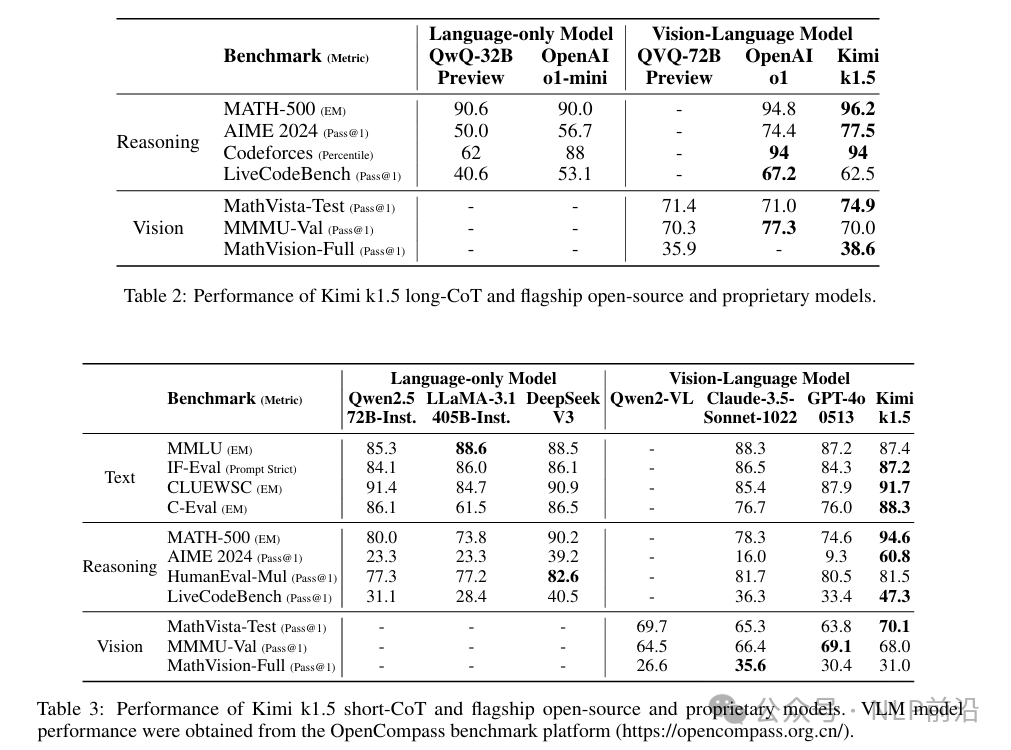
Yesterday, everyone was shouting about the New Year! Kimi has released a rare technical report, let’s take a look at the technical details.
The technical report is here: https://github.com/MoonshotAI/Kimi-k1.5
First, as always, Kimi emphasizes long context. So the question arises: if we provide the model with a longer ‘thinking space’, can it naturally learn to plan and reason?
Moreover, I must say, this image is very interesting. The reasoning model compared to the ordinary model left AIME puzzled for a long time (referring to just this image).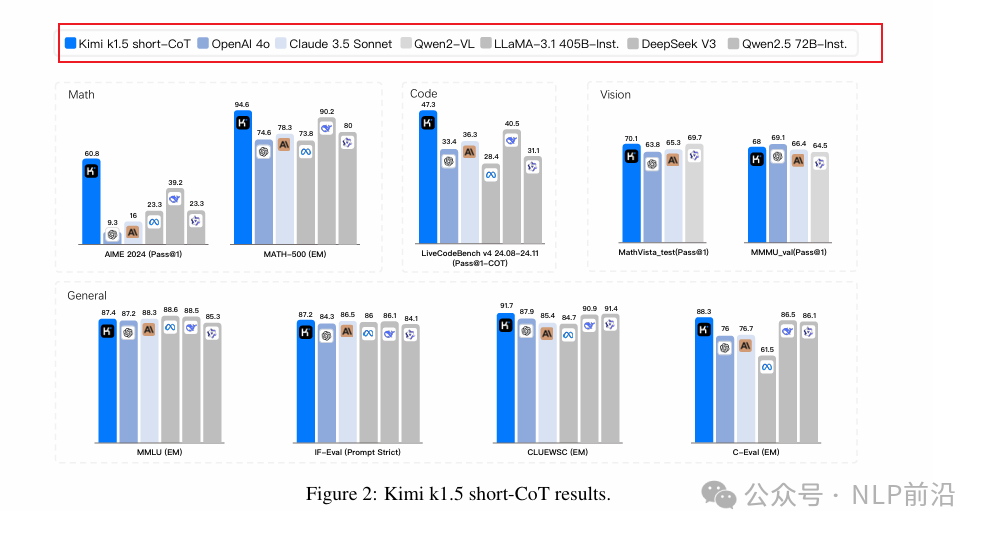
Three stages: Pre-training & SFT -> RL -> Longshort
Pre-training
Divided into three sub-stages, as mentioned in Appendix B.4
In simple terms:
-
Pre-training phase: First, build a basic language model, then train the visual part separately without updating the language model parameters, then unfreeze, and finally train with a visual:text ratio of 30%. -
Annealing phase: Use high-quality data and synthetic data for training. -
Training long contexts: set the base to 1,000,000, gradually expanding the length from 4,096 to 32,768, ultimately reaching 131,072. The long context data ratio is controlled at 40%:60%.
RL
Divided into two stages: Warm-up & Reinforcement Learning
Reinforcement learning has no value function, no Monte Carlo, and no process supervision, only result supervision.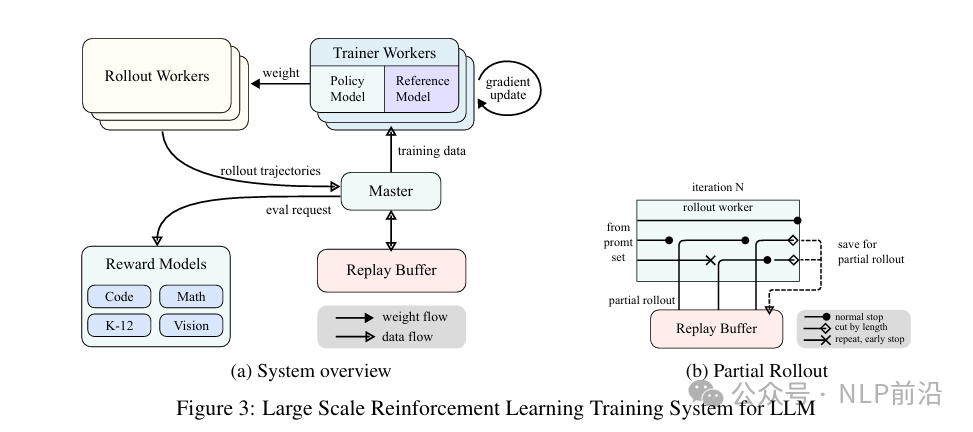
How to construct high-quality data?
-
Diversity, covering a wide range of fields. -
Difficulty balance, how to assess difficulty? Sample 10 times, calculate the pass rate; the higher the pass rate, the lower the difficulty, and vice versa. -
Accuracy, answers must be objectively verifiable. -
Address reward hacking: -
Exclude easily guessable questions, such as multiple-choice questions and yes/no questions, and questions based on proofs. -
Remove easily cracked questions, no reasoning, directly state the answer; if it can be answered correctly within a few attempts, it’s too easy.
-
-
Data filtering: -
Automatic filtering based on reasoning processes, evaluation angles, and image-text angles. -
Labeling system for balanced fields, disciplines, and classifications.
-
-
Special handling for specific fields, such as programming and mathematics.
RL steps:
-
Warm-up: Fine-tune using a small validated long-cot dataset. -
Reinforcement Learning.
Reinforcement learning uses a partial rollout strategy to handle long sequences.
For example, suppose there are three samples: A needs 2000 tokens, B needs 500 tokens, C needs 300 tokens.
If we wait for A to finish, then B and C will waste many tokens, resulting in low batch processing efficiency. The partial rollout specifies a maximum length, say 500; A generates 500 and then stops, and next time continues from there. This avoids long tasks blocking the training process.
Why is process supervision unnecessary? They believe that the model exploring incorrect paths is also meaningful, as long as it ultimately arrives at the correct answer, the model can learn from its mistakes.
Here, there is no value function estimating advantage; instead, the mean of sampled rewards is used as a baseline.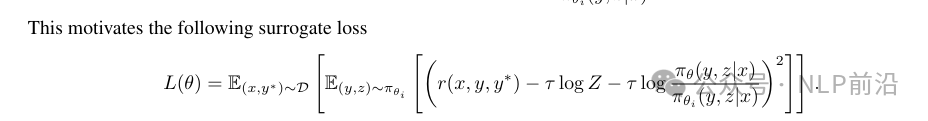
Finally, the Longshort phase
Longcot is already very powerful, but is it possible to transfer long thinking chains to short thinking chains? That is, to improve performance under a limited token budget.
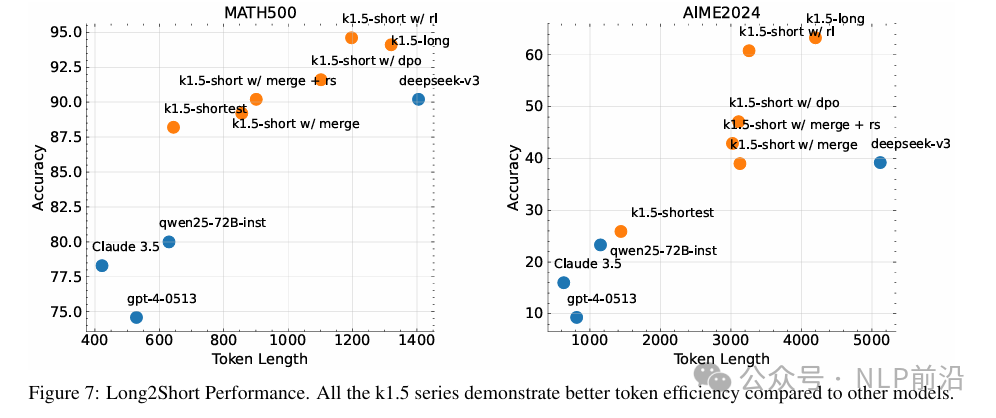
As shown in the figure, there are four methods:
-
Merging: Averaging the weights of the long and short models. -
Short sampling: Sampling 8 times for a question, selecting the shortest correct response for fine-tuning. -
DPO: Selecting the shortest correct response as positive, regardless of whether the longer one is correct as negative. -
RL: Increasing length penalties and reducing rollout lengths.