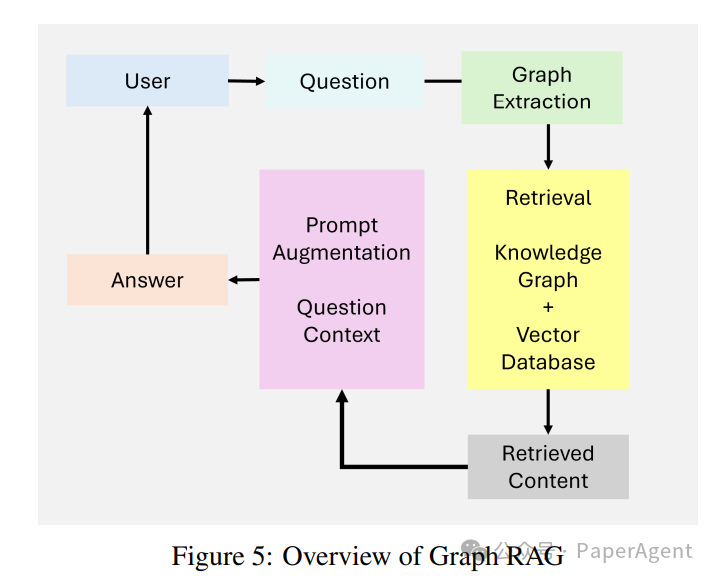
Graph RAG
-
Node connectivity: Capturing and reasoning about relationships between entities. -
Hierarchical knowledge management: Handling structured and unstructured data through graph-based hierarchies. -
Contextual richness: Adding relational understanding through graph-based paths.
-
Limited scalability: Dependence on graph structures may limit scalability, especially when data sources are extensive. -
Data dependency: High-quality graph data is crucial for meaningful outputs, limiting its applicability in unstructured or poorly annotated datasets. -
Integration complexity: Integrating graph data with unstructured retrieval systems increases design and implementation complexity.
Agentic RAG
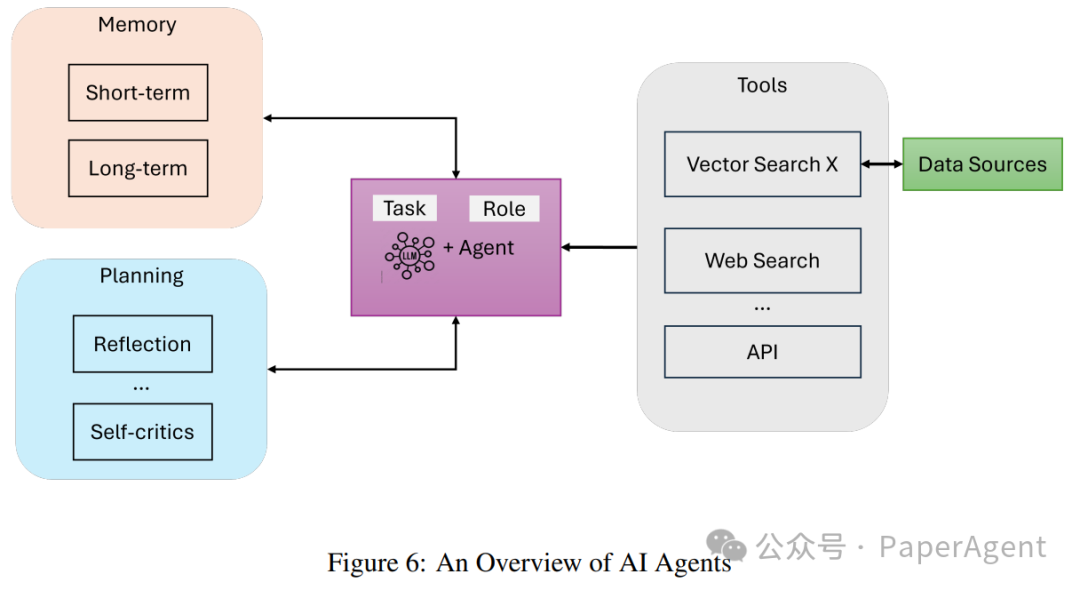
Agentic RAG Systems
Single-Agent Agentic RAG: Router
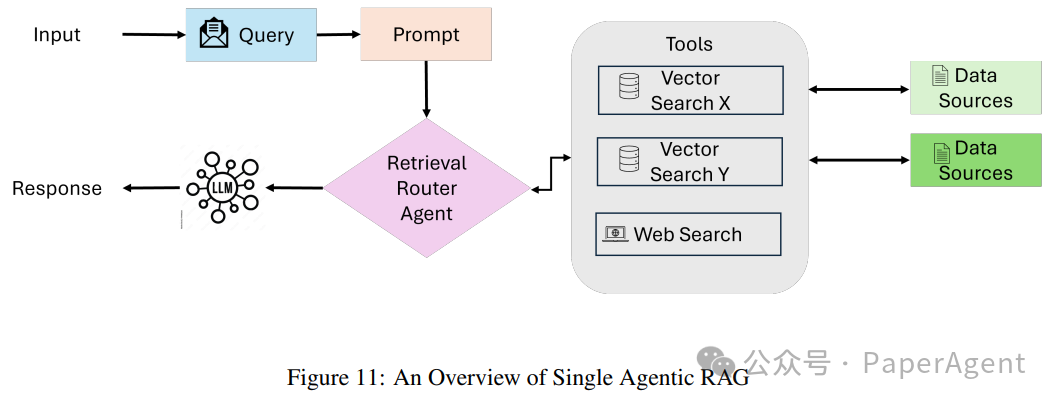
The single-agent Agentic RAG system acts as a centralized decision-making system where a single agent manages the retrieval, routing, and integration of information. This architecture simplifies the system by consolidating these tasks into a unified agent, particularly suited for settings with a limited number of tools or data sources.
-
Query submission and evaluation: The user submits a query, and the coordinating agent (or primary retrieval agent) receives the query and analyzes it to determine the most appropriate information sources.
-
Knowledge source selection: Depending on the query type, the coordinating agent selects from multiple retrieval options:
-
Structured databases: For queries requiring tabular data access, the system may interact with databases such as PostgreSQL or MySQL using a Text-to-SQL engine.
-
Semantic search: When dealing with unstructured information, vector-based retrieval is used to obtain relevant documents (e.g., PDFs, books, organizational records).
-
Web search: For real-time or broadly contextual information, the system utilizes web search tools to access the latest online data.
-
Recommendation systems: For personalized or contextual queries, the system leverages recommendation engines to provide customized suggestions.
Data integration and LLM synthesis: Relevant data retrieved from selected sources is passed to a large language model (LLM). The LLM synthesizes the collected information, integrating insights from multiple sources into coherent and contextually relevant answers.
Output generation: The system ultimately generates a comprehensive, user-oriented answer to address the original query. This answer is presented in an actionable, concise format, potentially including references or citations to the sources used.
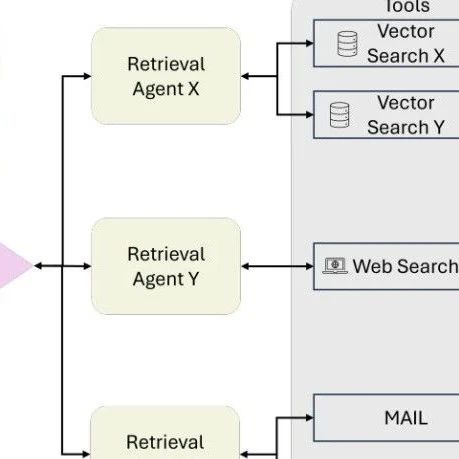
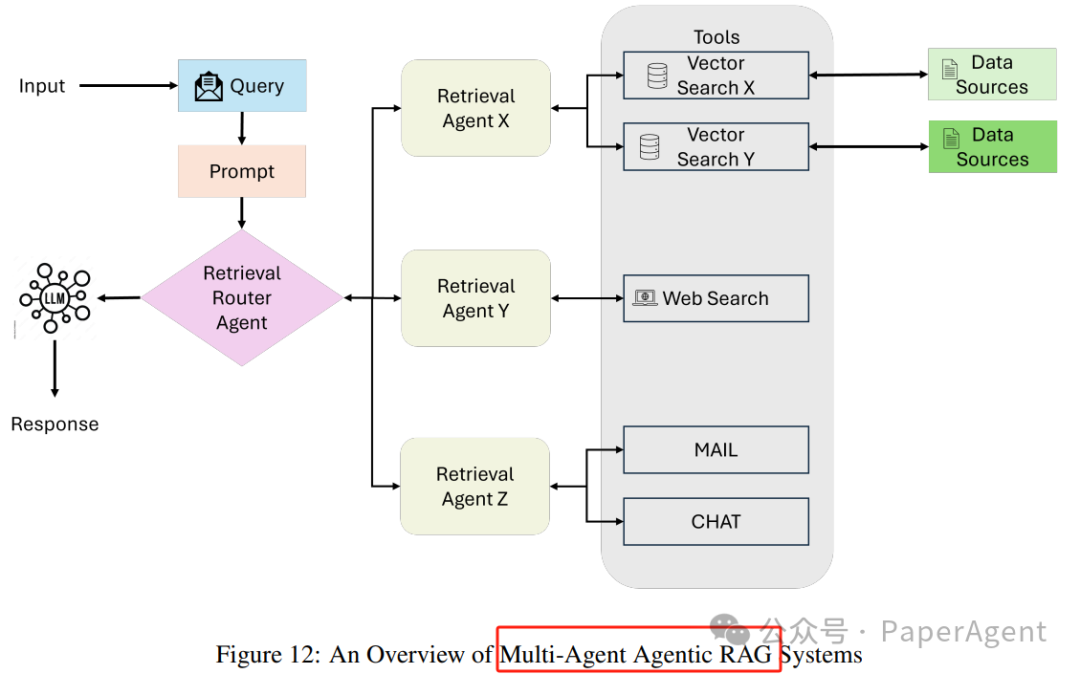
Multi-Agent Agentic RAG
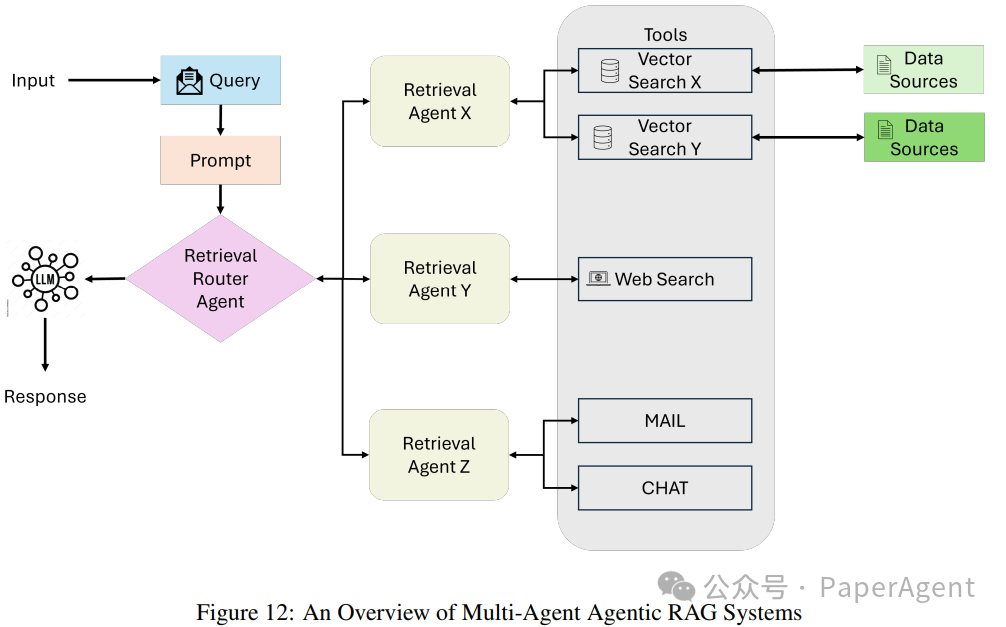
The multi-agent RAG system is a modular and scalable evolution of the single-agent architecture, leveraging multiple specialized agents to handle complex workflows and diverse query types. Unlike relying on a single agent to manage all tasks (reasoning, retrieval, and answer generation), this system distributes responsibilities among multiple agents, each optimized for specific roles or data sources.
Workflow:
-
Query submission: The user query is received by the coordinating agent or primary retrieval agent. This agent acts as a central coordinator, delegating the query to specialized retrieval agents based on the query requirements.
-
Specialized retrieval agents: Queries are distributed among multiple retrieval agents, each focusing on specific types of data sources or tasks. For example:
-
Agent 1: Handles structured queries, interacting with SQL-based databases (e.g., PostgreSQL or MySQL).
-
Agent 2: Manages semantic search, retrieving unstructured data from PDFs, books, or internal records.
-
Agent 3: Focuses on retrieving real-time public information from web searches or APIs.
-
Agent 4: Specializes in recommendation systems, providing context-aware suggestions based on user behavior or profiles.
Tool access and data retrieval: Each agent routes its query to the appropriate tools or data sources within its domain, such as:
-
Vector search: Used for semantic relevance.
-
Text-to-SQL: Used for structured data.
-
Web search: Used for real-time public information.
-
API: Used to access external services or proprietary systems. The retrieval process is executed in parallel, allowing efficient handling of diverse query types.
Data integration and LLM synthesis: Once retrieval is complete, data from all agents is passed to a large language model (LLM). The LLM synthesizes the retrieved information into coherent and contextually relevant answers, seamlessly integrating insights from multiple sources.
Output generation: The system generates a comprehensive answer, returning it to the user in an actionable and concise format.
Hierarchical Agentic RAG
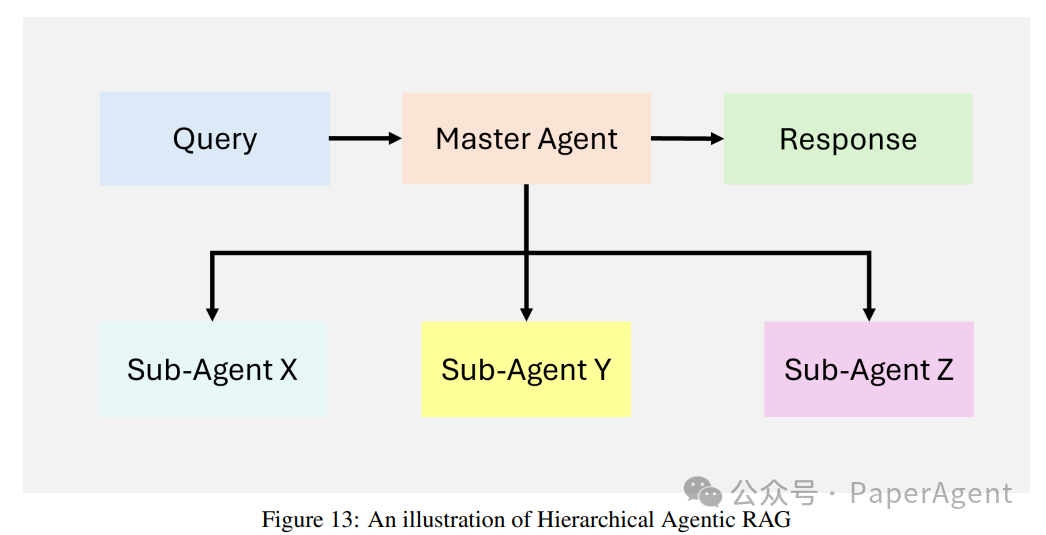
The hierarchical Agentic RAG system adopts a structured multi-level approach to information retrieval and processing, enhancing efficiency and strategic decision-making. Agents are organized hierarchically, with high-level agents overseeing and guiding lower-level agents. This structure enables multi-level decision-making, ensuring queries are handled by the most appropriate resources.
Workflow:
-
Query reception: The user submits a query, which is received by the top-level agent responsible for initial assessment and delegation.
-
Strategic decision-making: The top-level agent assesses the complexity of the query and decides which subordinate agents or data sources to prioritize. Depending on the domain of the query, certain databases, APIs, or retrieval tools may be deemed more reliable or relevant.
-
Delegation to subordinate agents: The top-level agent assigns tasks to lower-level agents specialized in specific retrieval methods (e.g., SQL databases, web searches, or proprietary systems). These agents independently execute their assigned tasks.
-
Aggregation and synthesis: The results from subordinate agents are collected and integrated by the high-level agent, which synthesizes the information into coherent answers.
-
Answer delivery: The final synthesized answer is returned to the user, ensuring it is both comprehensive and contextually relevant.
Agentic Corrective RAG
Corrective RAG introduces a mechanism for self-correcting retrieved results, enhancing document utilization and improving answer generation quality. By embedding intelligent agents within the workflow, Corrective RAG ensures iterative refinement of contextual documents and answers, minimizing errors and maximizing relevance.
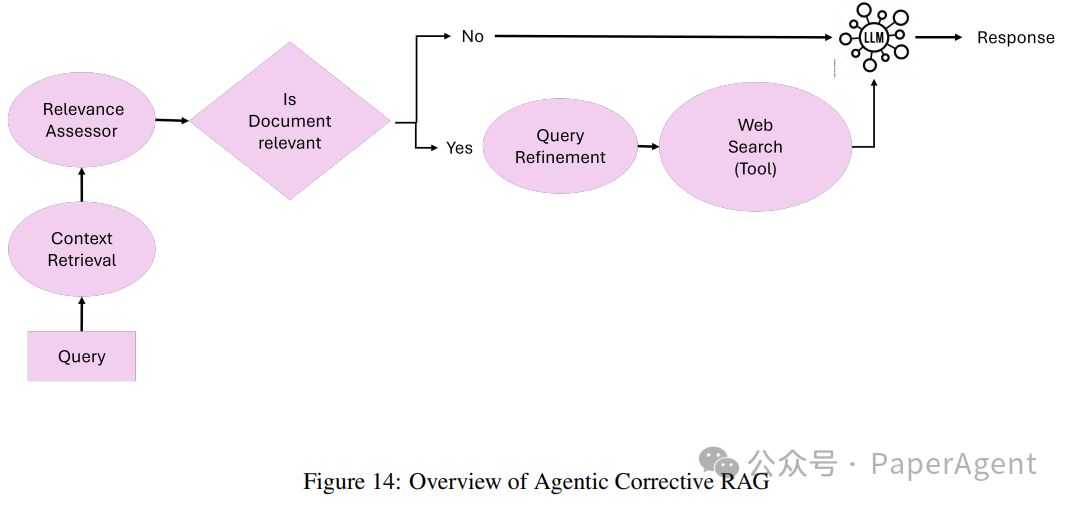
The core concept of Corrective RAG: The core principle of Corrective RAG lies in its ability to dynamically assess retrieved documents, execute corrective measures, and refine queries to improve the quality of generated answers. Corrective RAG adjusts its approach as follows:
-
Document relevance assessment: Retrieved documents are evaluated by a relevance assessment agent. Documents falling below a relevance threshold trigger corrective steps.
-
Query refinement and enhancement: Queries are refined by a query refinement agent, which utilizes semantic understanding to optimize retrieval for better results.
-
Dynamic retrieval from external sources: When contextual documents are insufficient, an external knowledge retrieval agent performs web searches or accesses alternative data sources to supplement the retrieved documents.
-
Answer synthesis: All validated and refined information is passed to an answer synthesis agent to generate the final answer.
Workflow: The Corrective RAG system is built around five key agents:
-
Context retrieval agent: Responsible for retrieving initial contextual documents from vector databases.
-
Relevance assessment agent: Evaluates the relevance of retrieved documents and flags any irrelevant or ambiguous documents for corrective measures.
-
Query refinement agent: Rewrites queries to enhance specificity and relevance of retrieval, utilizing semantic understanding to optimize results.
-
External knowledge retrieval agent: Executes web searches or accesses alternative data sources when contextual documents are insufficient.
-
Answer synthesis agent: Integrates all validated information into coherent and accurate answers.
Adaptive Agentic RAG
Adaptive retrieval-augmented generation (Adaptive RAG) enhances the flexibility and efficiency of large language models (LLMs) by dynamically adjusting query processing strategies based on the complexity of incoming queries. Unlike static retrieval workflows, Adaptive RAG employs classifiers to assess query complexity and determine the most appropriate approach, ranging from single-step retrieval to multi-step reasoning, or even skipping retrieval for simple queries.
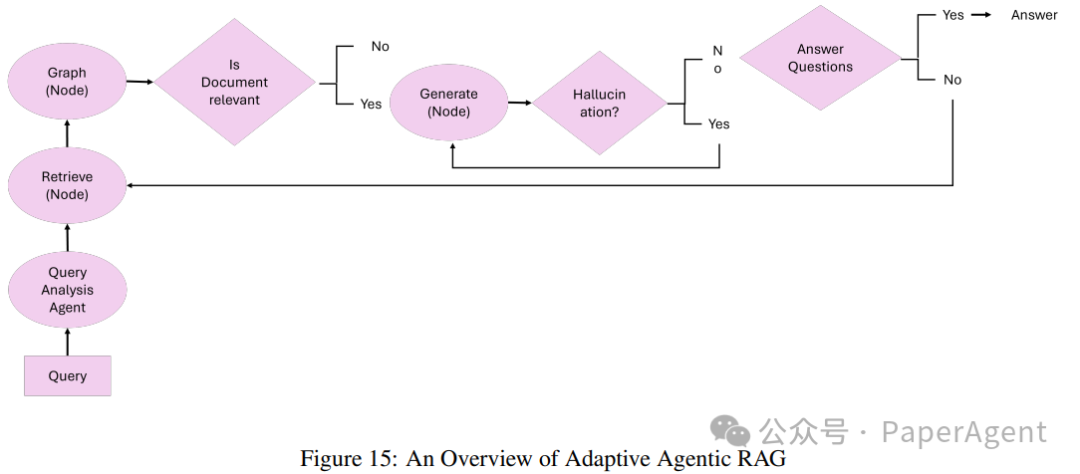
The core concept of Adaptive RAG: The core principle of Adaptive RAG lies in its ability to dynamically adjust retrieval strategies based on the complexity of queries. Adaptive RAG adjusts its approach as follows:
-
Simple queries: For fact-based questions that require no additional retrieval (e.g., “What is the boiling point of water?”), the system directly generates answers using pre-stored knowledge.
-
Moderate queries: For moderately complex tasks requiring minimal context (e.g., “What is the status of my latest electricity bill?”), the system performs single-step retrieval to obtain relevant details.
-
Complex queries: For multi-layered queries requiring iterative reasoning (e.g., “How has the population of city X changed over the past decade, and what factors contributed to this?”), the system employs multi-step retrieval to progressively refine intermediate results to provide comprehensive answers.
Workflow: The Adaptive RAG system is built around three main components:
-
Classifier role:
-
The smaller language model analyzes the query to predict its complexity.
-
The classifier is trained using an automatically labeled dataset derived from past model results and query patterns.
Dynamic strategy selection:
-
For simple queries, the system avoids unnecessary retrieval and directly utilizes the LLM to generate answers.
-
For moderate queries, it performs a single-step retrieval process to obtain relevant context.
-
For complex queries, it activates multi-step retrieval to ensure iterative refinement and enhanced reasoning.
LLM integration:
-
The LLM synthesizes the retrieved information into coherent answers.
-
Iterative interaction between the LLM and the classifier enables refinement of complex queries.
Graph-based Agentic RAG
Agent-G introduces a novel agent architecture that combines graph knowledge bases with unstructured document retrieval. By integrating structured and unstructured data sources, this framework enhances the retrieval-augmented generation (RAG) systems, improving reasoning and retrieval accuracy. It employs a modular retrieval library, dynamic agent interactions, and feedback loops to ensure high-quality outputs.
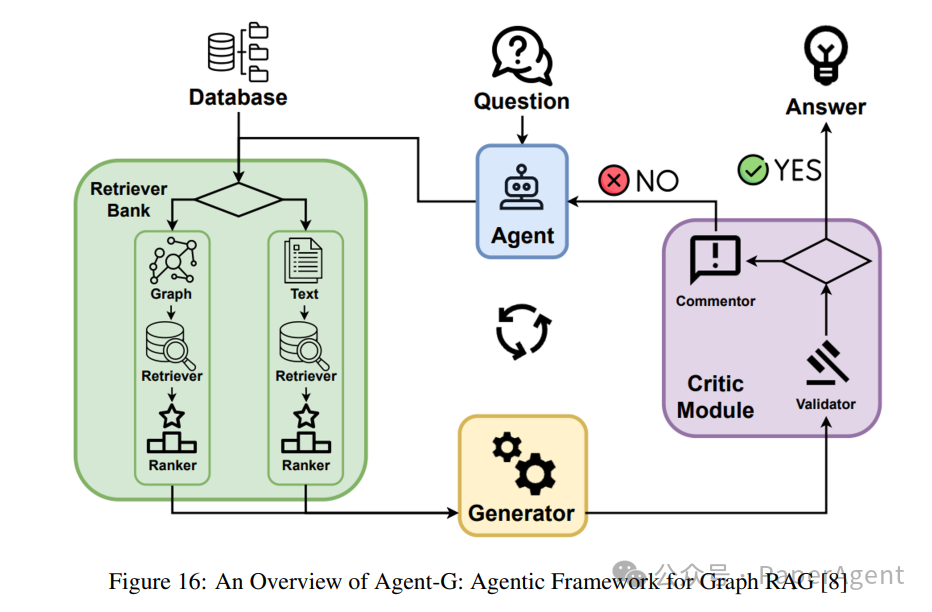
The core concept of Agent-G: The core principle of Agent-G lies in its ability to dynamically assign retrieval tasks to specialized agents, leveraging graph knowledge bases and text documents. Agent-G adjusts its retrieval strategies as follows:
-
Graph knowledge base: Extracts relationships, hierarchies, and connections using structured data (e.g., mapping diseases to symptoms in healthcare).
-
Unstructured documents: Traditional text retrieval systems provide contextual information to supplement graph data.
-
Critique module: Assesses the relevance and quality of retrieved information, ensuring consistency with the query.
-
Feedback loop: Iteratively verifies and re-queries to refine retrieval and synthesis.
Workflow: The Agent-G system is built around four main components:
-
Retriever library:
-
A set of specialized agents focused on retrieving graph-based or unstructured data.
-
Agents dynamically select relevant sources based on query requirements.
Critique module:
-
Validates the relevance and quality of retrieved data.
-
Flags low-confidence results for re-retrieval or refinement.
Dynamic agent interaction:
-
Agents collaborate on specific tasks, integrating diverse data types.
-
Ensures coherent retrieval and synthesis between graph and text sources.
LLM integration:
-
Synthesizes validated data into coherent answers.
-
Iterative feedback from the critique module ensures consistency with query intent.
Agentic Document Workflows
Agentic Document Workflows (ADW) extend traditional retrieval-augmented generation (RAG) paradigms to achieve end-to-end knowledge work automation. These workflows coordinate complex document-centric processes, integrating document parsing, retrieval, inference, and structured output with intelligent agents. ADW systems address the limitations of intelligent document processing (IDP) and RAG by maintaining state, coordinating multi-step workflows, and applying domain-specific logic to documents.
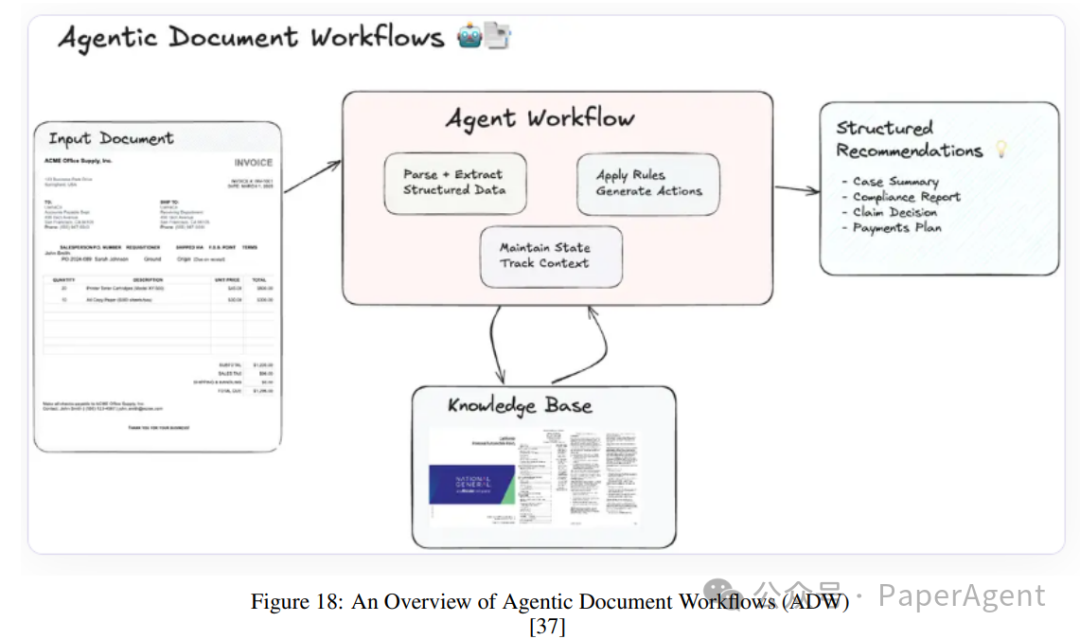
Workflow:
-
Document parsing and information structuring:
-
Using enterprise-level tools (e.g., LlamaParse) to parse documents and extract relevant data fields such as invoice numbers, dates, vendor information, line items, and payment terms.
-
Organizing structured data for downstream processing.
Status maintenance across processes:
-
The system maintains the state of document context, ensuring consistency and relevance across multi-step workflows.
-
Tracking the progress of documents through various processing stages.
Knowledge retrieval:
-
Retrieving relevant references from external knowledge bases (e.g., LlamaCloud) or vector indices.
-
Retrieving real-time domain-specific guidelines to enhance decision-making.
Agent coordination:
-
Intelligent agents apply business rules, perform multi-hop reasoning, and generate actionable suggestions.
-
Coordinating components such as parsers, retrievers, and external APIs for seamless integration.
Actionable output generation:
-
Presenting output in a structured format tailored to specific use cases.
-
Integrating suggestions and extracted insights into concise and actionable reports.
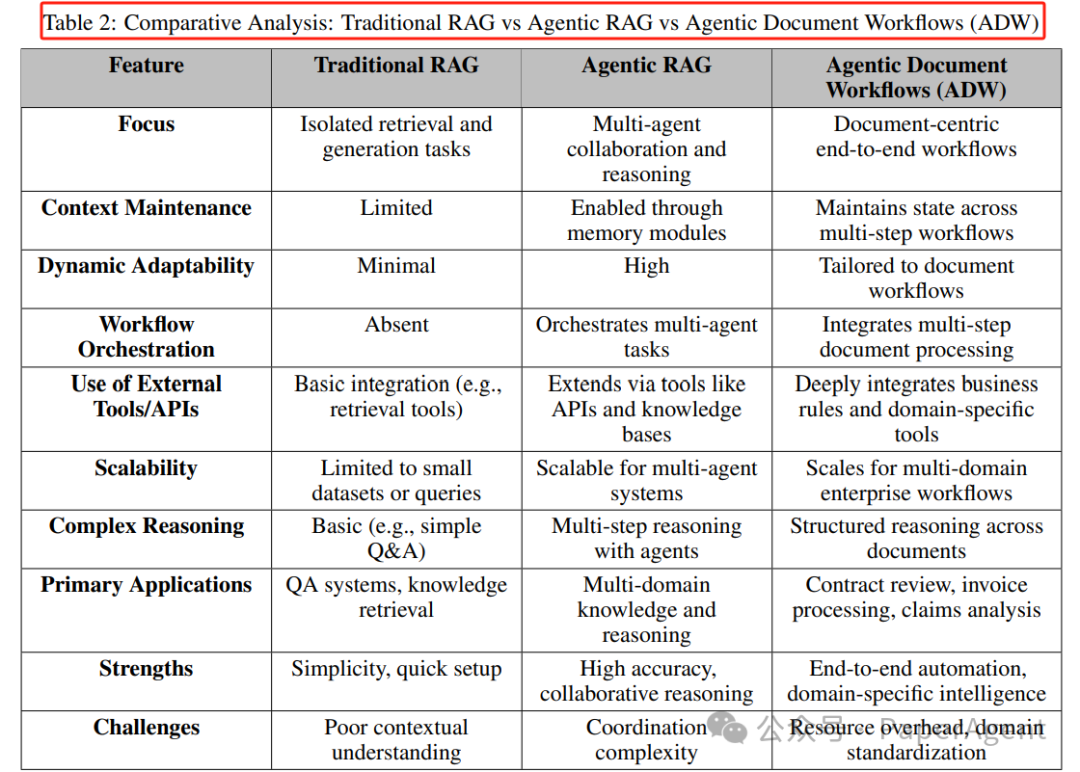
Comparison of Traditional RAG, Agentic RAG, and Agentic Document Workflows (ADW)
https://arxiv.org/abs/2501.09136Agentic Retrieval-Augmented Generation: A Survey on Agentic RAGSource | PaperAgent