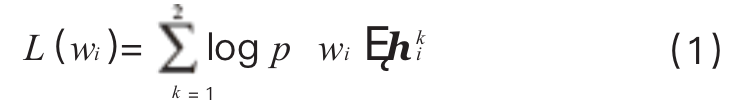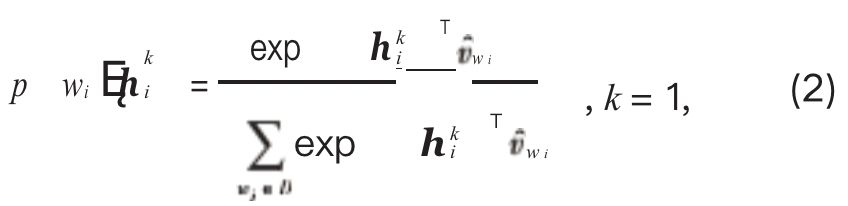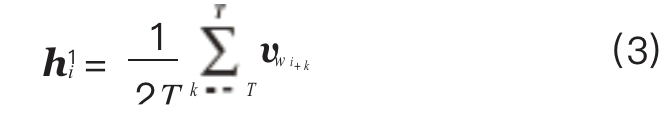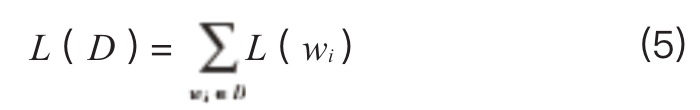Ding Zhengsheng, Ma Chunjie
(Xi’an University of Science and Technology, Shanxi Xi’an 710600)
Abstract: In order to improve the efficiency and accuracy of Chinese text classification, a Chinese text classification algorithm based on deep learning is established in response to the characteristics of Chinese characters and the dramatic increase in data volume in the big data context. Firstly, based on the characteristics of Chinese character sub-components (such as shape, radicals, strokes, etc.) and the inherent meaning carried by their shapes, a dual-channel CBOW model based on sub-character and contextual features is established to achieve Chinese text vectorization; secondly, in the context of big data, a fast kNN classification algorithm based on LSC clustering and multi-objective data filtering is proposed to address the slow classification speed of traditional kNN algorithms; finally, the fast kNN algorithm is applied to classify the feature word vector data transformed from text data. Experimental results show that the improved Chinese text classification algorithm expands the scope of algorithm application, can handle Chinese text data more accurately, and addresses big data issues more quickly, achieving improvements in both classification speed and effectiveness.
Keywords: Chinese text classification; text vectorization; fast kNN algorithm; word vector; dual-channel CBOW model; feature vector;data classification
Classification number: TN911. 1 ⁃ 34;TP3 Literature identification code: A
Article number: 1004 ⁃ 373X(2022)01⁃0100 ⁃04
0 Introduction
Human cognition of the world must start from basic data. With the dramatic increase in information volume, manually classifying Chinese text data has become a nearly impossible task, leading to a series of automatic text classification methods. Nowadays, text classification has gradually shifted from knowledge-based methods to statistical and machine learning methods [1].
To improve the efficiency and accuracy of Chinese text classification, researchers have proposed a series of improved methods, mainly focusing on improvements in Chinese text vectorization [2], text feature extraction [3], and classification algorithms [4]. Among them, literature [5] utilizes Word2vec for vector representation of text and combines it with the kNN algorithm to achieve sentiment classification of Chinese text, improving classification efficiency through enhancements in text vectorization; literature [6] employs a corpus-based and classification-based approach, integrating the best parameter values at each stage to provide a subset feature selection method, thereby improving the success rate of classification through enhancements in feature extraction methods; literature [7] adopts a dual-layer LSTM and CNN module to enhance the fusion of text features extracted from the classifier’s attention mechanism, improving the accuracy of text classification through enhancements in the classification algorithm. The above literature has improved algorithms from different aspects and achieved certain results.
However, considering the unique properties of Chinese characters and the dramatic increase in text data volume, this paper aims to classify Chinese text based on improvements in text vectorization and classification algorithms. The main work includes: improving the CBOW algorithm based on the characteristics of Chinese pictographs by incorporating sub-character and sub-information features, and using the improved algorithm for vectorization of Chinese text; improving the slow classification speed of the kNN algorithm through clustering and data reconstruction; and using the improved kNN algorithm to classify feature vector data.
Chinese text data cannot be directly processed by computers; it must first be expressed in a vectorized form, after which classification tools are used to classify the text feature vectors, achieving the desired classification effect.
1.1 Improvement and Steps of the Chinese Text Vectorization Algorithm
Natural language can be divided into phonetic and ideographic categories, with Chinese characters belonging to the ideographic system, meaning that the structure of Chinese characters can represent part of the meaning of words. Therefore, incorporating the internal structure of Chinese characters into text vectorization has certain research value [8].
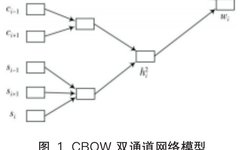
Word vectors can not only calculate semantic similarity between words but also improve the accuracy of semantic similarity calculations between texts [9]. When information such as the radical of the target word is included, the semantic similarity of the text can be better reflected. For example, characters with the radical ‘three dots water’ are often related to water, so incorporating radical information during the preprocessing phase of text vectorization can help the model find the inherent connections between texts more effectively. This paper will establish a dual-channel network model based on the word vector method CBOW [9], combining external information (context of words) and internal information (components of words and character segmentation). The structure is shown in Figure 1.
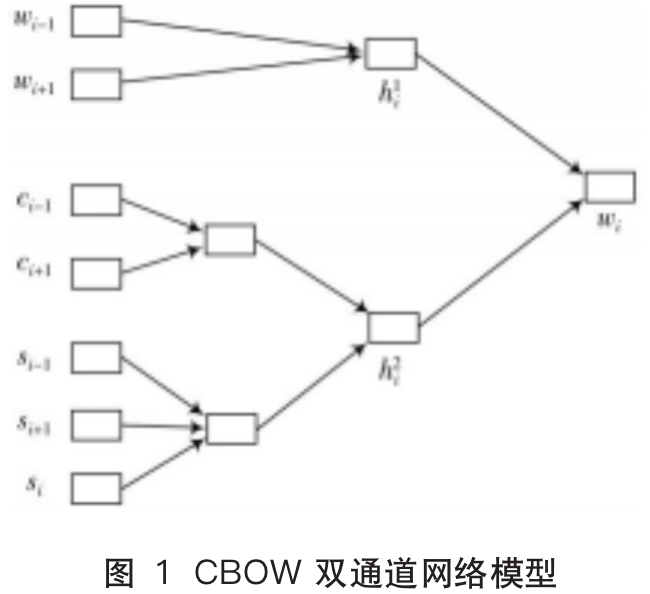 The model consists of a word prediction module and a sub-information prediction module. Here, wi is the target word, wi-1 and wi+1 are the left and right words of the target word in the sentence, si is the radical of the predicted word, and ci-1 and ci+1, si-1 and si+1 correspond to the Chinese characters and radicals of wi-1 and wi+1 respectively.
In the corpus D, analogous to the CBOW model, this model aims to maximize the log-likelihood of the conditional probability of the context vector of the target word wi, as shown in formula (1):
The conditional probability is obtained by the softmax function, as shown in formula (2):
In the formula, wi is the output vector of the word wi.
hi is the mean vector of the words within a window of size 2T, that is:
The model consists of a word prediction module and a sub-information prediction module. Here, wi is the target word, wi-1 and wi+1 are the left and right words of the target word in the sentence, si is the radical of the predicted word, and ci-1 and ci+1, si-1 and si+1 correspond to the Chinese characters and radicals of wi-1 and wi+1 respectively.
In the corpus D, analogous to the CBOW model, this model aims to maximize the log-likelihood of the conditional probability of the context vector of the target word wi, as shown in formula (1):
The conditional probability is obtained by the softmax function, as shown in formula (2):
In the formula, wi is the output vector of the word wi.
hi is the mean vector of the words within a window of size 2T, that is:
hi is the mean processing result of sub-information vectors, which means the average of characters and radicals:
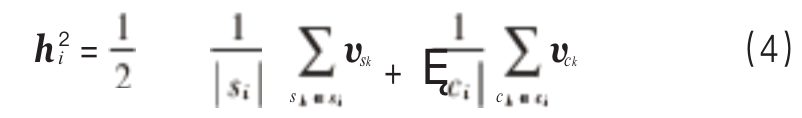
Where: |si|, |ci| are the total counts of vsi, vci; vwi, vci, vsi are the input vectors of word wi, character ci, and radical si respectively.
For the total corpus D, the objective function can be expressed as the log of the overall maximum likelihood function, as shown in formula (5):
1.2 Improvement and Steps of the Classification Algorithm
The kNN algorithm [10] is a theoretically mature method and one of the simplest machine learning algorithms. The algorithm completes classification prediction by sorting the distances between the points to be classified and the training samples, taking the most frequent type among the top k points as the type of the point to be classified. However, due to the large amount of redundant calculations during distance computation, the algorithm suffers from slow classification speed. This paper aims to improve the classification speed of the algorithm through clustering and reconstruction of sample data. The specific steps are as follows:
1) Using clustering algorithms to cluster the sample data and divide the data into multiple clusters.
Considering the complexity of large-scale problems, the improved LSC algorithm based on spectral clustering [11] is used to divide the data into m clusters, with the arithmetic mean of each cluster serving as the cluster center. The number of clusters m must satisfy formula (6), where M is the number of training samples and M0 is the minimum sample count for a cluster.

2) Sample data reconstruction and classification.
First data filtering: Calculate the distance between the point to be classified xi, i=1,2,⋯ ,n and each cluster center (which can be Euclidean distance, etc., chosen based on the situation during experiments) and store it, as shown in formula (7), where dzi is the distance between the test point xz and ci.
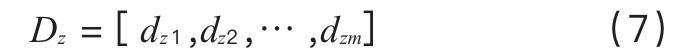
The data from the cluster closest to the test point is taken as the initial filtered data, as shown in formula (8), where Ai represents the i-th cluster set and ci represents the center point of the i-th cluster.
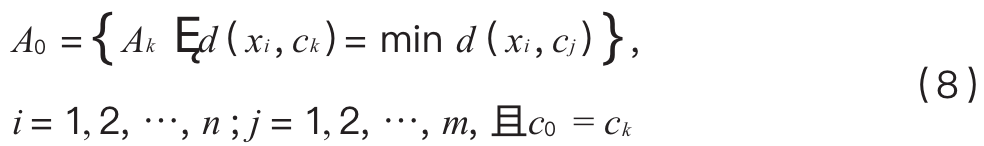
Second data filtering: Based on the classification principles of support vector machines, to enhance the diversity of data and reduce the loss of effective data, the second filtering aims to double the objectives, filtering out clusters that are close to the test data while being far from other clusters. The objective function is defined as:
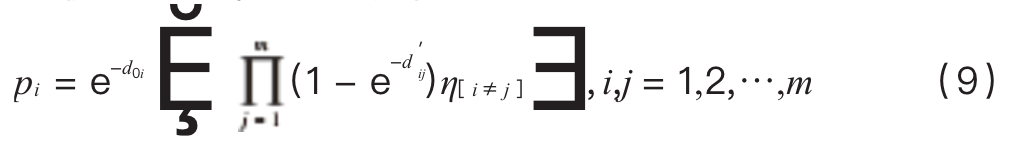
Where: d ij c ci and cj are the distances between cluster centers.
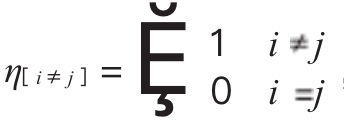
Taking the cluster with the maximum p value as the second filtering data.
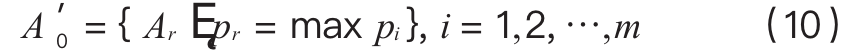
Data merging and classification: Merge A0 with A0 set, denoted as A=[A0,A0 ], for the final data center to perform kNN classification prediction.
2 Overall Process of the Chinese Text Classification Algorithm
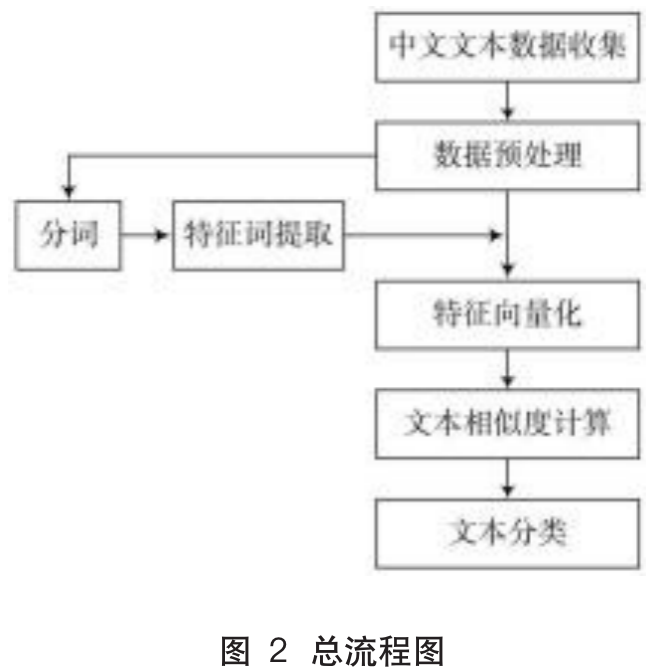
The framework process of this paper is shown in Figure 2, mainly including data collection and preprocessing, text vectorization, text similarity calculation, and text classification. Among them, preprocessing uses the NLPIR Chinese word segmentation system from the Chinese Academy of Sciences, employing the Harbin Institute of Technology stopword list, text vectorization uses the CBOW model based on the structure of Chinese characters, and since the text data processed in this paper is short text data, the initial features are directly selected for text features. The text similarity is calculated using the cosine similarity of the average keywords, and the classification tool employs the kNN algorithm based on data reconstruction.
This paper utilizes web crawlers to scrape visitor review data and evaluation labels (good reviews, neutral reviews, poor reviews) from Meituan, validating the effectiveness of the improved algorithm.
After removing invalid data (garbled text, character count less than 10, all punctuation symbols, etc.), a total of 11000 valid Chinese texts were obtained. The texts were categorized into three classes based on visitors’ satisfaction with tourist attractions: good, neutral, and poor.
Examples of the text data are shown in Table 1.

3.2 Method and Parameter Description
The experimental data was divided into training data and testing data in an 8:2 ratio. The ICTCLAS [13] from the Institute of Computing Technology, Chinese Academy of Sciences was used for Chinese word segmentation, and the Harbin Institute of Technology Chinese stopword list was employed to remove noise from the segmentation results, obtaining the text feature set. Since the dataset consists of short text data, the window size in the improved CBOW algorithm was set to 3, the minimum threshold for word occurrences was set to 1, and the dimension of the word vector was set to 60. The improved kNN classifier determined the parameter values of k=1 and m=5 based on accuracy and time results. The experimental results under different k and m values are compared in Figure 3. The distance calculation method of the kNN algorithm uses cosine similarity for measurement.
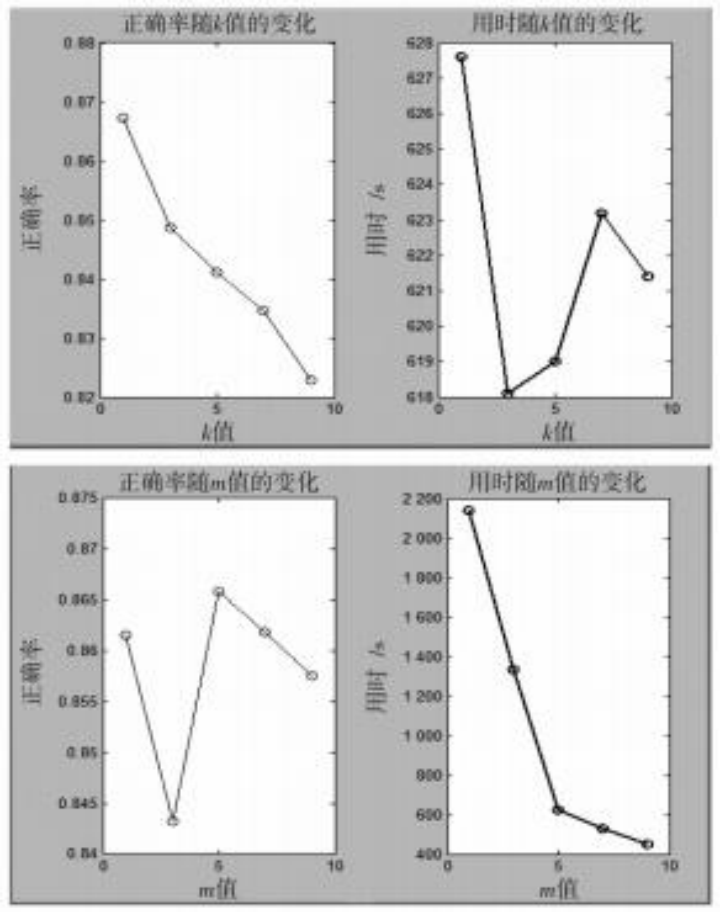
Figure 3 Comparison of experimental results under differentk values andm values
This paper evaluates the performance of classification results based on accuracy (p), recall (r) and F 1 value.

In the formula: m is the number of correctly classified instances; M is the total actual number of classifications; N is the expected number of texts.
3.3 Experimental Results and Analysis
A comprehensive comparative analysis was conducted using both the CBOW model and the dual-channel CBOW model proposed in this paper, as well as a comparative analysis of the speed of the traditional kNN algorithm and the data reconstruction kNN algorithm proposed in this paper. The testing results are shown in Table 2.
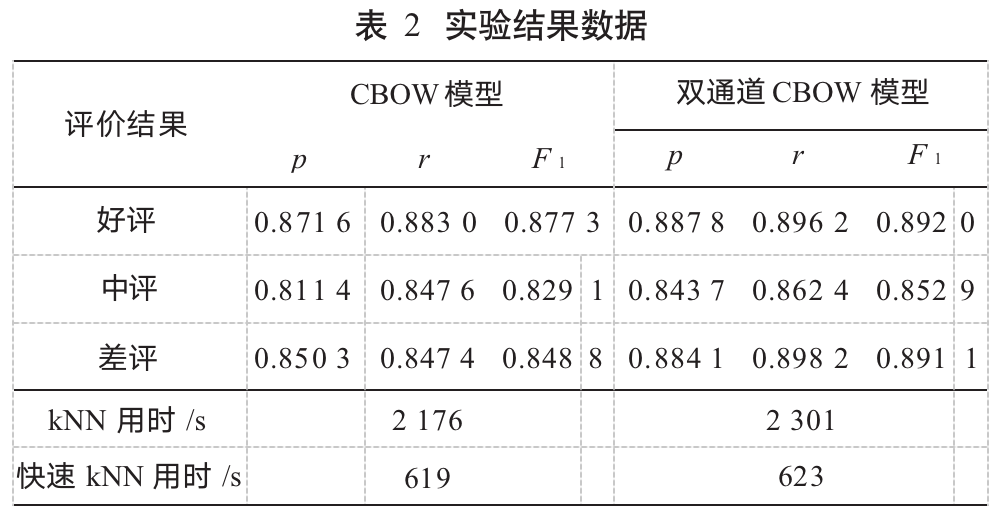
From Table 2, it can be seen that the improvements made to both algorithms have achieved certain advancements in classification effectiveness and efficiency. In terms of accuracy (p), recall (r), and F1 value, improvements of 0.274%, 0.263%, and 0.27% were achieved respectively. In terms of time, the time taken was about 14 times less than before the improvements, showing a significant reduction, and theoretically, this advantage becomes more evident as the data samples increase. This is due to the fact that this paper considers the structural features of the data in the vectorization conversion, enhancing the correlation between words with similar structural features, allowing for closer distances during relatedness calculations, thereby achieving better classification effects. Additionally, effectively partitioning the sample data can exponentially reduce the amount of distance calculations required by the algorithm, resulting in less classification time.
4 Conclusion
This paper addresses the characteristics of Chinese text data, making various improvements in text vectorization and classification algorithms. The innovation lies in incorporating sub-information such as radicals into text vectorization, improving classification accuracy, and partitioning large-scale data samples, reducing classification speed. Based on the model proposed in this paper, classification of visitor review data shows that the algorithm has improved classification effects and reduced classification speed to a certain extent. However, this classification is based on short text data, and further optimization in feature extraction is needed for long text data.
[1] Liu Hongguang, Ma Shuanggang, Liu Guifeng. A Review of Patent Text Classification Algorithms Based on Machine Learning [J]. Library and Information Research, 2016, 9(3): 79-86.
[2] Xu J, Liu J W, Zhang L G, et al. Improve Chinese word embeddings by exploiting internal structure [C]//Proceedings of 15th Annual Conference of the North American Chapter of the Association for Computational Linguistics. San Diego California, USA: ACL, 2016: 1041-1050.
[3] Chang Yaocheng, Zhang Yuxiang, Wang Hong, et al. A Review of Feature-Driven Keyword Extraction Algorithms [J]. Journal of Software, 2018, 29(7): 2046-2070.
[4] Kong Xixi, Liao Shukui, Cheng Bing. Research on Text Classification Based on Different Word Segmentation Modes [J]. Mathematics Practice and Understanding, 2018, 48(1): 116-123.
[5] Ma Sidan, Liu Dongsu. Research on Text Classification Method Based on Weighted Word2vec [J]. Information Science, 2019, 37(11): 38-42.
[6] Mendez-Molina A, Ona-García A L, Carrasco-Ochoa J A, et al. Revisiting Two-Stage Feature Selection Based on Coverage Policies for Text Classification [J]. Journal of Intelligent & Fuzzy Systems, 2018, 34(5): 2949-2957.
[7] Xie J, Hou Y, Wang Y, et al. Chinese Text Classification Based on Attention Mechanism and Feature-Enhanced Fusion Neural Network [J]. Computing, 2020, 102(3): 683-700.
[8] Xu Linhong, Lin Hongfei, Qi Ruihua, et al. Emotion Vocabulary Representation Model Based on Radicals and Phonemes [J]. Journal of Chinese Information Science, 2018, 32(6): 124-131.
[9] Liu M, Lang B, Guzp, et al. Measuring Similarity of Academic Articles with Semantic Profile and Joint Word Embedding [J]. Tsinghua Science and Technology, 2017, 22(6): 619-632.
[10] Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space [EB/OL]. [2013-09-27]. http://arxiv.org/abs/1301.3781v3.
[11] Cai D, Chen X L. Large Scale Spectral Clustering with Landmark-Based Representation [C]// Proceedings of the 25th AAAI Conference on Artificial Intelligence. New York, USA: [s.n.], 2011: 313-318.
[12] Zhou Qingping, Tan Changgeng, Wang Hongjun, et al. kNN Text Classification Algorithm Improved Based on Clustering [J]. Computer Applications Research, 2016, 33(11): 3374-3377.
[13] Xu Shan, Du Weifeng. Research on SMS Filtering System kNN Method under Imbalanced Training Set [J]. Computer Applications and Software, 2013, 30(11): 84-86.
[14] Dou Xiaofan. A Review of kNN Algorithm [J]. Communication World, 2018(10): 273-274.
Ding Zhengsheng (1965—), male, from Shaanxi, a second-level professor, mainly researching mathematics and statistics.
Ma Chunjie (1995—), female, from Shaanxi, a graduate student, mainly researching deep learning.
Click the link below to view historical articles
Good papers are made by “modifying”!
CNKI’s continuous price increases are suspected of monopolization; how should academia and commerce balance?
The Directory of Modern Electronic Technology, Issue 12, 2019
Which universities published the most SCI papers and granted patents in 2017?
The Modern Electronic Technology was included in the Overview of Core Journals in Chinese
Academician of the Chinese Academy of Sciences: The paper-led model dominated by SCI stifles scientific creativity
How to write a “Nature” article overnight, listen to what academicians have to say!