
Click the "Xiaobai Learns Vision" above, select to add "Starred" or "Pinned"
Heavy content, delivered first time

【Introduction】Neural networks have a wide range of applications in the field of computer vision. With slight modifications, the same tools and techniques can be effectively applied to a wide variety of tasks. In this article, we will introduce several applications and methods, including semantic segmentation, classification and localization, object detection, and instance segmentation.
Author | Ravindra Parmar
Translated by | Xiaowen
Detection and Segmentation through ConvNets
——Computer Vision – Object Detection and Segmentation
Neural networks have a wide range of applications in the field of computer vision. With slight modifications, the same tools and techniques can be effectively applied to a wide variety of tasks. In this article, we will introduce several applications and methods. The four most common are:
-
Semantic Segmentation
-
Classification and Localization
-
Object Detection
-
Instance Segmentation
Semantic Segmentation
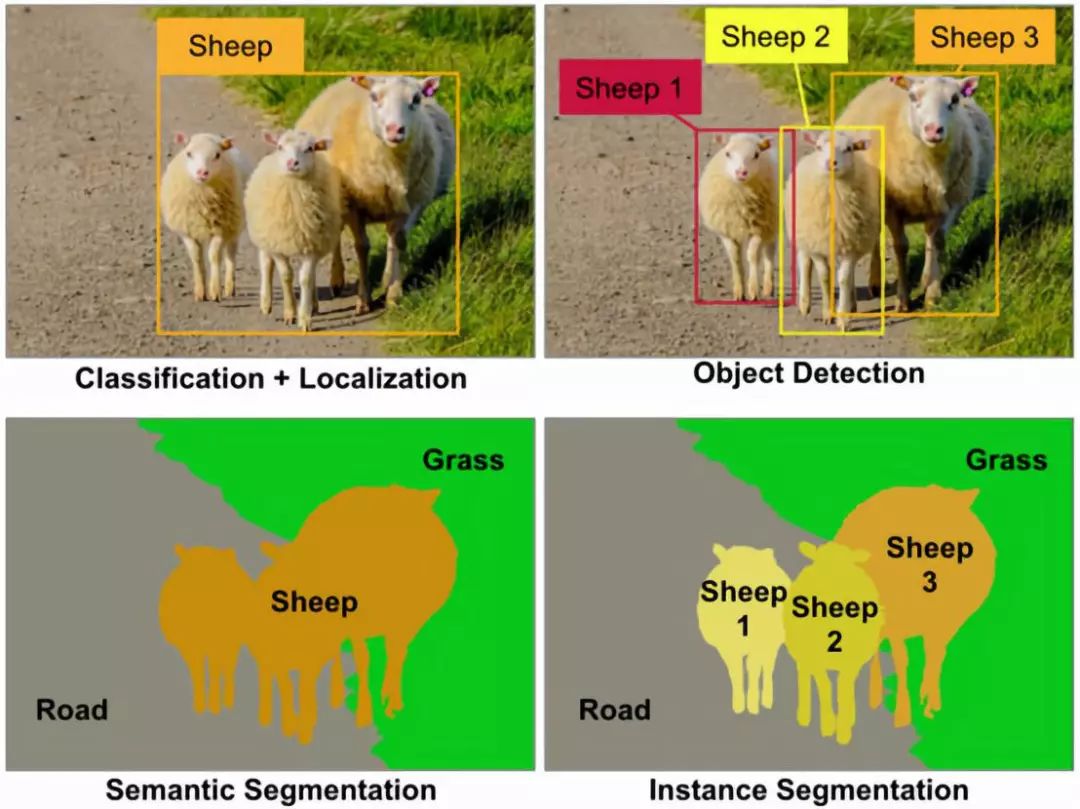
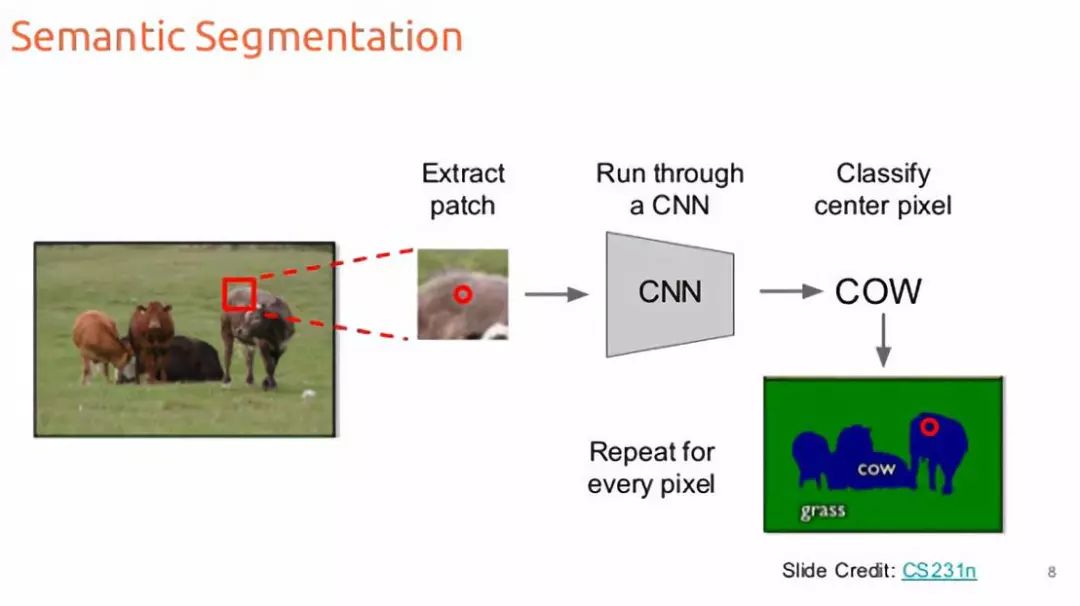
We input an image and output a class decision for each pixel. In other words, we want to classify each pixel into one of several possible categories. This means that all pixels carrying sheep will be classified as one category, and pixels with grass and roads will also be classified. More importantly, the output does not distinguish between two different sheep.
One possible method to solve this problem is to treat it as a sliding window classification problem[1]. We decompose the input image into several crops of the same size. Each crop is then sent to the CNN, and the classification category of that crop is obtained as output. Pixel-level crops will classify each pixel. This is very easy, isn’t it?
Sliding window semantic segmentation
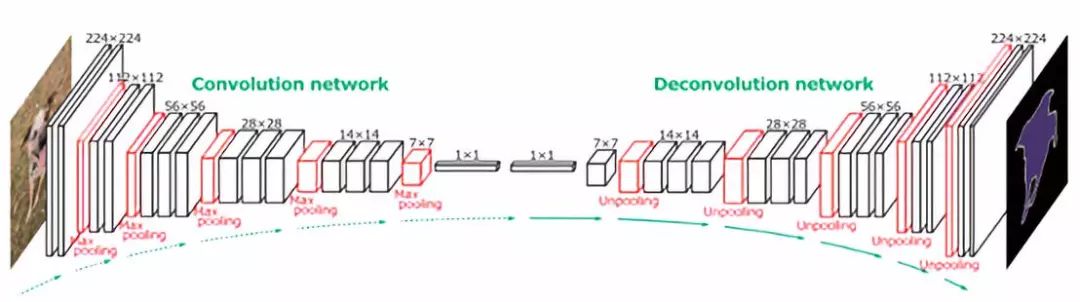
Well, it is even clear without a graduate degree how low the computational efficiency of this method is in practice. What we need is a method that minimizes the number of times the image is passed through as much as possible. Fortunately, there are some techniques that can use all convolutional layers to predict all pixels simultaneously.
Full convolutional layers for semantic segmentation
As you can see, such a network will be a mixture of down-sampling and up-sampling layers to maintain the spatial size of the input image (making predictions at the pixel level). Down-sampling is achieved by using strides or max/avg pooling. On the other hand, up-sampling requires some clever techniques, two of which are – nearest neighbor[2] and transpose convolution[3].
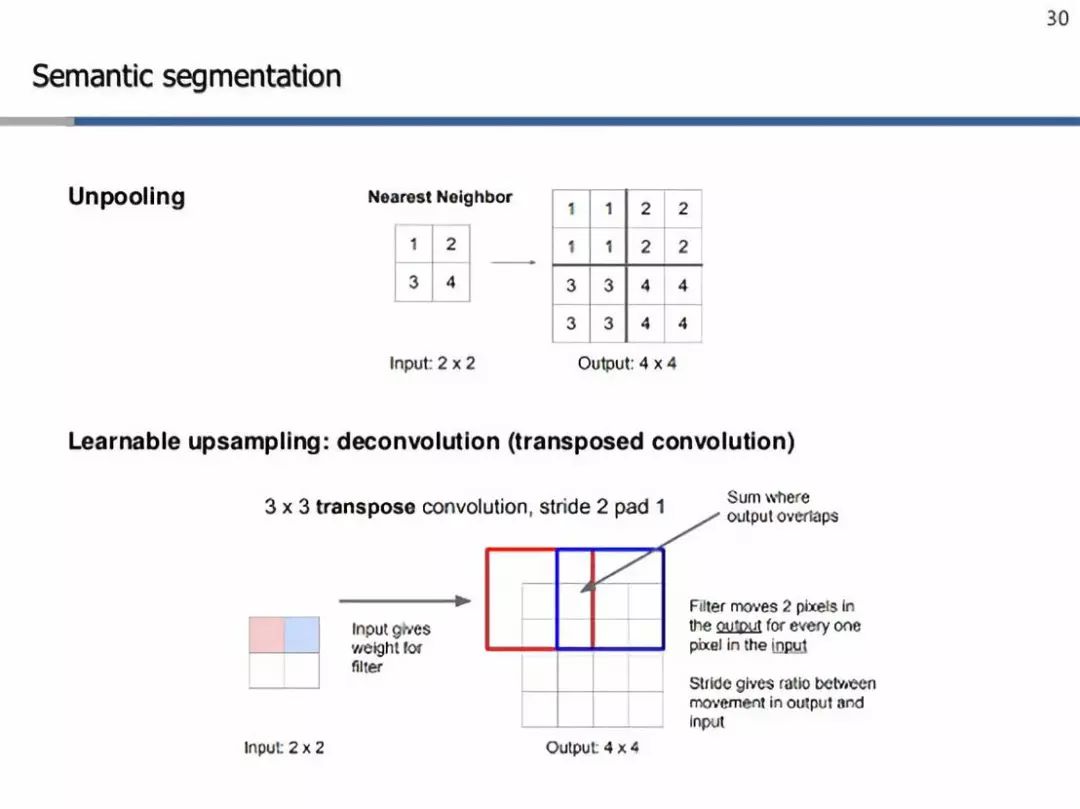
Up-sampling techniques
In short, nearest neighbor simply copies specific elements within its receptive field (in the above example, it is 2×2). On the other hand, transpose convolution attempts to learn appropriate weights to perform up-sampling for the filter. Here, we start with the value from the upper left corner, which is a scalar, multiply it with the filter, and copy these values to the output cells. Then, we proportionally move some specific pixels in the filter relative to one pixel in the input. This is the ratio between the output and input, which will give us the stride we want to use. In the case of overlap, we only summarize the values. Thus, these filters also constitute the learnable parameters of these networks, rather than a set of fixed values like the nearest neighbor. Finally, the entire network is trained using pixel-wise cross-entropy loss[4] for backpropagation[5].
Classification and Localization
Image classification[6] deals with assigning category labels to images. However, sometimes, in addition to predicting the category, we are also interested in the location of the object in the image. From a mathematical standpoint, we might want to draw a bounding box on top of the image. Fortunately, we can reuse all the tools and techniques learned from image classification.

Convolutional networks for classification localization
We first input the image into some huge ConvNet, which will give scores for each category. But now we have another fully connected layer that predicts the bounding box coordinates (x, y coordinates and height and width) of the object from the feature map generated by the previous layers. Therefore, our network will produce two outputs, one corresponding to the image class and the other corresponding to the boundary. To train this network, we must consider two losses: the cross-entropy loss for classification and the L1/L2 loss[7] for boundary prediction (a kind of regression loss).
Generally speaking, this idea of predicting a fixed number of sets can be applied to various computer vision tasks beyond localization, such as human pose estimation.

Human pose estimation
Here, we can define a fixed set of points on the body for human pose, such as joints. We then input our image into the ConvNet and output the same fixed set of points (x, y) coordinates. We can then apply some regression loss at each point to train the network through backpropagation.
Object Detection
The idea of object detection is to start from a fixed set of categories of interest, and whenever any of these categories appear in the input image, we draw a bounding box around the image and predict its class label. The difference from image classification and localization is that in the former sense, we only classify and draw a bounding box for a single object. In the latter case, we cannot know in advance the expected number of objects in the image. Similarly, we can also adopt a brute-force sliding window approach[8] to solve this problem. However, this is again a computationally inefficient problem, and few algorithms can effectively solve it, such as region proposal-based algorithms and YOLO object detection algorithms[9].
Region Proposal-based Algorithms
Given an input image, a region proposal algorithm will give thousands of possible bounding boxes for objects. Of course, there is a possibility of noise in the output boxes when there are no objects. However, if there are any objects in the image, the algorithm will select it as a candidate box.
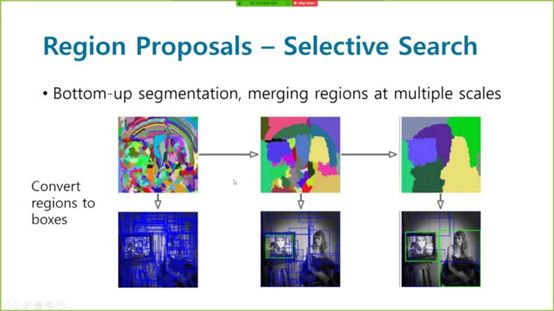
Selective search for region proposals
To make all candidate boxes the same size, we need to deform them to a fixed grid size so that we can finally input them into the network. We can then apply a huge ConvNet to each candidate box output from the region proposal to obtain the final category. Of course, compared to the brute-force sliding window algorithm, its final computational efficiency is much higher. That is the whole idea behind R-CNN. To further reduce complexity, the Fast R-CNN approach is adopted, where the idea of Fast R-CNN is to first pass the input image through ConvNet to obtain a high-resolution feature map, and then impose these region proposals onto this feature map instead of the actual image. This allows us to reuse a large number of costly convolution operations across the entire image when there are a large number of crops.
YOLO (You Only Look Once)
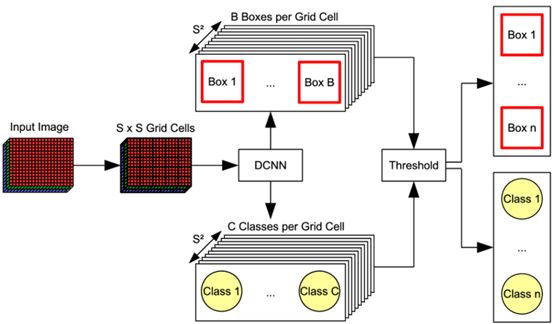
YOLO Object Detection
The idea behind YOLO is not to process each proposed region independently but to reorganize all predictions into a single regression problem, from the image pixels to the bounding box coordinates and classification probabilities.
We first divide the entire input image into an SxS grid, where each grid cell predicts the bounding box (x, y, w, h) along with the conditional class probability (Pr(Class | Object)) with b bounding boxes. The (x, y) coordinates represent the center of the box relative to the grid cell boundaries, while the width and height are predictions relative to the entire image. The probabilities are conditioned on the grid cell containing an object. We only predict a set of class probabilities for each grid cell, regardless of the number of bounding boxes B. The confidence score reflects the model’s confidence that an object is contained within the box, and if there is no object in the box, the confidence must be zero. At the other extreme, the confidence should be equal to the intersection over union (IOU) between the predicted box and the ground truth label.
Confidence score = Pr(Object) * IOU
During testing, we multiply the conditional class probabilities by the individual bounding box confidence predictions, which gives a confidence score for each specific category in the box. These scores encode both the probability of that class appearing in the box and the degree to which the predicted box fits the object.
Pr(Class | Object) ∗ (Pr(Object) ∗ IOU) = Pr(Class) ∗ IOU
Instance Segmentation
Instance segmentation combines techniques from semantic segmentation and object detection. Given an image, we want to predict the location and identity of the objects in the image (similar to object detection), but rather than predicting the bounding boxes of these objects, we predict the entire segmentation mask of these objects, i.e., which pixels in the input image correspond to which object instances. Based on this, we obtain separate segmentation masks for each sheep in the image, while all sheep in semantic segmentation receive the same segmentation mask.
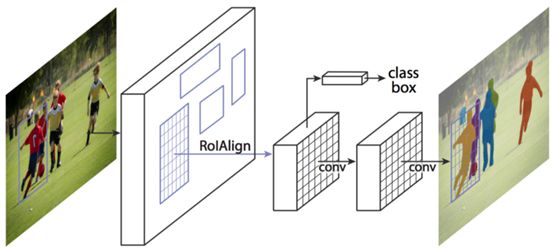
Instance segmentation based on Mask R-CNN
Mask R-CNN is the preferred network for this type of task. In this multi-stage processing task, we pass the input image through a ConvNet and some learning region proposal networks. Once we have these region proposals, we project these proposals onto the convolutional feature map, just as we did in the case of R-CNN. However, now, in addition to performing classification and bounding box predictions, we also predict the segmentation mask for each region proposal.
Good news!
Xiaobai Learns Vision knowledge community
is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of the "Xiaobai Learns Vision" public account to download the first OpenCV extension module tutorial in Chinese on the internet, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than 20 chapters of content.
Download 2: Python Vision Practical Projects 52 Lectures
Reply "Python Vision Practical Projects" in the backend of the "Xiaobai Learns Vision" public account to download 31 visual practical projects, including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help you quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the backend of the "Xiaobai Learns Vision" public account to download 20 practical projects based on OpenCV to advance OpenCV learning.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will be gradually subdivided in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, you will not be approved. Once added successfully, you will be invited into the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise you will be removed from the group. Thank you for your understanding~