“Programming is the art of telling another human being what one wants the computer to do.” — Donald Knuth


📑Paper:A Survey of Neural Code Intelligence: Paradigms, Advances and Beyond
🔧GitHub:https://github.com/QiushiSun/NCISurvey
Note: The authors of the paper are from Shanghai Artificial Intelligence Laboratory, The University of Hong Kong, National University of Singapore, East China Normal University, Fudan University, NetEase Fuxi, A*STAR Singapore, and Google DeepMind.”
Introduction
Neural Code Intelligence, which utilizes deep learning to understand, generate, and optimize code, is demonstrating its transformative impact on the field of artificial intelligence. As a bridge connecting natural language and programming languages, this field has attracted significant attention from both academia and industry over the past few years, both in terms of the number of papers and applications. This review systematically revisits the progress in the field of code intelligence in chronological order, encompassing over 50 representative models and their variants, more than 20 categories of code tasks, and covering over 680 related works. Following the historical development context, this paper traces the paradigm shifts across different research stages (e.g., from modeling code with RNNs to the era of LLMs). Meanwhile, this review also organizes the major learning paradigm shifts across different stages in terms of models, tasks, evaluations, and applications. In terms of applications, code intelligence has evolved from focusing on attempts to solve specific scenarios to exploring diverse tasks during its rapid expansion, and is now focused on tackling increasingly complex and diverse real-world challenges.
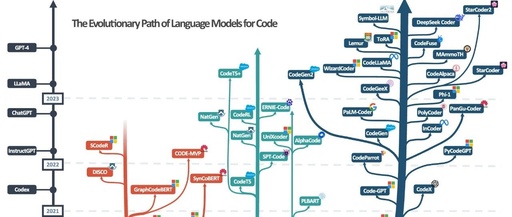
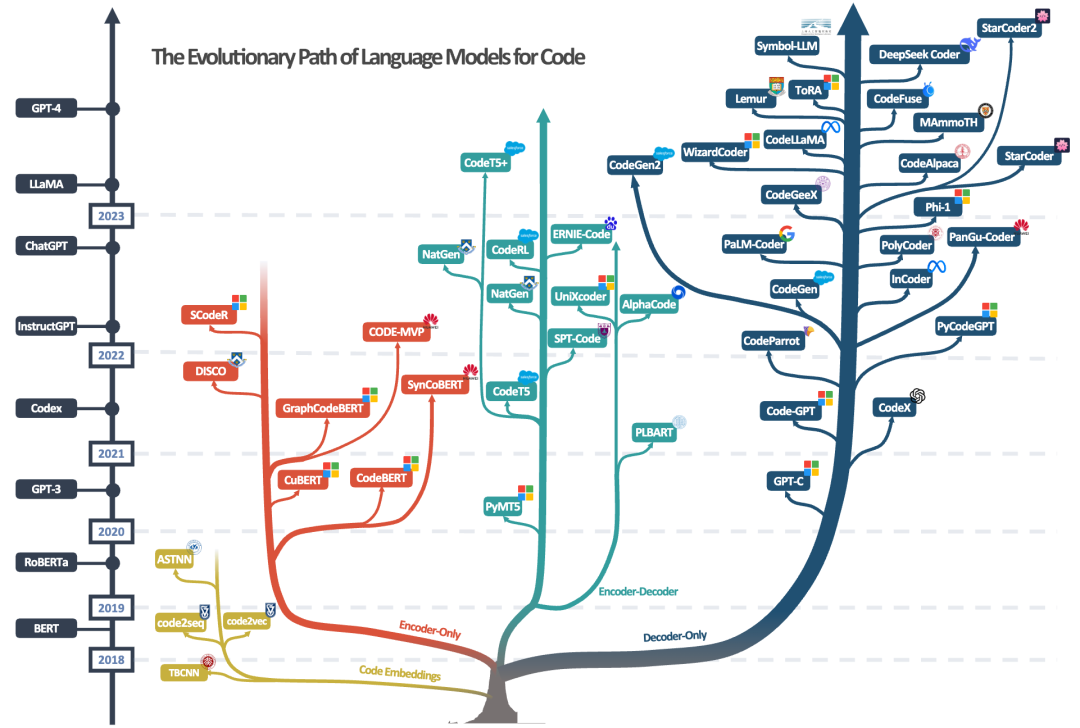
From RNN/CNN to Large Models: Key Milestones in the Development of Code Intelligence
Development of Code Models
This paper provides an extremely detailed overview of the development of code models, spanning:
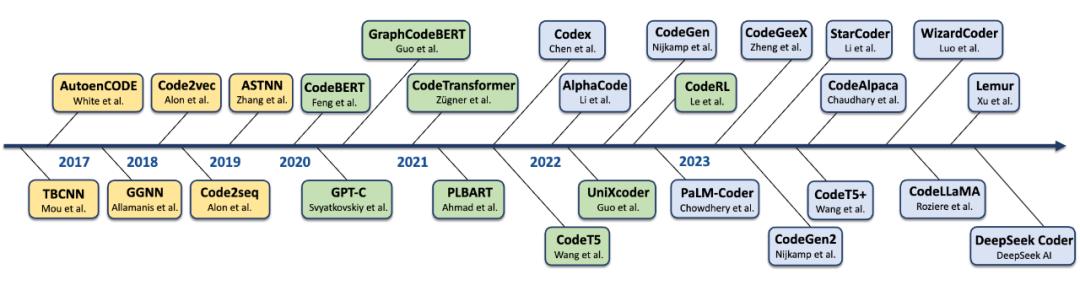
1. Neural Language Modeling Era
The neural language modeling era witnessed the earliest attempts to use deep learning for processing code. The methods designed during this period primarily relied on mature RNN/CNN architectures to model code. Notably, these methods not only utilized the textual information of the code but also extracted code structures such as Abstract Syntax Trees (AST), data flow, and control flow from the code, integrating them into the modeling process, closely linked to semantic parsing. Furthermore, since code snippets can be represented as continuous vectors, the technologies developed during this period are also referred to as Code Embeddings. The most representative techniques, such as code2vec and code2seq, capture the semantic and structural information of the code by embedding paths from the AST into vector space, enabling neural approaches to be applied to various code-related scenarios.
2. Code Pre-trained Models Era (CodePTMs)
Following the significant success of pre-trained language models in the NLP field, researchers quickly integrated their architectures for modeling code, leading to the prosperous development of Code Pre-trained Models (CodePTMs) represented by CodeBERT and CodeT5. This marks a flourishing period for code intelligence characterized by pre-training and fine-tuning, retaining the practice of modeling using code structure from the previous era while incorporating Transformer architectures to significantly enhance representation learning capabilities.
3. Large Language Models (LLMs) Era
Following the tremendous success of general LLMs like GPT-3 and PaLM in academia and industry, code large models (CodeLLMs) represented by Codex, CodeGen, and StarCoder have sparked a new wave of research. This stage also witnessed a shift in learning strategies from task-specific fine-tuning to prompt learning and in-context learning, as well as an expansion of code intelligence applications from solely code-related tasks to broader real-world scenarios, such as reasoning, mathematics, and assisting in solving classical natural language processing tasks.
Combining the discussions above, this paper organizes the relationships between code models from different eras, architectures, and sources in the figure below for researchers’ use.
Shift in Learning Paradigms
Throughout the development of models, the learning paradigm for code has undergone a similar shift as that in natural language processing, from the earliest use of neural approaches to model single tasks/scenarios, to pre-training followed by task-specific fine-tuning to handle multiple tasks, and finally to the large model era dominated by prompt learning.
Moreover, this paradigm shift has also expanded the reference scenarios of code intelligence from traditional code-related tasks to broader contexts, such as numerical reasoning, symbolic reasoning, and information extraction, which are classical NLP tasks.
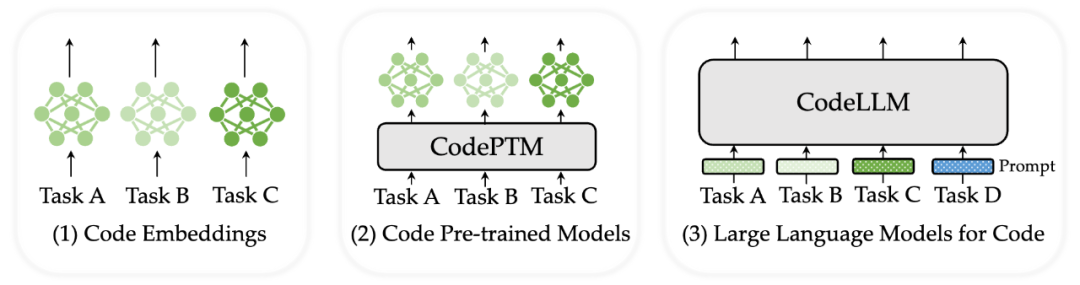
Shift in Code Learning Paradigms
Datasets and Evaluation Benchmarks
In addition to the characteristics of model architectures, this paper also systematically reviews the data used for building code models, represented by CodeSearchNet and The Stack, along with their features.
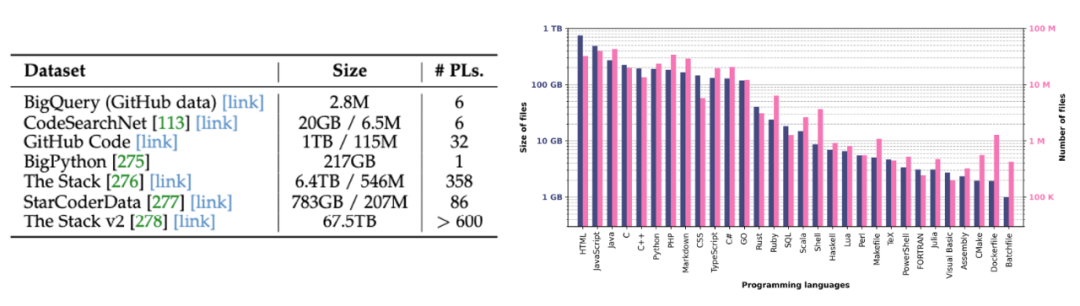
Corpus Overview and The Stack Programming Language Data Distribution
Regarding evaluation, this paper also provides a detailed review of common evaluation benchmarks in several scenarios, such as clone detection, defect detection, code translation/fixing, and code generation, and summarizes and categorizes all existing benchmarks. Additionally, it showcases the performance of different versions of some representative models when generating code and discusses them in detail.
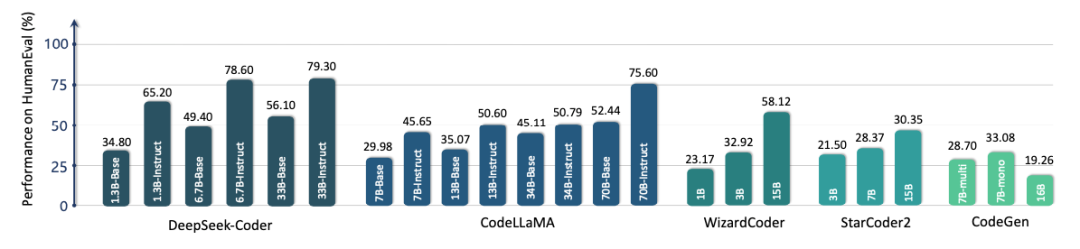
Performance of Representative CodeLLMs
Cross-domain Collaboration
In addition to common code tasks such as code generation, this paper also delves into cross-domain scenarios: code-assisted reasoning, code training and mathematical capabilities, and code intelligence solving NLP tasks, deriving the following insights:
(1) Combining code generation and symbolic solvers with LLM reasoning represents a disruptive shift in solving numerical tasks. By using executable code instead of natural language as the medium for reasoning, it not only overcomes long-standing computational limitations but also enhances the model’s interpretability and generalization capabilities. (2) Although the theoretical foundation has yet to be established, we can empirically conclude that code training can enhance LLMs’ mathematical abilities. This is gradually being accepted by the academic community. (3) Using code as an intermediate representation can significantly improve the efficiency of solving classical NLP tasks represented by information extraction. Moving beyond traditional text-centric modeling ideas, code-centric methods can effectively address complex and diverse input and output formats by constructing a unified pattern.
Applications and Future
In addition to the aforementioned research perspectives, this review thoroughly discusses the applications of code intelligence in (1) software engineering: such as programming assistants/automated software development (2) data-driven decision-making: Text2SQL and data science (3) agents: robotic control and automation (4) AI4Science: aiding molecular formula generation and automated theorem proving. Following this, the paper proposes several research directions worth exploring from the aspects of models, evaluation, applications, efficiency, and cross-domain collaboration.
Resources
In addition to the paper itself, the authors maintain a GitHub project that includes several carefully curated reading lists, tutorials, blogs, and resources used in this paper, which will be maintained long-term.
Reading Lists
🔧GitHub:https://github.com/QiushiSun/NCISurvey
Further interpretations of this paper will be provided in subsequent articles, detailing each section, so please stay tuned 🤩
To join the technical communication group, please add the AINLP assistant on WeChat (id: ainlp2)
Please specify the specific direction + relevant technical points used
About AINLP
AINLP is an interesting AI natural language processing community focused on sharing technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc., covering topics such as LLMs, pre-trained models, automatic generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, job experience sharing, etc. Welcome to follow! To join the technical communication group, please add the AINLP assistant on WeChat (id: ainlp2), specifying work/research direction + purpose of joining the group.