
Introduction This article explores how AI drives the next generation of sales. It discusses changes brought about by AI development, such as personalized text generation for telemarketing calls and enhanced interruption capabilities. It proposes future scenarios where sales personnel will no longer need to analyze user data and design scripts but will rely on AI systems for precise adjustments. Additionally, it shares how to utilize large models to facilitate interactions in telemarketing and intelligent customer service scenarios, improving efficiency and reducing costs.
The full table of contents is as follows:
1. Project Background and Goals
2. Core Technologies and Solutions
3. System Implementation and Business Impact
4. Sample Technologies | Model Training | Case Studies
5. Challenges and Solutions
6. Future Outlook
7. Q&A Session
Guest Speaker: Dong Wentao Sina Digital Science Technical Expert
Editor: Liang Yongqi
Content Proofreader: Li Yao
Produced by: DataFun
Project Background and Goals

Traditional telemarketing methods face significant challenges, primarily in flexibility and configuration complexity: on one hand, traditional telemarketing relies on preset and complex dialogue flows, which limits its adaptability during business adjustments; on the other hand, the professional nature and complexity of system configuration often require specially trained personnel to operate, making it difficult for ordinary users to get started directly, affecting the actual utilization rate of the product. These issues further lead to insufficient personalized services and limited recommendation capabilities, especially in scenarios requiring multi-turn dialogue and open communication, where traditional rule-based or model-based methods struggle to achieve efficient real-time adjustments.
In light of the above issues, our project aims to leverage large model technology to break through these bottlenecks. The initial goal was relatively basic: to build a powerful dialogue system and improve dialogue quality through fine-tuning and alignment technologies. Considering the limited experience of the team at the beginning, we first focused on establishing a stable dialogue foundation and then explored how to optimize the response of the dialogue system. In particular, to address the potential inaccuracies in responses generated by the dialogue system, we introduced a preference optimization mechanism to distinguish and improve dialogue quality. This initial concept provided direction for subsequent work.
Ultimately, our efforts exceeded expectations, and the specific data benefits will be detailed in subsequent sections. By applying large models, we not only addressed the inherent problems of traditional telemarketing but also enhanced user experience and service efficiency..
Core Technologies and Solutions
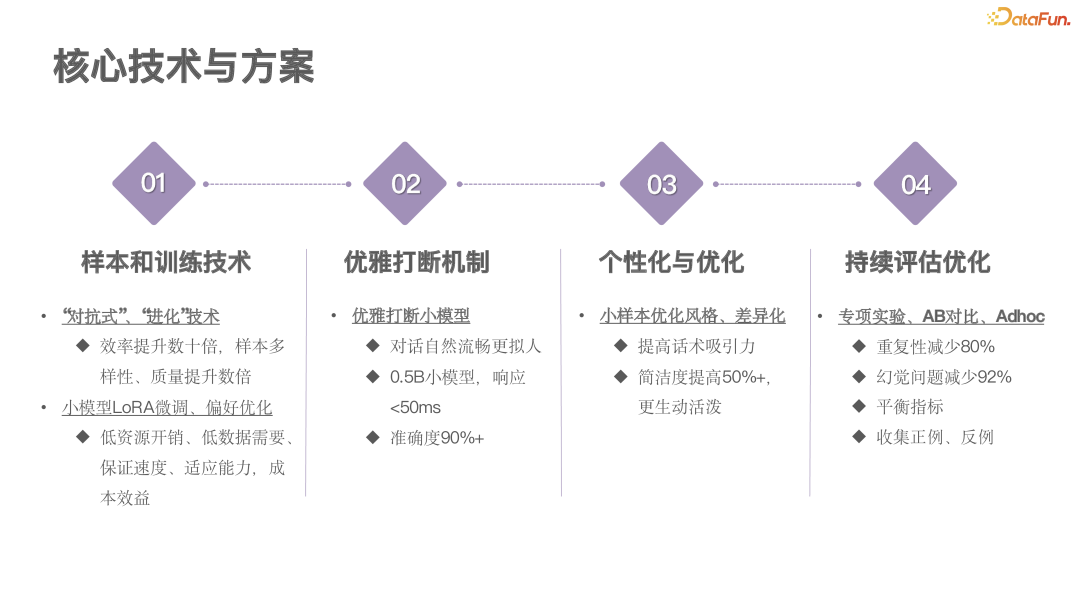
The project relies on innovations and applications of four key technologies, which not only enhance the system’s performance but also significantly reduce operational costs.
1. Efficient Sample Generation and Training Technology
To address the inefficiency of manually creating samples, we introduced adversarial generation technology, which greatly accelerated the sample synthesis process. Through automation, the sample generation speed increased by 30 times, from 200 pieces per person per day to 2000 pieces per day. In terms of model training, we adopted an incremental fine-tuning strategy, combined with DPO (Direct Preference Optimization) and other preference optimization methods to achieve efficient personalized customization. This not only enhanced model performance but also significantly reduced hardware resource expenditure, for example, from initially using 8 GPUs for fine-tuning to only needing 2 GPUs to complete an iteration in a few hours.
2. Elegant Interruption Mechanism
To address the common issue in traditional telemarketing where conversations cannot be interrupted, we specially developed a small dedicated model (about 0.5B parameters) to optimize interruption handling in dialogues. This technology greatly enhances the naturalness of conversations and user experience, making human-machine communication more human-like and solving the perception problem when both parties speak simultaneously.
3. Personalization and Optimization
To make conversations more engaging and ensure key information is prioritized, we implemented a series of human feedback-based alignment technologies to optimize the model’s dialogue. This not only made the dialogue more personalized and concise but also allowed for adjustments to the model’s expression style based on needs, making it more lively. Such optimizations significantly improved user interaction experiences.
4. Continuous Evaluation and Optimization
“To the evaluator belongs the world”—accurate evaluation is the foundation of optimization. We built a comprehensive evaluation system covering multiple dimensions, including targeted testing, hallucination detection, and repetitiveness checks, and conducted multi-level AB testing. During the evaluation process, we noted that there might be conflicts between different metrics, so we established a balancing mechanism to ensure optimal overall system performance. Additionally, we continuously collected positive and negative cases to iteratively improve the system, ensuring it remains in optimal condition.
Through the application of the above technologies, our project not only overcame the limitations of traditional telemarketing methods but also pioneered a new model of customer service that is smarter, more flexible, and more efficient..
System Implementation and Business Impact

To better showcase the actual effects of our system, we will provide detailed explanations from three aspects: revenue situation, return on investment, and core business data improvement.
1. Significant Revenue Situation
Our system not only possesses strong flexible dialogue capabilities, able to handle complex contexts with ease, but also further enhances dialogue quality through the integration of interruption technology and personalized alignment technology. More importantly, it significantly reduces operational costs and improves efficiency. For example, after introducing the large model, only one 24G memory A10 GPU can handle tens of thousands of calls per day, with almost no manual intervention or complex dialogue flow design needed, simplifying operations while greatly reducing labor costs.
2. High Reusability of Investment Returns
Considering the reusability of the project, we ensured from the design phase that various modules such as speech-to-text, text-to-speech, sample generation, and training technology could be seamlessly transferred to other application scenarios. This means that the system can be quickly deployed in fields such as intelligent customer service and debt collection, achieving efficient implementation. For example, in debt collection, based on the existing technical framework, we can deliver a customized model in just two to three weeks, which not only accelerates product launch but is expected to bring considerable investment returns to the company.
3. Substantial Improvement in Core Business Data
-
Conversion Rate: Through AB testing, the conversion rate after using the AI large model increased by over 20%, with still room for improvement.
-
Cost Savings: Especially for silent user groups that were previously overlooked due to their large numbers, now with the help of automated solutions, costs can be reduced by over 66%, which is a relatively conservative estimate.
It is important to note that differences among user groups may lead to varying results, but overall, this AI-driven telemarketing tool has brought significant efficiency improvements and potential growth opportunities to the business.
Sample Technologies | Model Training | Case Studies
1. Sample Technology – “Adversarial” Sample Generation
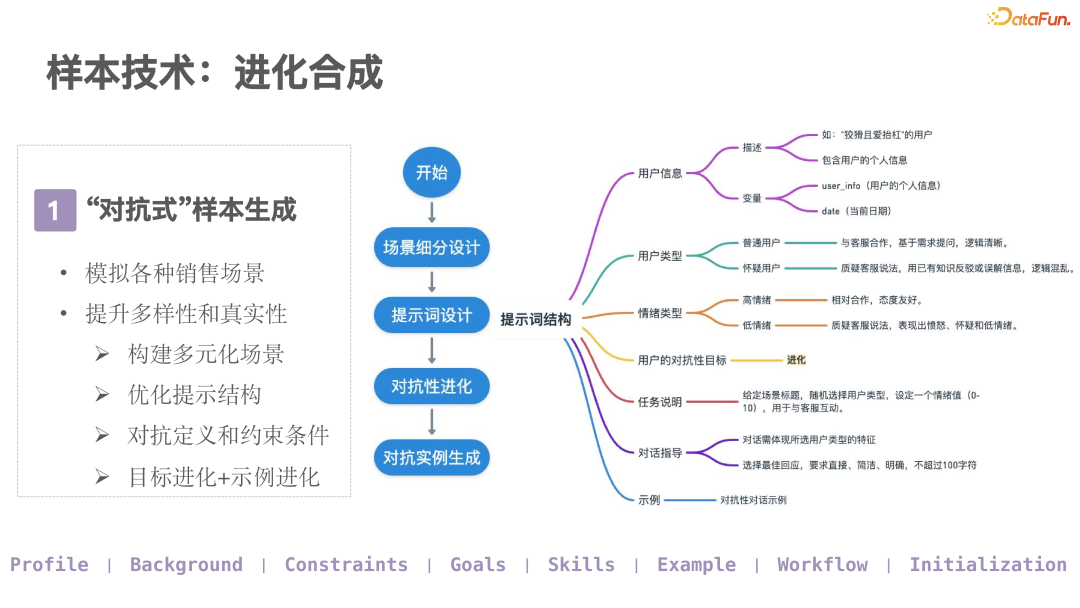
To clearly demonstrate how we enhance the performance of the dialogue system through sample evolution synthesis technology, we will provide detailed explanations in conjunction with practical cases and technical selection considerations. This section not only covers the basic process of sample generation but also delves into key aspects such as adversarial dialogue synthesis, genetic algorithm applications, and prompt structure design.
(1) From “Contrarian” Tool to Sample Evolution
In the early stages of the project, we faced issues with insufficient sample quality and quantity. To solve this problem, our technical lead developed a program called “Contrarian,” which specifically challenges the large model by simulating various difficult scenarios to uncover the model’s vulnerabilities. Although this process initially relied on manual efforts, it was inefficient and lacked accuracy. Later, we input these adversarial dialogue records as samples into the system and unexpectedly found that this greatly enriched the training data and significantly improved the model’s performance. This experience highlighted the importance of introducing adversarial diversity in sample generation.
(2)Basic Steps of Sample Generation
-
Detailed Process: First, thoroughly segment the target dialogue scenarios to ensure that each sub-scenario is fully covered.
-
Prompt Design: Carefully construct prompts to guide the model in generating expected dialogue content. Prompt design is the core part of the entire process, which will be detailed later regarding its structure.
-
Adversarial Dialogue Synthesis: Define the specific forms of adversarial dialogues, including how to set the roles and positions of both parties to increase the realism and complexity of the dialogue.
-
Adversarial Strength Generation: Generate corresponding samples for different intensities of adversarial situations, allowing the model to adapt to diverse communication environments.
-
Genetic Algorithm Application (Evolution): Borrowing principles from biological genetic algorithms, continuously optimize the sample set through iterative selection, crossover, and mutation operations. This approach ensures the diversity and high quality of samples, avoiding overfitting of the model to specific patterns.
(3)Prompt Structure Design
The structure of prompts is crucial for guiding the model to generate appropriate dialogues. Here are several key components:
-
User Objective Adversariality: Clearly define the goal of the dialogue and the adversarial factors that may be encountered during the process. This part needs to be flexibly adjusted according to specific business scenarios.
-
Example Provision: In addition to giving instructions, specific examples should also be provided to help the model better understand and learn dialogue strategies.
-
Task Description and Emotion Setting: Add background information to the dialogue, such as the user’s emotional state (ranging from 0 to 10), allowing the model to simulate more realistic human reactions. For example, the user may be logical and cooperative, or emotional and hostile. Such diverse emotional settings help improve the model’s ability to handle complex situations.
(4)Maintaining Sample Diversity and Quality
To prevent the model from becoming rigid due to overly regular training data, we emphasize the diversity and flexibility of samples. This means exposing the model to as many diverse dialogue scenarios as possible, avoiding memorization of fixed patterns. By introducing adversarial samples and continuously evolving the sample set using genetic algorithms, we ensure the quality of the training data, allowing the model to demonstrate higher adaptability and intelligence when facing unknown situations.
(5)Advanced Sample Technology Outlook
In addition to the basic methods mentioned above, we are also exploring more advanced sample generation technologies, such as online DPO support and the application of reward models. These technologies will further enhance the speed and accuracy of sample generation, but they also come with higher computational costs. As the project progresses, we will introduce these new technologies at the appropriate time to continuously optimize the performance of the dialogue system.
2. Sample Technology – Sample Evolution

To further enhance the quality and diversity of samples, we have summarized some tips in practice and optimized the entire process. Here are the specific sharing contents:
(1)Tips for Designing Pseudo-code Prompts
We discovered an effective method—using pseudo-code to write prompts (referred to as “code-to-prompt”). This method is not only intuitive and easy to understand but also helps the model better grasp task requirements. For example:
-
Define Method: You can define a generate_reply() function like programming, clearly instructing the model how to generate replies.
-
Main Method: Organize logic through a main() function, setting variables and constraints to guide the model’s behavior.
-
Loop and Filter: Use loop structures to generate multiple candidate replies and filter to find the best answer.
-
Comment Support: Similar to Python programming, comments can be added to prompts to help explain the intent of the code.
This pseudo-code style of prompt design has several significant advantages:
-
Improved Readability: Makes prompts easier to understand and maintain.
-
Enhanced Control: Structured code allows for precise control over the content generated by the model.
-
Simplified Complex Tasks: For multi-step or condition-branching tasks, pseudo-code effectively reduces complexity.
(2)Optimized Sample Generation Process
Based on the above tips, we have restructured the sample generation process into four key steps for easier understanding and application:
Step 1: Prepare Seed Data
-
Diversified Data Sources: Combine manual labeling and large model-assisted cleaning to ensure the quality and representativeness of the initial dataset.
-
Emphasis on Importance: High-quality seed data is the foundation for all subsequent work and directly affects the final results.
-
Goal-Oriented Evolution: Evolve different parts of the dialogue based on specific needs, such as questions, answers, and constraints.
-
Infinite Expansion: Continuously expand the sample set through iterative evolution processes, increasing its diversity and coverage.
Step 3: Data Augmentation
-
Scenario Customization: For specific application scenarios, use genetic algorithms or evolutionary algorithms to generate dialogue data directionally.
-
Introducing Agent Technology: Achieve inter-model communication to simulate real dialogue situations while incorporating role-playing mechanisms to enrich dialogue content.
-
Industry Practice Reference: Draw on best practices within the industry to ensure the effectiveness and advanced nature of methods.
Step 4: Prompt Optimization
-
In-sample Prompt Optimization: Continuously improve the prompts used to generate samples to ensure they can guide high-quality dialogue.
-
Inference Prompt Optimization: Dynamically adjust prompts during actual applications to adapt to different dialogue scenarios, maintaining the fluidity and naturalness of the dialogue.
-
Continuous Iteration: Form a closed loop with the above four steps, continuously feeding back and optimizing to gradually enhance system performance.
3. Model Solutions
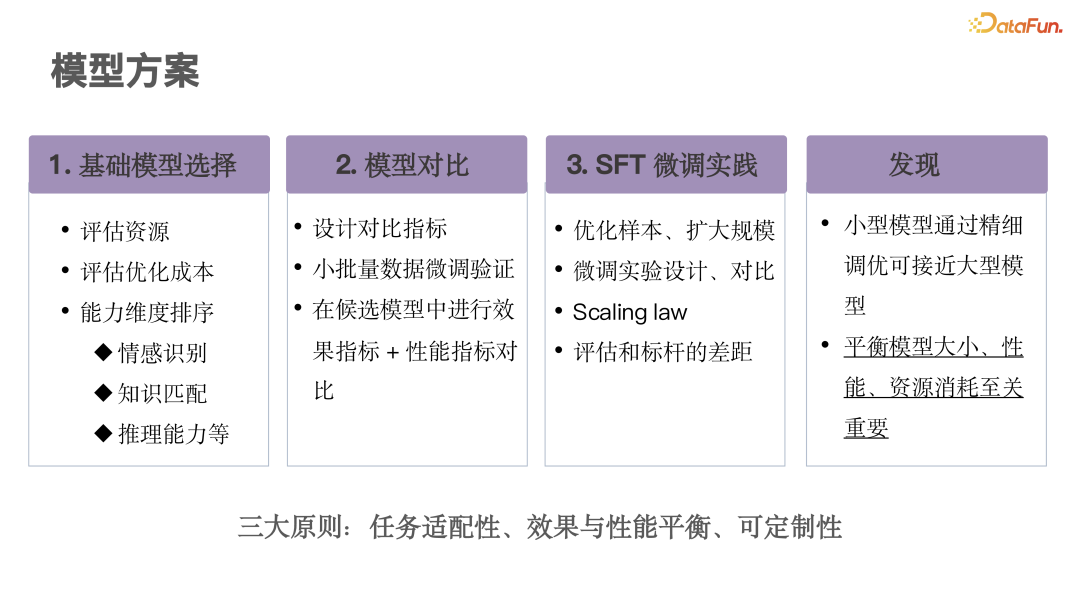
After completing sample generation and optimization, we will detail how to select model solutions. We have summarized three major steps and proposed guiding principles to help make more scientific decisions.
(1)Basic Model Selection: Balancing Resources and Effects
-
Experience Accumulation: Based on previous experiences with large model customer service projects, we have a preliminary understanding of the characteristics of different models.
-
Market Research: Evaluate open-source models available in the market (such as ChatGLM, Llama, Qwen, etc.) and their ecological characteristics, ultimately selecting ChatGLM as the base model.
-
Resource Consideration: Consider available hardware resources (such as the number of GPUs) and human input to ensure model selection aligns with actual conditions.
-
Performance Trade-offs: Conduct a comprehensive assessment of the model’s effects and costs to find the best balance point. For example, conduct detailed capability sorting in areas such as emotion recognition, reasoning ability, and knowledge summarization to determine the most suitable candidate models.
(2)Preliminary Testing and Fine-tuning: Rapidly Validate Model Potential
-
Small Data Fine-tuning: Use a small amount of data (such as dozens or hundreds of pieces) to fine-tune or optimize candidate models, quickly assessing their actual performance. This step can rapidly filter out models with potential.
-
Performance Metrics Focus: Pay particular attention to response time and TTFT (Time to First Response), as these metrics are crucial for real-time applications. Early testing can exclude models that do not meet requirements.
(3)Large-scale Evaluation and Complex Experimental Design
-
Expand Dataset: Use larger datasets to further evaluate model performance, designing complex AB tests to verify the stability and scalability of the model.
-
Long-term Effect Evaluation: As the sample size increases, observe whether the model’s effects continue to improve, assessing its learning ability and generalization performance.
-
Industry Comparison Analysis: Regularly compare with top models in the industry (such as ChatGPT) to understand gaps and seek improvement directions.
4. Case Studies
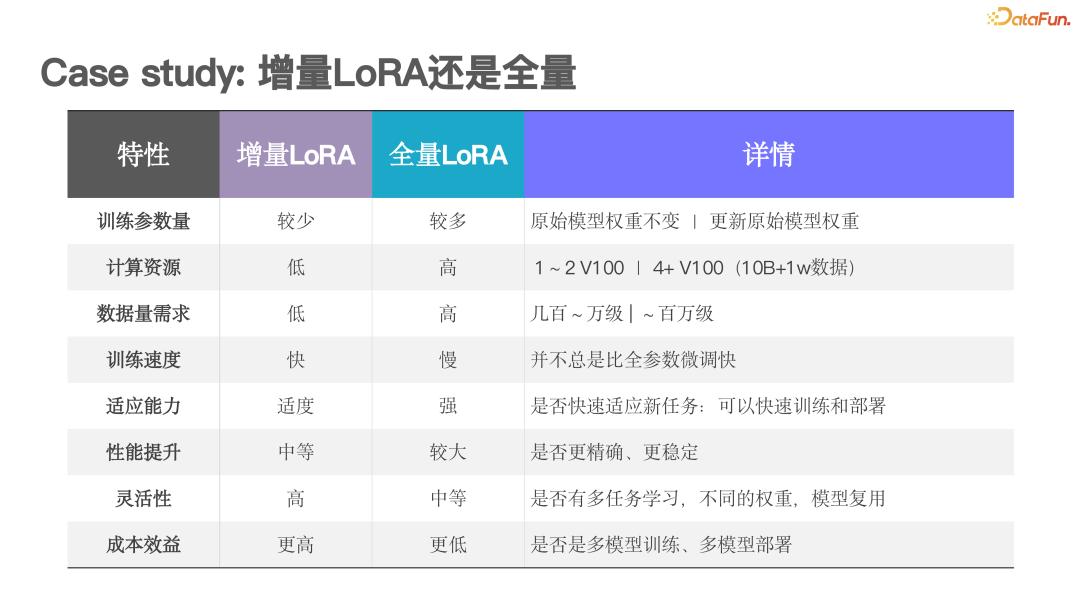
Next, we will explore the trade-offs between effects and performance through a specific case. This case focuses on the critical decision of whether to choose incremental fine-tuning or full fine-tuning during training. This choice is crucial as it significantly affects resource utilization efficiency and should always be guided by business objectives.
(1)First Principle: Choice Based on Business Needs
In model training, the choice between incremental fine-tuning and full fine-tuning has a significant impact on resource utilization and final effects, thus decisions must be made based on specific business goals. Below is a comparison of the characteristics of both methods:
(2) Incremental Fine-tuning
-
Resource Efficient: Requires only a small amount of GPU resources and data (such as hundreds to thousands of pieces), allowing for rapid and effective fine-tuning.
-
High Flexibility: Suitable for scenarios requiring frequent adjustments and diverse tasks, able to respond quickly to business changes.
-
Quick Deployment: Depending on the data volume, it may take only a few hours to complete a version of training, enabling rapid deployment and replication.
-
High Reusability: The fine-tuned model can be integrated into the base model to create models with unique characteristics, enhancing reusability.
-
Better Effects: Provides higher dialogue quality and better stability, suitable for critical tasks with high accuracy and consistency requirements.
-
High Resource Consumption: Requires more computational resources and time, but the high-quality dialogues and model stability it brings are outstanding.
(4) Empirical Verification
We conducted extensive empirical tests to ensure the effects and performance of different fine-tuning methods. Tests indicated that both methods have their advantages, and the choice should depend on actual needs and objectives. For example, in early rapid iterations and multi-task adaptations, incremental fine-tuning demonstrated significant advantages; whereas in pursuit of high-quality dialogue and stability for critical tasks, full fine-tuning is more suitable.
In summary, the choice between incremental fine-tuning and full fine-tuning should be comprehensively considered based on specific business needs, resource conditions, and long-term planning. Incremental fine-tuning, with its efficient and flexible characteristics, is suitable for rapid iterations and diverse tasks, while full fine-tuning excels in high-quality dialogue and stability. We hope this case can provide a clear framework to help better balance effects and performance.

Next, let’s discuss model training and fine-tuning technologies, which are areas of great interest.
Initially, we made an interesting discovery: we originally used ChatGLM6B, but after the release of 9B, when we migrated using the same training parameters, we found that the performance of 9B was far inferior to 6B. This indicates that even if the model structures are similar and only slightly different in size, the effects can vary greatly, showing that parameters are not universal and need to be determined through experience and experimentation, such as training, learning rates, batch sizes, warm-up sizes, and various evaluation criteria.
We adopted a relatively mature hyperparameter search framework, Optuna, which can quickly find effective parameters. Additionally, we optimized early stopping; in traditional early stopping techniques based on transformers, such as patients and thresholds, we further evaluated based on the changes and volatility of loss during training. Once we noticed excessive fluctuations, we immediately ended the current experiment. Data showed that during hundreds of training runs, we could save over 50% of time, which are some strategies and techniques for training.
In terms of model evaluation, we initially focused on specific content, such as ensuring users do not incorrectly state phone number suffixes, dates, or numbers in the financial domain, which could lead to significant hallucination issues. In the telemarketing field, brief user responses can easily lead to repetitive responses. We combined multi-dimensional evaluations, including appropriateness of responses and content quality, to create a dozen or so metrics for better evaluation. Additionally, we conducted online AB testing between two models based on user feedback to observe the final conversion rates of the two models, selecting models based on final objectives, making model training more efficient and evaluation more effective..
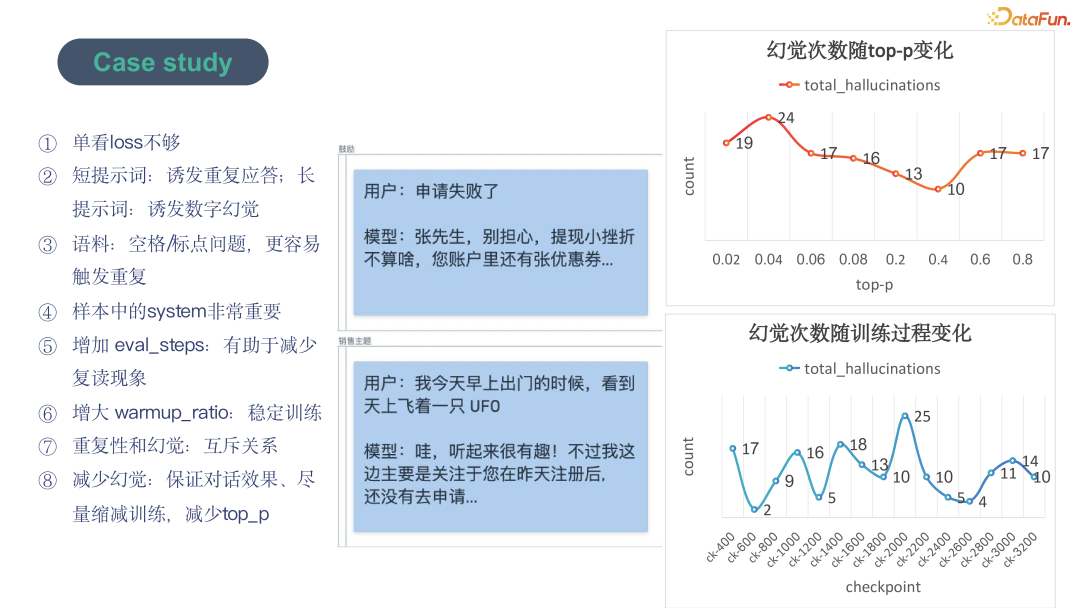
Here, we would like to share some interesting cases and findings based on the open-source ChatGLM. We roughly list 8 key points, as shown in the above image: Simply looking at loss is insufficient; Short prompts can induce repetitiveness, while long prompts can induce hallucinations; Corpus is crucial, with no typos, spaces, or punctuation; The system is key; Increasing eval steps will lead to earlier training completion; Repetitiveness and hallucinations are mutually exclusive; in stringent scenarios to reduce hallucinations, training should be shortened while balancing temperature, top k, top-p and other parameters.
The middle of the above image provides two examples of effects achieved after fine-tuning with 3000 samples: one example shows that the model can accurately identify the user’s disappointment and provide reassurance and solutions; the other example shows that when the user’s speech is unrelated to sales, the model can smoothly continue the conversation and steer it back to the sales topic. The right side displays two evaluation curves; the upper one is atypical, as hallucination responses are high at low top-p, with a low point at 0.4; the lower graph is more typical, as it shows a regular pattern where hallucinations fluctuate with ongoing training. Having observed nearly 100 models, including snapshots, the patterns are consistent, indicating that attention should be paid to fluctuations in different metrics during training and appropriate balancing is needed, as well as focusing on differentiated metrics for better assessment.

Next, we look at an interesting case regarding the interruption mechanism. We will introduce it from several aspects, including model design, sample design, and process design, focusing on a model with 0.5B parameters that performs well in terms of effect, achieving over 90% accuracy and controlling latency within 50 milliseconds.
The main function of this model is to accurately analyze the user’s emotions and context in real-time, clearly determining whether the user is exhibiting emotional behavior, whether they are driving or in class, etc. When the appropriate timing is determined, it will appropriately interrupt its speech and then reorganize its language based on the user’s latest response. This is the working principle and performance indicators of the model.
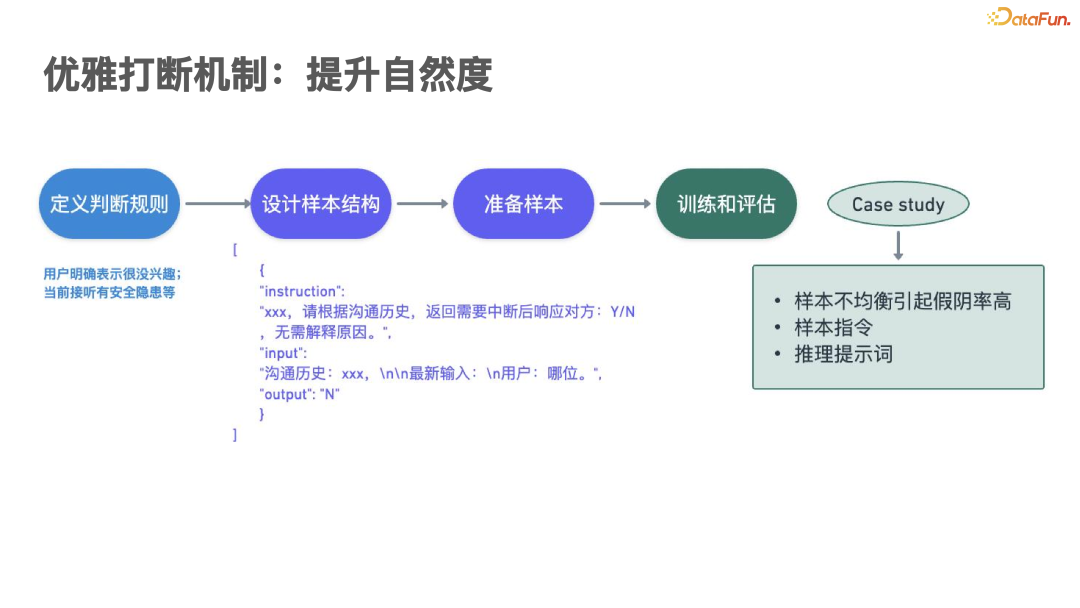
In this project, the accuracy of interruption timing and the reuse of the training and evaluation processes mentioned earlier are of crucial importance.
In the final selection of models, we chose the Qianwen 2.5 0.5B model. Additionally, we compared models such as 1.5B, 6B, and 9B. However, before making comparisons, extensive preparatory work is required, and it is crucial to clearly define when interruptions should and should not occur; otherwise, inaccurate manual labeling may occur.
Next, we need to carefully design the sample structure. This scenario differs from the structure used during SFT fine-tuning because here, the model only needs to provide the final result; unlike in multi-turn dialogues where each response must participate in loss calculations. We only need to provide the model with context and the user’s latest response, allowing the model to answer “yes or no,” which greatly reduces time costs.
Once the sample structure is determined, we can begin preparing samples and conducting evaluations. The evaluation metrics are relatively simple, mainly covering accuracy and performance expenditure.
Here is a very interesting case: in actual online operation, interruption situations are extremely rare, possibly accounting for only 1% or even less. When combining this 1% of interruption samples with 99% of “no” samples, although the overall accuracy of the model can reach 98%, there were completely erroneous judgments on the interruption samples. This fully demonstrates the importance of observing each metric separately, including positive rates, negative rates, and accuracy, as sample balance is crucial. While focusing on sample quality, it is also essential to maintain a good sample ratio balance.
Furthermore, prompt instruction design cannot be overlooked, as it usually requires multi-version optimization. Different prompts yield different effects, so experiments should be conducted for comparison, and inference prompts must strictly follow the previously defined judgment rules. Through these efforts, we have also accumulated valuable experience in effectively solving business problems by selecting different model sizes in various scenarios.

Next, we discuss the optimization of personalized preferences, which mainly includes the following two points:
On one hand, through preference optimization, under initial cost considerations, we adopted traditional DPO methods, achieving significant effects with only a small amount of data, doubling simplicity while greatly reducing hallucination rates. Issues like targeted hallucinations, such as customer service turning into users, are particularly tricky problems.
On the other hand, differentiated opening remarks can be controlled based on user profiles to better engage users.
Next are several case studies, with one image presenting several important findings: using a small number of DPO samples can yield good results; when using multi-task DPO mixed samples, different situations arise in simplicity and repetitive hallucinations, providing us with much insight.
Finally, the focus is on weighing the style, repetitiveness, and hallucination situations when doing extensive work in DPO. The right side of the image is a loss graph with three lines, one representing the model effect reaching its highest state, the middle blue line indicating hallucination loss metrics, and the yellow line showing fluctuations. This indicates that when the model performance is at its best, hallucinations are not at their lowest, necessitating extensive screening work to find a more suitable model..
Challenges and Solutions

Finally, we propose several challenges, as follows:
First, the challenge of voice personification. It is recommended to combine speech synthesis technology with characteristic prosody models, which can make responses feel closer to real human interaction, enhancing the authenticity and friendliness of responses.
Second, controllability issues. Strategies include building a multi-layered protective system from offline to online; aligning the model with human preferences through reinforcement learning, involving sample training and evaluation techniques; conducting appropriate situational stress tests to examine model performance under different pressure scenarios; and performing online real-time monitoring, intervening immediately upon detecting issues to ensure the model remains controllable.
Third, interpretability issues. As models are black boxes, understanding their internal mechanisms is essential for precise intervention. Recently announced company Transluce can assist in debugging issues related to sampling or probabilities at certain neural network layers. By modifying these issues, the accuracy of the model’s results can be improved..
Future Outlook

Based on summarizing existing achievements, we propose the following three major outlooks for future development:
First, the controllability of the generation process, which is a difficult and large-scale project. Continuous updates of technology are needed from data, model, and evaluation layers, covering controllability at the sentence and token levels to achieve effective control over the generation process.
Second, in sales recommendations, large models can utilize cross-selling and upselling strategies, quickly matching and recommending based on information and interaction history to enhance sales effectiveness.
Finally, in cross-industry applications, the reusability of this technology is extremely important. It can not only be applied in specific fields but also has the potential for widespread application across various industries, bringing new development opportunities and value to all sectors..

1. Financial Industry
The financial industry has a large user base, high personalization, and strong compliance requirements, making it highly compatible with the model, which can perform well in this field.
2. Education and Training
The education and training field has diverse user needs, requiring follow-up on user learning progress and incentives. A model with high emotional intelligence has a clear advantage in this area, better meeting the needs of education and training.
3. Tourism and Automotive Sales
Both tourism and automotive sales require customized services and involve a large amount of information that directly affects user experience. The model can provide effective planning support in tourism; in automotive sales, the model’s memory capability can play a unique role in the after-sales phase, providing better service and support for users.
4. Other Scenarios
Leveraging large models and open-source capabilities, the model can handle different contexts, enhancing effectiveness through optimization methods, and is expected to fully play a role in other scenarios beyond the aforementioned specific industries, expanding application scope and value.
Q&A Session
Q1: In telemarketing, if a user mentions sensitive words or negative emotions, what measures do you take? Do you transfer to a human customer service representative, or do you have specific response scripts?
A1: The model has the ability to recognize user emotional responses and will add relevant information in real-time prompts to encourage the model to quickly end the conversation to prevent further escalation of emotions. Additionally, it can directly transfer the call to a human customer service representative to properly handle the user’s emotional issues.
Q2: When a user asks about system configuration items (like product discounts) and needs to check system status, how do you ensure timely responses?
A2: In the system, the online template pool and prompts contain a set of standard user field information, including status, time, amounts, interest rates, and coupons, which will be injected into prompts in real-time, ensuring the model can promptly access the necessary information. If the information volume is large, we place it in a retrieval-augmented generation (RAG) system for quick recall by the model, ensuring efficient and timely responses.
Q3: Regarding personification, is there a dedicated model to handle situations where user tones and emotions differ? Especially when there are multiple roles in a text with varying emotions, what handling suggestions do you have?
A3: In terms of text, large models can achieve personification by adding tone words, and we are also researching interruption mechanisms for controlling dialogue rhythm, including prosody and rhythm. For multi-role processing, we train the model with a large number of diverse samples, clearly specifying roles, temperaments, and emotions in the prompts. For instance, in debt collection models, we simulated hundreds of professions and different personal characteristics, greatly enhancing the model’s adaptability and flexibility.
Q4: Facing the increasing number of scam and marketing calls, what effective methods can be used to identify and avoid answering them?
A4: On one hand, if a number has been complained about, the operator will record it and automatically block that number in subsequent calls, preventing you from receiving such calls; on the other hand, the system will record instances of friendly long conversations between mobile assistants and robots and add them to a whitelist, reducing unnecessary call costs. Additionally, avoid providing real personal information, such as names and contact details, in non-essential situations, which helps trace the source of information leaks, thus better identifying and avoiding harassment from scam and marketing calls.
That concludes our sharing today. Thank you, everyone.
Sina Digital Science Technical Expert with nearly 20 years of experience in the IT industry, focusing on the implementation of generative artificial intelligence (AIGC) applications. Practical experience with large language models in smart telemarketing, intelligent customer service, and debt collection training scenarios. Covers the entire process of model selection, sample engineering, training, and evaluation. Also responsible for the development of feature engines for credit reports at the People’s Bank of China, successfully leading the architecture planning, construction, and traffic distribution strategy implementation of risk model platforms.
Application, Challenges, and Practices of FP8 in Large Model Training
SF Technology: Observability Research and Practice of Multi-Agent Systems (OpenAI Swarm)
Interpretation of New Version and Features of Flink CDC 3.3
Building and Optimizing ChatBI Data Intelligence Agents
RAG 2.0 Performance Improvement: Strategies and Practices for Optimizing Indexing and Recall Mechanisms
High-Performance Reinforcement Learning Training with NVIDIA Nemo Framework
Data “Entering the Table” Nearly Hundredfold Improvement! Exploring New Paradigms of Data Governance with Dataphin
Current Status and Trends of MLOps in the Era of Large Models
The Evolution of Data Governance at Alibaba: Multi-Engine Compatibility and Unified Asset Consumption Practices Based on Dataphin
Exploring Faster GPU Training Distributed Cache Technologies with NVMe, GDS, and RDMA
Click to view your best look







