Machine Heart Reprint
Concept Overview
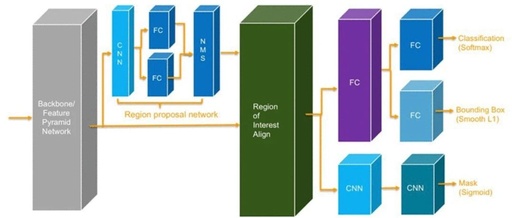
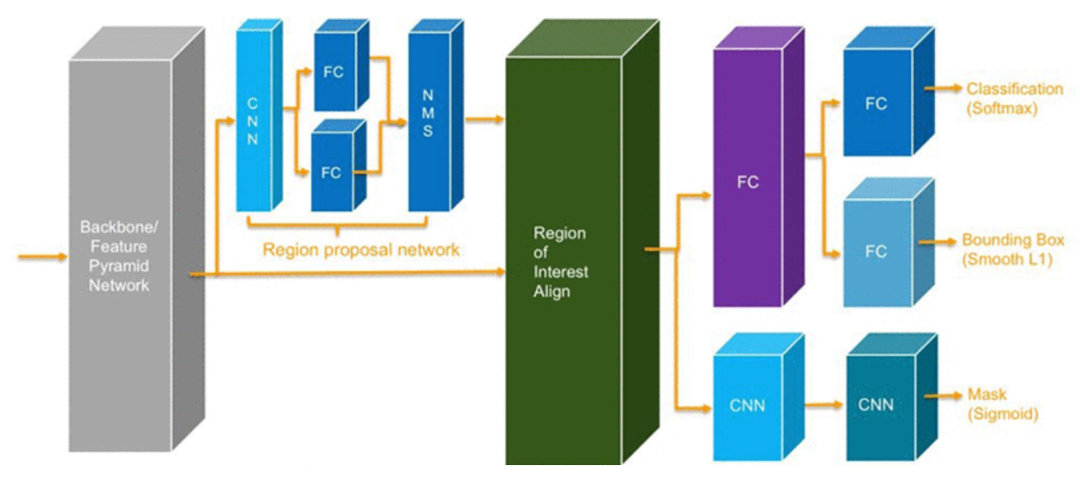
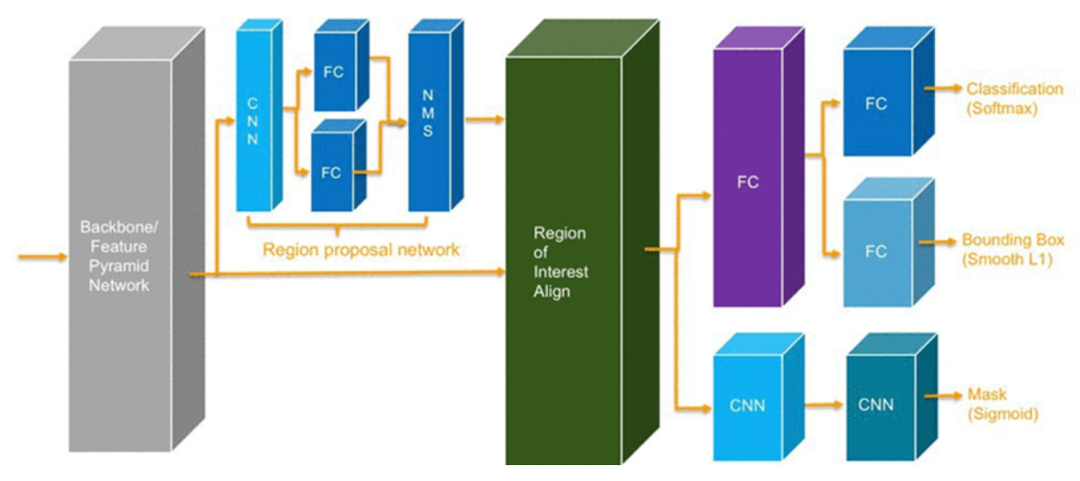
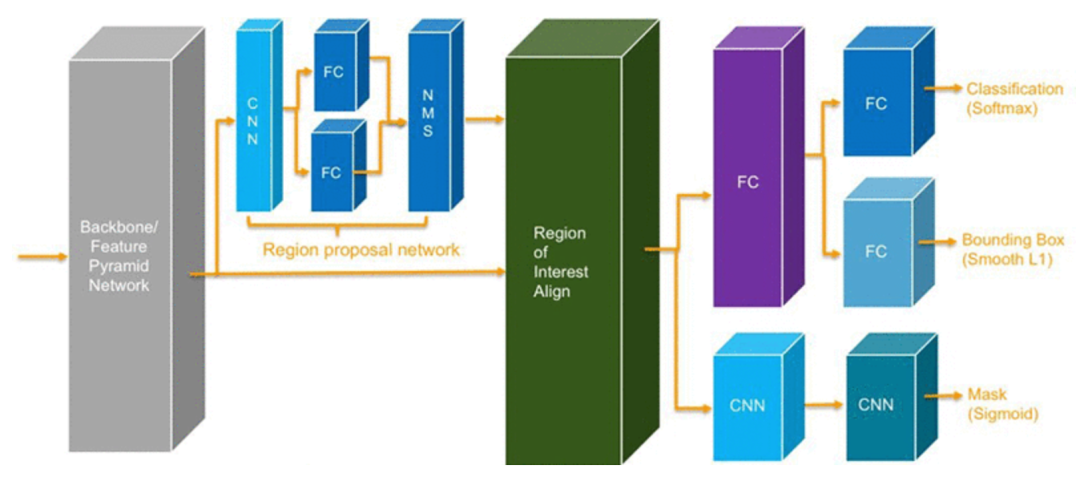
Model
-
Distributed data parallel training of Mask R-CNN on large datasets can increase image throughput through the training pipeline and reduce training time.
-
The Mask R-CNN model has many open-source TensorFlow implementations.This article uses the Tensorpack Mask/Faster-RCNN implementation as the primary example, but also recommends the highly optimized AWS Sample Mask-RCNN.
-
The Mask R-CNN model is evaluated as a large object detection model in MLPerf results.
Sync Allreduce Gradients in Distributed Training
-
The algorithm needs to scale with the increasing number of nodes and GPUs in the distributed training cluster.
-
The algorithm needs to leverage the topology of high-speed GPU-to-GPU interconnects within a single node. -
The algorithm needs to effectively interleave computations on GPUs with communications to other GPUs by efficiently batching communications.
-
Providing an efficient synchronization Allreduce algorithm that scales with the number of GPUs and nodes.
-
Utilizing Nvidia Collective Communications Library (NCCL) communication primitives, which leverage knowledge of Nvidia GPU topology.
-
Including Tensor Fusion, which efficiently interleaves communication with computation by batching Allreduce data communications.
Message Passing Interface
Integrating MPI with Amazon SageMaker Distributed Training
-
Amazon SageMaker requires that both the training algorithm and framework be packaged in a Docker image.
-
The Docker image must be enabled for Amazon SageMaker training.Using Amazon SageMaker containers can simplify the enabling process, as this container acts as a library to help create a Docker image enabled for Amazon SageMaker. -
You need to provide an entry point script (usually a Python script) in the Amazon SageMaker training image to act as an intermediary between Amazon SageMaker and your algorithm code. -
To start training on the specified hosts, Amazon SageMaker runs a Docker container from the training image,then calls the entry point script using provided information (such as hyperparameters and input data location) via entry point environment variables. -
The entry point script then starts the algorithm program with the correct args using the information passed to it in the entry point environment variables and polls the running algorithm processes. -
If an algorithm process exits, the entry point script will exit with the exit code of the algorithm process.Amazon SageMaker uses this exit code to determine whether the training job succeeded. -
The entry point script redirects the stdout and stderr of the algorithm process to its own stdout.In turn, Amazon SageMaker captures the stdout from the entry point script and sends it to Amazon CloudWatch Logs.Amazon SageMaker parses the stdout output for the algorithm metrics defined in the training job and sends the metrics to Amazon CloudWatch metrics. -
When Amazon SageMaker starts a training job requesting multiple training instances, it creates a set of hosts and logically names each host algo-k, where k is the global rank of that host.For example, if the training job requests four training instances, Amazon SageMaker will name the hosts algo-1, algo-2, algo-3, and algo-4.On the network, hosts can connect using these hostnames.
Solution Overview
-
Use AWS CloudFormation automation scripts to create a private Amazon VPC and an Amazon SageMaker notebook instance network attached to this private VPC.
-
Start a distributed training job from the Amazon SageMaker notebook instance in the Amazon VPC network attached to your private VPC.You can use Amazon S3, Amazon EFS, and Amazon FSx as data sources for the training data pipeline.
Prerequisites
-
Create and activate an AWS account or use an existing AWS account.
-
Manage your Amazon SageMaker instance limits.You need at least two ml.p3dn.24xlarge or two ml.p3.16xlarge instances, with a recommended service limit of four each.Remember, each AWS region has specific service limits.This article uses us-west-2. -
Clone the GitHub repository of this article and execute the steps in this article. All paths in this article are relative to the root directory of the GitHub repository. -
Use any AWS region that supports Amazon SageMaker, EFS, and Amazon FSx. This article uses us-west-2. -
Create a new S3 bucket or choose an existing one.
Create an Amazon SageMaker Notebook Instance Attached to VPC
-
Install and configure the AWS CLI.
-
In stack-sm.sh, set AWS_REGION and S3_BUCKET to your AWS region and your S3 bucket, respectively. You will need these two variables.
-
Alternatively, if you want to use an existing EFS file system, you need to set the EFS_ID variable. If your EFS_ID is left blank, a new EFS file system will be created. If you choose to use an existing EFS file system, ensure that the existing file system has no existing mount targets. For more information, see managing Amazon EFS file systems.
-
You can also specify GIT_URL to add a GitHub repository to the Amazon SageMaker notebook instance. If it is a GitHub repository, you can specify GIT_USER and GIT_TOKEN variables.
-
Run the customized stack-sm.sh script to create an AWS CloudFormation stack using the AWS CLI.
Start Amazon SageMaker Training Job
-
Mask R-CNN notebook using S3 bucket as data source: mask-rcnn-s3.ipynb.
-
Mask R-CNN notebook using EFS file system as data source: mask-rcnn-efs.ipynb. -
Mask R-CNN notebook using Amazon FSx Lustre file system as data source: mask-rcnn-fsx.ipynb.
-
For the S3 data source, it will take about 20 minutes to copy the COCO 2017 dataset from your S3 bucket to the storage volume attached to each training instance each time you start a training job.
-
For the EFS data source, it will take about 46 minutes to copy the COCO 2017 dataset from your S3 bucket to your EFS file system. You only need to copy this data once. During training, data will be input from the shared EFS file system mounted on all training instances via the network interface.
-
For Amazon FSx, it will take about 10 minutes to create a new Amazon FSx Lustre and import the COCO 2017 dataset from your S3 bucket into the new Amazon FSx Lustre file system. You only need to do this once. During training, data will be input from the shared Amazon FSx Lustre file system mounted on all training instances via the network interface.
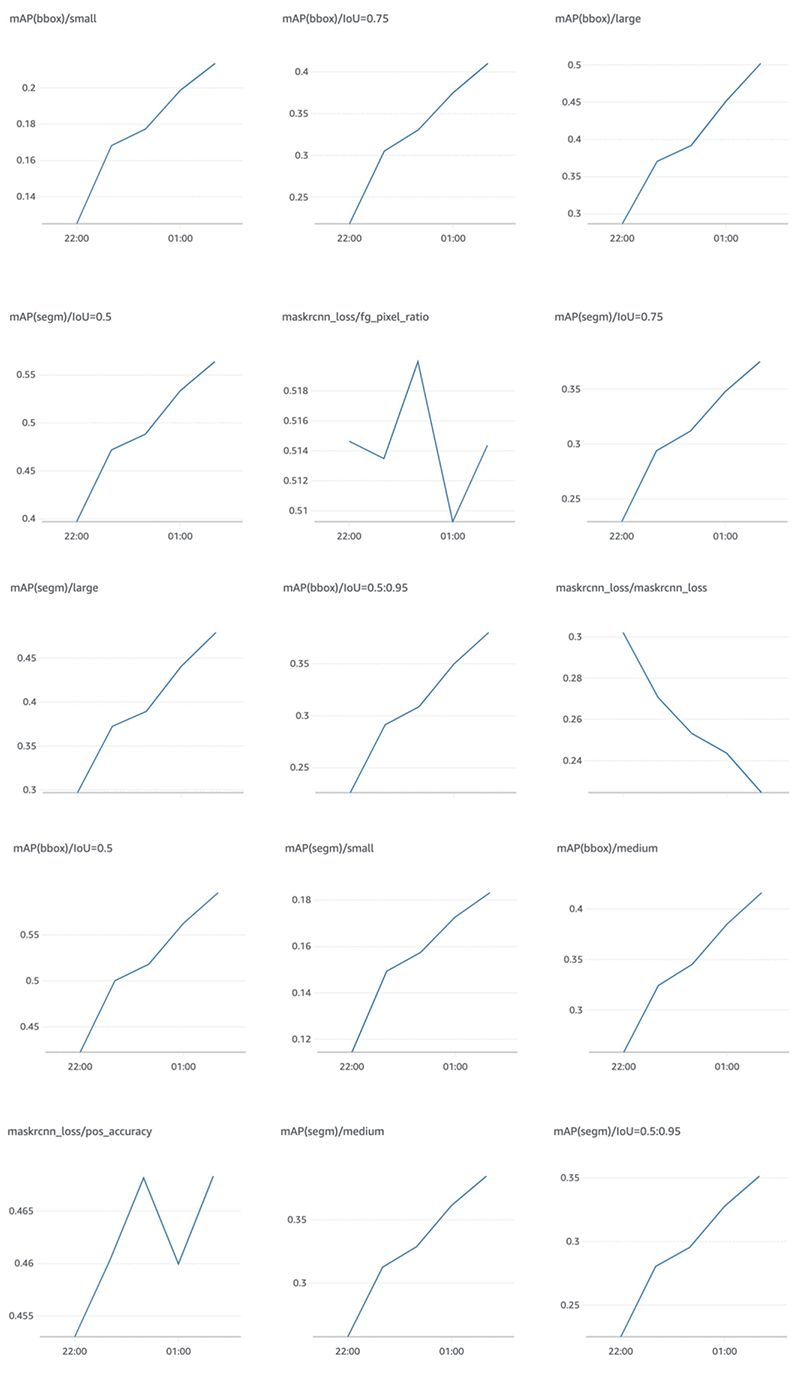
Training Results
-
Mean Average Precision (mAP) plots for target box predictions at various Intersection over Union (IoU) thresholds, as well as for small, medium, and large object sizes
-
Mean Average Precision (mAP) plots for object instance segmentation (segm) predictions at various Intersection over Union (IoU) thresholds, as well as for small, medium, and large object sizes
-
Other metrics related to training loss or label accuracy
Conclusion
Ajay Vohra is a Chief Solutions Architect specializing in developing perception machine learning for autonomous vehicle development. Before joining Amazon, Ajay worked in a local data center on large-scale parallel grid computing for financial risk modeling and automation of application platform engineering.
Amazon SageMaker 1000 YuanGift Package
Now, enterprise developers can receive a service deduction voucher worth 1000 Yuan for free, easily getting started with Amazon SageMaker, in addition to the content covered in this article, there are more application examples waiting for you to experience.
Click to read the original text or scan the QR code, and get it immediately.
