

1. SAM
1.1. Tasks

1.2. Network Architecture
-
Image encoder, which generates one-time image embeddings. -
Prompt encoder, which generates prompt embeddings; prompts can be points, boxes, or text. -
A lightweight mask decoder that combines the embeddings from the prompt and image encoders.
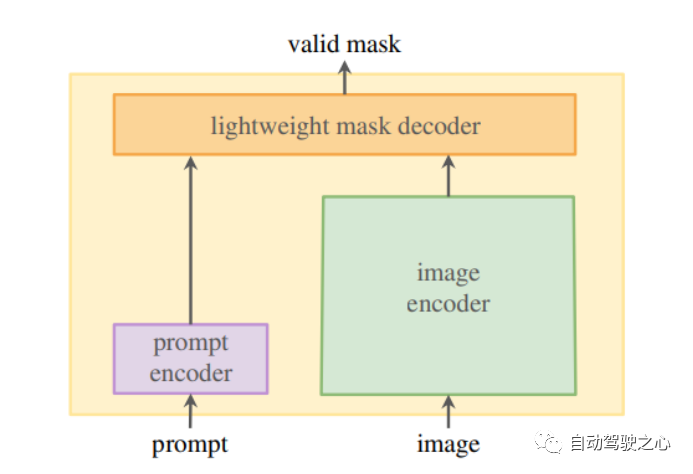
1.2.1. Image Encoder
1.2.2. Prompt Encoder
1.2.3. Mask Decoder
1.3. Dataset
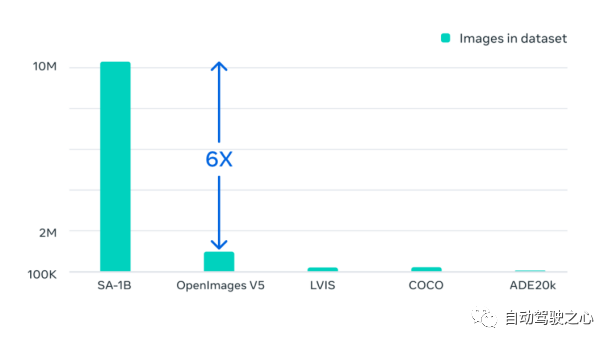
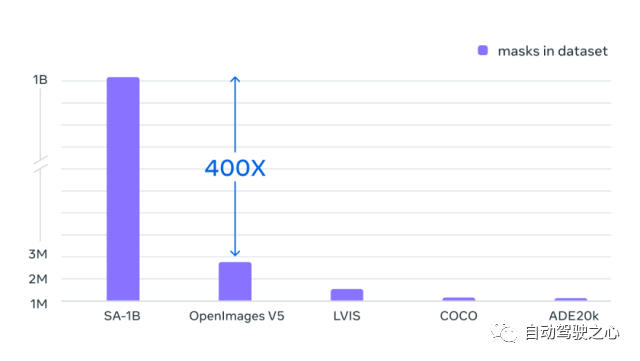
1.4. Zero-Shot Transfer Experiments
1.4.1. Zero-Shot Single Point Valid Mask Evaluation
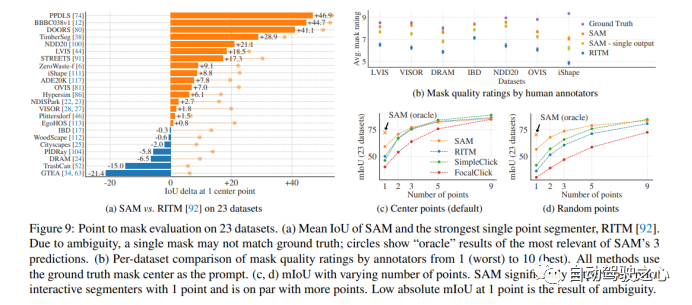
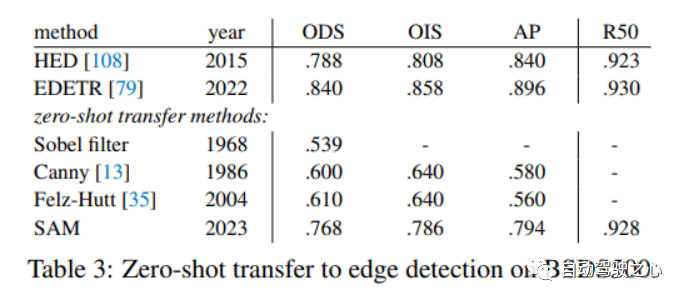
1.4.2. Zero-Shot Edge Detection

1.4.3. Zero-Shot Object Proposals

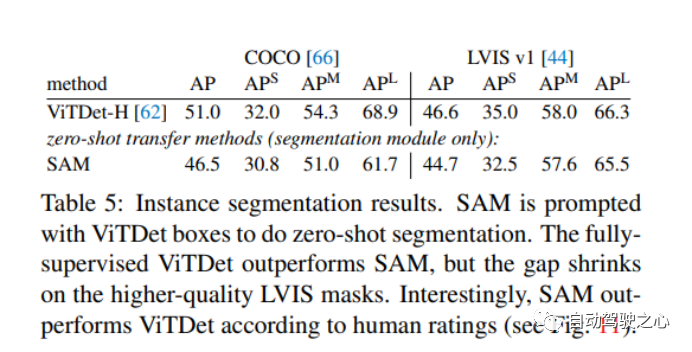
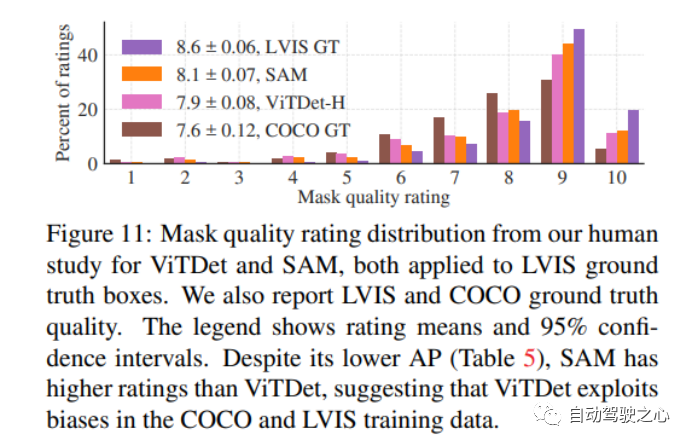
1.4.4. Zero-Shot Instance Segmentation
1.4.5. Zero-Shot Text to Mask

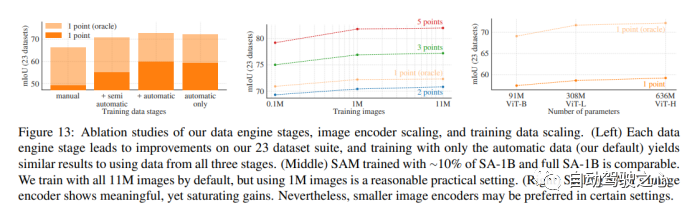
1.4.6. Ablation Studies
2. Grounded-SAM




3. SegGPT

-
SegGPT “one-to-many”: it can use one or a few example images and corresponding masks to segment a large number of test images. Users can annotate and recognize a type of object in one image, allowing for batch recognition and segmentation of all other similar objects, whether in the current image or in other images or video contexts. -
SAM “one-touch”: it provides interactive prompts on the target image through a point, bounding box, or a sentence, identifying and segmenting specified objects in the image. This means that SAM’s fine annotation capability can be further combined with SegGPT’s batch annotation and segmentation capabilities to create new CV applications. Specifically, SegGPT is a derivative model of the Zhiyuan universal visual model Painter, optimized for the goal of segmenting everything. After training, SegGPT does not require fine-tuning; it only needs to provide examples to automatically infer and complete corresponding segmentation tasks, including instances, categories, parts, contours, text, faces, etc., in images and videos.
-
Universal capability: SegGPT has contextual reasoning ability, allowing the model to adaptively adjust predictions based on the masks provided in the context (prompt), achieving segmentation of “everything”, including instances, categories, parts, contours, text, faces, medical images, etc. -
Flexible reasoning ability: supports any number of prompts; supports tuned prompts for specific scenarios; can represent different targets with different color masks, achieving parallel segmentation reasoning. -
Automatic video segmentation and tracking capability: using the first frame of an image and the corresponding object mask as context examples, SegGPT can automatically segment subsequent video frames and use the mask colors as object IDs for automatic tracking.
3.1. Methods
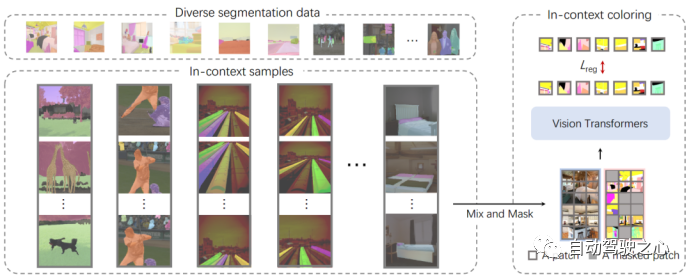
3.1.1. In-Context Coloring
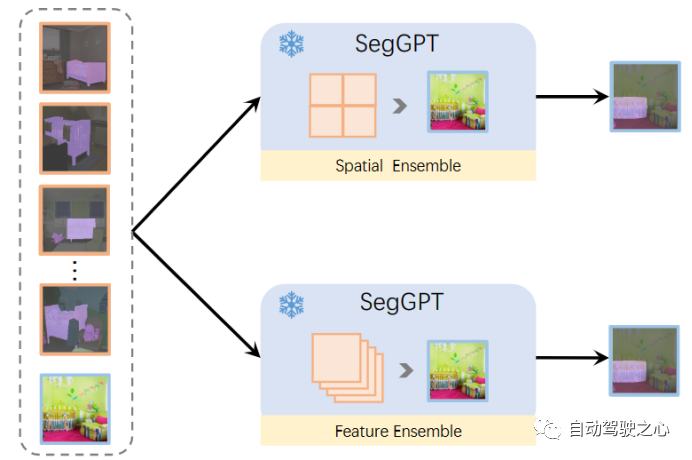
3.1.2. Context Ensemble
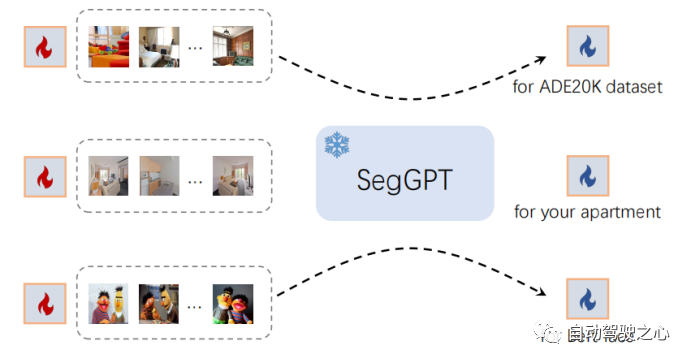
3.1.3. In-Context Tuning
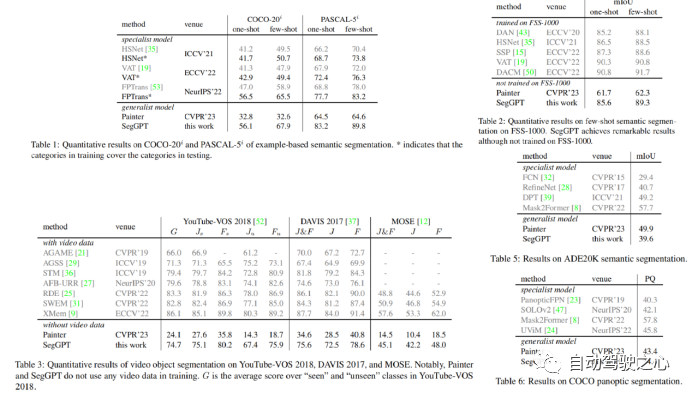
3.2. Experiments
4. SEEM
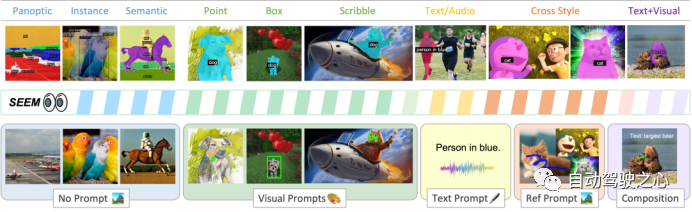
-
Versatility: Handles various types of prompts, such as clicks, box selections, polygons, sketches, text, and reference images; -
Compositional: Handles any combination of prompts; -
Interactivity: Engages in multi-turn interactions with users, benefiting from SEEM’s memory prompts to store session history; -
Semantic-aware: Provides semantic labels for any predicted masks.
4.1. Methods
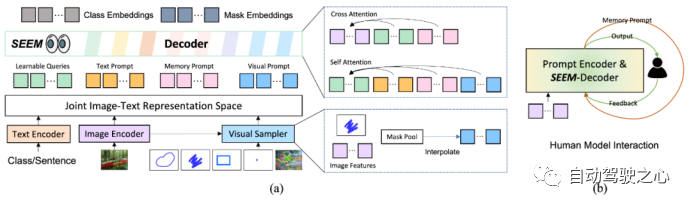
-
The user provides a prompt; -
The model sends prediction results to the user; -
The model updates the memory prompt.
4.1.1. Versatility
4.1.2. Compositional
4.1.3. Interactive
4.1.4. Semantic-aware
4.2. Experiments
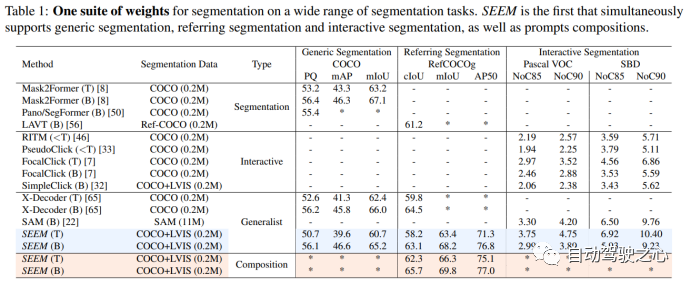
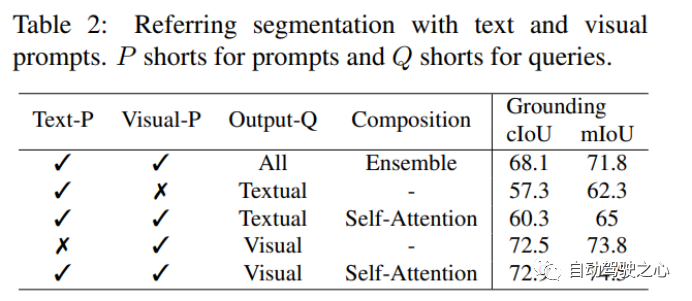
ABOUT
关于我们
深蓝学院是专注于人工智能的在线教育平台,已有数万名伙伴在深蓝学院平台学习,很多都来自于国内外知名院校,比如清华、北大等。