

The technology of searching cars by image is based on computer vision, image processing, and image recognition technologies, including four major steps: image preprocessing, feature extraction, establishing image feature indexing, and feature matching.
Images in complex backgrounds often suffer from diverse noise, low resolution, and uneven lighting. To ensure that images have uniform properties, preprocessing is necessary to achieve position calibration and grayscale normalization. First, background subtraction and filtering are performed to denoise the image, followed by scaling transformations to obtain fixed-sized image samples, enabling subsequent algorithms to uniformly process and recognize these samples. Next, the image is converted to grayscale, and enhancements are made through median filtering and morphological methods, making the main textures of vehicle features (such as license plate numbers, body colors, and local features) clear while blurring interference textures to optimize the image for texture-based vehicle feature positioning. Finally, histogram equalization is applied to standardize the image with uniform mean and variance, resulting in a standard image.
Compared to other popular detection methods (Harris detector), the advantage of SIFT feature vectors lies in their invariance to scaling, translation, rotation, and changes in brightness, as well as their robustness against partial occlusion and background noise; moreover, they are rich in information and unique, making them suitable for massive feature databases. Additionally, a small number of targets can yield a large quantity of SIFT feature vectors. Therefore, this article employs a SIFT-based algorithm to represent feature vectors for images in the database. The feature vectors extracted by this algorithm have 128 dimensions, avoiding the curse of dimensionality while reducing the computational complexity during feature vector matching. The PCA-SIFT algorithm is used to extract local features from images, which maintains the good properties of the SIFT operator while effectively reducing the dimensionality of the feature vectors. First, SIFT features are uniformly extracted from the image, followed by Principal Component Analysis (PCA) to transform the feature vector matrix, converting multiple measured variables into a few uncorrelated composite indicators. The specific implementation steps for feature extraction are as follows:
① Input the original vehicle image library
The vehicle area is defined as a rectangular area at the front of the vehicle, with the upper edge at the top of the driver’s window, the lower edge at the bottom of the license plate, the left edge at the left boundary of the driver’s window, and the right edge at the right boundary of the driver’s window.
② Extract SIFT feature set from the image library
To extract SIFT feature points, it is first necessary to establish a Gaussian pyramid for the image. This aims to segment the image into blocks, presenting a hierarchical pyramid structure, and then statistics are collected for each sub-block, ultimately stitching together all the sub-block features to form a complete feature set.
③ Dimensionality reduction using PCA algorithm
First, for the existing dataset P = {P1, P2, … , Pn}, the mean is calculated
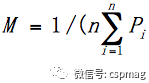 , and the original data is subtracted from the mean to obtain Pi′= Pi – M. Then, the covariance matrix is calculated.
, and the original data is subtracted from the mean to obtain Pi′= Pi – M. Then, the covariance matrix is calculated.
 Next, the eigenvalues E1, E2,…, Em and eigenvectors EV1, EV2,…, EVm of the covariance matrix are computed. Finally, the eigenvalues are sorted in descending order to obtain E1′, E2′,…, Em′, with corresponding eigenvectors EV1′, EV2′,…, EVm′. The eigenvectors represent the distribution direction of the original data, and the larger the corresponding eigenvalue, the more important the eigenvector, which is referred to as a principal component.
Next, the eigenvalues E1, E2,…, Em and eigenvectors EV1, EV2,…, EVm of the covariance matrix are computed. Finally, the eigenvalues are sorted in descending order to obtain E1′, E2′,…, Em′, with corresponding eigenvectors EV1′, EV2′,…, EVm′. The eigenvectors represent the distribution direction of the original data, and the larger the corresponding eigenvalue, the more important the eigenvector, which is referred to as a principal component.
After completing the above steps, the top 32 eigenvalues can be selected to reduce the original data from 128 dimensions to a new 32 dimensions, completing the dimensionality reduction operation on the original data.
④ Discretizing the SIFT feature set using K-means clustering
A large number of SIFT feature sets can be extracted from the image library, and K-means clustering is used for discretization, with the cluster label serving as the image index value. K-means clustering iteratively assigns each SIFT feature to the nearest cluster, ultimately partitioning the SIFT feature set into K discrete clusters, where SIFT features within the same cluster are considered the same and can be represented by cluster numbers, i.e., discrete SIFT features. The single linkage method is used for inter-cluster distance measurement, and for any two clusters ci, cj, the calculation formula for single linkage is:
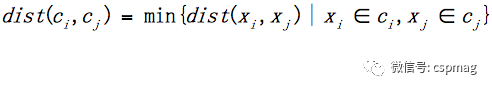
In the optimal example of this article, K is set to 100000.
⑤ Generating neighborhood features
To compensate for the lack of relative positional relationships among SIFT features, the discretized SIFT features must be further converted into neighborhood features. Assuming the number of SIFT clusters is K, and selecting an N*N neighborhood, the neighborhood features can be represented as an integer sequence, with element values not exceeding K*N*N. Given a SIFT feature point, a N*N neighborhood is defined around it. The following rules are used to generate a matrix: within the same sub-region, if the same discrete SIFT feature appears multiple times, it is recorded only once; if the k-th discrete SIFT feature appears in the n-th region, the value in the n-th row and k-th column of the matrix is set to 1, otherwise it is set to 0. The final integer sequence is generated as follows: the initial sequence is empty, and by scanning the matrix from left to right and top to bottom, if the n-th row and k-th column value is 1, an integer is added to the sequence with a value of (n-1) * K + k, ignoring elements with a value of 0. This integer sequence represents the neighborhood features. Figure 1 illustrates the generation of neighborhood features when K=10, N=3. In the optimal example of this article, K is set to 100000 and N to 3.
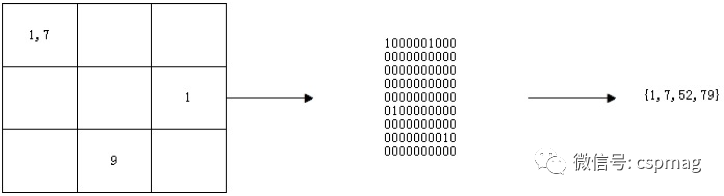
Figure 1
The inverted index technology used in image retrieval originates from the document retrieval field and is used for indexing and matching large-scale document data. Inverted indexes are widely applied in similarity search fields. In large-scale image datasets, the low-level feature vectors of images are quantized into visual words using a trained feature vector codebook, with each visual word corresponding to an index entry in the inverted index, enabling fast retrieval in image search.
Given a feature to be retrieved, after quantization, the corresponding index entry Wi in the inverted index for the feature to be retrieved is determined. Thus, the column of related indexed features corresponding to index entry Wi serves as candidate matching results. The matching function between two image feature vectors x and y is defined as follows:
fq(x,y)=δq(x),q(y)
where q(.) is the quantization function that maps the feature vector to the nearest cluster center in the codebook, i.e., the codeword.
After this process, the problem of calculating similarity between the user-input template image and all images in the image library is transformed into a matching problem among these local features represented by binary strings. In this article, the similarity metric for binary strings uses Hamming distance, which is computationally efficient. Finally, the corresponding images in the image library are output based on similarity from high to low.