

Concept of Deep Learning
Deep Learning (DL) was first proposed by G. E. Hinton and others at the University of Toronto in 2006. It is a machine learning (ML) process that derives a deep network structure with multiple layers based on sample data through certain training methods. Machine learning typically analyzes structured data using traditional algorithms such as decision trees, logic programming, clustering, and Bayesian networks to make decisions and predictions about real-world events. Deep learning was introduced to machine learning to bring it closer to its original goal—Artificial Intelligence (AI). The motivation is to build models that simulate the neural connections of the human brain, forming more abstract high-level representations, attribute categories, or features by combining low-level features, thus providing a hierarchical feature representation of the data. It extracts knowledge from data to solve and analyze problems using artificial neural network algorithms, allowing the discovery of hierarchical representations to extend standard machine learning. These hierarchical representations can solve more complex problems with higher accuracy, fewer observations, and simpler manual tuning, potentially addressing other issues. Traditional neural networks randomly initialize network weights, which can easily lead to convergence at local minima. To solve this problem, Hinton proposed using unsupervised pre-training methods to optimize the initial weights of the network, followed by fine-tuning the weights, marking the dawn of deep learning. The deep network structure obtained through deep learning contains a large number of single elements (neurons), each connected to many other neurons. The strength of the connections (weights) between neurons is modified during the learning process and determines the function of the network. The deep network structure derived from deep learning conforms to the characteristics of neural networks, thus a deep network is a deep neural network (DNN). A deep neural network is composed of multiple layers of nonlinear networks stacked together, and common single-layer networks are classified into three types based on encoding and decoding: those that only contain the encoder part, those that only contain the decoder part, and those that contain both encoder and decoder parts. The encoder provides a bottom-up mapping from input to hidden feature space, while the decoder aims to reconstruct results as closely as possible to the original input by mapping hidden features back to the input space. Deep neural networks can be classified into the following three types.
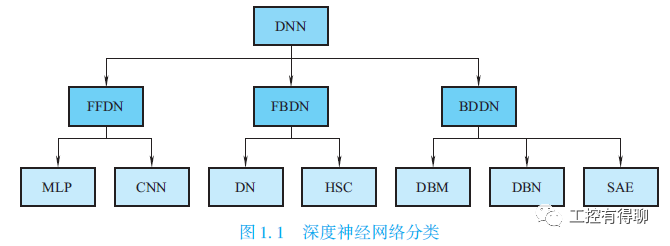
(1) Feed-forward deep networks (FFDN), composed of multiple stacked encoder layers, such as multi-layer perceptrons (MLP) and convolutional neural networks (CNN).
(2) Feed-back deep networks (FBDN), composed of multiple stacked decoder layers, such as deconvolutional networks (DN) and hierarchical sparse coding (HSC).
(3) Bi-directional deep networks (BDDN), constructed by stacking multiple encoder and decoder layers (each layer may be a separate encoding or decoding process, or may include both encoding and decoding processes), such as Deep Boltzmann Machines (DBM), deep belief networks (DBN), and stacked auto-encoders (SAE).