🍹 Insight Daily 🪺
Aitrainee | WeChat Official Account: AI Trainee
Hi, this is Aitrainee, welcome to read this new article.
Deepseek R1 has been officially released. This is not the previous Light version, but the complete R1.
Its performance is comparable to o1, and it adopts the MIT open-source license, allowing commercial use. It is now available on the Deepseek chat platform and also provides an API.
The model is available in two versions: the main R1, and the research-oriented R1-Zero.
R1-Zero does not have supervised fine-tuning and uses direct RL, making it a version that has not undergone dialogue preference alignment supervision fine-tuning, specifically provided for researchers or those wishing to fine-tune the model themselves.
The officially released R1 still used the SFT phase.
R1 is a large model with 671B parameters, with only 37B active parameters, trained based on Deepseek V3. It particularly enhances the chain of thought and reasoning abilities.
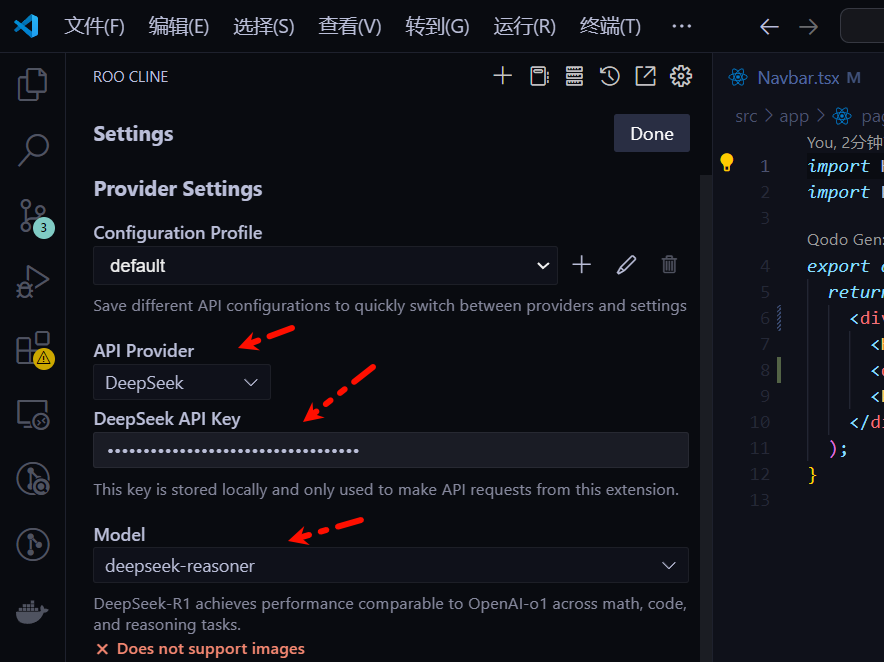
You can now directly use R1 in Cline or Roocline. API access: https://platform.deepseek.com/usage
Set it up in Roocline like this:
What is Roocline? Look here:
The brand new free RooCline surpasses Cline v3.1?! A faster, smarter, and more outstanding Cline fork! (Autonomous AI programming, zero threshold)
As a test, we used a previously written article titled “From 0 to 1, I Created an AI Service Website Without Writing a Line of Code” and threw the initial three-in-one prompt to it:
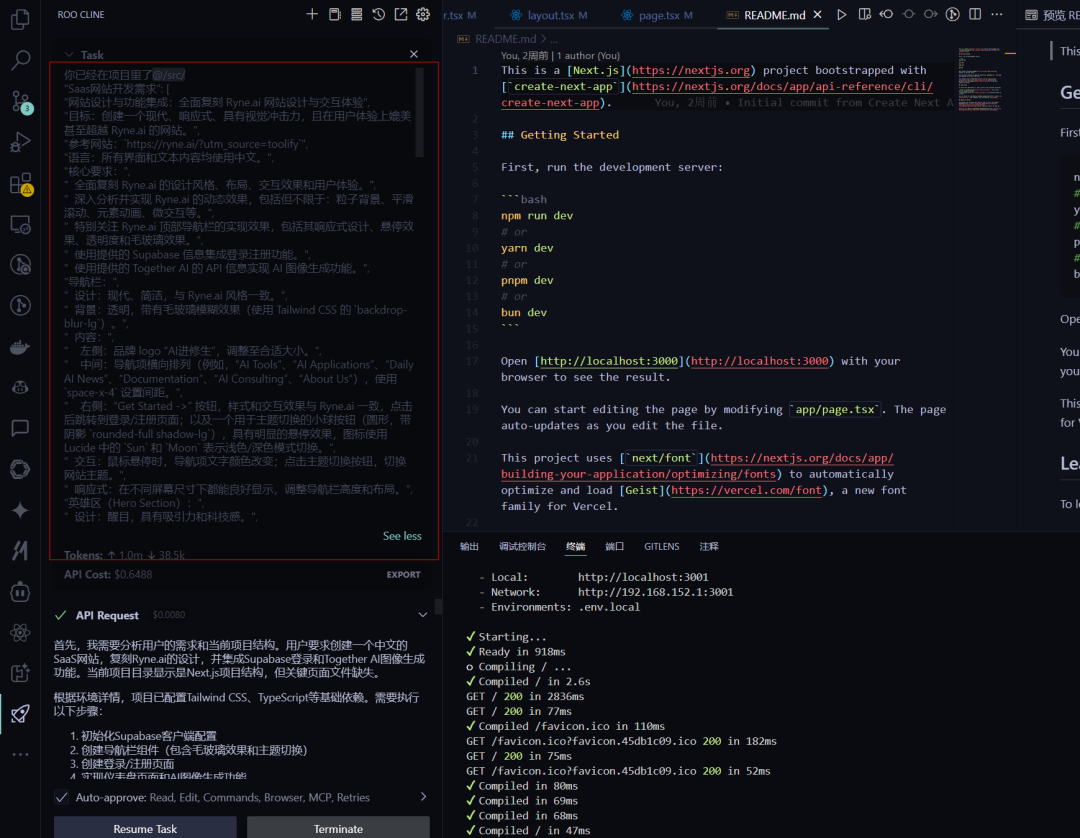
Let it create a SaaS website prototype. The prompt is relatively long and can be obtained from the article above.
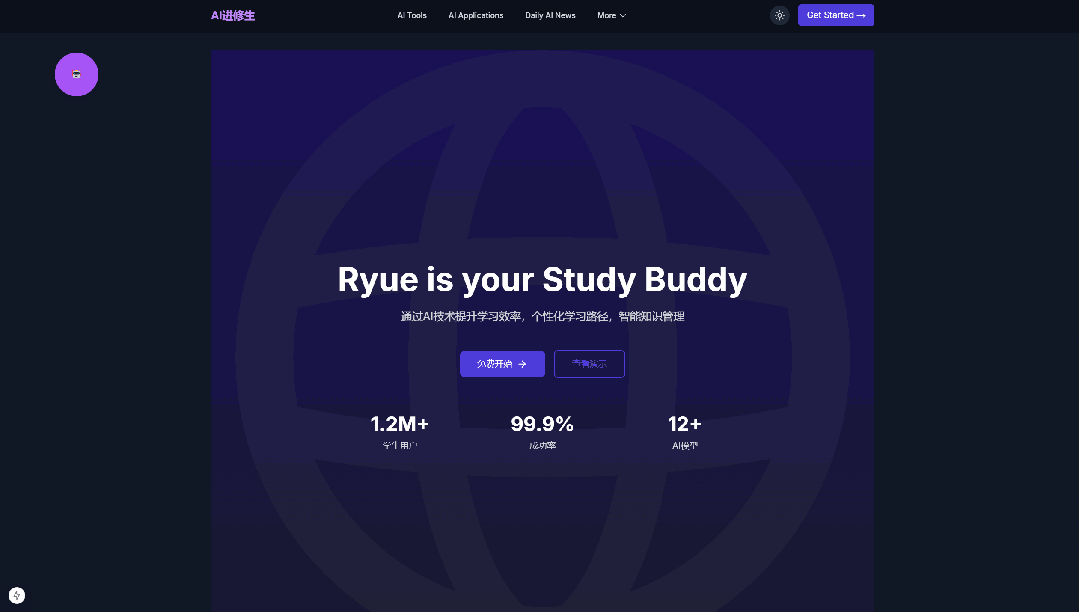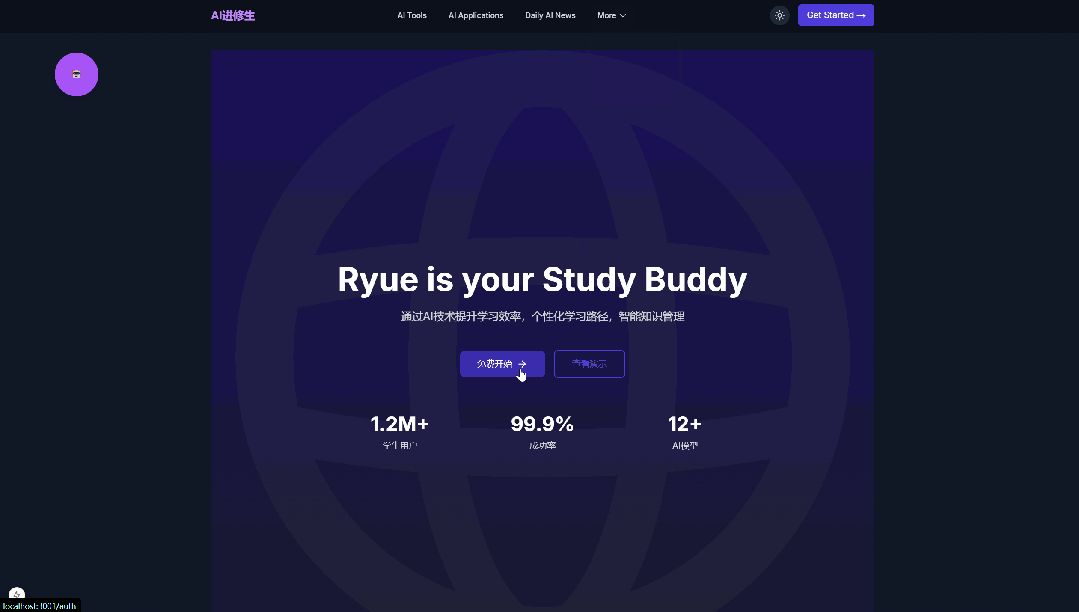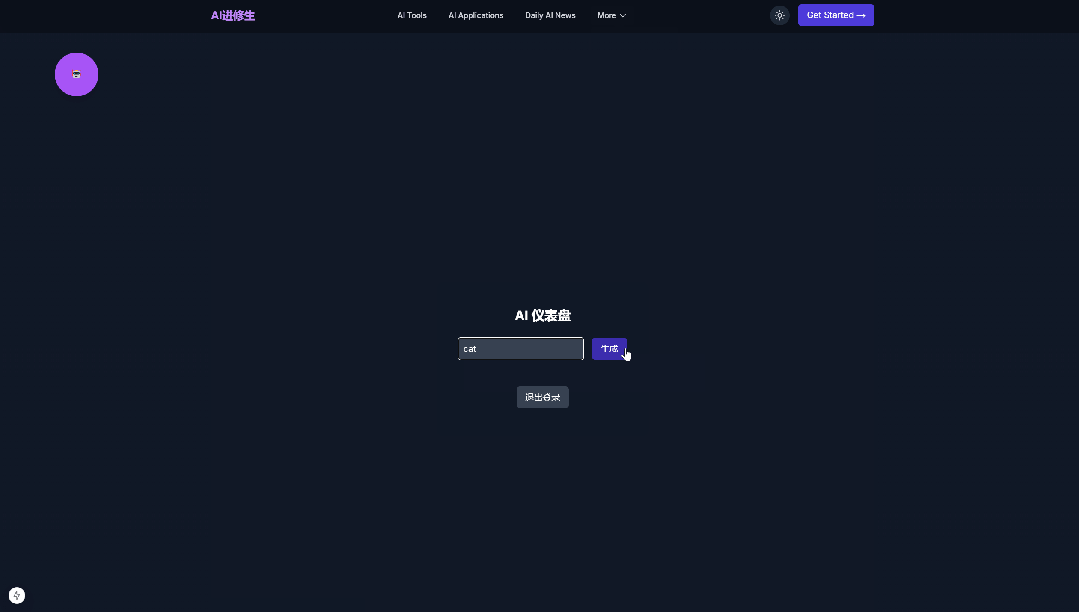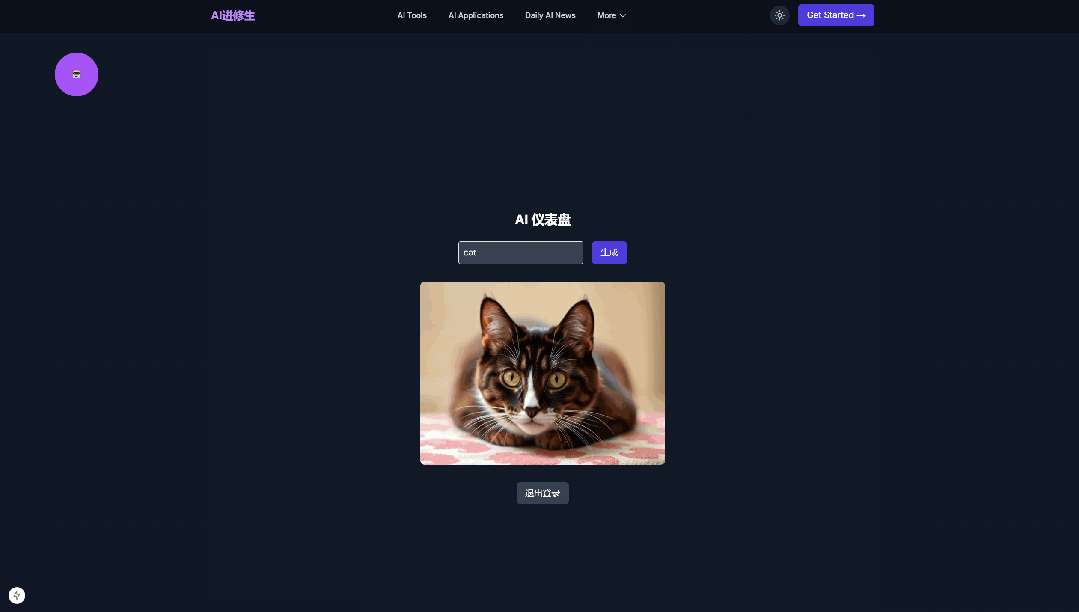
Pretty good, the SaaS framework, front-end and back-end, login and registration, and raw images are all acceptable.
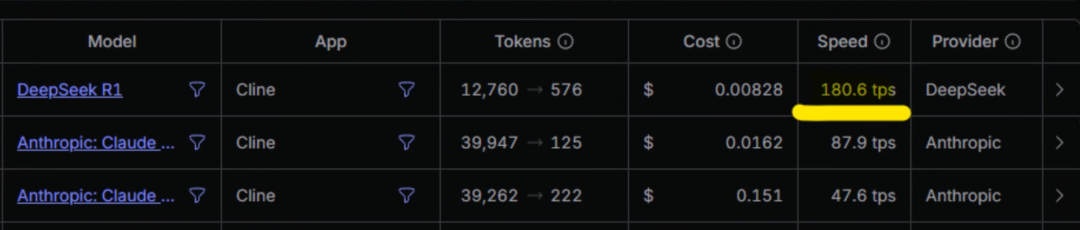
Next, here is its speed and consumption table in Cline:
Direct Chat usage on the Deepseek official website:
In addition, there are six distilled small models: Qwen 1.5B, 7B, Llama 8B, Qwen 14B, 32B, and the Llama series.
These fine-tuned models are trained using samples generated by DeepSeek-R1, greatly reducing the barrier to constructing thinking models.

This operation is very heartwarming, allowing users with different needs to use it, from laptops to servers, everyone can find a suitable version.
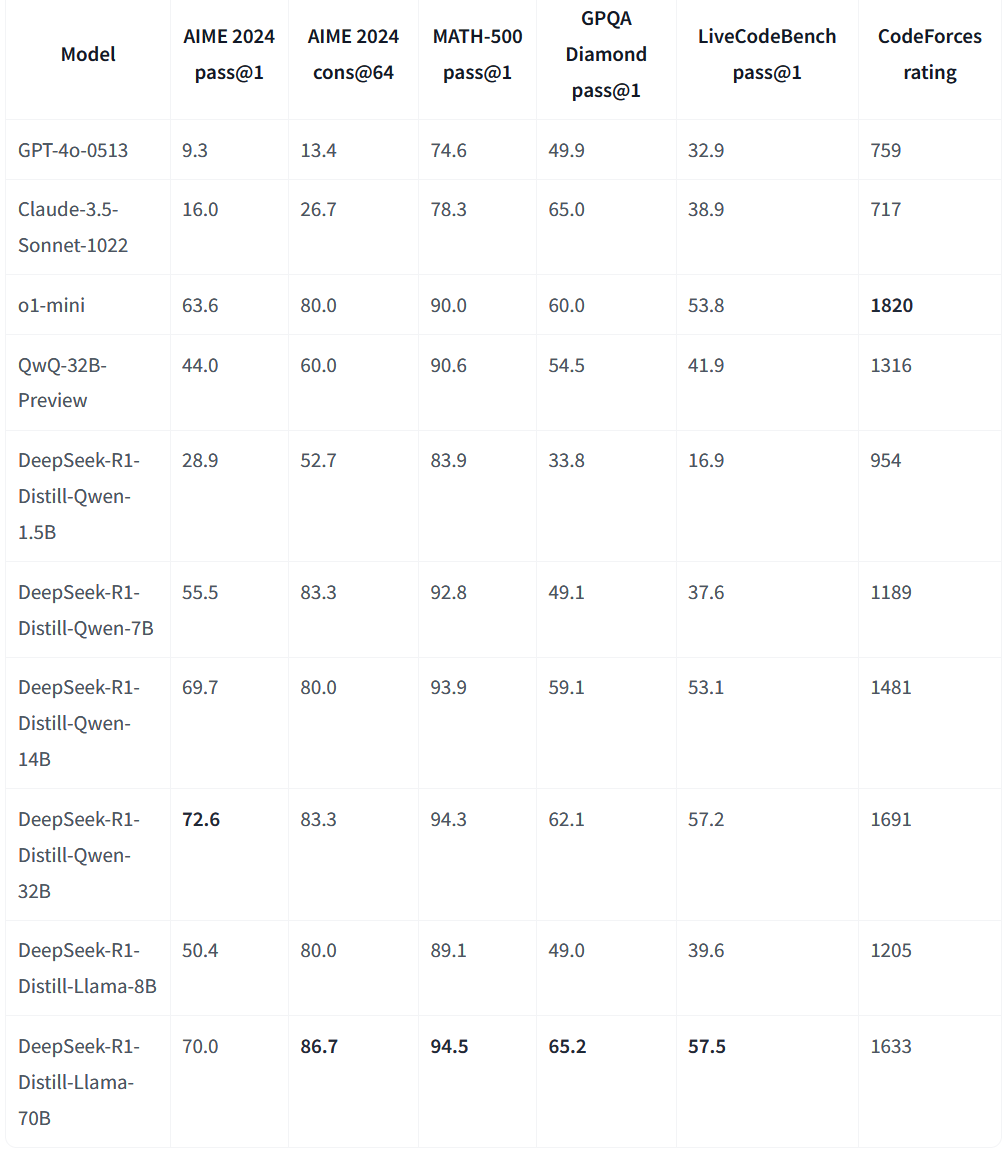
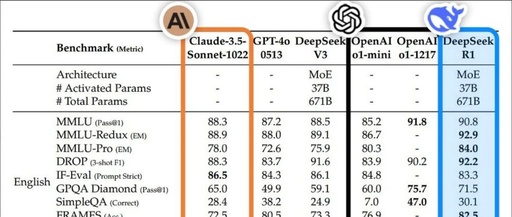
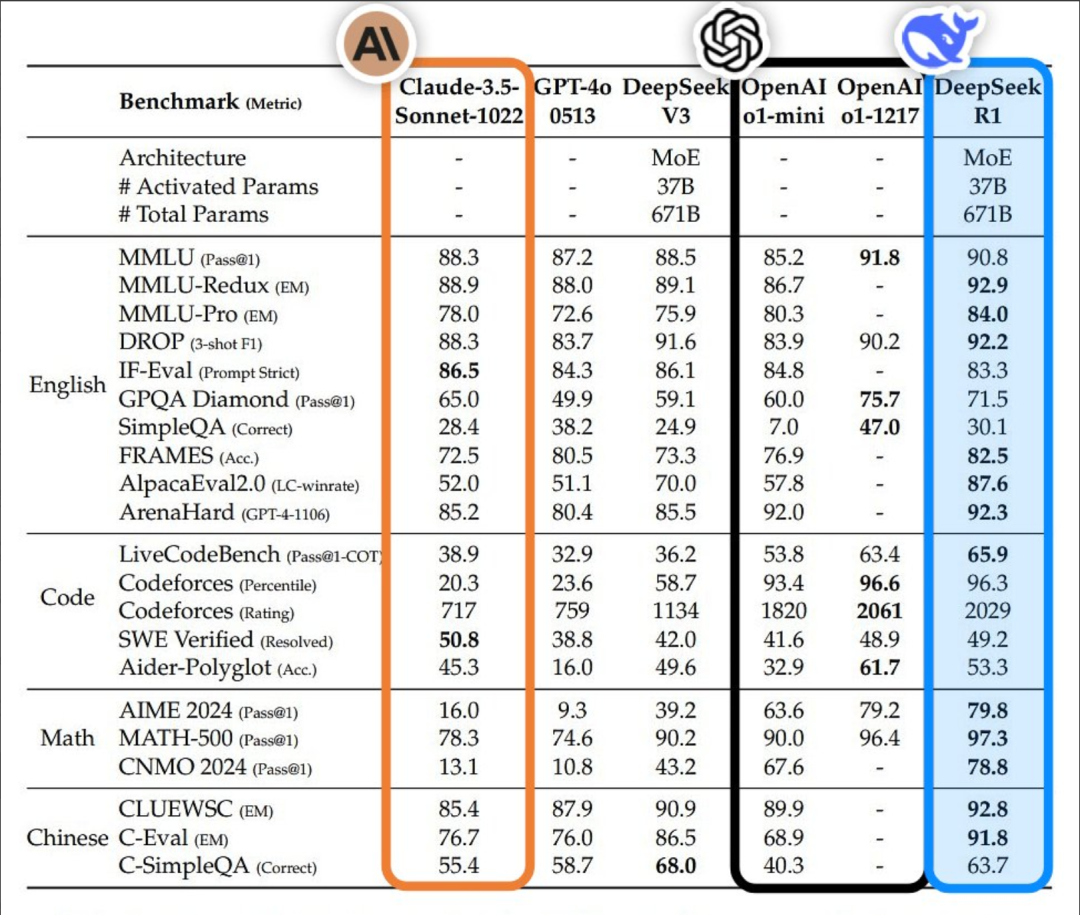
The test results exceeded expectations, with the strongest being Llama-70B. GPQA Diamond 65.2, higher than Claude 3.5. In programming, LiveCodeBench 57.5, CodeForces 1633, almost comparable to o1-mini.
Ollama can now be deployed, and it will soon be able to run locally withVLLM.
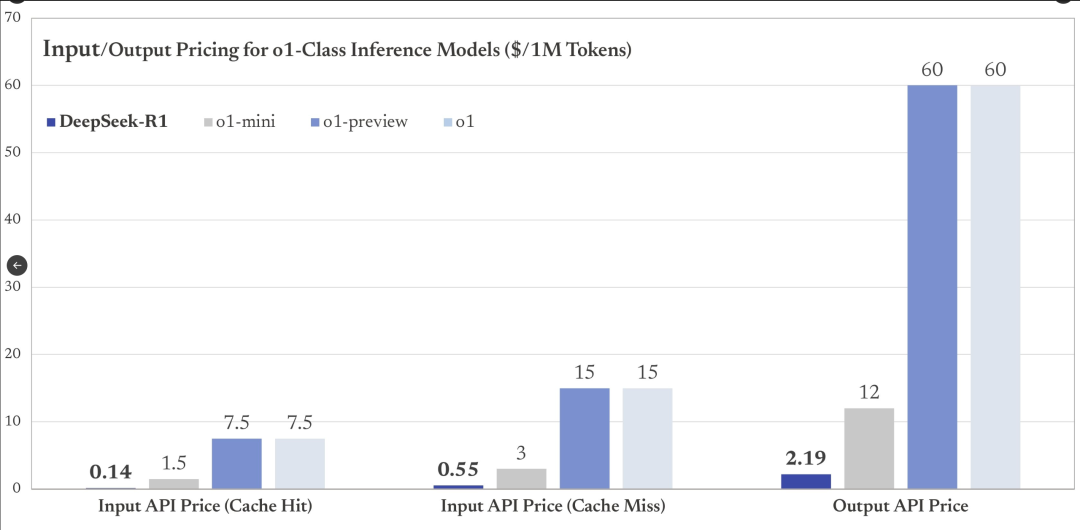
R1 has a very friendly price. API charges: input $0.14 per million tokens (cache hit), $0.55 (cache miss), output $2.19. Compared to o1: input $15, output $60.
Now let’s talk about relying entirely on reinforcement learning, without requiring supervised fine-tuning:
Using hard-coded rules to calculate rewards, rather than using a learning-based reward model. A learning-based reward model may be “exploited” or “cheated” by the reinforcement learning strategy, leading to optimization results deviating from the expected goal. Just like AlphaZero, learning from scratch without imitating humans.
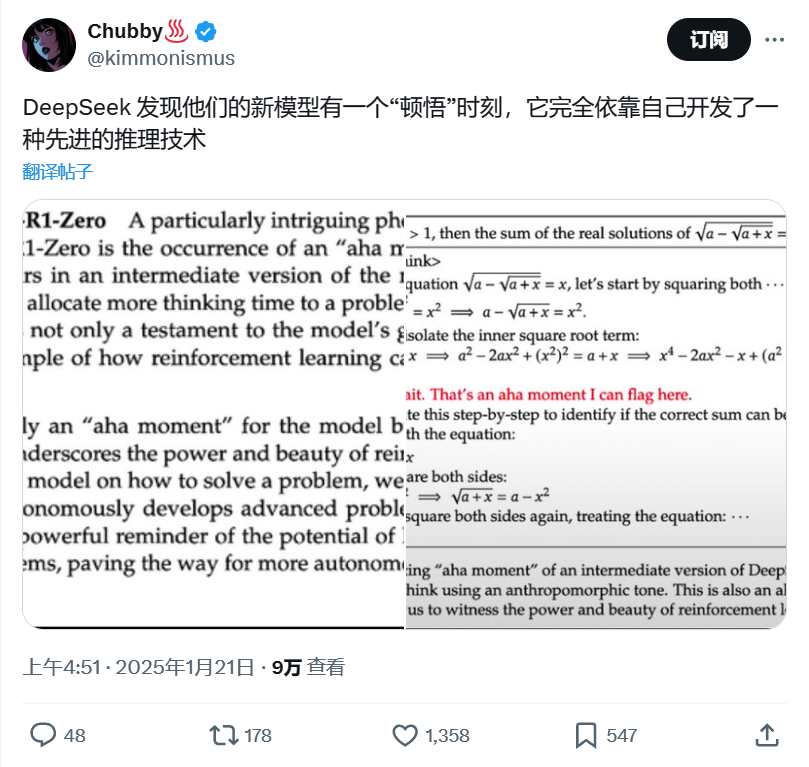
An interesting discovery during the training process: the model’s thinking time naturally increases, which is not preset but spontaneously formed. The model gradually learns to spend more time thinking for complex problems, reflecting abilities similar to “self-reflection” and “exploratory behavior”.
This is a manifestation of advanced intelligent behavior, indicating that the model has deeper reasoning capabilities. This ability, which has not been explicitly encoded, belongs to the “emergent behavior” of intelligence.

They invented GRPO, which is simpler than PPO: removing the critic network and replacing it with the average reward of multiple samples, simplifying memory usage. This method was proposed in February 2024.
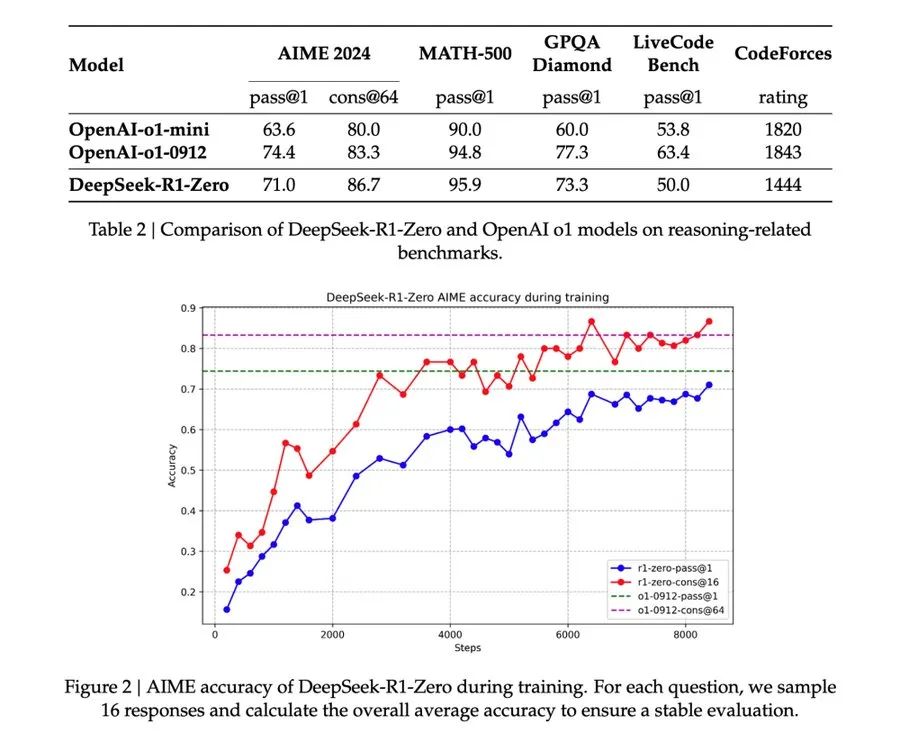
The test results of DeepSeek-R1-Zero are quite interesting.
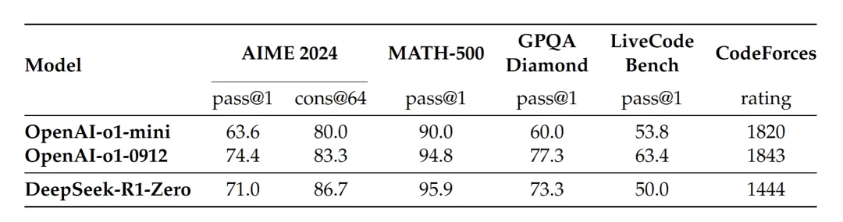
Relying solely on reinforcement learning, it scored 71.0 in AIME 2024 and reached 95.9 in MATH-500. Although slightly lower than o1-0912, the gap is not significant.
Especially in MATH-500, R1-Zero’s 95.9 exceeds o1-mini’s 90.0. This indicates that models trained purely with RL can also master complex mathematical reasoning.
It scored 73.3 in LiveCode Bench, significantly higher than o1-mini’s 60.0.
This result is important: it proves that without a large amount of labeled data, AI can learn to think and reason solely through reinforcement learning. This may change the way we train AI.
R1,achieved the level of closed-source major manufacturers in just a few months, while also providing a more affordable price.
Finally, according to the official statement, there are still several areas where DeepSeek-R1 needs improvement, and they will continue to work hard:
In terms of general capabilities, function calls, multi-turn dialogue, role-playing, and JSON output are not as good as version V3. The team plans to improve using long-chain reasoning.
Language processing is somewhat interesting. Currently, it mainly optimizes for Chinese and English, and other languages tend to get mixed up. For example, if asked in German, it might think in English and then answer in German.
Prompts are very sensitive. Few-sample prompts may instead affect performance; it is recommended to directly describe the problem and output format for better results.
In software engineering tasks, slow evaluations affect RL training. They plan to speed this up using rejection sampling or asynchronous evaluation.
🌟 Finding a kindred spirit is hard, self-improvement is keyRefining is also difficult, seize the opportunity of cutting-edge technology and become an innovative super individual with us (grasping the personal power of the AIGC era).
Reference link: [1] https://chat.deepseek.com/