
Follow the public account “ML_NLP“
Set as “Starred“, heavy content delivered in real-time!

Reprinted from | DataFunTalk
Welfare at the end of the article! We will randomly select 10 lucky fans to each receive a copy of the latest work from Harbin Institute of Technology SCIR Laboratory“Natural Language Processing: Methods Based on Pre-trained Models (Full Color)”!
Natural language processing faces eight challenges: the abstractness, combinatorial nature, ambiguity, evolution, non-standardization, subjectivity, knowledge dependency, and difficulty in transplantation of language.
These challenges lead to the complexity of natural language processing tasks.
However, despite the diversity of natural language processing tasks, they can be classified into three common categories: language modeling, foundational tasks, and application tasks.
This article will introduce each of them!
Language Model (Language Model, LM) (also known as statistical language model) is a model that describes the probability distribution of natural language, and it is a very basic and important natural language processing task.
Using a language model, one can compute the probability of a sequence of words or a sentence, and also estimate the probability distribution of the next word given the context. At the same time, the language model is a natural pre-training task, playing a very important role in natural language processing methods based on pre-trained models, hence this pre-trained model is sometimes referred to as a pre-trained language model.
Here we will mainly introduce the classic N-gram language model.
The basic task of a language model is to estimate the conditional probability of the next word given a sequence of words.
Generally, we refer to the previous words as the history.
For example, for the history “I like”, we want to obtain the probability of the next word being “reading”, that is:

Given a corpus, this conditional probability can be understood as how many times the next word is “reading” when “I like” appears in the corpus, and then calculated through maximum likelihood estimation:
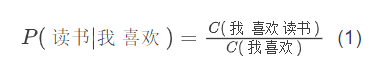
Where, n represents the number of occurrences of the corresponding sequence in the corpus (also known as frequency).
Using the above conditional probability, we can further calculate the probability of a sentence occurring, that is, the joint probability of the corresponding sequence of words P(w_1, w_2,…, w_n), where n is the length of the sequence.
We can use the chain rule to decompose this expression, thus transforming it into a problem of calculating conditional probabilities, that is:
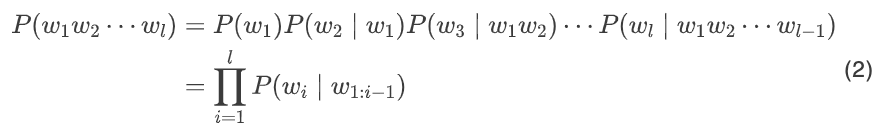
Where, w_i represents the substring from position i to j.
However, as the length of the sentence increases, the number of occurrences of w_i becomes scarcer, even never appearing, so P(w_i) may very likely be 0, making probability estimation meaningless.
To solve this problem, we can assume that “the probability of the next word only depends on the previous n words”, that is:
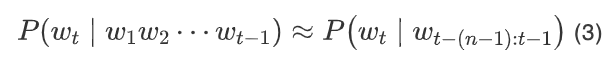
This assumption is known as the Markov assumption. Models that satisfy this assumption are called N-gram models.
Specifically, when n=1, the occurrence of the next word is independent of its history, and the corresponding unigram is usually denoted as unigram. When n=2, the occurrence of the next word only depends on the previous 1 word, and the corresponding bigram is denoted as bigram.
Bigram models are also known as first-order Markov chains.
Similarly, trigram assumption (n=3) is also called second-order Markov assumption, and the corresponding trigram is denoted as trigram. The larger the value of n, the more complete the history considered.
In the unigram model, since the words are independent of each other, it is order-agnostic.
Taking the bigram model as an example, the equation (2) can be transformed into:
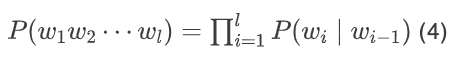
To make P(w_i|w_{i-1}) meaningful, a beginning-of-sentence marker
Note: Some papers also use <s> to indicate the beginning of a sentence, and </s>, <e> to indicate the end of a sentence.
Although the Markov assumption (that the probability of the next word only depends on the previous n words) reduces the likelihood of the sentence probability being 0, when n is relatively large or the test sentence contains out-of-vocabulary words (OOV), the “zero probability” problem still occurs.
Due to data sparsity, training data is often insufficient to cover all possible N-grams in the test data; however, this does not mean that the probabilities of these N-grams are 0.
To avoid this problem, smoothing techniques are needed to adjust the results of probability estimates. Here we will introduce one of the most basic and simplest smoothing algorithms – discounting method.
Discounting smoothing is based on the idea of “giving up some of the excess to compensate for the insufficient”, that is, distributing a portion of the probability from frequently occurring N-grams to low-frequency (including zero-frequency) N-grams, thereby making the overall probability distribution more uniform.
Add-one smoothing (Laplace Smoothing) is a typical discounting method, which assumes that the frequency of all N-grams is one more than the actual occurrence frequency.
For example, for the unigram model, the smoothed probability can be calculated as follows:
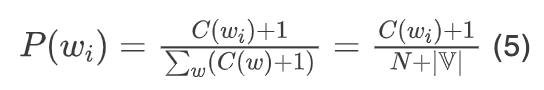
Where, V is the vocabulary size. All out-of-vocabulary words can be mapped to a unique token that is different from other known words, such as
Correspondingly, for the bigram model, we have:
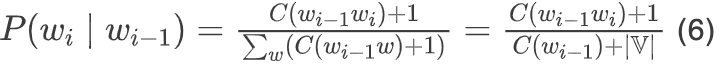
In practical applications, especially when the training data is small, add-one smoothing will give too high probability estimates for low-frequency or zero-frequency events. A natural extension is add-k smoothing. In add-k smoothing, it is assumed that the frequency of all events is more than the actual occurrence frequency by k, where k is a hyperparameter.
For the bigram language model, the conditional probability after using add-k smoothing is:
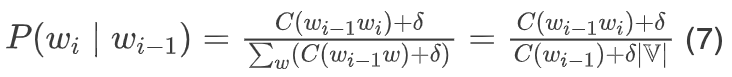
Regarding the hyperparameter k, it needs to be evaluated using development set data. The perplexity of the language model under different k values is evaluated on the development set, and the optimal k is used for the test set.
Due to the introduction of the Markov assumption, N-gram language models cannot model long-distance dependencies that exceed n in length. If n is increased, it will lead to more serious data sparsity issues while dramatically increasing the model’s parameter count (the number of N-grams), posing significant challenges for storage and computation. Neural network language models can effectively address these shortcomings of N-gram language models.
How to measure the quality of a language model?
One method is to apply it to specific external tasks (such as machine translation) and evaluate the language model based on the performance metrics of that task.
This method is also known as “external task evaluation”, which is the closest evaluation method to actual application needs.
However, this approach is computationally expensive and difficult to implement. Therefore, the most commonly used method currently is the “internal evaluation” based on perplexity (PPL).
To conduct internal evaluation, the data is first divided into two disjoint sets, referred to as the training set and the testing set, where the training set is used to estimate the parameters of the language model. The probability calculated by this model on the testing set reflects the model’s generalization ability on the testing set.
Note: When the model is complex (for example, using smoothing techniques), repeatedly evaluating and adjusting hyperparameters on the testing set may lead to overfitting to some extent. Therefore, in standard experimental setups, an additional set is needed for necessary tuning during the training process. This set is usually referred to as the development set (or validation set).
Assuming the testing set T (with beginning and end distribution markers

Perplexity is the inverse of the geometric mean of the probabilities assigned by the model to each word in the testing set:
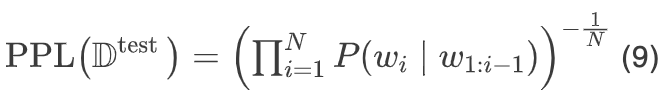
For example, for the bigram model:

In practical calculations, considering that multiplying multiple probabilities may lead to floating-point underflow, it is usually necessary to convert the expression into a form of sums of logarithms:
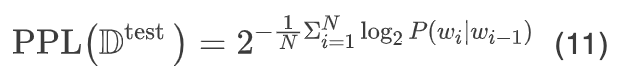
The lower the perplexity, the greater the probability of the word sequence, which means that the model can better explain the data in the testing set.
It is important to note that a language model with lower perplexity does not always achieve better performance metrics on external tasks, but there is usually a positive correlation between the two.
Therefore, perplexity can serve as a quick evaluation metric for language model performance, while its application to downstream tasks still requires evaluation based on its performance in specific tasks.
A major characteristic of natural language processing is the variety of tasks and the various ways to classify them.
From the perspective of processing order, they can be divided into lower-level foundational tasks and higher-level application tasks.
Foundational tasks are often defined by linguists based on introspection, and the results output are often used as a link in the overall system or additional linguistic features for downstream tasks, rather than being aimed at the general public.
This article will introduce several common foundational tasks, including lexical analysis (word segmentation, part-of-speech tagging), syntactic analysis, and semantic analysis.
A word is the smallest unit of sound and meaning that can be used independently, capable of expressing semantic or pragmatic content.
In Indo-European languages, represented by English, words are usually distinguished by delimiters (spaces, etc.). However, in Sino-Tibetan languages represented by Chinese, as well as in Semito-Hamitic languages represented by Arabic, there are no obvious delimiters between words.
Therefore, to perform subsequent natural language processing, it is usually necessary to first perform word segmentation on languages without delimiters. This section will take Chinese word segmentation as an example to introduce the issue of word cutting and the simplest word segmentation algorithm.
Chinese word segmentation is to divide a string of continuous characters into a sequence of words, such as “I like reading”, resulting in “I like reading” after segmentation. The simplest word segmentation algorithm is called the Forward Maximum Matching (FMM) algorithm, which scans the string in the sentence from front to back, trying to find the longest word in the dictionary as the result of segmentation. The specific code is as follows:
def fmm_word_seg(sentence, lexicon, max_len):
"""sentence: the sentence to be segmented
lexicon: dictionary (all words collection)
max_len: length of the longest word in the dictionary"""
begin = 0
end = min(begin + max_len, len(sentence))
words = []
while begin < end:
word = sentence[begin:end]
if word in lexicon or end - begin == 1:
words.append(word)
begin = end
end = min(begin + max_len, len(sentence))
else:
end -= 1
return wordsLoad the dictionary and call the forward maximum matching word segmentation algorithm with the following code:
def load_dict():
f = open("lexicon.txt") # Dictionary file, each line stores a word
lexicon = set()
max_len = 0
for line in f:
word = line.strip()
lexicon.add(word)
if len(word) > max_len:
max_len = len(word)
f.close()
return lexicon, max_len
lexicon, max_len = load_dict()
words = fmm_word_seg(input("Please enter a sentence:"), lexicon, max_len)
for word in words:
print(word,)The forward maximum matching word segmentation algorithm has a significant drawback of tending to segment longer words, which can easily lead to incorrect segmentation results, such as “researching the origin of life”. Since “research student” is a word in the dictionary, the segmentation result using the forward maximum matching algorithm would be “research student life origin”, which is clearly incorrect.
This situation is generally referred to as the segmentation ambiguity problem, where the same sentence may have multiple segmentation results. Once segmentation is incorrect, it will affect the understanding of the sentence’s meaning. The forward maximum matching word segmentation algorithm not only has segmentation ambiguity but also lacks clear definitions of Chinese words, such as “Harbin City” can be considered one word, or “Harbin” as one word and “City” as another word. Therefore, there are currently multiple standards for Chinese word segmentation, and different datasets are annotated according to different standards.
Additionally, there is the out-of-vocabulary issue, meaning that some words are not included in the dictionary, such as new words, named entities, domain-specific words, and misspelled words. Due to the dynamic nature of language, new words emerge continuously, making it impossible to include all words in the dictionary in a timely manner. Therefore, a good word segmentation system must be able to handle the out-of-vocabulary issue well.
Compared to the segmentation ambiguity problem, the proportion of segmentation errors caused by the out-of-vocabulary problem is higher in real application environments.
Therefore, the word segmentation task itself is also a challenging foundational task in natural language processing, which can be solved using various machine learning methods. Detailed introductions can be found in the book “Natural Language Processing: Methods Based on Pre-trained Models (Full Color)”.
It is generally believed that languages represented by Indo-European languages, such as English, typically have delimiters (spaces, etc.) between words and do not require additional word segmentation processing.
However, due to the complex morphological variations of these languages, simply using natural delimiters for segmentation can lead to data sparsity issues and reduce processing speed due to a large vocabulary. For example, “computer”, “computers”, “computing” are considered completely different words even though they are semantically similar.
The traditional approach is to introduce lemmatization or stemming tasks based on linguistic rules to extract the root of the words, thereby mitigating data sparsity to some extent.
Lemmatization refers to converting inflected words to their base form, such as reducing “computing” to “compute”; while stemming involves removing prefixes, suffixes, etc., keeping the stem, such as the stem of “computing” being “comput”. It can be seen that the result of stemming may not be a complete word.
Although lemmatization or stemming alleviates data sparsity to some extent, it requires a large number of manually written rules, making this rule-based approach not easily extendable to new domains or new languages.
Therefore, unsupervised subword segmentation based on statistics has emerged and is used in modern pre-trained models.
Subword segmentation refers to dividing a word into several continuous segments. There are currently various commonly used subword segmentation algorithms, which have similar methods, and the basic principle is to use the longest and most frequent subwords to segment words.
This section will focus on the commonly used Byte Pair Encoding (BPE) algorithm.
First, BPE constructs a subword vocabulary using Algorithm 2.1.

Next, an example will illustrate how to construct the subword vocabulary.
Assume that the corpus contains the following three words in the Python dictionary and the corresponding frequencies for each word. Each word ends with a “</w>” character, and each word is segmented into individual characters to form subwords.
{'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}The initial subword vocabulary includes all characters contained in the three words:
{'l', 'o', 'w', 'e', 'r', '</w>', 'n', 's', 't', 'i', 'd'}Then, the frequency of adjacent subwords within a word is counted, and the most frequent subword pair ‘e’ and ‘s’ is merged into a new subword ‘es’ (which appears 9 times), and then added to the subword vocabulary, while the subword ‘s’ that no longer exists in the corpus is deleted from the subword vocabulary. At this point, the corpus and subword vocabulary become:
{'l o w e r </w>': 2, 'n e w es t </w>': 6, 'w i d es t </w>': 3}{'l', 'o', 'w', 'e', 'r', '</w>', 'n', 't', 'i', 'd', 'es'}Next, merge the next subword pair ‘es’ and ‘t’, resulting in the new corpus and subword vocabulary:
{'l o w e r </w>': 2, 'n e w est </w>': 6, 'w i d est </w>': 3}{'l', 'o', 'w', 'e', 'r', '</w>', 'n', 'i', 'd', 'est'}Repeat the above process until the subword vocabulary size reaches a desired vocabulary size.
Once the subword vocabulary is constructed, how to segment a word into a sequence of subwords? A greedy method can be used, which involves sorting the subword vocabulary by the length of the subwords from longest to shortest. Then, traverse the subword vocabulary from front to back, checking if a subword is a substring of the word. If so, segment the word and continue traversing the subword vocabulary. If the entire subword vocabulary is traversed and there are still substrings in the word that have not been segmented, these substrings must be low-frequency segments, and they are replaced with a uniform marker, such as ‘
For example, for a sentence containing three words [‘the</w>’, ‘highest</w>’, ‘mountain </w>’], assuming the sorted vocabulary is [‘errrr</w>’, ‘tain</w>’, ‘moun’, ‘est</w>’, ‘high’, ‘the</w>’, ‘a</w>’], the subword segmentation result would be [‘the</w>’, ‘high’, ‘est</w>’, ‘moun’, ‘tain</w>’]. This process is also referred to as encoding a sentence (sequence of words).
Now, how to decode an encoded sentence back to its original form? At this point, the end character ‘</w>’ plays a role. By concatenating all subwords and replacing the ending character with a space, we can restore the original sentence.
From the above process, it can be seen that the encoding step in the BPE algorithm requires traversing the entire vocabulary, which is a very time-consuming process. Caching techniques can be used to speed up the encoding process by pre-storing the encoding results of common words, allowing for quick retrieval during encoding. For words that cannot be found, the actual encoding algorithm is executed. Since high-frequency words cover most words in the language, this method does not execute the encoding algorithm many times, thus significantly speeding up the encoding process.
In addition to BPE, there are many other similar subword segmentation methods, such as WordPiece, Unigram Language Model (ULM) algorithm, etc. WordPiece is similar to BPE, as it also merges two subwords from the subword vocabulary each time. The main difference from BPE is that the strategy for selecting two subwords to merge is different: BPE merges the most frequent adjacent subwords, while WordPiece merges the adjacent subwords that maximize the probability of the language model. Through formula derivation, the adjacent subwords that maximize the language model probability have the highest mutual information value, meaning that the two subwords have a strong correlation in the language model and often appear together in the corpus.
Similar to WordPiece, ULM also uses language models to select subwords. The difference is that BPE and WordPiece algorithms have vocabulary sizes that change from small to large, which is an incremental method. In contrast, ULM is a decremental method, which starts with a large vocabulary and continuously discards subwords from the vocabulary according to evaluation criteria until certain conditions are met. The ULM algorithm considers different possible segmentations of sentences, thus capable of outputting multiple subword segments with probabilities.
To make it easier to use the above subword segmentation algorithms, Google has released the SentencePiece open-source toolkit, which integrates BPE, ULM, and other subword segmentation algorithms, supporting calls in Python and C++ programming languages, with the advantages of being fast and lightweight. Additionally, by treating sentences as sequences of Unicode encoding, it can handle multiple languages.
Part of Speech refers to the grammatical role a word plays in a sentence, also known as word class (Part-Of-Speech, POS). For example, words that represent the names of abstract or concrete things (such as “computer”) are classified as nouns, while words that represent actions (such as “hit”) or states (such as “exist”) are classified as verbs. Part-of-speech can assist in syntactic analysis and semantic understanding.
Part-of-Speech Tagging (POS Tagging) task refers to outputting the corresponding part of speech for each word in a given sentence. For example, when the input sentence is:
他 喜欢 下 象棋 。The output of part-of-speech tagging would be:
他/PN 喜欢/VV 下/VV 象棋/NN 。/PUHere, the abbreviations PN, VV, NN, and PU after the slash represent pronouns, verbs, nouns, and punctuation marks, respectively.
① The definitions of parts of speech and their representations may vary according to different tagging standards; this book mainly uses the Chinese Penn Treebank POS tagging standard as an example.
The main difficulty in part-of-speech tagging lies in ambiguity, where a word can have different parts of speech in different contexts. For example, in the above example, “下” can represent both a verb and an adverb. Therefore, it is necessary to determine the specific part of speech of a word in the sentence based on the context.
Syntactic Parsing (Syntactic Parsing) aims to analyze the syntactic component information of a given sentence, such as subject, predicate, object, modifiers, etc. The ultimate goal is to convert the sentence represented by the sequence of words into a tree structure, which helps to understand the meaning of the sentence more accurately and assists downstream natural language processing tasks. For example, for the following two sentences:
您转的这篇文章很无知。
您转这篇文章很无知。
Although they differ by only one character, they express completely different meanings, mainly because the subjects of the two sentences are different. In the first sentence, the subject is “article”, while in the second sentence, the subject is the action of “transferring”. By performing syntactic parsing on both sentences, we can accurately identify their respective subjects, thereby deducing different meanings.
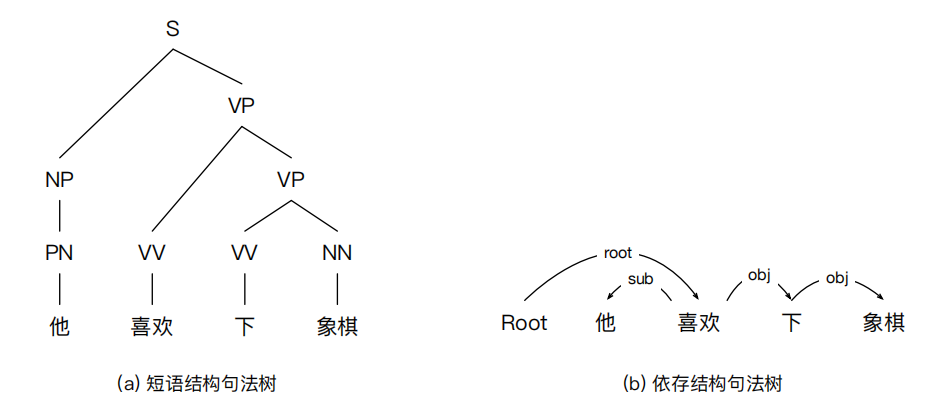
Typical syntactic structure representation methods include two types—phrase structure syntax representation and dependency structure syntax representation. The difference lies in the grammatical rules on which they are based. Phrase structure syntax representation relies on context-free grammars and is a hierarchical representation method, while dependency structure syntax representation relies on dependency grammars.
Figure 2-2 compares the two syntactic structure representation methods. In the phrase structure representation, S represents the start symbol, NP and VP represent noun phrases and verb phrases, respectively. In the dependency structure representation, sub and obj represent the subject and object, respectively, while root represents a virtual root node that points to the core predicate of the entire sentence.
The core task of natural language processing is to enable computers to “understand” the meaning contained in natural language, that is, semantics (Semantic). The text vector representation introduced earlier in this chapter can be considered to implicitly contain a lot of semantic information. The general meaning of semantic analysis refers to explicitly representing semantics through discrete symbols and structures. Depending on the granularity of the language units to be represented and the methods of semantic representation, semantic analysis can be divided into various forms.
From the perspective of word granularity, a word may have multiple meanings (word senses); for example, “打” can mean “attack” (as in “打人”), “play” (as in “打篮球”), or even “knit” (as in “打毛衣”).
The natural language processing task of determining the specific meaning of a word based on its different contexts is called Word Sense Disambiguation (WSD). The possible meanings of each word are often determined through semantic dictionaries, such as WordNet, etc. In addition to the above case of polysemy, there is also the case of synonymy, where multiple words have the same meaning, such as “马铃薯” and “土豆”.
Due to the compositionality and evolution of language semantics, it is difficult to define the semantics of sentences, paragraphs, or texts using dictionaries, making it challenging to represent the semantics of language units uniformly. Various linguistic schools have proposed different semantic representation forms, such as Semantic Role Labeling (SRL) and Semantic Dependency Parsing (SDP).
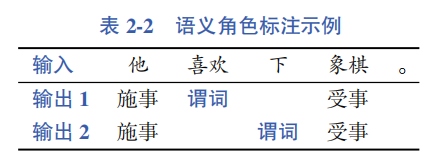
Semantic Role Labeling, also known as predicate-argument structure, first identifies the possible predicates in a sentence (usually verbs), and then determines the semantic roles (also called arguments) carried by each predicate, such as the agent representing the doer of the action and the patient representing the receiver of the action. In addition to core semantic roles, there is a class of auxiliary language components that describe actions, referred to as adjunct semantic roles, such as the time, place, and manner of action occurrence. Table 2-2 shows an example of semantic role labeling, where there are two predicates—”like” and “下”, and the corresponding argument outputs for each predicate.
Semantic dependency analysis utilizes a general graph to represent richer semantic information. Depending on the types of nodes in the graph, it can be divided into two representations—Semantic Dependency Graph representation and Conceptual Graph representation. In the semantic dependency graph, the nodes are the actual words in the sentence, and semantic relations are created between words. In the conceptual graph, the sentence is first transformed into virtual concept nodes, and then semantic relations are created between concept nodes. Figure 2-3 shows an example of a semantic dependency graph analysis result.
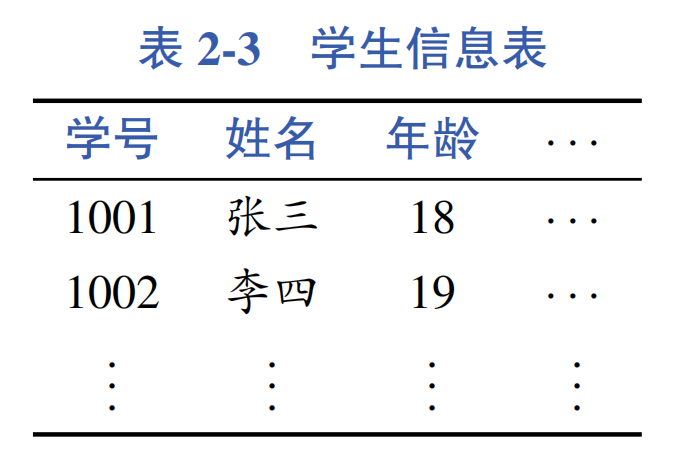
The above semantic representation methods belong to general semantic representation methods, which are designed to provide a uniform semantic representation for various linguistic phenomena. In addition, there is another type of semantic analysis that deals specifically with concrete tasks, such as converting natural language representations of database queries into structured query language (SQL). For example, for the student information table shown in Table 2-3, the system needs to convert the user’s natural language query: “the names of students older than 18 years” into SQL statement: “select name where age > 18;”.
This article introduces natural language processing application tasks such as information extraction, sentiment analysis, question answering systems, machine translation, and dialogue systems.
These tasks can directly or indirectly provide services to end users in product form, representing the main technologies for the practical application of natural language processing research.
Information Extraction (IE) is the process of automatically extracting structured information from unstructured text, which facilitates subsequent processing by computers. Moreover, the extracted results can also be added as new knowledge to knowledge bases. Information extraction generally includes the following sub-tasks.
Named Entity Recognition (NER) is the task of extracting each mentioned named entity from the text and labeling its type, generally including person names, place names, organization names, etc., as well as proper names such as book titles, movie names, and drug names. After finding the mentioned named entities in the text, it is often necessary to link these named entities to specific entities in knowledge bases or knowledge graphs, a process known as Entity Linking.
For example, “Washington” can refer to both the first president of the United States and the capital of the United States, requiring context to determine which is meant, a process similar to word sense disambiguation.
Relation Extraction (Relation Extraction) is used to identify and classify the semantic relationships between entities mentioned in the text, such as relationships between spouses, children, workplaces, and geographical locations.
Event Extraction (Event Extraction) aims to identify events of interest from the text, along with key elements such as time, place, and people involved. Events are often defined by specific trigger words mentioned in the text. Thus, event extraction is quite similar to the semantic role labeling task, where the trigger words correspond to the predicates in semantic role labeling, and the event elements can be considered as the arguments in semantic role labeling.
The occurrence time of events is often crucial, and thus Temporal Expression recognition (Temporal Expression) is also considered an important sub-task of information extraction, generally including two types of time: absolute time (dates, days of the week, months, and holidays) and relative time (such as tomorrow, two years ago, etc.). Temporal expression normalization maps these temporal expressions to specific dates or times within a day.
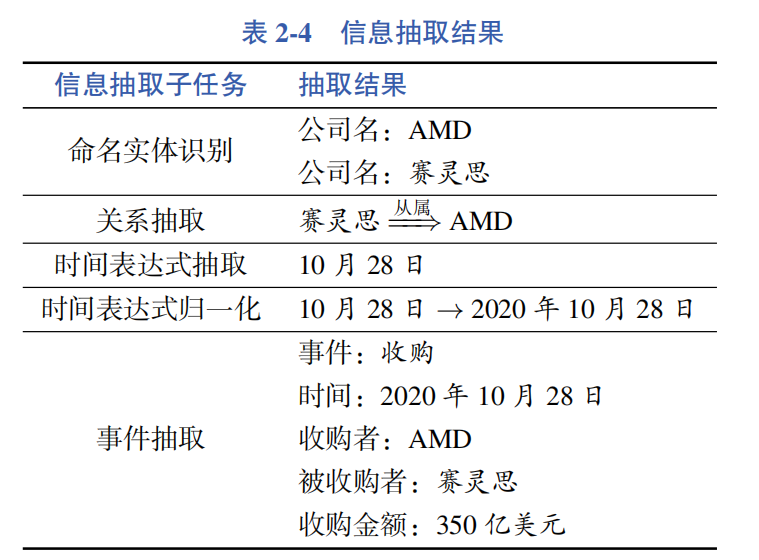
Below is an example that comprehensively demonstrates the various sub-tasks of information extraction. Consider the following news report:
On October 28, AMD announced a $35 billion acquisition of FPGA chip giant Xilinx. The two chip companies that had been rumored for years finally came together.
The information extraction results are shown in Table 2-4.
Sentiment (Sentiment) is an important cognitive ability of humans, and using computers to automatically perceive and process human emotions has become an important research topic in the field of artificial intelligence. Sentiment analysis in natural language processing mainly studies the emotions expressed by humans through text, thus also referred to as text sentiment analysis.
However, sentiment is a relatively vague concept, including both individual attitudes, opinions, or tendencies towards external things, such as positive, negative, etc.; and can also refer to a person’s emotions (Emotion), such as happiness, anger, sadness, and fear. With the rapid development of the Internet, various user-generated content (User Generated Content, UGC) has emerged, many of which contain people’s emotions. Accurately analyzing these emotions helps to understand people’s preferences for certain products and keep track of the development of public sentiment. Therefore, sentiment analysis has become one of the main applications of natural language processing technology.
Sentiment analysis can be divided into two main sub-tasks from a task perspective: sentiment classification (identifying the types or intensities of sentiment contained in the text, where the text can be a sentence or a passage) and sentiment information extraction (extracting sentiment elements from the text, such as evaluation words, evaluation objects, and evaluation collocations). For the following user review:
This phone has a great screen and decent performance.
The sentiment analysis results are shown in Table 2-5.

Due to the numerous application scenarios of sentiment analysis, such as analyzing product reviews and public sentiment analysis, sentiment analysis has received widespread attention from the industry and has become an important manifestation of the practical application of natural language processing research. Furthermore, sentiment analysis has shown significant research significance and broad application prospects in fields such as sociology, economics, and management, which continuously raise higher demands on sentiment analysis, driving the expansion and deepening of sentiment analysis research.
Question Answering System (Question Answering, QA) refers to a system that accepts questions described by users in natural language and retrieves answers from heterogeneous data using techniques such as retrieval, matching, and reasoning. Depending on the source of data, question answering systems can be divided into four main types:
1) Retrieval-based question answering systems, where answers are sourced from fixed text corpora or the Internet, with systems finding relevant documents and extracting answers;
2) Knowledge base question answering systems, where the knowledge required to answer questions is stored in structured forms such as databases, and the question answering system first parses the question into a structured query statement, retrieves relevant knowledge points, and combines knowledge reasoning to obtain answers;
3) Frequently Asked Questions (FAQ) question answering systems, which answer user questions by searching through a repository of accumulated frequently asked questions;
4) Reading comprehension question answering systems, which answer user questions by extracting text segments from given documents or generating an answer. In practice, various types of question answering systems can be combined to better answer user questions.
Machine Translation (Machine Translation, MT) refers to the automatic translation from one natural language (source language) to another natural language (target language) using computers.
According to statistics, there are approximately 7,000 languages in the world, of which over 300 languages have more than one million speakers.
With the trend of globalization and the widespread popularity of the Internet, communication between speakers of different languages has become increasingly important. Overcoming language barriers between different countries and ethnicities has become a common challenge faced by humanity.
Machine translation provides an effective technological means to overcome this challenge, aiming to establish automatic translation methods, models, and systems that break down language barriers, ultimately achieving automatic translation between any time, any place, and any language, fulfilling the dream of seamless communication.
Since the inception of natural language processing, machine translation has been one of its main research tasks and application scenarios.
In recent years, companies like Google and Baidu have launched online machine translation services, and companies like iFlytek have also released translation devices that can directly translate the speech of one language into the speech of another language, facilitating communication between people who speak different languages.
Below is an example of Chinese-English translation, where both the source language (Chinese) and the target language (English) have undergone word segmentation:
S: 北京 是 中国 的 首都 。
T: Beijing is the capital of China .
Machine translation methods generally take sentences as the basic input unit, studying the mapping function from source language sentences to target language sentences.
Since its inception, machine translation has mainly revolved around two methods: rationalism and empiricism.
Rationalism refers to rule-based methods, while empiricism refers to data-driven statistical methods, represented in the field of machine translation by research methods based on corpora (translation instance libraries).
Recent deep learning-based machine translation methods utilize deep neural networks to learn implicit translation rules from source language sentences to target language sentences, meaning all translation rules are encoded in the model parameters of the neural network. This method is also known as Neural Machine Translation (NMT).
Dialogue System (Dialogue System) refers to an intelligent system in which users and computers achieve specific goals through multi-turn interactions in natural language.
These specific goals include completing specific tasks, obtaining information or recommendations, providing emotional comfort, and social companionship, among others.
In the 1950s, Turing proposed the “Turing Test” to assess the intelligence level of computer systems, which is conducted in the form of natural language dialogue.
Dialogue systems can be directly applied in various scenarios such as voice assistants, smart speakers, and in-car voice systems.
Dialogue systems are mainly divided into Task-Oriented Dialogue Systems and Open-Domain Dialogue Systems.
The former is task-oriented dialogue systems, mainly used for automated business assistants in vertical fields, with clear task objectives, such as completing flight bookings or weather inquiries.
The latter is social-oriented dialogue systems, usually targeting casual conversation and emotional support, thus also referred to as chat systems or chatbots, exhibiting strong openness in terms of domains and topics.
Below is an example of a human-computer dialogue from an open-domain dialogue system, where U represents the user’s utterance, and S represents the response of the dialogue system. The main goal of such dialogue systems is to enhance the number of dialogue turns and user satisfaction. Compared to the accuracy of dialogue, open-domain dialogue systems focus more on the diversity of dialogues and their attractiveness to users.
U: The weather is really nice today!
S: Yes, it’s very suitable for outdoor sports.
U: What sports do you like?
S: I like playing football, how about you?
Task-oriented dialogue systems generally consist of three modules executed sequentially, namely natural language understanding, dialogue management, and natural language generation.
Among them, the Natural Language Understanding (NLU) module’s main function is to analyze the semantics of the user’s utterance, typically represented by the domain, intent, and corresponding slot values of that utterance. For the user’s utterance:
U: Help me book a flight to Beijing tomorrow.
The natural language understanding result is shown in Table 2-6.

Dialogue Management (Dialogue Management, DM) module includes Dialogue State Tracking (DST) and Dialogue Policy Optimization (DPO) as two sub-modules.
The dialogue state is generally represented as a list of semantic slots and values. For example, by tracking the dialogue state based on the natural language understanding results of the above user utterance, we obtain the current dialogue state (usually a list of semantic slots and their corresponding values): [Destination = Beijing; Departure Time = Tomorrow; Departure Location = NULL; Quantity = 1].
After obtaining the current dialogue state, a strategy optimization is performed to select the next strategy, also referred to as an action. There are many types of actions, such as asking about the departure location or the type of cabin.
In task-oriented dialogue systems, the natural language generation (NLG) module works relatively simply, usually implemented through writing templates. For example, to inquire about the departure location, one can directly ask, “Where are you departing from?” and then provide feedback to the user through speech synthesis (Text-to-Speech, TTS).
These three modules can continuously execute in a loop, with the dialogue state changing according to each user’s utterance. Then, different response strategies are adopted until the user’s booking needs are met.
This article is excerpted from “Natural Language Processing: Methods Based on Pre-trained Models (Full Color)”. To learn more about pre-trained models, this book is highly recommended!


▊《Natural Language Processing: Methods Based on Pre-trained Models (Full Color)》
Che Wanxiang, Guo Jiang, Cui Yiming Authors
-
Several scholars from Harbin Institute of Technology SCIR have contributed greatly
-
Revealing the source of the “magic” of pre-trained language models in natural language processing
-
Detailed explanation of the basic knowledge, model design, code implementation, and cutting-edge progress of pre-trained language models
This book introduces new natural language processing technologies based on pre-trained models, building on basic concepts of natural language processing, deep learning, etc. In addition to theoretical knowledge, the book also provides corresponding PyTorch code implementations combined with specific cases, allowing readers to gain a deeper understanding of the theory and quickly implement natural language processing models, achieving a unity of theory and practice.

(JD.com offers 50 off for purchases over 100, hurry and scan the code to grab it!)
Recommended Reading:
Prompt—From CLIP to CoOp, New Paradigm of Visual-Language Model
Focal Loss --- From Intuition to Implementation
CPU vs GPU, Who is the Real Elementary Student?
Click the card below to follow the public account “Machine Learning Algorithms and Natural Language Processing” for more information: