
Click 01 Muggle Society Follow the official account, and you won’t get lost in AI learning

LangGraph is an important feature recently released by LangChain, marking its move towards a multi-agent framework. LangGraph is built on top of LangChain, helping developers easily create powerful agent runtimes.
LangChain and its expression language (LCEL) provide technical support for developers to build custom chains. From the perspective of graphs, these chains are directed acyclic graphs (DAG). In practical applications, users expect to construct cyclic graphs. This means that in LLM applications, agents may be called in a loop based on inference until the task is completed. AutoGen is an example of a multi-agent framework that implements this mechanism.
LangGraph is designed to meet such user needs, allowing developers to build multi-agent LLM applications similar to AutoGen.
LangGraph presents a mechanism akin to a state machine that drives agents to work in a loop. Thus, there are three important elements in LangGraph:
-
StateGraph
-
Node
-
Edge
StateGraph
StateGraph is a LangChain class that represents a graph data structure and reflects the state of the graph. The graph state is updated by nodes.
class State(TypedDict): input: str all_actions: Annotated[List[str], operator.add]
graph = StateGraph(State)Node
One of the most important concepts in the graph structure is the node (Node). Each node has a name (Name), and the value of a node can be a function or an LCEL Runnable. Each node receives a dict type of data, which has the same structure as the state definition. The node returns the state updated with the same structure.
There is a special node in LangGraph called END, which marks the end state of the state machine.
from langgraph.graph import END
graph.add_node("model", model)
graph.add_node("tools", tool_executor)Edge
The relationships between nodes in the graph need to be defined through edges (Edge). LangGraph defines two types of edges: normal edges and conditional edges.
Normal edges define the sequential relationship between nodes. This defines the subsequent node that must follow the upstream node, which is the next hop in task execution.
graph.add_edge("tools", "model")Conditional edges define routing relationships and conditionally determine the next hop of the upstream node.
graph.add_conditional_edge( "model", should_continue, { "end": END, "continue": "tools" })As shown in the code above, conditional edges require three elements:
-
Upstream node
-
Routing function (conditionally determines the next hop node)
-
State mapping (maps the next hop node based on the return value of the routing function)
Running the Graph
Once the LangGraph application is built, before calling/executing, we need to complete two steps:
Set the entry point
graph.set_entry_point("model")Compile the graph
app = graph.compile()app is an LCEL Runnable, and developers can operate it like other Runnables, for example:
app.stream( { "messages": [ HumanMessage(content="Write a tweet about LangChain news") ] })An Example of a Supervisor Architecture
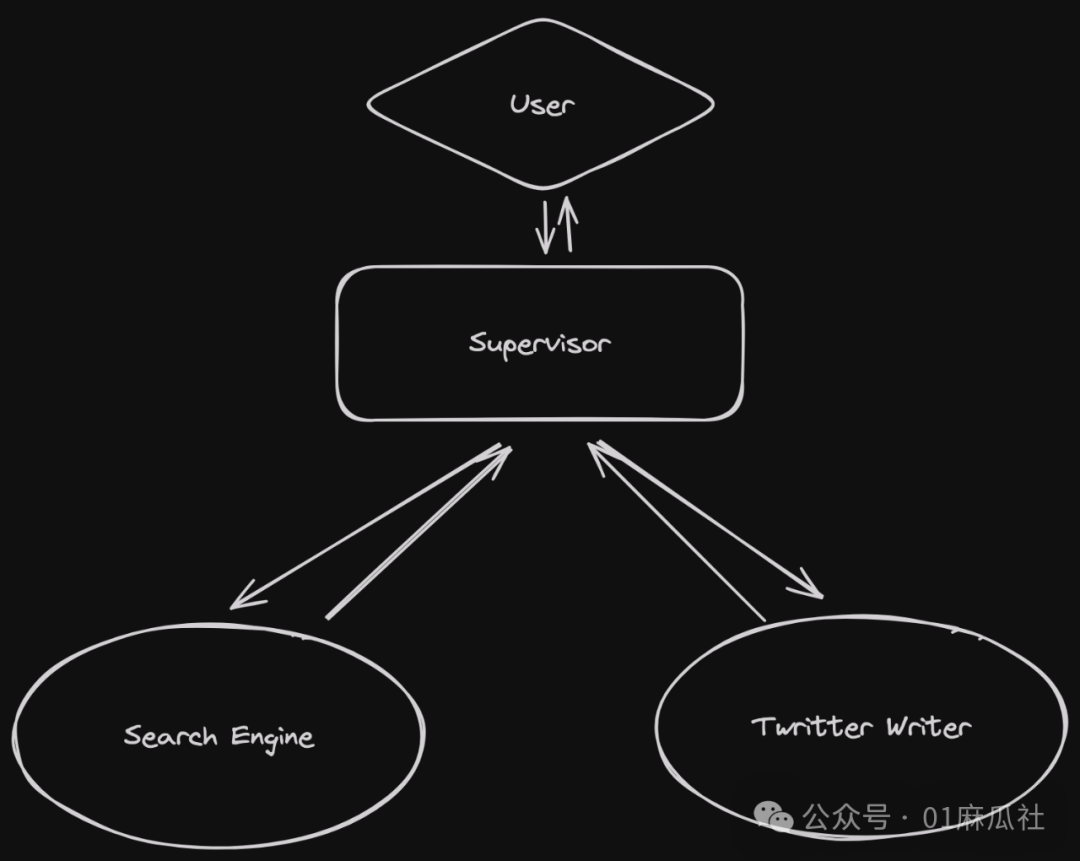
This is an example of a Supervisor. The graph contains three nodes: Supervisor, Search Engine, and Twitter Writer.
As needed, the Supervisor may call the Search Engine multiple times to obtain the required data and deliver it to the Twitter Writer to write a tweet. Thus, the “loop” exists between the Supervisor and the Search Engine.
LangChain can help developers easily build agents based on tools and then create nodes based on those agents.
Defining the Graph State Data Structure
class AgentState(TypedDict): # The annotation tells the graph that new messages will always # be added to the current states messages: Annotated[Sequence[BaseMessage], operator.add] # The 'next' field indicates where to route to next next: strDeclaring Tool Functions
@tool("web_search")
def web_search(query: str) -> str: """Search with Google SERP API by a query"""
search = SerpAPIWrapper()
return search.run(query)
@tool("twitter_writer")
def write_tweet(content: str) -> str: """Based on a piece of content, write a tweet."""
chat = ChatOpenAI()
messages = [ SystemMessage( content="You are a Twitter account operator." " You are responsible for writing a tweet based on the content given." " You should follow the Twitter policy and make sure each tweet has no more than 140 characters." ), HumanMessage( content=content ), ] response = chat(messages)
return response.contentBuilding Agents Based on Tools
def create_agent(llm: ChatOpenAI, tools: list, system_prompt: str): prompt = ChatPromptTemplate.from_messages( [ ( "system", system_prompt, ), MessagesPlaceholder(variable_name="messages"), MessagesPlaceholder(variable_name="agent_scratchpad"), ] ) agent = create_openai_tools_agent(llm, tools, prompt) executor = AgentExecutor(agent=agent, tools=tools) return executorBuilding Nodes Based on Agents
def agent_node(state, agent, name): result = agent.invoke(state) return {"messages": [HumanMessage(content=result["output"], name=name)]}Building the Supervisor Node
members = ["Search_Engine", "Twitter_Writer"]
system_prompt = ( "You are a supervisor tasked with managing a conversation between the" " following workers: {members}. Given the following user request," " respond with the worker to act next. Each worker will perform a" " task and respond with their results and status. When finished," " respond with FINISH.")
options = ["FINISH"] + members
# Using openai function calling can make output parsing easier for us
function_def = { "name": "route", "description": "Select the next role.", "parameters": { "title": "routeSchema", "type": "object", "properties": { "next": { "title": "Next", "anyOf": [ {"enum": options}, ], } }, "required": ["next"], },}
prompt = ChatPromptTemplate.from_messages( [ ("system", system_prompt), MessagesPlaceholder(variable_name="messages"), ( "system", "Given the conversation above, who should act next?" " Or should we FINISH? Select one of: {options}", ), ]).partial(options=str(options), members=", ".join(members))
supervisor_chain = ( prompt | llm.bind_functions(functions=[function_def], function_call="route") | JsonOutputFunctionsParser())Creating Nodes and Edges
search_engine_agent = create_agent(llm, [web_search], "You are a web search engine.")
search_engine_node = functools.partial(agent_node, agent=search_engine_agent, name="Search_Engine")
twitter_operator_agent = create_agent(llm, [write_tweet], "You are responsible for writing a tweet based on the content given.")
twitter_operator_node = functools.partial(agent_node, agent=twitter_operator_agent, name="Twitter_Writer")
workflow = StateGraph(AgentState)
workflow.add_node("Search_Engine", search_engine_node)
workflow.add_node("Twitter_Writer", twitter_operator_node)
workflow.add_node("supervisor", supervisor_chain)
for member in members: workflow.add_edge(member, "supervisor")
conditional_map = {k: k for k in members}conditional_map["FINISH"] = END
workflow.add_conditional_edges("supervisor", lambda x: x["next"], conditional_map)Compiling the Graph
workflow.set_entry_point("supervisor")
graph = workflow.compile()Now we can execute tasks based on the graph. Let’s have it help us search for LangChain news and write a tweet:
for s in graph.stream( { "messages": [ HumanMessage(content="Write a tweet about LangChain news") ] }): if "__end__" not in s: print(s) print("----")For the complete code, please refer to:
https://github.com/sugarforever/LangChain-Tutorials/blob/main/langgraph_nodes_edges.ipynb
Wishing everyone success in work and study!
📝 Recommended Reading
Ollama | Local Deployment of Open Source Large Models
[Preparing for Gemini] Introduction to Google Vertex AI API and LangChain Integration
Google Releases the Strongest Model Gemini – Bard Integrates Gemini Pro, API Integration Interface Released on December 13
[Privacy-Focused] Llama 2 + GPT4All + Chroma Achieve 100% Localization RAG
[Spark API Gateway] iFLYTEK’s Spark Large Model Seamlessly Replaces OpenAI GPT4-Vision
No Coding Required! Create OpenAI Assistants Applications – [Zero-Code Platform Flowise Practical Guide]
[Stylish RAG] 03 Multi-Document Based Agents
[Stylish RAG] 02 Multimodal RAG
[Stylish RAG] 01 RAG on Semi-Structured Data